
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Понятие информации. Носители информации. Понятие сообщения. Формы сообщений.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте Понятие информации. Носители информации. Понятие сообщения. Формы сообщений. Информация – потребляемый всеми отраслями общества ресурс, который имеет такое же значение как энергия или запасы полезных ископаемых. Свойства информации: · Релевантность. · Полнота · Своевременность · Достоверность · Защищенность · Эргономичность Носители информации - среда или физическое тело для передачи, хранения и воспроизведения информации. Основные характеристики НИ: · Информационная емкость · Скорость обмена информацией · Надежность · Стоимость Сообщение – форма предоставления информации, совокупность знаков или первичных сигналов, содержащих информацию. Формы сообщений: · Устное сообщение – предоставление информации с помощью речи. · Письменное сообщение – представление информации в письменном виде · Дискретное сообщение – сообщение, переданное с помощью дискретных сигналов, т.е. сигналов, параметры которых принимают последовательное во времени конечное число значений. · Непрерывное сообщение – сообщение, которое можно задать непрерывной функцией · Языковое сообщение – сообщение, переданное с помощью определенного языка. Понятие сообщения. Передача сообщений. Сообщение – форма предоставления информации, совокупность знаков или первичных сигналов, содержащих информацию.
Информация передаётся в форме сообщений от некоторого источника информации к её приёмнику посредством канала связи между ними. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал. Этот сигнал посылается по каналу связи. В результате в приёмнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
Каналы связи делятся на односторонние и двусторонние. Каналы связи: 1. симплексный – однонаправленный. 2. полудуплексный – рассчитан на два направления, но в конкретный момент имеет только одно направление. 3. дуплексный – одновременно в два направления.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
3. Понятие информации. Способы измерения информации.Информация – потребляемый всеми отраслями общества ресурс, который имеет такое же значение как энергия или запасы полезных ископаемых. Свойства информации: · Релевантность. · Полнота · Своевременность · Достоверность · Защищенность · Эргономичность Количество информации i, содержащееся в сообщении о том, что произошло одно из N равновероятных событий, определяется из решения показательного уравнения: 2i = N. N — количество возможных событий (неопределённость знаний), i — количество информации в сообщении о том, что произошло одно из N событий.
Понятие информационного процесса. Виды информационных процессов. Информационный процесс – процесс получения, создания, сбора, обработки, накопления, хранения, поиска, распространения и использования информации Виды: · Хранение - представление информации на носителе с доступом к ней. · Передача – перенос информации между объектами. · Обработка – изменение информации над ее содержимым. Понятие кибернетики. Кибернетический подход к управлению. Кибернетика – наука об общих закономерностях процессов управления и передачи информации в различных системах. Кибернетический подход – исследование системы на основе принципов кибернетики, в частности с помощью выявления прямых и обратных связей, изучения процессов управления, рассмотрения элементов системы как неких «черных ящиков» (систем, в которых исследователю доступна лишь их входная и выходная информация, а внутреннее устройство может быть и неизвестно). Понятие информационных ресурсов, информационных систем. Эволюция информационных технологий. Информационный ресурс – информация и инструменты управления этой информацией. Информационная система – комплекс информационных ресурсов, а также получение, обработка и поддержание этих ресурсов в актуальном состоянии. Информационные системы делятся на: Малые: не долго используются на рабочих местах; массовое использование; работа с небольшими объемами информации; маленькая цена и отсутствие средств модификации; использование настольных БД. Средние: возможность использования сети; обработка информации для нескольких рабочих мест; разделение функций между рабочими местами; при создании ведется тесное взаимодействие с заказчиком; присутствует штат обслуживающих сотрудников; включает в себя малые ИС. Большие: использование большого разнообразия вычислительной техники и программного обеспечения; поддержка территориальной распределенности предприятия; включает в себя средства для аналитической обработки и поддержки принятия решений; включает в себя малые и средние ИС.
Эволюция информационных систем. Изменение подхода к использованию информационных систем.
