Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Система массового параллелизма и многоядерные процессоры: структура, организация взаимодействия.Содержание книги
Поиск на нашем сайте
Многоядерный процессор — центральный процессор, содержащий два и более вычислительных ядра на одном процессорном кристалле или в одном корпусе.
Архитектура многоядерных систем
Многоядерные процессоры можно классифицировать по наличию поддержки когерентности кеш-памяти между ядрами. Бывают процессоры с такой поддержкой и без нее.
Способ связи между ядрами: разделяемая шина сеть (Mesh) на каналах точка-точка сеть с коммутатором общая кеш-память
Кеш-память: Во всех существующих на сегодня многоядерных процессорах кеш-памятью 1-го уровня обладает каждое ядро в отдельности, а кеш-память 2-го уровня существует в нескольких вариантах: разделяемая — расположена на одном кристалле с ядрами и доступна каждому из них в полном объёме. Используется в процессорах семейств Intel Core. индивидуальная — отдельные кеши равного объёма, интегрированные в каждое из ядер. Обмен данными из кешей 2-го уровня между ядрами осуществляется через контроллер памяти — интегрированный (Athlon 64 X2, Turion X2, Phenom) или внешний (использовался в Pentium D, в дальнейшем Intel отказалась от такого подхода).
Параллельные вычисления
Еще при появлении первых процессоров производители старались максимально увеличить их мощность. В 1995 году университетом Вашингтона была выдвинута идея поддержки «одновременной многопоточности», которая была подхвачена и реализована компанией Intel в виде технологии Hyper-Threading. На практике это выглядело как разделение одного физического CPU на два виртуальных и значительная оптимизация работы процессора. Первым микрочипом с поддержкой данной технологии стал Intel Pentium 4, выпушенный 14 ноября 2002 года. По словам представителей компании, внедрение технологии Hyper-Threading вместе с необходимым увеличением площади кристалла на 5% позволило повысить производительность чипа на 15-30%. Правда, данные цифры напрямую зависели от программ, используемых для вычислений. Если говорить о создании аналогичной технологии со стороны AMD, то здесь компания Intel значительно опередила своих конкурентов. ПРЕИМУЩЕСТВА МНОГОЯДЕРНЫХ.
Итак, создание многоядерных процессоров можно считать логическим развитием технологии HyperThreading. Производители стараются разделить работу CPU на множество потоков, которые процессорные ядра смогут обрабатывать параллельно. Однако для этого многоядерность должна полностью поддерживаться не только операционной системой, но и конкретными программами. Сейчас же, несмотря на доминирование «многоядерников» на рынке, количество оптимизированных под них приложений минимально. Обычно здесь идет речь о мультимедийных или узкоспециализированных программах, которые, в большинстве своем, «дружат» с новыми процессорами и используют всю мощь их ядер. С игровыми продуктами ситуация следующая: многие игры уже оптимизированы для работы с двумя и четырьмя ядрами, а со временем будут использоваться и многоядерные ресурсы современных CPU. Пока же наиболее практично и актуально в мире компьютеров смотрятся процессоры с четырьмя ядрами, а шести- и восьмиядерные чипы, пожалуй, стоит покупать лишь в том случае, если вы собираетесь запускать на своей системе программы с поддержкой многопоточности. МИНУСЫ МНОГОЯДЕРНЫХ CPU
Недостатков у шести- и восьмиядерных процессоров куда больше. Одним из самых важных является внушительное энергопотребление, а значит, сильное тепловыделение и высокие температуры чипа при работе под нагрузкой. Производители борются с этим, осваивая все более «тонкие» технологические процессы и разрабатывая более совершенные схемы питания. Также тормозит массовое развитие «многоядерников» уже упомянутый дефицит соответствующего программного обеспечения: большая часть потенциала микрочипа остается попросту нереализованной. Кроме того, себестоимость многоядерных процессоров пока обуславливает отнюдь не привлекательную для рядового пользователя цену, которая тоже сдерживает спрос.
Массовый параллелизм
Проблемы, присущие многопроцессорным системам с общей памятью, простым и естественным образом устраняются в системах с массовым параллелизмом. Компьютеры этого типа представляют собой многопроцессорные системы с распределенной памятью, в которых с помощью некоторой коммуникационной среды объединяются однородные вычислительные узлы (рис. 1.2).
