Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основные архитектуры эвм и их сравнительная оценка 9неймановская, гарвардская, RISC, CISC и пр. )Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Основные архитектуры ЭВМ и их сравнительная оценка 9неймановская, Гарвардская, RISC, CISC и пр.)
Архитектура фон Неймана (англ. von Neumann architecture) — широко известный принцип совместного хранения программ и данных в памяти компьютера. Вычислительные системы такого рода часто обозначают термином «машина фон Неймана», однако соответствие этих понятий не всегда однозначно. В общем случае, когда говорят об архитектуре фон Неймана, подразумевают физическое отделение процессорного модуля от устройств хранения программ и данных. Наличие заданного набора исполняемых команд и программ было характерной чертой первых компьютерных систем. Сегодня подобный дизайн применяют с целью упрощения конструкции вычислительного устройства. Так, настольные калькуляторы, в принципе, являются устройствами с фиксированным набором выполняемых программ. Их можно использовать для математических расчётов, но невозможно применить для обработки текста и компьютерных игр, для просмотра графических изображений или видео. Изменение встроенной программы для такого рода устройств требует практически полной их переделки, и в большинстве случаев невозможно. Впрочем, перепрограммирование ранних компьютерных систем всё-таки выполнялось, однако требовало огромного объёма ручной работы по подготовке новой документации, перекоммутации и перестройки блоков и устройств и т. п. Всё изменила идея хранения компьютерных программ в общей памяти. Ко времени её появления использование архитектур, основанных на наборах исполняемых инструкций и представление вычислительного процесса как процесса выполнения инструкций, записанных в программе, чрезвычайно увеличило гибкость вычислительных систем в плане обработки данных. Один и тот же подход к рассмотрению данных и инструкций сделал лёгкой задачу изменения самих программ. Принципы фон Неймана В 1946 году трое учёных[1] — Артур Бёркс (англ. Arthur Burks), Герман Голдстайн и Джон фон Нейман — опубликовали статью «Предварительное рассмотрение логического конструирования электронного вычислительного устройства».[2][3] В статье обосновывалось использование двоичной системы для представления данных в ЭВМ (преимущественно для технической реализации, простота выполнения арифметических и логических операций — до этого машины хранили данные в десятичном виде[4]), выдвигалась идея использования общей памяти для программы и данных. Имя фон Неймана было достаточно широко известно в науке того времени, что отодвинуло на второй план его соавторов, и данные идеи получили название «принципы фон Неймана». Принцип двоичного кодирования Согласно этому принципу, вся информация, поступающая в ЭВМ, кодируется с помощью двоичных сигналов (двоичных цифр, битов) и разделяется на единицы, называемые словами. Принцип однородности памяти Программы и данные хранятся в одной и той же памяти. Поэтому ЭВМ не различает, что хранится в данной ячейке памяти — число, текст или команда. Над командами можно выполнять такие же действия, как и над данными. Принцип адресуемости памяти Структурно основная память состоит из пронумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка. Отсюда следует возможность давать имена областям памяти, так, чтобы к хранящимся в них значениям можно было бы впоследствии обращаться или менять их в процессе выполнения программы с использованием присвоенных имен. Принцип последовательного программного управления Предполагает, что программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в определенной последовательности. Принцип жесткости архитектуры Неизменяемость в процессе работы топологии, архитектуры, списка команд. Компьютеры, построенные на этих принципах, относят к типу фон-неймановских. Отличие от архитектуры фон Неймана В чистой архитектуре фон Неймана процессор одномоментно может либо читать инструкцию, либо читать/записывать единицу данных из/в памяти. То и другое не может происходить одновременно, поскольку инструкции и данные используют одну и ту же системную шину. Использование Первым компьютером, в котором была использована идея гарвардской архитектуры, был Марк I. Гарвардская архитектура используется в ПЛК и микроконтроллерах, таких, как Microchip PIC, Atmel AVR, Intel 4004, Intel 8051. RISC (англ. Restricted (reduced) instruction set computer [1][2] — компьютер с сокращённым набором команд) — архитектура процессора, в которой быстродействие увеличивается за счёт упрощения инструкций, чтобы их декодирование было более простым, а время выполнения — короче. Первые RISC-процессоры даже не имели инструкций умножения и деления. Это также облегчает повышение тактовой частоты и делает более эффективной суперскалярность (распараллеливание инструкций между несколькими исполнительными блоками). Наборы инструкций в более ранних архитектурах для облегчения ручного написания программ на языках ассемблеров или прямо в машинных кодах, а также для упрощения реализации компиляторов, выполняли как можно больше работы. Нередко в наборы включались инструкции