Эволюция информационных систем, связанная с характером развития технических средств обработки информации и достоинств информационных систем: 1-й этап (до конца 60-х годов) характеризуется проблемой обработки больших объемов данных в условиях ограниченных возможностей аппаратных средств. 2-й этап (до конца 70-х годов) связывается с распространением ЭВМ серии 1ВМ/360. Проблема этого этапа - отставание программного обеспечения от уровня развития аппаратных средств. 1-й и 2-й этапы характеризуются довольно эффективной обработкой информации при выполнении рутинных операций с ориентацией на централизованное коллективное использование ресурсов вычислительных центров. Основным критерием оценки эффективности создаваемых информационных систем была разница между затраченными на разработку и сэкономленными в результате внедрения средствами. Основной проблемой на этом этапе была психологическая - плохое взаимодействие пользователей, для которых создавались информационные системы, и разработчиков из-за различия их взглядов и понимания решаемых проблем. Как следствие этой проблемы - создавались системы, которые пользователи плохо воспринимали и, несмотря на их достаточно большие возможности, не использовали в полной мере. 3-й этап (с начала 80-х годов) - компьютер становится инструментом непрофессионального пользователя, а информационные системы - средством поддержки принятия его решений. Проблемы - максимальное удовлетворение потребностей пользователя и создание соответствующего интерфейса работы в компьютерной среде. Изменился подход к созданию информационных систем - ориентация смещается в сторону индивидуального пользователя для поддержки принимаемых им решений. Пользователь заинтересован в проводимой разработке, налаживается контакт с разработчиком, возникает взаимопонимание обеих групп специалистов. На этом этапе используется как централизованная обработка данных, характерная для 1-го этапа, так и децентрализованная, базирующаяся на решении локальных задач и работе с локальными базами данных на рабочем месте пользователя. 4-й этап (с начала 90-х годов) -.создание современной технологии межорганизационных связей и информационных систем. Этот этап связан с понятием анализа стратегических преимуществ в бизнесе и основан на достижениях телекоммуникационной технологии распределенной обработки информации. Информационные системы имеют своей целью не просто увеличение эффективности обработки данных и помощь управленцу. Соответствующие информационные технологии должны помочь организации выстоять в конкурентной борьбе и получить преимущество. Проблемы этого этапа весьма многочисленны. Наиболее существенными из них являются:
7.Понятие информационных ресурсов, информационных систем. Характеристики современных информационных систем. Величина и сложность Уникальность 5. Динамичность Вещественные числа.
Все равные по абсолютному значению положительные и отрицательные числа отличаются только этим битом. В остальном числа с разным знаком полностью одинаковы. Для представления отрицательных чисел здесь не используется дополнительный код. Символьная информация Таблица кодировки – распределение символов по кодам их представления. ASCII (American Standard Code Information Interchange) - 1 символ в этой кодировке занимает 1 байт, в таблице находится 256 символов. Unicode - 1 символ в этой кодировке занимает 2 байта, в таблице Графика · Векторная графика описывает изображение с помощью математических формул. · Растровая графика прямоугольная матрица состоит из множества очень мелких неделимых точек, пикселей. Звук · Аналоговое представление звука. Звуковая дорожка грампластинки - пример непрерывной формы записи звука. Такую форму называют аналоговой. В электрофоне колебания движущейся по звуковой дорожке иглы превращаются в непрерывный электрический сигнал, он может быть получен с помощью прибора, который называется осциллографом. Электрический сигнал передается на динамик электрофона и превращается в звук. · Цифровое представление звука: принцип дискретности - любые данные в памяти компьютера хранятся в виде цепочек битов, т. е. последовательностей нулей и единиц. Запись звука происходит через микрофон, который создает непрерывный электрический сигнал, а воспроизведение - через динамики, которые звучат также под действием непрерывного электрического сигнала. Происходит преобразование аналоговой формы представления звука в дискретную и обратное преобразование. Первый процесс называется аналого-цифровым преобразованием (АЦП), второй - цифро-аналоговым преобразованием (ЦАП). Видео Способы представления информации в ЭВМ, кодирование и преобразование кодов в значительной степени зависят от принципа действия устройств, в которых эта информация формируется, накапливается, обрабатывается и отображается. · Статическая видеоинформация включает текст, рисунки, графики, чертежи, таблицы и др. Рисунки делятся также на плоские - двухмерные и объемные - трехмерные. Динамическая видеоинформация используется либо для передачи движущихся изображений (анимация), либо для последовательной демонстрации отдельных кадров вывода (слайд-фильмы). · Динамическая видеоинформация - это видео, мульт и слайд фильмы. В их основе лежит последовательное экспонирование на экране в реальном масштабе времени отдельных кадров в соответствии со сценарием. По способу формирования видеоизображения бывают растровые, матричные и векторные. · Растровые видеоизображения используются в телевидении, а в ЭВМ практически не применяются. · Матричные изображения получили в ЭВМ наиболее широкое распространение. Изображение на экране рисуется электронным лучом точками. Информация представляется в виде характеристик значений каждой точки – пиксела, рассматриваемого как наименьшей структурной единицей изображения.. · Изображение может быть и в векторной форме. Тогда оно составляется из отрезков линий (в простейшем случае - прямых).
