Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Унифицированный язык работы с БД SQL.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте В 1970 году Э. Подд написал статью «реляционная модель для больших банков». В исследовательской версии СУБД появился язык SEQEL. В 1979 году появилась первая коммерческая СУБД Oracle. В 1982 году появляется продукт DB2. Известно 3 версии стандартов языка: 89, 92 и 99 года. В настоящее время самым признанным является стандарт 92 года, и все реляционно полные сервера стараются поддерживать его. В 1986 году SYBASE появился реляционно полный сервер, в котором предложена бизнес-логика. У Microsoft полновесный сервер появился в 1998 году. В 1992 году Microsoft предложена ODBC – унификация доступа к данным БД. SQL включает в себя совокупность конструкций для определения структуры БД, операций автоматизации, выборки, санкционирования доступа, описания пользовательских представлений, управления транзакциями, триггеры. Рассмотрим основные конструкции:
Хранимые процедуры. Современные сервера БД наряду с организацией ведения базы поддерживают бизнес-логику в теле сервера, которая позволяет поддерживать целостность БД, расширяя возможности модели, организация обработки информации, организуют клиентский интерфейс. Таким образом, классическую ИС можно построить на функциональности сервера БД, привлекая ЯВУ для организации интерфейса. Бизнес-логика организуется посредством хранимых процедур и триггеров. Разработан универсальный язык процедур: SPL – это обычный структурный язык, в котором поддерживаются условные операторы, циклы, блоки, именованные переменные. К сожалению, каждый сервер БД поддерживает свой диалект языка и процедуры, зашитые в один сервер, не будут работать в другом сервере. Считается, что развитую бизнес-логику приложения целесообразно хранить отдельно на ЯВУ для обеспечения конвертации. Описание процедуры: CREATE PROCEDURE <имя процедуры> (<список формальных параметров>). Вызов процедуры – EXECUTE <имя процедуры> (<список фактических параметров>). Приведем пример работы с хранимой процедурой в MS SQL: CREATE PROCEDURE <имя> [{@ <имя параметра><тип>[=значение по умолчанию][OUTPUT]}*] AS <SQL-выражение> EXEC[UTE] <имя> [{[<имя входных параметров>=]<значение входного параметра>}*]. Процедура, возвращающая список поставок за определенный интервал времени: PROCEDURE sp_date_supp @ start DATETIME @ end DATETIME AS SELECT s.SUPPLIER_NAME, d.DETAIL_NAME, o.ORDER_QUANTITY FROM SUPPLIER s INNER JOIN ORDER o ON s.SUPPLIER_CODE = o.SUPPLIER_CODE INNER JOIN DETAIL d ON o.DETAIL_CODE = d.DETAIL_CODE WHERE o.ORDER_DATE BETWEEN @start AND @end GO. Обращение к этой процедуре: EXECUTE sp_date_supp ’01.01.2004’,’31.01.2004’ ИЛИ EXECUTE sp_date_supp @start = ’01.01.2004’, @end = ’31.01.2004’. Результат:
Процедуры хранятся в БД наряду с таблицами, индексами и для описания проектов они показываются на диаграмме пакетов. Триггеры – это особые хранимые процедуры, которые вызываются в ответ на оптуализацию содержимого БД. В отличие от хранимой процедуры каждый триггер связывается с определенной таблицей БД и СУБД его выполняет, когда данные в соответствующей таблице изменяются (реакция на команды INSERT, DELETE, UPDATE). Использование: контроль изменений – триггер может отслеживать и отменять определенные изменения, не разрешенные в БД; каскадная операция – может отслеживать определенные операции и автоматически вносить собственные изменения в другие таблицы; поддержание целостности базы – может поддерживать сложные связи между данными, расширяя возможности реляционной модели; вызов хранимых процедур (процедуры могут вызываться самостоятельно без триггеров). Первые три использования реализуются процедурами, а триггер их запускает.
