Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Введение в базы данных, основы интеграции данных.Стр 1 из 8Следующая ⇒
Базы данных. Ратманова Ирина Дмитриевна, Игнатьева Елена Сергеевна.
Ратманова «Базы данных. Курс лекций» (2006). Методички: «Проектирование баз данных и разработка приложений в среде MS SQL Server», «Проектирование баз данных и разработка приложений СУБД InterBase». Дополнительно: Ратманова «Методология организаций информационная поддержка принятия решений в сфере энергетики» (2006), Левенец «Технология разработки ПО», Дейт «Введение в систему баз данных».
Курс лекций:
Модели данных. Модели данных. Трехуровневое представление информации в интегрируемых базах данных.
Концептуальная модель предметной области отражает семантику в виде совокупности информационных объектов (сущностей), их характеристик (свойств) и связей между ними. (Семантика – смысловое значение слова.) Логическая модель БД – это выраженная в терминах модели данных СУБД концептуальная модель предметной области (модели данных – иерархическая, сетевая, реляционная). Физическая модель – это выраженная в терминах языка описания данных конкретной СУБД логическая модель БД. Её называют скрипт на создание базы. Сама БД, содержащая экземпляры информационных объектов, находится в файловом пространстве сервера и на модельном уровне не описывается. Реляционная модель данных. Характеристика модели. Предложил концепцию реляционной модели Эдвард Кодд, он предложил вложить в основу алгебру отношений. В основе реляционной модели лежит понятие теоретико-множественных отношений – это подмножество декартова произведения доменов, а домен – это множество значений, которые принимает атрибут (множество названий городов, фамилий сотрудников). Отношение (таблица) – подмножество декартова произведения одного или более доменов.
А11, А12 – это значения атрибутов. Реляционная база данных – это множество связанных между собой отношений (таблиц), и при этом связи между таблицами задаются посредством внешних или вторичных ключей, то есть атрибутов таблиц, которые в каких-то других отношениях являются первичными. Список имен атрибутов называется схемой отношения. Каждое отношение имеет уникальное имя. Свойства отношений: нет одинаковых кортежей – все записи отличаются по первичному ключу; кортежи не упорядочены сверху вниз; атрибуты не упорядочены слева направо (в операциях реляционной алгебры строки и столбцы отношений могут просматриваться в любом порядке и последовательности безотносительно к их информационному содержанию смыслу); все значения – скалярные и все элементы столбца имеют одинаковую природу, так как построены на одном домене. Отношение с такими свойствами называется нормализованным. В отношении один или несколько атрибутов являются ключом, то есть однозначно характеризует кортеж. Свойства ключа: уникальная идентификация выборки, неизбыточность (удаление любого атрибута лишает его свойства уникальности). Наряду со смысловым ключом используется инкрементный (счетчик), состоящий из одного числового поля, который автоматически наращивается.
Правила отображения концептуальной модели предметной области в реляционную БД. На рисунке 5 изображена концептуальная модель. Отобразим её в реляционную.
Целостность реляционной модели.