Программное обеспечение Технология макетирования. Вся программа создается как последовательность прототипов. Прототип – программа, которая решает все типичные задачи заказчика и которую можно быстро разработать. ДЕМОНСТРАЦИОННЫЙ ПРОТОТИП ИССЛЕДУЮЩИЙ ПРОТОТИП ДЕЙСТВУЮЩИЙ ПРОТОТИП ПРОМЫШЛЕННАЯ СИСТЕМА КОММЕРЧЕСКАЯ СИСТЕМА Демонстрационный прототип – программа, которая с одной стороны демонстрирует заказчику способ решения его задач, а с другой стороны - жизнеспособность всех методов, которые выбраны для решения данной задачи. Исследовательский прототип – программа, которая решает все задачи заказчика в полном объеме, но при этом она не устойчива в работе. Действующий прототип – программа, которая надежно решает все задачи заказчика, но для решения некоторых задач она требует слишком много ресурсов. Промышленная система – программа, которая надежно решает все задачи заказчика и при этом требует минимума ресурсов (часто работа заканчивается на этом этапе). Коммерческая система – программа, пригодная для тиражирования.
Языки программирования Машина Тьюринга.
Машина Тьюринга – абстрактная вычислительная машина. В состав машины Тьюринга входит бесконечная в обе стороны лента (возможны машины Тьюринга, которые имеют несколько бесконечных лент), разделённая на ячейки, и управляющее устройство, способное находиться в одном из множества состояний. Число возможных состояний управляющего устройства конечно и точно задано. Машина имеет головку для чтения записей информации, эта головка, обозревает некоторую ячейку в результате, либо считывается либо записывается информация в ячейку. М – это считывающая головка. М Машина обладает внутренней памятью, она может иметь К-состояний. Состояние внутреннее памяти = состоянию машины Тьюринга. Машина имеет собственную программу для функционирования (набор команд = программа). Какой символ прочитан с ленты? В каком состоянии находится машина? Результат: - Символ, который записывается в ячейку; - Возможное изменение состояний машины; - Возможное перемещение читающей головки. Команда имеет вид: aq1bq2 D a – Символ который читается с ленты, q1 – начальное состояние, b – символ, который записывается, q2 – новое состояние, D – возможное перемещение читающей головки. D={L, R, S} L – переместится на одну ячейку в лево, R – вправо, S – остаться на месте. Символы, это символы из некоторого алфавита, которые остаются вместе с программой. A={a1, …, an, e}, где e – пустое значение. Q={q1, …, qk}, k возможных состояний. Для того что бы определить машину Тьюринга, нужно определить: Алфавит; Состояние; Программу. Способы записи машины Тьюринга: 1. Двумерная таблица. По строкам таблицы записываются все символы алфавита, по столбцам – состояние машины. Внутри это результат работы, если не входе определен символ и определено состояние.
2. Граф. Строится из точек и дуг направления: Точки – Состояние машины Тьюринга, Дуги – Переходы машины из одного состояния в другое, причем все дуги являются помеченными.
Дополнительные условия машины Тьюринга: 1. Для некорректных исходных данных программы для машины Тьюринга должны зациклиться. · Данные считаются корректными, если в начальный момент времени читающая головка находится на единице, входные данные. · Исходные данные должны состоять только из алфавита машины · Входные данные должны отвечать дополнительным условиям задачи. 2. После завершения работы алгоритма машины Тьюринга, читающая головка должна вернуться под первый символ результата. Тезис Тьюринга – Любой неформальный алгоритм может быть записан с помощью машины Тьюринга, которая дает один и тот же результат при одинаковых исходных данных. Композиции машин Тьюринга.