MS SQL Server CREATE TRIGGER <имя триггера> ON <имя таблицы> [BE] FOR[E]/AFTER/INSTEAD OF <триггерное событие> AS <SQL-выражение>. Триггерное событие::= INSERT/DELETE/UPDATE. Рассмотрим пример триггера на поддержание актуального количества деталей на складе при осуществлении поставок: CREATE TRIGGER tr_order ON ORDER FOR INSERT AS UPDATE DETAIL SET d.DETAIL_QUANTITY = d.DETAIL_QUANTITY+i.ORDER_QUANTITY FROM DETAIL d INNER JOIN INSERTED i ON d.DETAIL_CODE = i.DETAIL_CODE. Примечание: для примера в таблицу DETAIL ввели поле «количество», во время вставки в таблицу ORDER новой поставки (триггерное событие) осуществляется пересчет в таблице DETAIL количества (к существующему количеству добавляется новый объем поставки), MS SQL поддерживаются 2 рабочие таблицы: в одной из них хранятся копии всех вставляемых записей (INSERTED), а во второй хранятся копии удаляемых (DELETED). Встроенный SQL. SQL-конструкции встраиваются в исходный текст программы на ЯПВУ. Базовая разновидность встроенного SQL называется статическим SQL, усовершенствованный вариант, позволяющий формировать конструкции SQL прямо в программе, называется динамическим SQL. Каждый сервер поддерживает интерфейс с определенными ЯВУ, в котором можно поддерживать EXEC SQL. При этом в пользовательском программе интерактивно запрашиваются значения переменных, которые передаются в SQL-команды, они выполняются с БД и затем просматриваются результаты. Специальные программы (предкомпиляторы) преобразуют исходный текст программы на ЯПВУ в вызов соответствующих функций СУБД. Для обработки результата запроса предусмотрена работа с курсором. Курсор – это вид указателя, который может быть использован для перемещения по набору строк отношения, являющегося результатом выборки информации из БД. При этом используется команда объявления курсора DECLARE <имя курсора> CURSOR FOR <табличное выражение> [ORDER BY <список полей>] и команда чтения текущей строки курсора FETCH [NEXT/LAST/CURRENT/PREVIOUS] <имя курсора> INTO <список переменных основной программы>. <объявление переменных> EXEC SQL CONNECT <имя базы> EXEC SQL DECLARE X CURSOR FOR SELECT s.SUPPLIER_CODE, s.SUPPLIER_NAME, s.SUPPLIER_CITY FROM SUPPLIER S WHERE s.SUPPLIER_CITY=:Y; EXEC SQL OPEN X; BEGIN <перебор строк выборки> EXEC SQL FETCH x INTO:S#,:Sname,:Scity; <обработка данных> END; EXEC SQL CLOSE X. В третьем стандарте языка появились команды динамического SQL и возникла потребность формировать команду выборки. PREPFRE <идентификатор> FROM <базовая переменная> - формирует указания серверу в виде синтезированной текстовой строки SQL-предложения. EXECUTE <идентификатор> USING <базовая переменная> - выполняет предложение. 15. прикладной интерфейс СУБД – в конце 80-х годов в сервере SyBase применен новый подход организации интерфейса из языка ВУ в СУБД. Типичный набор функций: функция подключения к СУБД и конкретной БД, передача инструкций в программе, контроль инструкций и ошибок, выполнения запроса и передача результатов, функция отключения. В связи с развитием объектной парадигмы появились стандартные компоненты для работы с БД, в которые зашиты функции, в частности среда Delphi поставляет компонент IBX, которая позволяет работать с СУБД interBase. Корпорация Microsoft в 1992 году разработала универсальную библиотеку – набор стандартных функций для серверов. При этом поддерживается библиотека драйверов, позволяющая переформулировать стандартную функцию в функцию сервера. Фирма Borland разработала свою библиотеку BDF. Но для ряда СУБД нет драйверов. Для работы с БД на конкретном клиентском месте должна быть установлена система BDE, DBC, в которых нужно прописать источник. Кроме того, в библиотеке драйверов надо посмотреть, есть ли соответствующий драйвер. Для тонкого клиента вся обработка идет на сервере. Тенденции развития СУБД. В настоящее время широкое распространение получили реляционные сервера БД. Нормализованность отношений мешает хранить сложно структурированные объекты. Поэтому тенденциями развития является синтез реляционной модели и иерархической. Направления: создание ОО СУБД и ОР СУБД, унификация организации слабоструктурированной информации в виде XML-документов с организацией их хранения. В настоящее время большинство реляционно-полных серверов включили возможность хранения XML-документов. Первое направление: ОО СУБД позволяли описывать абстрактные типы данных. Таким образом, получилась микро иерархия исходный-порожденный «таблица в таблице», связь которой осуществляется посредством указателя и соединение при выборке информации не требуется. Кроме того, появилась возможность работы с большими объектами – блобами для хранения видео, документов и веб-страниц. Кроме того, появились чисто ОО СУБД, которые позволяют во внешней памяти хранить объекты, эффективно манипулировать ими и поддерживать целостность, управление транзакциями и т.д. Но унификация не была достигнута и коммерческих СУБД не появилось. XML СУБД – с появлением языка структурированной разметки документов открылось новое, альтернативное реляционному направление хранения информации. Любую информацию (табличную, иерархическую) можно загнать в XML-структуру. Документ на XML имеет иерархическую структуру (узлы, атрибуты и значения атрибутов). Последние версии реляционных серверов обеспечивает хранение и навигацию по таким документам. При этом достигнута унификация языка. Пример: ORDER [number=”896702”]. XML стал стандартом обмена информации между ИС. Кроме того, на XML унифицируются структуры данных общего использования. Итоги раздела СУБД. Знания:
Умения:
Навыки:
Автоматизированные ИС. Сетевая обработка данных. Виды автоматизированных ИС. Методология анализа и проектирования ИС.