Целостность объектов (отношений) – в базе не допускается, чтобы какой-либо атрибут из первичного ключа принимал неопределенные значения. Ссылочная целостность – БД не должна содержать несогласованных значений внешних ключей (FK). Если отношение R2 имеет среди своих атрибутов какой-то внешний ключ, который соответствует первичному ключу (PK) отношения R1, то каждое значение FK должно быть равно значению РК. Пример: все коды материалов таблицы «деталь» должны присутствовать как первичные ключи в таблице материалов. Функции СУБД. План:
История. 70–первая половина 80-х – распространение иерархических и сетевых СУБД на ЕС ЭВМ. Конец 80-х – начало 90-х – широкое распространение псевдо-реляционных СУБД на ПЭВМ, развитие локальных вычислительных сетей. Середина 90-х – распространение реляционно полных серверов на рабочих станциях SUN, DEC, ПЭВМ. Развитие корпоративных вычислительных сетей, технологии «клиент-сервер». Конец 90-х – внедрение ОО подхода в технологию БД, появление ОР СУБД и ОО СУБД. Начало 2000-х – соединение баз данных с Интернет-технологиями, распространение корпоративных порталов, организация хранения XML-документов. За исключением первого этапа, актуальны все направления. Основные функции СУБД:
Управление данными во внешней памяти (физическая модель БД). С точки зрения ОС БД представляет собой один или несколько файлов. Форматирован на блоки (за один шаг доступа к диску считывается один блок памяти, который называется страницей (2, 4, 8, 16, 32 Кб)), объем страницы определяется в конфигурации сервера, страницы объединяются в экстенты – целое число страниц. Таким образом, физическая модель БД определяется понятиями «файл, экстент, страница» (существует и логический уровень для больших серверов БД). Например, для MS SQL Server существует CREATE DATABASE sample ON PRIMARY (NAME = Sample_data, FILENAME = ‘C:\mssql7\data\sample.mdf, SIZE = 10 MB, MAXSIZE = 15 MB, FILE GROWTH = 20 %) LOG ON (NAME = Sample_log, FILENAME = ‘C:\mssql7\data\Sample.ldf, SIZE = 3 MB, MAXSIZE = 5 MB, FILEGROWTH = 1 MB). Действие, выполняемое при сохранении или извлечении записи и файла, называется методом доступа. Различают 3 метода: последовательный, прямой и индексный. При последовательном доступе страницы в ОЗУ выбираются одна за другой последовательно от начала файла. На одной странице может быть расположено несколько логических записей базы, при этом поиск нужной записи идет последовательно. Одновременно в ОЗУ может находиться несколько страниц, с которыми работают информационные системы. Процесс обработки информации в буфере ОЗУ с периодическим сбрасыванием изменений на диск называется кэшированием. Настройку объема кэш-памяти задает администратор.
В основе прямого метода лежит прямое обращение к конкретной странице, при этом по ключу искомой записи строго определяется номер страницы. Если в конкретном приложении отсутствуют ключи, соответствующие определенным номерам страниц, то место все равно выделяется. Но в реальной практике сложно установить однозначное соответствие между ключом и номером страницы. Существуют методы алгоритмического определения номера страницы по ключу. Это методы хеширования, то есть задается хеш-функция, которая по ключу определяет номер страницы (в случае коллизии предусмотрена область переполнения). Прямой метод доступа в серверах является основой выборки информации, но для преобразования ключа в адрес страницы в настоящее время применяются индексы. Индексный метод доступа основан на создании специальных наборов, посредством которых устанавливается соответствие между ключом и номером страницы. Индексы хранятся в файле базы данных вместе с таблицами и состоят из двух полей: упорядоченный ключ поиска и номер страницы. Индексы автоматом создаются по всем первичным, альтернативным и вторичным ключам. Поиск осуществляется методом половинного деления. Кроме того, создаются бинарные деревья, при этом поиск по индексу осуществляется с помощью указателей. Индекс компактный, весь помещается в ОЗУ, поиск по нему идет очень быстро, в случае больших индексов поддерживаются деревья из индексов. Поиск включает 3 этапа:
Индексы по указанию проектировщика могут быть созданы по любому полю или группе полей (CREATE INDEX). СУБД поддерживают уникальные физические модели баз данных. Рассмотрим 3 уникальные модели:
Управление базой данных.
Оптимизатор запросов логически выводит код программы, оптимизируя его: относительная стоимость запросов оценивается из предполагаемого количества операций с дисками и операций сравнения в памяти. Используется системный каталог, в котором хранится информация о структуре БД, а также статистика базы (количество кортежей, количество блоков памяти, количество уникальных значений атрибутов, число уровней индексов). Для примера рассмотрим варианты выполнения запроса на выборку сведений по деталям, сделанным из стали, весом больше 10 единиц:
SELECT * FROM DETAIL d, MATERIAL m WHERE (d.MATERIAL_CODE = m.MATERIAL_CODE) AND (d.DETAIL_WEIGHT>10 AND m.MATERIAL_NAME = ‘Сталь’). Имеют место 3 варианта выполнения:
Чтобы принять решение оптимизатор по системному каталогу оценивает объем таблиц, участвующих в запросе. В современных информационных системах поддерживается еще один уровень метаданных, который позволяет переформулировать запрос в терминах концептуальной модели предметной области в SQL. Преобразование SQL в код программы для доступа к серверу осуществляет СУБД, а переформулирование запроса SQL в концептуальную модель посредством метаданных выполняет информационная система.
