
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Оценка факторов риска и прогнозирование на основе логистической регрессииСодержание книги
Поиск на нашем сайте
Оценка рисков и влияния факторов риска являются важными задачами медицинских исследований – на основании этих данных строятся профилактические мероприятия и прогнозируются исходы тех или иных методов лечения. Как правило, в поиске наиболее значимых анализируется множество факторов, которые могут быть измерены по разным шкалам – непрерывным, дискретным, ординальным, номинальным. В этом случае есть проблема подбора адекватного многомерного статистического метода, не ограниченного какимилибо особыми рамками. Логистическая регрессия используется, когда зависимая величина является бинарной (т.е. принимает значения да/нет, имеет/не имеет, например, пациент может выздороветь, а может не выздороветь, нуждается в госпитализации или не нуждается и т.д.) и на ее исход влияют независимые переменные различного характера (качественные и/или количественные). Фактически оценивается вероятность принять одно из этих двух утверждений под влиянием изучаемых признаков. Логит этой вероятности – натуральный логарифм отношения вероятности «положительный эффект» (р) к вероятности «отрицательный эффект» (1 р).
Величина Процедура логистической регрессии заключается в создании и оценке уравнения вида
где x1, x2, x3, – независимые переменные, b0 и b1, b2, b3,…– постоянные коэффициенты Тогда вероятность положительного эффекта
Рассмотрим пример построения логистической регрессии в программе «STATISTICA6». В таблице 71 представлены некоторые факторы, которые возможно влияют на риск возникновения артериальной гипертензии (АГ).
Таблица 71. Факторы риска
Необходимо определить какое влияние на вероятность АГ оказывают отобранные переменные. Исходные данные представляются в виде матрицы n×m, где n количество обследованных, m число признаков. Фрагмент этой матрицы показан в таблице 72. Общий объем выборки составил 607 человек.
Таблица 72. Данные к примеру
Анализ проводится в модуле Nonlinear Estimation, для запуска которого надо в меню Statistics выбрать команду Advanced Linear/Nonlinear Models (линейные/нелинейные модели). В открывшемся меню выбрать команду Nonlinear Estimation (нелинейная оценка), а затем опцию Quick Logit regression (логит регрессия) – «ОК». В открывшемся окне необходимо указать зависимую и независимые переменные из списка переменных, щелкнув кнопкой Variables. Зависимой переменной (откликом) является «АГ», независимой – все остальные. Нажмите ОК. Программа возвратится в начальное диалоговое окно. С помощью строки Input File contains (введите содержимое файла) отметьте вариант: Codes and no count (только коды) и вновь нажмите на ОК. Откроется окно Model Estimation. Во вкладке Advanced можно выбрать процедуру оценивания — Estimation method. Выберем: quasiNewton. Поставьте птичку в окошке Asymptotic standart errors. ОК. Появится диалоговое окно Results. Видно, что значение параметра Chisquare (хиквадрат) = 294,6 велико, а значение р =0,000000 мало. Это говорит о достаточной адекватности выбранной модели. Качество модели можно оценить и по классификационной матрице во вкладке Classification of cases and odds ratio (таблица 73) Таблица 73. Результаты статобработки
В целом информационная способность модели составляет 470/607*100%=77% Отношение шансов показывает, что классификация по модели в 8 раз корректнее, чем если бы мы предсказывали исход случайным образом. Кнопка Summary. Parameter estimates на вкладке Advanced предназначена для визуализации предсказанных значений коэффициентов b0, b1, b2, b3, b4, b5, b6, b7 уравнения логит регрессии (таблица 74).
Таблица 74. Результаты статобработки
Первые три строки таблицы дают нам значения коэффициентов логистической регрессии, их стандартные ошибки, статистическую значимость по критерию Стъюдента и доверительный интервал для каждого коэффициента.
Статистическую значимость можно оценить и по критерию хиквадрат Вальда. Из таблицы видно, что статистически незначимыми являются коэффициенты для факторов «пол», «курение» и «потребление алкоголя» (р>0,05), т.е. для них принимается нулевая гипотеза о равенстве отношения шансов единице, т.е. эти факторы не влияют на риск развития артериальной гипертензии. Влияние всех других факторов можно оценить по величине отношения шансов (ОШ) и доверительным интервалам для них. Значительно повышает риск артериальной гипертензии наследственный фактор в 6,8 (4,510,3) раз. Далее идет «потребление соли» – в 1,9 (1,22,9) раз, «вес» – ОШ от 1,01,3, а возраст фактически не ассоциирован с риском АГ (ОШ=1,0161,045). Теперь рассмотрим, как можно использовать полученную модель для прогнозирования. Пусть обследуется пациент со следующими признаками: мужчина в возрасте 45 лет, вес 75 кг (3 весовая категория), курит, алкоголь не потребляет, любит соленую пищу, отец гипертоник. Рассчитаем
Вероятность положительного эффекта (отсутствия АГ)
Тогда вероятность развития АГ =10,45=0,55
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 361; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.122.20 (0.006 с.) |

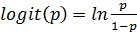 (75)
(75) является непрерывной и принимает значения в интервале от 0 до 1 (от отрицательного эффекта к положительному эффекту).
является непрерывной и принимает значения в интервале от 0 до 1 (от отрицательного эффекта к положительному эффекту). (76)
(76) (77)
(77)
 =0,196
=0,196