Сетевая обработка данных. Термин применяется для описания систем с несколькими процессорами, территориально удаленными друг от друга. Имеют место 2 причины посылки транзакции: необходимы данные, которые хранятся на другом компьютере; недостаточна мощность используемой машины. Остановимся на первой причине. Технология «клиент-сервер». Организация сетевой обработки данных базируется на этой технологии. При этом выделяются в прикладных ИС функции и данные, которые служат многим. Обслуживающая часть называется сервером. Функции: управление работой оборудования коллективного использования, управление БД (сервер БД), поддержание сервисов Интернет. При этом может быть двухзвенная архитектура, тогда на сервере БД организована вся бизнес-логика приложения, к которой посредством запросов обращается клиентская часть. Более продвинутая – трехзвенная, кроме сервера БД и клиента существует сервер приложений, на котором расположены базовые классы – платформы конкретной ИС. В трехзвенной архитектуре хранятся сущностные экземпляры, соответствующие экземплярам базовых классов. На машинах клиентов происходит оформление заданий на составление отчетов. Эта часть может быть выполнена в 2 вариантах: толстый и тонкий.
Классификация ИС по способам распределения данных.
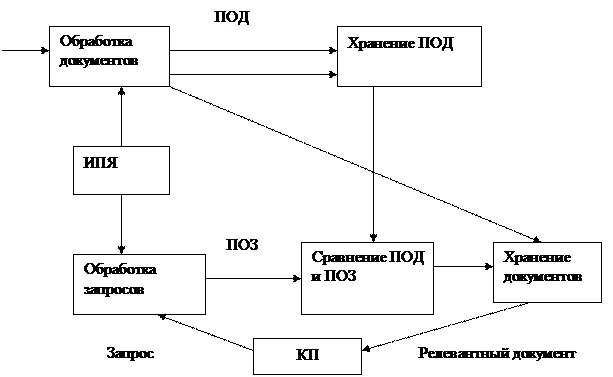
Виды автоматизированных ИС. АИС предназначены для хранения, обработки, поиска, распространения, передачи и представления информации. Документальные информационно-поисковые системы. Фактографические информационно-аналитические системы. Геоинформационные системы. В реальной практике имеется возможность пересечения систем. Документальные информационно-поисковые системы. Большая часть информации существует в виде документов – это средства закрепления различным способом на специальном материале информации о фактах, событиях, явлениях объективной действительности и мыслительной деятельности человека. Документальный поиск – это поиск сведений о документе или самого документа или его копии. Различают датоцентричные и документоцентричные объекты. Датоцентричные характеризуются строгой регулярной структурой, мелкой зернистостью и отличаются отсутствием или малым количеством смешанного содержимого (регистрационные карточки). Документоцентричные используются для восприятия человека, характеризуются менее регулярной структурой, крупнозернистыми данными и содержат мало смешанного содержимого (произведения искусства). Для хранения документоцентричных объектов в современных СУБД поддерживаются блобы. Документальные информационно-поисковые системы прошли 3 стадии развития: · середина 80-х годов – первые документальные ИПС, работа с БД началась с их создания. ИПС – совокупность программных, языковых и технических средств, предназначенных для организации сбора, хранения, поиска и постобработки информации. Для них используются коммерческие СУБД и в основу положено индексирование документов и запросов. Индексирование – процесс выражения содержимого поисковых образов документов и поисковых образов запросов на информационно-поисковом языке.