для прямой поддержки конструкций языков высокого уровня. Другая особенность этих наборов — большинство инструкций, как правило, допускали все возможные методы адресации (т. н. «ортогональность системы команд (англ.)») — к примеру, и операнды, и результат в арифметических операциях доступны не только в регистрах, но и через непосредственную адресацию, и прямо в памяти. Позднее такие архитектуры были названы CISC (англ. Complex instruction set computer). Однако многие компиляторы не задействовали все возможности таких наборов инструкций, а на сложные методы адресации уходит много времени из-за дополнительных обращений к медленной памяти. Было показано, что такие функции лучше исполнять последовательностью более простых инструкций, если при этом процессор упрощается и в нём остаётся место для большего числа регистров, за счёт которых можно сократить количество обращений к памяти. В первых архитектурах, причисляемых к RISC, большинство инструкций для упрощения декодирования имеют одинаковую длину и похожую структуру, арифметические операции работают только с регистрами, а работа с памятью идёт через отдельные инструкции загрузки (load) и сохранения (store). Эти свойства и позволили лучше сбалансировать этапы конвейеризации, сделав конвейеры в RISC значительно более эффективными и позволив поднять тактовую частоту. Философия RISC В середине 1970-х разные исследователи (в частности, из IBM) показали, что большинство комбинаций инструкций и ортогональных методов адресации не использовались в большинстве программ, порождаемых компиляторами того времени. Также было обнаружено, что в некоторых архитектурах с микрокодной реализацией сложные операции зачастую были медленнее последовательности более простых операций, выполняющих те же действия. Это было вызвано, в частности, тем, что многие архитектуры разрабатывались в спешке и хорошо оптимизировался микрокод только тех инструкций, которые использовались чаще.[3] Поскольку многие реальные программы тратят большинство своего времени на выполнение простых операций, многие исследователи решили сфокусироваться на том, чтобы сделать эти операции максимально быстрыми. Тактовая частота процессора ограничена временем, которое процессор тратит на выполнение наиболее медленных шагов в процессе обработки любой инструкции; уменьшение длительности таких шагов даёт общее повышение частоты, а также зачастую ускоряет выполнение и других инструкций за счёт более эффективной конвейеризации.[4] Фокусирование на простых инструкциях и ведёт к архитектуре RISC, цель которой — сделать инструкции настолько простыми, чтобы они легко конвейеризировались и тратили не более одного такта на каждом шаге конвейера на высоких частотах. Позднее было отмечено, что наиболее значимая характеристика RISC в разделении инструкций для обработки данных и обращения к памяти — обращение к памяти идёт только через инструкции load и store, а все прочие инструкции ограничены внутренними регистрами. Это упростило архитектуру процессоров: позволило инструкциям иметь фиксированную длину, упростило конвейеры и изолировало логику, имеющую дело с задержками при доступе к памяти, только в двух инструкциях. В результате RISC-архитектуры стали называть также архитектурами load/store. [5] Недостатки CISC архитектуры
Методика построения системы комманд CISC комплементарна (противоположна, имеется в виду) другой методике - RISC. Различие этих концепций состоит в методах программирования, а не в реальной архитектуре процессора. Практически все современные процессоры эмулируют наборы команд как RISC так и CISC типа. В рабочих станциях, серверах среднего звена и персональных компьютерах используются процессоры с CISC. Наиболее распространенная архитектура команд процессоров мобильных уcтройств - SOC и мэйнфреймов - RISC. В микроконтроллерах различных устройств RISC используется в подавляющем большинстве случаев.
2.Базовая структура фон-Неймановской архитектуры ЭВМ. Порядок выполнения команды Форматы команд ЭВМ В команде, как правило, содержатся не сами операнды, а информация объект адресах ячеек памяти или регистрах, в которых они находятся. Код команды можно представить состоящим из нескольких полей, каждое из которых имеет свое функциональное назначение. В общем случае команда состоит из: ¨ операционной части (содержит код операции); ¨ адресной части (содержит адресную информацию о местонахождении обрабатываемых данных и месте хранения результатов). В свою очередь, эти части, что особенно характерно для адресной части, могут состоять из нескольких полей. Структура команды определяется составом, назначением и расположением полей в коде. Форматом команды называется заранее оговоренная структура полей ее кода с разметкой номеров разрядов (бит), определяющих границы отдельных полей команды, или с указанием числа разрядов (бит) в определенных полях, позволяющая ЭВМ распознавать составные части кода. Пример формата команды процессора i486. mod r/m - спецификатор режима адресации; r/m - регистр памяти; SS - масштабный множитель для режима масштабирования индексной адресации;
КОП - код операции; index - определяет индексный регистр; base - определяет базовый регистр.