По-другому их можно назвать операции над машиной Тьюринга. ü ИТЕРАЦИЯ, последовательное соединение. Имеются две машины Тьюринга, Т1 и Т2, задается некоторое начальное состояние Т1 и некоторая комбинация на ленте. Эта программа выполняется и в один этап, мы получаем результат. Результат исходные данные для Т2 и после этого выполнится машина Т2. Алгоритм работы последовательного соединения. 1. Механически объединить в одну таблицу две программы. 2. Заменить конечное состояние Т1 на начальное состояние Т2. 3. Нужно заменить клетки Т1, которые означают завершение первой программы, команды следующего вида. ip1S i – Символ который стоит в строке, p1 – Начальное состояние, S – движение остаться на месте. ü ПОВТОРЕНИЕ машины Тьюринга. 1. В тех машинах где встречается конечное состояние, нужно указать начальное состояние этой же машины. 2. В пустых клетках указать iq1S i – Символ который соответствует строке, где записана команда, q1 – Начальное состояние, S – движение остаться на месте. Алгорифмы Маркова.
Нормальные алгорифмы являются вербальными, то есть предназначенными для применения к словам в различных алфавитах. Определение всякого нормального алгорифма состоит из двух частей: определения алфавита алгорифма (к словам, в котором алгорифм будет применяться) и определения его схемы. Схемой нормального алгорифма называется конечный упорядоченный набор т. н. формул подстановки, каждая из которых может быть простой или заключительной. Простыми формулами подстановки называются слова вида Аналогично, заключительными формулами подстановки называются слова вида При этом предполагается, что вспомогательные буквы
Примером схемы нормального алгорифма в пятибуквенном алфавите | * abc может служить схема
Концепция типа данных
1. Любая переменная, константа, выражение или функция относятся к некоторому типу; 2. Тип данных определяет множество значений, к которым относится константа, и, которые могут принимать переменные, выражение или функция; 3. Каждая операция и функция требует для своего выполнения аргументов строго определенного типа и вырабатывает результат так же строго определенного типа. Следствия: 1. Все новые типы данных определяются только на основе уже существующих; 2. Значения новых типов данных всегда состоят из комбинации значений предыдущих типов данных, поэтому значения новых типов называются составными; 3. Если при построении нового типа данных используется только один составляющий тип, то он называется базовым; 4. Число различных значений, входящих в тип данных, называется мощностью типа; 5. Каждый язык высокого уровня дает свои изобразительные средства для указания принадлежности какой-либо переменной к определенному типу; 6. Любой язык для любого типа данных вводит всегда 2 операции: это присваивание и сравнение на равенство; 7. Если для значения какого-либо типа данных определяется операция отношения, то такой тип данных называется скалярным. Диаграмма Вирта 1. Терминальный символ – «круг» 2. Детерминальный символ – «квадрат» 3. Стрелки Бэкус-Наур форма 1. Терминальный символ – a 2. Детерминальный символ - <a> 3. [a] – 0/1 4. {a} – 0/1/2/3… 5. a|b – a/b 6. конструкция – S::=L Переопределение типа: typedef «старый тип» «новый тип» Целочисленный тип
Операции: · Div, mod; · Арифметические (+, -, *, /); · Сравнения (<, >, <=, >=, <>, =); Процедуры и функции: · Математические (sqr(x), sqrt(x)); · Тригонометрич. (sin(x), cos(x)), x – угол в радианах; · Прочие: o pred(x) – пред. знач.; o succ(x) – след. знач.; o odd(x) – true, если нечетное; o inc(x) – увеличение x на 1; o dec(x) – уменьшение x на 1; Вещественный тип
Операции: · Сравнения (<,>,=,>=,<=,<>); · Арифметические(+,-,*,/).