Каждый из узлов состоит из одного или нескольких процессоров, собственной оперативной памяти, коммуникационного оборудования, подсистемы ввода/вывода, т.е. обладает всем необходимым для независимого функционирования. При этом на каждом узле может функционировать либо полноценная операционная система (как в системе RS/6000 SP2), либо урезанный вариант, поддерживающий только базовые функции ядра, а полноценная ОС работает на специальном управляющем компьютере (как в системах Cray T3E, nCUBE2).
Процессоры в таких системах имеют прямой доступ только к своей локальной памяти. Доступ к памяти других узлов реализуется обычно с помощью механизма передачи сообщений. Такая архитектура вычислительной системы устраняет одновременно как проблему конфликтов при обращении к памяти, так и проблему когерентности кэш-памяти. Это дает возможность практически неограниченного наращивания числа процессоров в системе, увеличивая тем самым ее производительность. Успешно функционируют MPP системы с сотнями и тысячами процессоров (ASCI White - 8192, Blue Mountain - 6144). Производительность наиболее мощных систем достигает 10 триллионов оп/сек (10 Tflops). Важным свойством MPP систем является их высокая степень масштабируемости. В зависимости от вычислительных потребностей для достижения необходимой производительности требуется просто собрать систему с нужным числом узлов.
На практике все, конечно, гораздо сложнее. Устранение одних проблем, как это обычно бывает, порождает другие. Для MPP систем на первый план выходит проблема эффективности коммуникационной среды. Легко сказать: "Давайте соберем систему из 1000 узлов". Но каким образом соединить в единое целое такое множество узлов? Самым простым и наиболее эффективным было бы соединение каждого процессора с каждым. Но тогда на каждом узле потребовалось бы 999 коммуникационных каналов, желательно двунаправленных. Очевидно, что это нереально. Различные производители MPP систем использовали разные топологии. В компьютерах Intel Paragon процессоры образовывали прямоугольную двумерную сетку. Для этого в каждом узле достаточно четырех коммуникационных каналов. В компьютерах Cray T3D/T3E использовалась топология трехмерного тора. Соответственно, в узлах этого компьютера было шесть коммуникационных каналов. Фирма nCUBE использовала в своих компьютерах топологию n-мерного гиперкуба. Подробнее на этой топологии мы остановимся в главе 4 при изучении суперкомпьютера nCUBE2. Каждая из рассмотренных топологий имеет свои преимущества и недостатки. Отметим, что при обмене данными между процессорами, не являющимися ближайшими соседями, происходит трансляция данных через промежуточные узлы. Очевидно, что в узлах должны быть предусмотрены какие-то аппаратные средства, которые освобождали бы центральный процессор от участия в трансляции данных. В последнее время для соединения вычислительных узлов чаще используется иерархическая система высокоскоростных коммутаторов, как это впервые было реализовано в компьютерах IBM SP2. Такая топология дает возможность прямого обмена данными между любыми узлами, без участия в этом промежуточных узлов.
Системы с распределенной памятью идеально подходят для параллельного выполнения независимых программ, поскольку при этом каждая программа выполняется на своем узле и никаким образом не влияет на выполнение других программ. Однако при разработке параллельных программ приходится учитывать более сложную, чем в SMP системах, организацию памяти. Оперативная память в MPP системах имеет 3-х уровневую структуру: кэш-память процессора; локальная оперативная память узла; оперативная память других узлов.
При этом отсутствует возможность прямого доступа к данным, расположенным в других узлах. Для их использования эти данные должны быть предварительно переданы в тот узел, который в данный момент в них нуждается. Это значительно усложняет программирование. Кроме того, обмены данными между узлами выполняются значительно медленнее, чем обработка данных в локальной оперативной памяти узлов. Поэтому написание эффективных параллельных программ для таких компьютеров представляет собой более сложную задачу, чем для SMP систем.