Важной и сложной проблемой при проектировании ЭВМ является выбор структуры и форматов команды, т.е. ее длины, назначения и размерности отдельных ее полей. Естественно стремление разместить в команде в возможно более полной форме информацию о предписываемой командой операции. Однако в условиях, когда в современных ЭВМ значительно возросло число выполняемых различных операций и соответственно команд (в компьютерах с CISC-архитектурой более 200 команд) и значительно увеличилась емкость адресуемой основной памяти (32, 64 Мб), это приводит к недопустимо большой длине формата команды. Вместе с тем, для упрощения аппаратуры и повышения быстродействия ЭВМ длина формата команды должна быть по возможности короче, укладываться в машинное слово или полуслово. Решение проблемы выбора формата команды значительно усложняется в микропроцессорах, работающих с коротким словом. Проследим изменения классических структур команд. Чтобы команда содержала в явном виде всю необходимую информацию о задаваемой операции, она должна, как это показано на рис. 3.1 (б), содержать следующую информацию: А1, А2 - адреса операндов, А3 - адрес результата, А4 - адрес следующей команды (принудительная адресация команд).
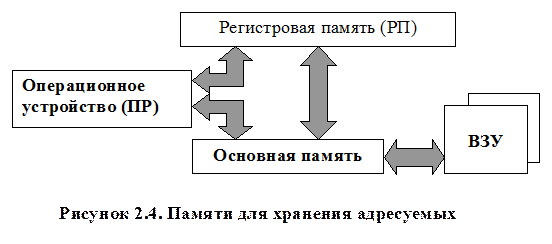
Такая структура приводит к большей длине команды и неприемлема для прямой адресации операндов основной памяти. В компьютерах с RISC-архитектурой четырехадресные команды используются для адресации операндов, хранящихся в регистровой памяти процессора. Можно установить, как это принято для большинства машин, что после выполнения данной команды, расположенной по адресу К (и занимающей L ячеек), выполняется команда из (K+L)-ой ячейки. Такой порядок выборки команды называется естественным. Он нарушается только специальными командами (передачи управления). В таком случае отпадает необходимость указывать в команде в явном виде адрес следующей команды. В трехадресной команде (рис. 3.1, в) первый и второй адреса указывают ячейки памяти, в которых расположены операнды, а третий определяет ячейку, в которую помещается результат операции. Можно условиться, что результат операции всегда помещается на место одного из операндов, например первого. Получим двухадресную команду (рис. 3.1, г), т.е. для результата используется подразумеваемый адрес. В одноадресной команде (рис. 3.1, д) подразумеваемые адреса имеют уже и результат операции и один из операндов. Один из операндов указывается адресом в команде, в качестве второго используется содержимое регистра процессора, называемого в этом случае регистром результата или аккумулятором. Результат операции записывается в тот же регистр. Наконец, в некоторых случаях возможно использование безадресных команд (рис. 3.1, е), когда подразумеваются адреса обоих операндов и результата операции, например, при работе со стековой памятью. С точки зрения программиста, наиболее естественны и удобны трехадресные команды. Обычно в ЭВМ используется несколько структур и форматов команд разной длины. Приведенные на рис. 3.1. структуры команд достаточно схематичны. В действительности адресные поля команд большей частью содержат не сами адреса, а только информацию, позволяющую определить действительные (исполнительные) адреса операндов в соответствии с используемыми в командах способами адресации. Основные способы адресации Существует два различных принципа поиска операндов в памяти: ассоциативный и адресный. Ассоциативный поиск операнда (поиск по содержанию ячейки) предполагает просмотр содержимого всех ячеек памяти для выявления кодов, содержащих заданный командой ассоциативный признак. Эти коды и выбираются из памяти в качестве искомых операндов. Адресный поиск предполагает, что искомый операнд извлекается из ячейки, номер которой формируется на основе информации в адресном поле команды. Ниже мы будем рассматривать только реализацию адресного принципа поиска операнда. Следует различать понятия исполнительного адреса и адресного кода. Адресный код – это информация об адресе операнда, содержащегося в команде. Исполнительный адрес – это номер ячейки памяти, к которой фактически производится обращение. В современных ЭВМ адресный код, как правило, не совпадает с исполнительным адресом. Таким образом, способ адресации можно определить как способ формирования исполнительного адреса операнда Аи по адресному коду команды Ак. В системах команд современных ЭВМ часто предусматривается возможность использования нескольких способов адресации операндов для одной и той же операции. Для указания способа адресации в некоторых системах команд выделяется специальное поле в команде - «метод» (указатель адресации). В этом случае любая операция может выполняться с любым способом адресации, что значительно упрощает программирование. Адресуемые в командах операнды хранятся в основной памяти (ОП) и регистровой памяти (РП), рисунок 3.2.