Процедуры и функции: · Все математические; · Все тригонометрические; · Прочие: o Trunc(x) – отсечение дробной части; o Round(x) – округление до ближайшего целого числа; Перечислимые типы имя знач.1 имя знач.2 Type имя =..... имя знач.N-1 имя знач.N var x:имя;
Операции: · Сравнения (<,>,=,>=,<=,<>);
Процедуры и функции: · Pred; · Succ; · Ord;
I/O: НЕТ! Множественные типы Type имя = set of базовый тип M1 = set of color; Var x:M1; Присваивания: x:=[red,black,green]; x:=[white]; x:=[]. Операции: · Сложение; · Умножение; · Вычитание; · In. Процедуры и функции: НЕТ! I/O: НЕТ! Массив Type имя = array [T1] of T2
T1 – тип индекса (кроме вещ.) T2 – тип элементов (кроме file)
Запись Type имя = record {как begin} имя поля1: тип1; имя поля2: тип2; End;
Пример: type day=1..31; month=(янв,фев,мар,..,дек); data=record
d:day; m:month; y:integer; end;
var x:data;
begin x.d:=15; x.m:=май; x.y:=2007; end.
Массив Массивы - это группа элементов одинакового типа (double, float, int и т.п.). Из объявления массива компилятор должен получить информацию о типе элементов массива и их количестве. В языке СИ первый элемент массива имеет индекс равный 0. Например: int a[2][3]; - матрица 2х3 double b[10]; - вектор из 10 элементов имеющих тип double int w [3][3] = { { 2, 3, 4 }, { 3, 4, 8 }, { 1, 0, 9 } }; В последнем примере объявлен массив w[3][3]. Списки, выделенные в фигурные скобки, соответствуют строкам массива, в случае отсутствия скобок инициализация будет выполнена неправильно. Структура Структуры - это составной объект, в который входят элементы любых типов, за исключением функций. Тип структуры определяется записью вида: struct {список определений } В структуре обязательно должен быть указан хотя бы один компонент. Например: struct { double x,y; } s1, s2, sm[9]; struct { int year; char moth, day; } date1, date2; Объединения (смеси) Объединение подобно структуре, однако в каждый момент времени может использоваться (или другими словами быть ответным) только один из элементов объединения. Тип объединения может задаваться в следующем виде: union { описание элемента 1; ... описание элемента n; }; Для каждого из объявленных элементов выделяется одна и та же область памяти. Доступ к элементам объединения осуществляется тем же способом, что и к структурам. Например: union { char fio[30]; char adres[80]; int vozrast; int telefon; } inform; Обработка подмассива 1. Для массива определить схему и индекс, который будет связан с обработкой этого массива. 2. Для подмассива определить схему и индекс, связанный с подмассивом. Для каждого элемента массива обработать все ему предшествующие. · От первого к последнему For i:=2 to n do For j:=1 to i-1 do обработать a[j]; · От первого к последнему – массив, от последнего к первому – подмассив. For i:=2 to n do For j:=i-1 downto 1 do обработать a[j]; · От последнего к первому – массив, от первого к последнему – подмассив. For i:=n downto 2 do For j:=1 to i-1 do Обработать a[j]; Нелинейные схемы обработки Переменная величина для изменения индекса. 1. Выписать пример изменения индекса. 2. Проанализировать пример на наличие частичных закономерностей. 3. Определить закономерность по переходу между частичными закономерностями. Класс Сначала определить какие действия нужно выполнить с конкретным элементом массива. Затем, схему обработки элементов из условий задачи. Пример: Дан массив, нужно найти кол-во элементов массива, которые равны максимальному. max:=a[1]; count:=1; For i:=2 to n do If a[i]> max then begin max:=a[i]; count:=1; end else if a[i]=max then count:=count+1;