Потребительские качества СУБД. Сервер БД ориентирован на удовлетворение информационных потребностей и работает в многозадачном, многопользовательском режиме. Рассмотрим несколько аспектов работоспособности сервера в таком режиме: · Масштабируемость – свойство ВС, обеспечивающее предсказуемый рост характеристик при возникновении потребностей без отключения работы сервера. Сервер поддерживает конфигурационный файл, посредством которого без остановок можно наладить объем используемой ОП, число занятых процессоров, количество параллельных потоков, выполняющихся на одном процессоре, объем внешней дисковой памяти. · Производительность – достигается поддержкой параллелизма и организация многопоточной архитектуры. Любой запрос делится на атомарные операции, которые выполняются параллельно, и каждый из которых начинает работу не дожидаясь окончания предыдущей (например, считывание записи с диска, выборка по фильтру нужной записи, запись на диск результатов выборки). Этим процессом можно управлять, увеличивая размер буферного пула. При этом большое количество параллельных операций может выполняться в памяти. · Возможность смешанной загрузки разными типами задач – информационные системы решают 3 типа задач: оперативная обработка транзакций – это задачи оперативной обработки данных (расчет зарплаты, кадровый учет); DSS (Decision Support System) – задачи, связанные со стратегическим менеджментом; пакетная обработка. Работа сервера в разных режимах имеет особенности. Работа сервера OLTP можно охарактеризовать следующим образом: часто используются короткие транзакции, которые не использует одинаковые данные, запрос затрагивает небольшое число строк таблицы, используется несколько таблиц большого размера. Пример: получить информацию о регистрационных сведениях поставщика, внести в справочник новую деталь. Требования к серверу: небольшой объем кэш-памяти, простой оптимизатор, с точки зрения приложений исключить конкуренцию запросов. Работа сервера DSS: объем таблиц неограничен, часто требуется просмотр всех строк таблицы, число таблиц, участвующих в транзакции, может быть очень велико, транзакция работает только на чтение, высока вероятность разделения ресурсов между разными задачами. Для такого сервера нужен мощный оптимизатор, эффективная методика сканирования и соединения таблиц, разный механизм параллельного доступа. Сервер пакетной обработки: обрабатывает большие и сверхбольшие таблицы, преобладает значительная продолжительность транзакций, часто используется просмотр и/или модификация всех строк таблицы, преобладает запуск очень небольшого числа задач с высокой загрузкой процессора при заполнении ОП. Перечисленные особенности надо учитывать при определении конфигурации ВС. · Постоянная доступность данных, включая зеркалирование и тиражирование (репликация). Зеркалирование БД осуществляется на другом сервере, в случае аппаратного сбоя работа автоматически переходит на зеркало. Тиражирование поддерживается удаленно, это по сути копирование базы для дистанционного доступа к информации. Если обновление сервера незначительное, то можно поддерживать репликацию, то есть в определенное время во всех филиалах будут доступны все обновления.