Рассмотрим способы адресации, применяемые в современных ЭВМ.
Относительная адресация Базирование способом суммирования. В команде адресный код Ак разделяется на две составляющие: Аб - адрес регистра в регистровой памяти, в котором хранится база Б (базовый адрес); С - код смещения относительно базового адреса (рис. 3.5). С помощью метода относительной адресации удается получить так называемый перемещаемый программный модуль, который одинаково выполняется процессором независимо от адресов, в которых он расположен. Начальный адрес программного модуля (база) загружается, при входе в модуль, в базовый регистр. Все остальные адреса программного модуля формируются через смещение относительно начального адреса (базы) модуля. Таким образом, одна и та же программа может работать с данными, расположенными в любой области памяти, без перемещения данных и без изменения текста программы только за счет изменения содержания всего одного базового регистра. Однако время выполнения каждой операции при этом возрастает. Базирование способом совмещения составляющих. Для увеличения емкости адресной ОП без увеличения длины адресного поля команды можно использовать для формирования исполнительного адреса совмещение (конкатенацию) кодов базы и смещения (рис. 3.6).
Рис. 3.5 Схема формирования относительного адреса способом суммирования кодов базы и смещения. СМ – сумматор, РАОП – регистр адреса ОП, Б – база (базовый адрес), С – смещение, Аб – адрес регистра базы
Однако в данном случае начальные адреса массивов не могут быть реализованы произвольно, а должны иметь в младших разрядах n нулей, где n – длина поля смещения. Индексная адресация. Для работы программ с массивами, требующими однотипных операций над элементами массива, удобно использовать индексную адресацию. Схема индексной адресации аналогична базированию путем суммирования (см. рис. 3.5). В этом случае адрес i-гo операнда в массиве определяется как сумма начального адреса массива (задаваемого полем смещения С) и индекса И, записанного в одном из регистров РП, называемом теперь индексным регистром. Адрес индексного регистра задается в команде полем адреса индекса — Аин (аналогично Аб). В каждом i-м цикле содержимое индексного регистра изменяется на величину постоянную (часто равную 1). Использование индексной адресации значительно упрощает программирование циклических алгоритмов. Для эффективной работы при относительной адресации применяется комбинированная индексация с базированием, при которой адрес операнда вычисляется как сумма трех величин (рис. 3.7):
Аи = Б + И + С.
Рис. 3.6.Схема формирования относительного адреса способом совмещения кодов базы и смещения.
Рис. 3.7 Схема формирования дополнительного адреса при индексной адресации и базировании: АИН - адрес индексного регистра.
Стековая адресация Стековая память (стек) является эффективным элементом современных ЭВМ, реализует неявное задание адреса операнда. Хотя адрес обращения в стек отсутствует в команде, он формируется схемой управления автоматически по специальному правилу.