5. CISC-процессоры семейства 80х86 – основные блоки и их назначение. Микропроцессоры семейства Intel 80х86 относятся к микропроцессорам с конвейерной архитектурой. Это означает, что из последовательности команд управляющее устройство микропроцессора выбирает блок из нескольких байт и образует из них очередь или конвейер. По мере выборки команд для исполнения следующие байты сдвигаются к началу очереди, а очередь с конца пополняется новыми байтами так, что длина очереди постоянна. Можно предложить две группы средств защиты от трассировки. В первую группу входят средства блокировки работы самих отладчиков, делающие невозможным трассировку программы. Вторая группа средств направлена на определение факта работы программы под управлением отладчика. К первой группе средств относятся: • блокировка специальных "отладочных" прерываний процессора; Напомним, что прерывания INT 1 и INT 3 (соответственно прерывание для пошаговой работы и прерывание по однобайтовой команде INT) интенсивно используются отладчиками. Первое прерывание позволяет отладчику получать управление после выполнения каждой команды трассируемой программы. С помощью второго прерывания отладчик может устанавливать точки останова, заменяя байты программы на команду однобайтового прерывания. Защищенная от трассировки программа должна подготовить свои собственные обработчики для этих прерываний и "незаметно" для человека, занимающегося трассировкой, записать их адреса в таблицу векторов прерываний. Эти обработчики прерываний могут не делать ничего, т. е. состоять из одной команды IRET, или выполнять какие-либо действия, фиксирующие факт работы программы под контролем отладчика. В ходе трассировки программы (при ее пошаговом выполнении) вам необходимо нажимать на клавиши для перехода к очередной команде. Это можно использовать для блокировки отладчика. Запретив прерывания командой CLI и переназначив клавиатурное прерывание на себя, программа установки может выполнять какие-либо действия, не, требующие работы оператора, производящего установку, с клавиатурой. Обработчик клавиатурного прерывания защищенной от трассировки программы должен фиксировать прерывания, например установкой флага. Если же используется режим пошагового выполнения программы под управлением отладчика, отладчик разрешает клавиатурные прерывания, невзирая на то, что была выдана команда CLI. Наш обработчик клавиатурного прерывания в этом случае зафиксирует работу в режиме трассировки. Аналогично можно воспользоваться прерыванием таймера. Защищенная программа устанавливает свой обработчик для прерывания таймера, который взводит флаг в случае прихода прерывания от таймера. В подходящий момент времени она запрещает прерывания и выполняет какую-либо работу, периодически проверяя флаг.
21. Процессоры класса Pentium – общая архитектура, блок подготовки микрокоманд, потоки микрокоманд (на примере Pentium III)
Intel Pentium III (в русской разговорной речи — Интел Пентиум три) — x86-совместимый микропроцессор архитектуры Intel P6, анонсированный 26 февраля 1999 года. Ядро Pentium III представляет собой модифицированное ядро Deschutes (которое использовалось в процессорах Pentium II). По сравнению с предшественником расширен набор команд (добавлен набор инструкций SSE) и оптимизирована работа с памятью. Это позволило повысить производительность как в новых приложениях, использующих расширения SSE, так и в существующих (за счёт возросшей скорости работы с памятью). Также был введён 64-битный серийный номер, уникальный для каждого процессора.
Общие сведения Процессоры Pentium III для настольных компьютеров выпускались в трёх вариантах корпусов: SECC2, FCPGA и FCPGA2. Pentium III в корпусе SECC2 представляет собой картридж, содержащий процессорную плату («субстрат») с установленным на ней ядром процессора (во всех модификациях), а также микросхемами кэш-памяти BSRAM и tag-RAM (в процессорах, основанных на ядре Katmai). Маркировка находится на картридже. Процессор предназначен для установки в 242-контактный щелевой разъём Slot 1. В процессорах, основанных на ядре Katmai, кэш-память второго уровня работает на половине частоты ядра, а в процессорах на ядре Coppermine — на частоте ядра. Pentium III в корпусе FCPGA представляют собой подложку из органического материала зелёного цвета с установленным на ней открытым кристаллом на лицевой стороне и контактами на обратной. Также на обратной стороне корпуса (между контактами) расположено несколько SMD-элементов. Маркировка нанесена на наклейку, расположенную под кристаллом. Кристалл защищён от сколов специальным покрытием синего цвета, снижающим его хрупкость. Однако, несмотря на наличие этого покрытия, при неаккуратной установке радиатора (особенно неопытными пользователями) кристалл получал трещины и сколы (процессоры, получившие такие повреждения, на жаргоне назывались колотыми). В некоторых случаях процессор, получивший существенные повреждения кристалла (сколы до 2—3 мм с угла), продолжал работать без сбоев