Класс Либо изменение порядка (сортировка), либо структуры (действия, которые производятся над конкретным элементом массива). Пример: Поделить все элементы массива на его 5 элемент. B:=a[5]; For i:=1 to n do A[i]:=a[i]/b; Пример: Массив нужно записать так, чтобы его элементы шли в обратном порядке. For i:=1 to n div 2 do Begin B:=a[i]; A[i]:=a[n-i+1]; A[n-i+1]:=b; End; Класс Задачи синхронные и асинхронные. Если синхронная, то элементы разных массивов, стоящих на одинаковых позициях, обрабатываются одновременно. Можно использовать первую схему и индекс для обработки нескольких массивов. Если асинхронная, то элементы различных массивов обрабатываются независимо друг от друга. Пример: Даны 2 вектора, необходимо сложить 2 вектора. For i:=1 to n do c[i]:=a[i]+b[i]; Пример: Из вектора а переместить в вектор b только положительные элементы, при этом в векторе b сохранить порядок следования элементов из вектора а, записывать элементы с самого начала. i:=0; For i:=1 to n do If a[i]>0 then begin j:=j+1; b[j]:=a[i]; end; Пример: Даны 2 вектора, известно, что в каждом из этих векторов информация упорядочена по возрастанию. Нужно получить 3ий вектор, куда переписать все элементы из двух векторов, при этом сохранить условие упорядоченности. Алгоритм Фон-Неймана: const n=10; const m=20; Var a:array [1..n] of real; b:array [1..m] of real; c:array [1…n+m]; I,j,k:integer; Begin i:=1; j:=1; k:=1; While (i<=n) and (j<=m) do begin If a[i]<b[j] then begin c[k]:=a[i]; i:=i+1; end else begin c[k]:=b[j]; j:=j+1; end; k:=k+1; end; While i<=n do begin c[k]:=a[i]; i:=i+1; k:=k+1; end; While j<=m do begin c[k]:=b[j]; j:=j+1; k:=k+1; end; Класс Поисковые задачи на массивах. 1. Линейный поиск (применяется в любых случаях). Пример: Функция должна возвращать индекс искомого элемента. Const n=…; no:=…; Type massiv=array [1..n] of real; Var a: massiv; Function search (a:massiv; x:real): integer; Var i: integer; q: boolean; Begin i:=1;q:=false; While (i<=n) and (not q) do If a[i]=x then q:=true else i:=i+1; if q then search:=i else search:=no; end; 2. Линейный поиск с барьером. Барьер – дополнительный, фиктивный элемент в массиве, располагающийся либо в начале, либо в конце. Значение барьера устанавливается значение элемента, который ищется в массиве. Можно использовать только две схемы: от 1го к последнему или от последнего к первому. Const n=…; no:=…; Type massiv1=array [1..n] of real; Var a:massiv; Function search1 (a:massiv1; x:real):integer; Var:integer; Begin i:=1;a[n+1]:=x; While a[i]<>x do i:=i+1; If i<=n then search:=i else search:=no; End; 3. Бинарный поиск. Берется последовательность (упорядоченная). Сначала определяется серединный элемент массива. Производится равнение искомого значения с серединным элементом. Если значение искомого элемента < серединного, то поиск продолжается в левой части массива, если >, то – в правой. Если выполняется равенство, то элемент найден.
Const n=…; no=…; Type massiv = array [1..n] of real Function search2 (a: massiv; x: real): integer; Var m, l, r: integer; q: Boolean; Begin l:=1; r:=n; q:=false; While (not q) and (l<=r) do Begin m:=(l+r) div 2; If a[m]=x then q:=true else if x<a[m] then r:=m-1 else l:=m+1; End; If q then search2:=m else search2:=no; End;
Динамические структуры. Хеширование. Рехеширование. Хеширование – преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины. Хеширование применяется для сравнения данных: если у двух массивов хеш-коды разные, массивы гарантированно различаются; если одинаковые — массивы, скорее всего, одинаковы. В общем случае однозначного соответствия между исходными данными и хеш-кодом нет в силу того, что количество значений хеш-функций меньше, чем вариантов входного массива; существует множество массивов, дающих одинаковые хеш-коды — так называемые коллизии. Рехеширование – повторное хеширование. Виды рехеширования: · Линейное — Hi(x) =(H(x)+i) mod N · Квадратичное — Hi(x) =(H(x)+i)2 mod N · Случайное — Hi(x) =(H(x)+Ri) mod N, где Ri – случайная константа.