Существует 2 класса ИПЯ: в основе ИПЯ классификационного типа лежит организация понятий в виде иерархической древовидной структуры. Примеры: УДК, ГРНТИ. В основе ИПЯ дескрипторного типа лежит алфавитный перечень единиц, выраженных словами или словосочетаниями. В целях повышения эффективности поиска используются синонимы, ассоциативные понятия. Такой словарь называется тезаурус. В ИПС, созданных на основе коммерческих СУБД, индексирование выполняется с помощью справочников. Когда поддерживается двухуровненвая классификация, то применяется категорный справочник. Существуют организации, в которых поддерживаются ИПЯ, в частности РосСтат, ОКАТО, ОКФС, ОКВЭД, ОКСМ, при создании своего справочника надо всегда посмотреть, нет ли готового классификатора и его урезать под конкретное пользование. Чаще всего используется верхушка готового и она развивается для конкретного использования. Существует в налоговой службе классификатор адресов. Существуют отраслевые классификаторы. Поисковый образ документа в идеальном варианте должен полностью проиндексирован. Каждому полю должен соответствовать какой-то классификатор. Например, библиографическая карточка включает поле ключевых слов по УДК. · В 90-е годы появилась система управления электронными документами. Поиск в них основан на механизме полнотекстового поиска на основе инвертированной матрицы, в которую вносятся все значимые слова из всех документов в алфавитном порядке. С каждым словом связывается указатель на соответствующий документ. Разработана система распознавания образов, которая позволяет сканированные документы хранить с полнотекстовым индексированием всех слов. Для создания ИПС стали применять специализированные программные средства, в которых поддерживаются ОО БД, базовые классы, соответствующие основным шаблонам документов и автоматизированные бизнес-процессы, поддерживающее управление документами. По сути дела EDMS – это платформа, на основе которой поддерживаются соответствующие СУБД. Основные функции систем электронного документооборота: работа с документами, ведение внутренних документов, создание, согласование, утверждение, исполнение и списание дела. Следует заметить, что современные системы управления предприятиями интегрируются с системами документооборота. Исходящие и входящие документы: процедура рассмотрения документов, постановка на контроль, контроль сроков, формирование отчетов по поступлению документов. Коллективная работа с документами, при этом поддерживаются шаблоны маршрутов бизнес-процессов по каждому документу. Выделяется 2 класса систем документооборота: group ware – коллективный доступ, work flow – модель группового взаимодействия с распределением ролей, очередности обращения. Фактографический поиск – это поиск данных, фактов, извлеченных из документов. Определим фактографические ИС. Они делятся по назначению, масштабу, виду обработки. По назначению можно выделить следующие классы АС, для которых БД играют роль информационного обеспечения.
По масштабу можно выделить локальные системы, предназначенные для учета по одному или нескольким направлениям (бухучет), финансово-управляющие системы, предназначенные для управления ресурсами непроизводственных компаний (финансовое управление), средне-интегрированные системы предназначены для управления производственным процессом на предприятиях, крупные интегрированные системы ориентированы на корпоративную консолидацию информации, управление сложными финансовыми потоками, глобальное планирование. Данный класс систем применяется в крупных корпорациях, холдингах, их свойства – территориальная распределенность, наличие нескольких ведомственных вертикалей, несколько иерархических уровней управления. С большой концентрацией производства создание крупных ИС становится актуальным. Корпорация – это стабильная, многопрофильная территориально-распределенная структура, обладающая всеми необходимыми системами жизнеобеспечения и функционирующая на принципах децентрализованного управления. По виду обработки данных различаются системы оперативной обработки данных (учетные системы), системы поддержки принятия решений – программные средства для руководства среднего звена, занимающегося планированием и управлением. Вся основная информация копится в системах оперативной обработки, а аналитическая обработка в целях принятия тактических и стратегических решений осуществляется в СППР. С укрупнением производства роль СППР резко возрастает. На малых предприятиях, в сфере услуг применяются малые и средние ИС. Для управленческих структур (холдингов) используются крупные ИС с использованием автоматизации поддержки принятия решений. Принцип управления, основанный на интеграции данных и их комплексной аналитической обработки, называется контролингом. Контролинг – это мониторинг состояния сложной системы, оценка и поддержка принятия решений, направленных на совершенствование и развитие системы. В основе информационной поддержки принятия решений лежит концепция хранилищ данных корпоративных информационно-аналитических систем. С развитием СППР теория БД получила новое развитие (технология многомерного анализа и интеллектуальный анализ данных).
|
||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-27; просмотров: 482; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.151 (0.015 с.) |