или с редкими сбоями. Процессор предназначен для установки в 370-контактный гнездовой разъём Socket 370. В корпусе FCPGA выпускались процессоры на ядре Coppermine. Корпус FCPGA2 отличается от FCPGA наличием теплораспределителя (металлическая крышка, закрывающая кристалл процессора), защищающего кристалл процессора от сколов (однако, его наличие снижает эффективность охлаждения[1]). Маркировка нанесена на наклейки, расположенные сверху и снизу от теплораспределителя. В корпусе FCPGA2 выпускались процессоры на ядре Tualatin, а также процессоры на поздней версии ядра Coppermine (известной как Coppermine-T). [править] Особенности архитектуры Основная статья: Intel P6 Первые процессоры архитектуры P6 в момент выхода значительно отличались от существующих процессоров. Процессор Pentium Pro отличало применение технологии динамического исполнения (изменения порядка исполнения инструкций), а также архитектура двойной независимой шины (англ. Dual Independent Bus), благодаря чему были сняты многие ограничения на пропускную способность памяти, характерные для предшественников и конкурентов. Тактовая частота первого процессора архитектуры P6 составляла 150 МГц, а последние представители этой архитектуры имели тактовую частоту 1,4 ГГц. Процессоры архитектуры P6 имели 36-разрядную шину адреса, что позволило им адресовать до 64 ГБ памяти (при этом линейное адресное пространство процесса ограничено 4 ГБ). Суперскалярный механизм исполнения инструкций с изменением их последовательности Принципиальным отличием архитектуры P6 от предшественников является RISC-ядро, работающее не с инструкциями x86, а с простыми внутренними микрооперациями. Это позволяет снять множество ограничений набора команд x86, таких как нерегулярное кодирование команд, переменная длина операндов и операции целочисленных пересылок регистр-память[2]. Кроме того, микрооперации исполняются не в той последовательности, которая предусмотрена программой, а в оптимальной с точки зрения производительности, а применение трёхконвейерной обработки позволяет исполнять несколько инструкций за один такт[3].
Суперконвейеризация Процессоры архитектуры P6 имеют конвейер глубиной 12 стадий. Это позволяет достигать более высоких тактовых частот по сравнению с процессорами, имеющими более короткий конвейер при одинаковой технологии производства. Так, например, максимальная тактовая частота процессоров AMD K6 на ядре (глубина конвейера — 6 стадий, 180 нм технология) составляет 550 МГц, а процессоры Pentium III на ядре Coppermine способны работать на частоте, превышающей 1000 МГц.
Для того, чтобы предотвратить ситуацию ожидания исполнения инструкции (и, следовательно, простоя конвейера), от результатов которого зависит выполнение или невыполнение условного перехода, в процессорах архитектуры P6 используется предсказание ветвлений. Для этого в процессорах архитектуры P6 используется сочетание статического и динамического предсказания: двухуровневый адаптивный исторический алгоритм (англ. Bimodal branch prediction) применяется в том случае, если буфер предсказания ветвлений содержит историю переходов, в противном случае применяется статический алгоритм[3][4].
Двойная независимая шина С целью увеличения пропускной способности подсистемы памяти, в процессорах архитектуры P6 применяется двойная независимая шина. В отличие от предшествующих процессоров, системная шина которых была общей для нескольких устройств, процессоры архитектуры P6 имеют две раздельные шины: Back side bus, соединяющую процессор с кэш-памятью второго уровня, и Front side bus, соединяющую процессор с северным мостом набора микросхем[3]
19. Принципы архитектуры RISC. Способы адресации и форматы команд типичные RISC-процессоров. Структура простейших RISC-процессоров.
RISC (англ. Restricted (reduced) instruction set computer[1][2] — компьютер с сокращённым набором команд) — архитектура процессора, в которой быстродействие увеличивается за счёт упрощения инструкций, чтобы их декодирование было более простым, а время выполнения — короче. Первые RISC-процессоры даже не имели инструкций умножения и деления. Это также облегчает повышение тактовой частоты и делает более эффективной суперскалярность (распараллеливание инструкций между несколькими исполнительными блоками).
Наборы инструкций в более ранних архитектурах для облегчения ручного написания программ на языках ассемблеров или прямо в машинных кодах, а также для упрощения реализации компиляторов, выполняли как можно больше работы. Нередко в наборы включались инструкции для прямой поддержки конструкций языков высокого уровня. Другая особенность этих наборов — большинство инструкций, как правило, допускали все возможные методы адресации (т. н. «ортогональность системы команд (англ.)») — к примеру, и операнды, и результат в арифметических операциях доступны не только в регистрах, но и через непосредственную адресацию, и прямо в памяти. Позднее такие архитектуры были названы CISC (англ. Complex instruction set computer).