Хранимые процедуры. Современные сервера БД наряду с организацией ведения базы поддерживают бизнес-логику в теле сервера, которая позволяет поддерживать целостность БД, расширяя возможности модели, организация обработки информации, организуют клиентский интерфейс. Таким образом, классическую ИС можно построить на функциональности сервера БД, привлекая ЯВУ для организации интерфейса. Бизнес-логика организуется посредством хранимых процедур и триггеров. Разработан универсальный язык процедур: SPL – это обычный структурный язык, в котором поддерживаются условные операторы, циклы, блоки, именованные переменные. К сожалению, каждый сервер БД поддерживает свой диалект языка и процедуры, зашитые в один сервер, не будут работать в другом сервере. Считается, что развитую бизнес-логику приложения целесообразно хранить отдельно на ЯВУ для обеспечения конвертации. Описание процедуры: CREATE PROCEDURE <имя процедуры> (<список формальных параметров>). Вызов процедуры – EXECUTE <имя процедуры> (<список фактических параметров>). Приведем пример работы с хранимой процедурой в MS SQL: CREATE PROCEDURE <имя> [{@ <имя параметра><тип>[=значение по умолчанию][OUTPUT]}*] AS <SQL-выражение> EXEC[UTE] <имя> [{[<имя входных параметров>=]<значение входного параметра>}*]. Процедура, возвращающая список поставок за определенный интервал времени: PROCEDURE sp_date_supp @ start DATETIME @ end DATETIME AS SELECT s.SUPPLIER_NAME, d.DETAIL_NAME, o.ORDER_QUANTITY FROM SUPPLIER s INNER JOIN ORDER o ON s.SUPPLIER_CODE = o.SUPPLIER_CODE INNER JOIN DETAIL d ON o.DETAIL_CODE = d.DETAIL_CODE WHERE o.ORDER_DATE BETWEEN @start AND @end GO. Обращение к этой процедуре: EXECUTE sp_date_supp ’01.01.2004’,’31.01.2004’ ИЛИ EXECUTE sp_date_supp @start = ’01.01.2004’, @end = ’31.01.2004’. Результат:
Процедуры хранятся в БД наряду с таблицами, индексами и для описания проектов они показываются на диаграмме пакетов. Триггеры – это особые хранимые процедуры, которые вызываются в ответ на оптуализацию содержимого БД. В отличие от хранимой процедуры каждый триггер связывается с определенной таблицей БД и СУБД его выполняет, когда данные в соответствующей таблице изменяются (реакция на команды INSERT, DELETE, UPDATE). Использование: контроль изменений – триггер может отслеживать и отменять определенные изменения, не разрешенные в БД; каскадная операция – может отслеживать определенные операции и автоматически вносить собственные изменения в другие таблицы; поддержание целостности базы – может поддерживать сложные связи между данными, расширяя возможности реляционной модели; вызов хранимых процедур (процедуры могут вызываться самостоятельно без триггеров). Первые три использования реализуются процедурами, а триггер их запускает.
MS SQL Server CREATE TRIGGER <имя триггера> ON <имя таблицы> [BE] FOR[E]/AFTER/INSTEAD OF <триггерное событие> AS <SQL-выражение>. Триггерное событие::= INSERT/DELETE/UPDATE. Рассмотрим пример триггера на поддержание актуального количества деталей на складе при осуществлении поставок: CREATE TRIGGER tr_order ON ORDER FOR INSERT AS UPDATE DETAIL SET d.DETAIL_QUANTITY = d.DETAIL_QUANTITY+i.ORDER_QUANTITY FROM DETAIL d INNER JOIN INSERTED i ON d.DETAIL_CODE = i.DETAIL_CODE. Примечание: для примера в таблицу DETAIL ввели поле «количество», во время вставки в таблицу ORDER новой поставки (триггерное событие) осуществляется пересчет в таблице DETAIL количества (к существующему количеству добавляется новый объем поставки), MS SQL поддерживаются 2 рабочие таблицы: в одной из них хранятся копии всех вставляемых записей (INSERTED), а во второй хранятся копии удаляемых (DELETED). Встроенный SQL. SQL-конструкции встраиваются в исходный текст программы на ЯПВУ. Базовая разновидность встроенного SQL называется статическим SQL, усовершенствованный вариант, позволяющий формировать конструкции SQL прямо в программе, называется динамическим SQL. Каждый сервер поддерживает интерфейс с определенными ЯВУ, в котором можно поддерживать EXEC SQL. При этом в пользовательском программе интерактивно запрашиваются значения переменных, которые передаются в SQL-команды, они выполняются с БД и затем просматриваются результаты. Специальные программы (предкомпиляторы) преобразуют