Строки и подстроки Метод решета. Метод является логическим дополнением к процессу поиска с возвращением, который перечисляет все элементы множества, отвечающие условию задачи. Одним из самых известных примеров применения метода решета является алгоритм отыскания простых чисел под названием «решето Эратосфена». Суть метода состоит в просеивании множества натуральных чисел от Генерирование перестановок. Методы генерирования последовательности всех · в лексикографическом порядке · с помощью векторов инверсий · с помощью вложенных циклов · в порядке минимального изменения. Генерирование сочетаний. Обычно требуются не все подмножества множества
Генерирование размещений. Так как размещения - это упорядоченные k-элементные подмножества множества из n элементов (упорядоченные сочетания из n no k), то алгоритм их порождения можно получить путем комбинации алгоритмов порождения сочетаний и перестановок. Понятие перестановки, подмножества, сочетания и разбиения. Реализация алгоритмов порождения перестановок в лексикографическом порядке, с помощью векторов инверсий, вложенных циклов и в порядке минимального изменения.
· Перестановка — это упорядоченный набор чисел 1, 2,…,n, обычно трактуемый как биекция на множестве {1, 2,…,n}, которая числу i ставит соответствие i-й элемент из набора. Число n при этом называется порядком перестановки. · Множество A является подмножеством множества B, если любой элемент, принадлежащий A, также принадлежит B. · Сочетание из n по k - повторная выборка k элементов из n-элементного множества без возвращения и без упорядочения, · Разбиением целого положительного числа n называется представление n в виде суммы n = x1 + x2 +... + xk целых положительных чисел xi, i = 1,..., k. Задача - сгенерировать последовательности всех n! перестановок n-элементного множества. С помощью вложенных циклов. Будем говорить, что перестановка Алгоритм порождения подстановок с помощью вложенных циклов основан на следующей теореме.
Любую подстановку В качестве начальной перестановки берем
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-14; просмотров: 5204; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.018 с.) |



 символов.
символов. , где L и D — два произвольных слова в алфавите алгорифма (называемые, соответственно, левой и правой частями формулы подстановки).
, где L и D — два произвольных слова в алфавите алгорифма (называемые, соответственно, левой и правой частями формулы подстановки). , где L и D — два произвольных слова в алфавите алгорифма.
, где L и D — два произвольных слова в алфавите алгорифма. и
и  не принадлежат алфавиту алгоритма (в противном случае на исполняемую ими роль разделителя левой и правой частей следует избрать другие две буквы).
не принадлежат алфавиту алгоритма (в противном случае на исполняемую ими роль разделителя левой и правой частей следует избрать другие две буквы).


 до
до  путем поэтапного вычеркивания составных чисел. Сначала удаляются все числа, кратные двум(каждое второе), затем – все, кратные трем(каждое третье), и т.д. Процесс прекращается после просеивания для наибольшего простого числа меньшего
путем поэтапного вычеркивания составных чисел. Сначала удаляются все числа, кратные двум(каждое второе), затем – все, кратные трем(каждое третье), и т.д. Процесс прекращается после просеивания для наибольшего простого числа меньшего 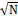 .
. перестановок
перестановок  множества.
множества. , а только те, которые удовлетворяют некоторым ограничениям. Особый интерес представляют подмножества фиксированной длины
, а только те, которые удовлетворяют некоторым ограничениям. Особый интерес представляют подмножества фиксированной длины  ,
,  - сочетаний из
- сочетаний из  предметов по
предметов по 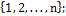 таким образом, будем порождать все сочетания длины
таким образом, будем порождать все сочетания длины 

 является циклом длины k степени d, если ее элементы
является циклом длины k степени d, если ее элементы  , получены из 1, 2, …, k циклическим сдвигом вправо на d позиций, остальные n – k элементов стационарны. Например, подстановка
, получены из 1, 2, …, k циклическим сдвигом вправо на d позиций, остальные n – k элементов стационарны. Например, подстановка  является циклом длины 4 степени 1.
является циклом длины 4 степени 1. на множестве
на множестве  можно представить в виде композиции
можно представить в виде композиции  , где
, где  — циклическая подстановка порядка i.
— циклическая подстановка порядка i.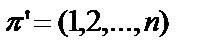 и сдвигаем на одну позицию вправо все элементы до тех пор, пока вновь не получим
и сдвигаем на одну позицию вправо все элементы до тех пор, пока вновь не получим  ; теперь сдвигаем циклически первые
; теперь сдвигаем циклически первые  элементов и снова повторяем сдвиг всех n элемент
элементов и снова повторяем сдвиг всех n элемент 