Однако многие компиляторы не задействовали все возможности таких наборов инструкций, а на сложные методы адресации уходит много времени из-за дополнительных обращений к медленной памяти. Было показано, что такие функции лучше исполнять последовательностью более простых инструкций, если при этом процессор упрощается и в нём остаётся место для большего числа регистров, за счёт которых можно сократить количество обращений к памяти. В первых архитектурах, причисляемых к RISC, большинство инструкций для упрощения декодирования имеют одинаковую длину и похожую структуру, арифметические операции работают только с регистрами, а работа с памятью идёт через отдельные инструкции загрузки (load) и сохранения (store). Эти свойства и позволили лучше сбалансировать этапы конвейеризации, сделав конвейеры в RISC значительно более эффективными и позволив поднять тактовую частоту.
Характерные особенности RISC-процессоров Фиксированная длина машинных инструкций (например, 32 бита) и простой формат команды. Специализированные команды для операций с памятью — чтения или записи. Операции вида «прочитать-изменить-записать» отсутствуют. Любые операции «изменить» выполняются только над содержимым регистров (т. н. архитектура load-and-store). Большое количество регистров общего назначения (32 и более). Отсутствие поддержки операций вида «изменить» над укороченными типами данных — байт, 16-битное слово. Так, например, система команд DEC Alpha содержала только операции над 64-битными словами, и требовала разработки и последующего вызова процедур для выполнения операций над байтами, 16- и 32-битными словами. Отсутствие микропрограмм внутри самого процессора. То, что в CISC процессоре исполняется микропрограммами, в RISC процессоре исполняется как обыкновенный (хотя и помещённый в специальное хранилище) машинный код, не отличающийся принципиально от кода ядра ОС и приложений. Так, например, обработка отказов страниц в DEC Alpha и интерпретация таблиц страниц содержалась в так называемом PALCode (Privileged Architecture Library), помещённом в ПЗУ. Заменой PALCode можно было превратить процессор Alpha из 64-битного в 32-битный, а также изменить порядок байтов в слове и формат входов таблиц страниц виртуальной памяти.
12. Ввод-вывод в программном режиме: шинная архитектура, машинный цикл, командный цикл: варианты реализации механизма запрос-ответ.
Программно-управляемый ввод-вывод означает обмен данными с внешними устройствами с использованием команд процессора. Передача данных происходит через регистры процессора и при этом в конечном счете может реализовываться обмен собственно с процессором, обмен внешнего устройства с памятью, обмен между внешними устройствами. Прерывания обычно генерируются устройствами ввода-вывода, которые таким образом хотят обратить на себя внимание процессора
Функционирование любой вычислительной системы обычно сводится к выполнению двух видов работы: обработке информации и операций по осуществлению ее ввода-вывода.
Содержание понятий "обработка информации" и "операции ввода-вывода" зависит от того, с какой точки зрения мы смотрим на них. С точки зрения программиста, под "обработкой информации" понимается выполнение команд процессора над данными, лежащими в памяти независимо от уровня иерархии – в регистрах, кэше, оперативной или вторичной памяти. Под "операциями ввода-вывода" программист понимает обмен данными между памятью и устройствами, внешними по отношению к памяти и процессору, такими как магнитные ленты, диски, монитор, клавиатура, таймер. С точки зрения операционной системы "обработкой информации" являются только операции, совершаемые процессором над данными, находящимися в памяти на уровне иерархии не ниже, чем оперативная память. Все остальное относится к "операциям ввода-вывода". Чтобы выполнять операции над данными, временно расположенными во вторичной памяти, операционная система, сначала производит их подкачку в оперативную память, и лишь затем процессор совершает необходимые действия.
Данная лекция будет посвящена второму виду работы вычислительной системы – операциям ввода-вывода. Мы разберем, что происходит в компьютере при выполнении операций ввода-вывода, и как операционная система управляет их выполнением. При этом для простоты будем считать, что объем оперативной памяти в вычислительной системе достаточно большой, т. е. все процессы полностью располагаются в оперативной памяти, и поэтому понятие "операция ввода-вывода" с точки зрения операционной системы и с точки зрения пользователя означает одно и то же. Такое предположение не снижает общности нашего рассмотрения, так как подкачка информации из вторичной памяти в оперативную память и обратно обычно строится по тому же принципу, что и все операции ввода-вывода.
Для учета особенностей реализации процессов ввода-вывода и специфики различного типа ПУ используются три режима ввода-вывода информации: программный ввод-вывод, ввод-вывод в режиме прерываний и с прямым доступом к памяти.
Интерфейсы должны учитывать возможность реализации всех 3-х режимов ввода-вывода.