исходный текст программы на ЯПВУ в вызов соответствующих функций СУБД. Для обработки результата запроса предусмотрена работа с курсором. Курсор – это вид указателя, который может быть использован для перемещения по набору строк отношения, являющегося результатом выборки информации из БД. При этом используется команда объявления курсора DECLARE <имя курсора> CURSOR FOR <табличное выражение> [ORDER BY <список полей>] и команда чтения текущей строки курсора FETCH [NEXT/LAST/CURRENT/PREVIOUS] <имя курсора> INTO <список переменных основной программы>. <объявление переменных> EXEC SQL CONNECT <имя базы> EXEC SQL DECLARE X CURSOR FOR SELECT s.SUPPLIER_CODE, s.SUPPLIER_NAME, s.SUPPLIER_CITY FROM SUPPLIER S WHERE s.SUPPLIER_CITY=:Y; EXEC SQL OPEN X; BEGIN <перебор строк выборки> EXEC SQL FETCH x INTO:S#,:Sname,:Scity; <обработка данных> END; EXEC SQL CLOSE X. В третьем стандарте языка появились команды динамического SQL и возникла потребность формировать команду выборки. PREPFRE <идентификатор> FROM <базовая переменная> - формирует указания серверу в виде синтезированной текстовой строки SQL-предложения. EXECUTE <идентификатор> USING <базовая переменная> - выполняет предложение. 15. прикладной интерфейс СУБД – в конце 80-х годов в сервере SyBase применен новый подход организации интерфейса из языка ВУ в СУБД. Типичный набор функций: функция подключения к СУБД и конкретной БД, передача инструкций в программе, контроль инструкций и ошибок, выполнения запроса и передача результатов, функция отключения. В связи с развитием объектной парадигмы появились стандартные компоненты для работы с БД, в которые зашиты функции, в частности среда Delphi поставляет компонент IBX, которая позволяет работать с СУБД interBase. Корпорация Microsoft в 1992 году разработала универсальную библиотеку – набор стандартных функций для серверов. При этом поддерживается библиотека драйверов, позволяющая переформулировать стандартную функцию в функцию сервера. Фирма Borland разработала свою библиотеку BDF. Но для ряда СУБД нет драйверов. Для работы с БД на конкретном клиентском месте должна быть установлена система BDE, DBC, в которых нужно прописать источник. Кроме того, в библиотеке драйверов надо посмотреть, есть ли соответствующий драйвер. Для тонкого клиента вся обработка идет на сервере. Тенденции развития СУБД. В настоящее время широкое распространение получили реляционные сервера БД. Нормализованность отношений мешает хранить сложно структурированные объекты. Поэтому тенденциями развития является синтез реляционной модели и иерархической. Направления: создание ОО СУБД и ОР СУБД, унификация организации слабоструктурированной информации в виде XML-документов с организацией их хранения. В настоящее время большинство реляционно-полных серверов включили возможность хранения XML-документов. Первое направление: ОО СУБД позволяли описывать абстрактные типы данных. Таким образом, получилась микро иерархия исходный-порожденный «таблица в таблице», связь которой осуществляется посредством указателя и соединение при выборке информации не требуется. Кроме того, появилась возможность работы с большими объектами – блобами для хранения видео, документов и веб-страниц. Кроме того, появились чисто ОО СУБД, которые позволяют во внешней памяти хранить объекты, эффективно манипулировать ими и поддерживать целостность, управление транзакциями и т.д. Но унификация не была достигнута и коммерческих СУБД не появилось. XML СУБД – с появлением языка структурированной разметки документов открылось новое, альтернативное реляционному направление хранения информации. Любую информацию (табличную, иерархическую) можно загнать в XML-структуру. Документ на XML имеет иерархическую структуру (узлы, атрибуты и значения атрибутов). Последние версии реляционных серверов обеспечивает хранение и навигацию по таким документам. При этом достигнута унификация языка. Пример: ORDER [number=”896702”]. XML стал стандартом обмена информации между ИС. Кроме того, на XML унифицируются структуры данных общего использования. Итоги раздела СУБД. Знания:
Умения:
Навыки:
Автоматизированные ИС. Сетевая обработка данных. Виды автоматизированных ИС. Методология анализа и проектирования ИС.