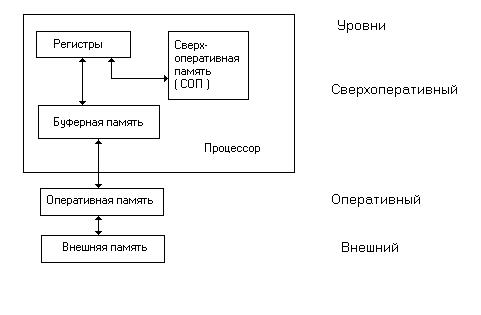
Иерархия памяти эвм Память – один из блоков ЭВМ, состоящий из ЗУ и предназначенный для запоминания, хранения и выдачи информации (алгоритма обработки данных и самих данных). Основными характеристиками отдельных устройств памяти (запоминающих устройств) являются емкость памяти, быстродействие и стоимость хранения единицы информации (бита). Быстродействие (задержка) памяти определяется временем доступа и длительностью цикла памяти. Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти. Требования к увеличению емкости и быстродействия памяти, а также к снижению ее стоимости являются противоречивыми. Чем больше быстродействие, тем технически труднее достигается и дороже обходится увеличение емкости памяти. Стоимость памяти составляет значительную часть общей стоимости ЭВМ. Как и большинство устройств ЭВМ, память имеет иерархическую структуру. Обобщённая модель такой структуры, отражающая многообразие ЗУ и их взаимодействие, представлена на рисунке 8.1. Все запоминающие устройства обладают различным быстродействием и емкостью. Чем выше уровень иерархии, тем выше быстродействие соответствующей памяти, но меньше её емкость.
Рис. 8.1. Иерархическая структура памяти К самому высокому уровню - сверхоперативному - относятся регистры управляющих и операционных блоков процессора, сверхоперативная память, управляющая память, буферная память (кэш-память). На втором оперативном уровне, более низком, находится оперативная память (ОП), служащая для хранения активных программ и данных, то есть тех программ и данных, с которыми работает ЭВМ. На следующем более низком внешнем уровне размещается внешняя память. Местная память или регистровая память процессора. Входит в состав ЦП (регистры управляющих и операционных блоков процессора) и предназначена для временного хранения информации. Она имеет малую ёмкость и наибольшее быстродействие. Построена на базе регистров общего назначения. РОН конструктивно совмещены с процессором ЭВМ. Этот тип ЗУ используется для хранения управляющих и служебных кодов, а также информации, к которой наиболее часто обращается процессор при выполнении программы. Сверхоперативная память. Иногда в архитектуре ЭВМ регистровая память организуется в виде сверхоперативного ЗУ с прямой адресацией. Такая память имеет то же назначение как и РОН, служит для хранения операндов, данных и служебной информации, необходимой процессору. Управляющая память предназначена для хранения управляющих микропрограмм процессора (см. раздел Устройство управления микропрограммного типа). Выполнена в виде постоянного ЗУ (ПЗУ) или программируемого постоянного ЗУ (ППЗУ). В системах с микропрограммным способом обработки информации УП применяется для хранения однажды записанных микропрограмм, управляющих программ, констант и т.п. Буферная память. В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти. Кэш – память от английского cashe – тайник. Она не является программно доступной. Поэтому она оказывает влияние на производительность ЭВМ, но не влияет на программирование прикладных задач. В современных ЭВМ различают кэш первого и второго уровней. Кэш первого уровня интегрирована с блоком предварительной выборки команд и данных ЦП и служит, как правило, для хранения наиболее часто используемых команд. Кэш второго уровня служит буфером между ОП и процессором. В некоторых ЭВМ существует кэш память отдельно для команд и отдельно для данных. ОП (ОЗУ) служит для хранения информации, непосредственно участвующей в вычислительном процессе (происходящем в операционном устройстве - АЛУ). Из ОЗУ в процессор поступают коды и операнды, над которыми производятся предусмотренные программой операции, из процессора в ОЗУ направляются для хранения промежуточные и конечные результаты обработки информации. ОЗУ имеет сравнительно большую ёмкость и высокое быстродействие, однако меньшее, чем ЗУ сверхоперативного уровня. Внешняя память (ВнП) используется для хранения больших массивов информации в течении продолжительного времени. Обычно ВнП не имеет непосредственной связи с процессором. Обмен информацией носит групповой характер, что значительно сокращает время обмена. ВнП обладает сравнительно низким быстродействием (поиск информации). В качестве носителя используются магнитные диски (гибкие и жёсткие), лазерные диски(CD-room) и др. Сравнительно небольшая емкость оперативной памяти (8 - 64 Мбайта) компенсируется практически неограниченной емкостью внешних запоминающих устройств. Однако эти устройства сравнительно медленные - время обращения за данными для магнитных дисков составляет десятки микросекунд. Для сравнения: цикл обращения к оперативной памяти (ОП) составляет 50 нс. Исходя из этого, вычислительный процесс должен протекать с возможно меньшим числом обращений к внешней памяти. Рост производительности ЭВМ проявляется в первую очередь в увеличении скорости работы процессора. Быстродействие ОП также растет, но все время отстает от быстродействия аппаратных средств процессора потому, что одновременно происходит опережающий рост ее емкости, что делает более трудным уменьшение времени цикла работы памяти. Вследствие этого быстродействие ОП оказывается недостаточным для обеспечения требуемой производительности ЭВМ. Проявляется это в несоответствии пропускных способностей процессора и памяти. Для выравнивания их пропускных способностей и предназначена сверхоперативная буферная память небольшой емкости (как правило, не более 512 Кбайт) и повышенного быстродействия. При обращении к блоку данных, находящемуся на оперативном уровне, его копия пересылается в сверхоперативную буферную память. Последующие обращения к этому блоку данных производится к буферной памяти. Поскольку время выборки из СОЗУ tСОЗУ много меньше времени выборки из оперативной памяти tОП, введение в структуру ЭВМ СОЗУ приводит к уменьшению эквивалентного времени обращения tэ по сравнению с временем обращения к оперативной памяти tОП: tЭ = tСОЗУ + αtОП, где α = 1- q, а q – вероятность попадания, т. е. вероятность того, что блок данных, к которому производится обращение, находится в СОЗУ.