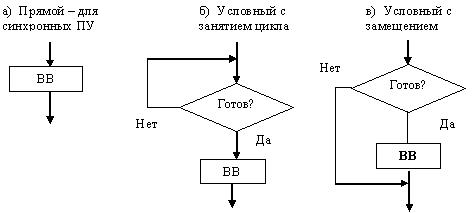
Программный ввод-вывод. Здесь инициализация и управление процессом ввода-вывода
осуществляет процессор. Существует три способа его выполнения (см. рис.1).
Первый способ – прямой, используется для синхронных ПУ, т.е. устройств, которые всегда готовы к работе и циклов ожидания не требуется. Второй – условный с занятием цикла, когда при не готовности ПУ, процессор ждет до тех пор, пока наступит его готовность. Третий – условный с совмещением. В отличие от предыдущего, процессор не ждет готовности ПУ, а переходит к продолжению программы с периодической проверкой готовности ПУ.
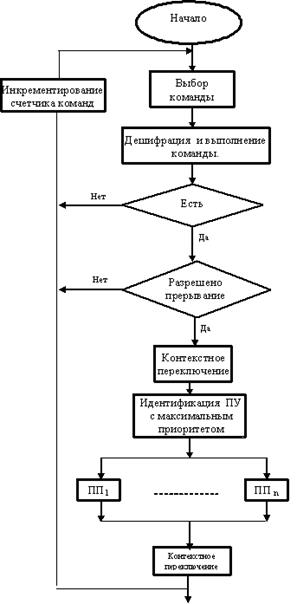
Ввод-вывод в режиме прерываний. В этом случае инициатором начала процесса ввода-вывода является ПУ. Оно, когда готово, подает сигнал процессору "запрос на прерывание". Процессор, если ПУ разрешен такой режим, завершает текущую команду и переходит к выполнению процесса ввода-вывода (см. рис. 2). Сначала он осуществляет контекстное переключение, т.е. запоминает свое состояние, чтобы можно было после продолжить программу, идентифицирует ПУ и передает управление драйверу данного ПУ (ПП), который и осуществляет ввод или вывод информации. Идентификация ПУ производится с помощью адреса вектора прерывания, который содержит номер ячейки, где хранится первая команда этого драйвера. Адрес вектора прерывания ПУ передается процессору от контроллера прерываний.
Рис.2. Ввод-вывод в режиме прерывания
Следует отметить два момента. Во-первых, ПУ должно иметь, предварительно установленное, разрешение на работу в режиме прерываний. Во-вторых, возможны коллизии, когда несколько ПУ выставляют процессору запрос прерывания. Эта коллизия разрешается с помощью механизма задания уровня приоритетов для каждого ПУ. Возможна организация вложенных прерываний, когда ПУ с большим приоритетом прерывает работу ПУ с меньшим приоритетом. Все эти моменты должен учитывать стандарт на интерфейс.
Прямой доступ к памяти (см. рис. 3). Этот режим используется для высокоскоростных ПУ. В этом режиме активным устройством является контроллер прямого доступа к памяти (КПДП). Процессор, получив от КПДП заявку на прямой доступ, прерывает свою работу и отключается от интерфейса, передавая его задатчику, т.е. КПДП. Процессор при этом не выполняет контекстного переключения, а может продолжать свою работу, если она не требует интерфейса. Управление интерфейсом переходит к КПДП, который посредством выполнения операций чтения и записи передает информацию между ОЗУ и ПУ с соответствующим заданием адресов памяти. В этом режиме используется механизм задания уровня приоритетов для тех ПУ, которые работают с прямым доступом к памяти. Этот режим также должен быть предусмотрен в интерфейсах.
Как следует из вышеизложенного, канал ввода-вывода (главный контроллер) реализует функции управления общие для всех ПУ, а контроллер внешнего интерфейса учитывает специфику интерфейса, связывающего его с соответствующим ПУ.
В компьютерах, которые работают с малой интенсивностью ввода-вывода, главный контроллер (канал) ввода-вывода обычно отсутствует, а его функции берет на себя процессор. В этом случае процессор работает непосредственно с контроллером ввода-вывода ПУ, что упрощает структуру компьютера.
При работе с высокоскоростным ПУ обычно используется режим прямого доступа к памяти. Для этого режима аппаратно реализуется специальный канал ввода-вывода в виде КПДП.
Рис. 3. Режим прямого доступа к памяти
|
||
|
|
Последнее изменение этой страницы: 2016-08-15; просмотров: 1307; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.217.170.146 (0.016 с.) |