Сетевая обработка данных. Термин применяется для описания систем с несколькими процессорами, территориально удаленными друг от друга. Имеют место 2 причины посылки транзакции: необходимы данные, которые хранятся на другом компьютере; недостаточна мощность используемой машины. Остановимся на первой причине. Технология «клиент-сервер». Организация сетевой обработки данных базируется на этой технологии. При этом выделяются в прикладных ИС функции и данные, которые служат многим. Обслуживающая часть называется сервером. Функции: управление работой оборудования коллективного использования, управление БД (сервер БД), поддержание сервисов Интернет. При этом может быть двухзвенная архитектура, тогда на сервере БД организована вся бизнес-логика приложения, к которой посредством запросов обращается клиентская часть. Более продвинутая – трехзвенная, кроме сервера БД и клиента существует сервер приложений, на котором расположены базовые классы – платформы конкретной ИС. В трехзвенной архитектуре хранятся сущностные экземпляры, соответствующие экземплярам базовых классов. На машинах клиентов происходит оформление заданий на составление отчетов. Эта часть может быть выполнена в 2 вариантах: толстый и тонкий.
Классификация ИС по способам распределения данных.
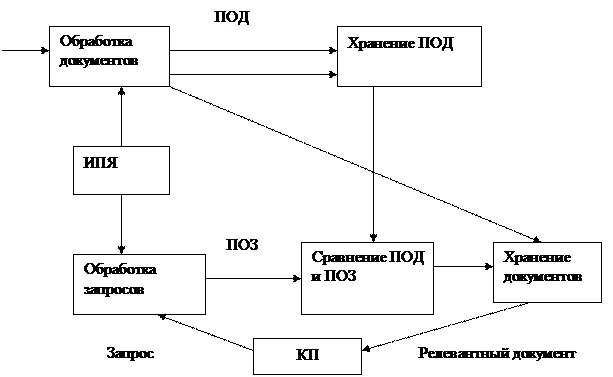
Виды автоматизированных ИС. АИС предназначены для хранения, обработки, поиска, распространения, передачи и представления информации. Документальные информационно-поисковые системы. Фактографические информационно-аналитические системы. Геоинформационные системы. В реальной практике имеется возможность пересечения систем. Документальные информационно-поисковые системы. Большая часть информации существует в виде документов – это средства закрепления различным способом на специальном материале информации о фактах, событиях, явлениях объективной действительности и мыслительной деятельности человека. Документальный поиск – это поиск сведений о документе или самого документа или его копии. Различают датоцентричные и документоцентричные объекты. Датоцентричные характеризуются строгой регулярной структурой, мелкой зернистостью и отличаются отсутствием или малым количеством смешанного содержимого (регистрационные карточки). Документоцентричные используются для восприятия человека, характеризуются менее регулярной структурой, крупнозернистыми данными и содержат мало смешанного содержимого (произведения искусства). Для хранения документоцентричных объектов в современных СУБД поддерживаются блобы. Документальные информационно-поисковые системы прошли 3 стадии развития: · середина 80-х годов – первые документальные ИПС, работа с БД началась с их создания. ИПС – совокупность программных, языковых и технических средств, предназначенных для организации сбора, хранения, поиска и постобработки информации. Для них используются коммерческие СУБД и в основу положено индексирование документов и запросов. Индексирование – процесс выражения содержимого поисковых образов документов и поисковых образов запросов на информационно-поисковом языке.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-27; просмотров: 405; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.14.6.194 (0.075 с.) |