10. Память КЭШ-назначения, основные структуры.
Кэш микропроцессора — кэш (сверхоперативная память), используемый микропроцессором компьютера для уменьшения среднего времени доступа к компьютерной памяти. Является одним из верхних уровней иерархии памяти. Кэш использует небольшую, очень быструю память (обычно типа SRAM), которая хранит копии часто используемых данных из основной памяти. Если большая часть запросов в память будет обрабатываться кэшем, средняя задержка обращения к памяти будет приближаться к задержкам работы кэша.
Когда процессору нужно обратиться в память для чтения или записи данных, он сначала проверяет, доступна ли их копия в кэше. В случае успеха проверки процессор производит операцию используя кэш, что быстрее использования более медленной основной памяти. Подробнее о задержках памяти см. Задержки (англ. SDRAM latency) SDRAM: tCAS, tRCD, tRP, tRAS.
Большинство современных микропроцессоров для компьютеров и серверов имеют как минимум три независимых кэша: кэш инструкций для ускорения загрузки машинного кода, кэш данных для ускорения чтения и записи данных, и буфер ассоциативной трансляции (TLB) для ускорения трансляции виртуальных (математических) адресов в физические, как для инструкций, так и для данных. Кэш данных часто реализуется в виде многоуровневого кэша (L1, L2, L3).
Кэш процессора 1го уровня (L1) — время доступа порядка нескольких тактов, размером в десятки килобайт Кэш процессора 2го уровня (L2) — большее время доступа (от 2 до 10 раз медленнее L1), около полумегабайта или более Кэш процессора 3го уровня (L3) — время доступа около сотни тактов, размером в несколько мегабайт (в массовых процессорах используется с недавнего времени)
Увеличение размера кэш-памяти положительно влияет на производительность почти всех приложений
Структура записи в кэше
Типичная структура записи в кэше
Блок данных (кэш-линия) содержит непосредственную копию данных из основной памяти. Адрес памяти разделяется (от старших бит к младшим) на Тег, индекс и смещение. Бит актуальности означает, что данная запись содержит актуальную (самую свежую) копию. Длина поля индекса равна бит и соответствует ряду (строке) кэша, используемой для записи. Длина смещения равна
14. Прерывания: определение, виды прерываний, порядок обслуживания внешних прерываний.
Прерывания представляют собой механизм позволяющий координировать параллельное функционирование отдельных устройств вычислительной системы и реагировать на особые состояния возникающие при работе процессора. Прерывания – это принудительная передача управления от выполняющейся программы к системе, а через неё к соответствующей программе обработки прерываний, происходящая при определенном событии. Основная цель введения прерываний – реализация асинхронного режима работы и распараллеливания работы отдельных устройств вычислительного комплекса. Механизм прерываний реализуется аппаратно-программными средствами.
Структуры систем прерываний могут быть самыми различными, но все они имеют общую особенность – прерывание непременно ведет за собой изменение порядка выполнения команд процессором. Механизм обработки прерываний включает в себя следующие элементы:
1. Установление факта прерывания (прием и идентификация сигнала на прерывание). 2. Запоминание состояния прерванного процесса (состояние процесса определяется значением счетчика команд, содержимым регистра процессора, спецификацией режима: пользовательский или привилегированный) 3. Управление аппаратно передается программе обработки прерывания. В этом случае, в счетчик команд заносится начальный адрес подпрограммы обработки прерывания, а в соответствующие регистры из слова состояния.??? 4. Сохранение информации прерванной программе, которую не удалось спасти с помощью действий аппаратуры. 5. Обработка прерывания. Работа может быть выполнена той же подпрограммой, которой было передано управление на 3-ем шаге, но в ОС чаще всего эта обработка реализуется путем вызова соотв. подпрограммы. 6. восстановление информации относящейся к прерванному процессу. 7. Возврат в прерванную программу.
Первые 3 шага реализуются аппаратными средствами, а остальные – программно. Классификация прерываний
Механизм обработки прерываний, по которому процессор прекращает выполнение команд в обычном режиме и, частично сохранив свое состояние, ответвляется на выполнение других действий, оказался настолько удобен, что зачастую разработчики процессоров используют их и для других целей. Хотя эти случаи и не относятся к операциям ввода-вывода, мы вынуждены упомянуть их здесь, для того, чтобы их не путали с прерываниями. Похожим образом процессор обрабатывает исключительные ситуации и программные прерывания.
Для внешних прерываний характерны следующие особенности: Внешнее прерывание обнаруживается процессором между выполнением команд (или между итерациями в случае выполнения цепочечных команд). Процессор при переходе на обработку прерывания сохраняет часть своего состояния перед выполнением следующей команды. Прерывания происходят асинхронно с работой процессора и непредсказуемо, программист ни коим образом не может предугадать, в каком именно месте работы программы произойдет прерывание.
Исключительные ситуации возникают во время выполнения процессором команды. К их числу относятся ситуации переполнения, деления на ноль, обращения к отсутствующей странице памяти (см. часть III) и т.д. Для исключительных ситуаций характерно следующее: Исключительные ситуации обнаруживаются процессором во время выполнения команд. Процессор при переходе на выполнение исключительной ситуации сохраняет часть своего состояния перед выполнением текущей команды. Исключительные ситуации возникают синхронно с работой процессора, но непредсказуемо для программиста, если только тот специально не заставил процессор делить некоторое число на ноль.
Программные прерывания возникают после выполнения специальных команд, как правило, для выполнения привилегированных действий внутри системных вызовов. Программные прерывания имеют следующие свойства: Программное прерывание происходит в результате выполнения специальной команды. Процессор при выполнении программного прерывания сохраняет свое состояние перед выполнением следующей команды. Программные прерывания, естественно, возникают синхронно с работой процессора и абсолютно предсказуемы программистом.
Надо честно сказать, что похожие механизмы обработки внешних прерываний, исключительных ситуаций и программных прерываний лежат целиком на совести разработчиков процессоров. Существуют вычислительные системы, где все эти три ситуации обрабатываются по-разному
Главные функции механизма прерывания:
1. Распознавание или классификация прерывания. 2. Передача управления обработчику прерывания. 3. Корректное возвращение к прерванной программе
Обычно в микропроцессорных системах запросы на прерывание могут поступать от нескольких устройств, поэтому возникает проблема идентификации устройства, приславшего запрос с тем, чтобы можно было выполнить действия по обслуживанию именно этого устройства. Для увеличения гибкости системы прерывания вводят дополнительные условия:
1) система приоритетов; 2) вложенность прерываний; 3) способ маскирования; 4) режим обслуживания прерывания; 5) способ определения начального адреса программы обработки прерывания; 6) вид сигнала от устройства ввода/вывода, вызывающего прерывание.
1. Сущность системы приоритетов состоит в том, что каждому из устройств ввода/вывода присваивается число (1,2,3,…), называемое приоритетом. При одновременном поступлении нескольких запросов на прерывание обслуживается тот из них, который имеет старший приоритет.
2. Вложенность прерываний означает, что при поступлении прерывания с некоторым приоритетом в момент обслуживания прерывания с низшим приоритетом осуществляется переход на обслуживание этого нового прерывания. После выполнения программы с более высоким приорит
|
|||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-15; просмотров: 2999; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.146.178.220 (0.013 с.) |


 Рис. 3.1. Структуры команд: а) обобщенная, б) четырехадресная, в) трехадресная, г) двухадресная, д) одноадресная, е)безадресная
Рис. 3.1. Структуры команд: а) обобщенная, б) четырехадресная, в) трехадресная, г) двухадресная, д) одноадресная, е)безадресная