Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
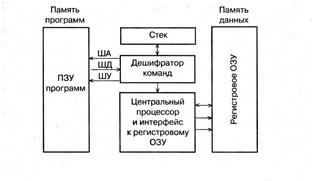
Процессоры гарвардской архитектуры: общие принципы и архитектура микроконтроллера 8051Содержание книги
Поиск на нашем сайте
Типичные операции (сложение и умножение) требуют от любого вычислительного устройства нескольких действий:
Идея, реализованная Эйкеном, заключалась в физическом разделении линий передачи команд и данных. В первом компьютере Эйкена «Марк I» для хранения инструкций использовалась перфорированная лента, а для работы с данными — электромеханические регистры. Это позволяло одновременно пересылать и обрабатывать команды и данные, благодаря чему значительно повышалось общее быстродействие компьютера. В Гарвардской архитектуре характеристики устройств памяти для инструкций и памяти для данных не требуется иметь общими. В частности, ширина слова, тайминги, технология реализации и структура адресов памяти могут различаться. В некоторых системах инструкции могут хранится в памяти только для чтения, в то время как, для сохранения данных обычно требуется память с возможностью чтения и записи. В некоторых системах требуется значительно больше памяти для инструкций, чем памяти для данных (поскольку данные обычно могут подгружатся с внешней или более медленной памяти). Такая потребность увеличивает битность (ширину) шины адреса памяти инструкций по сравнению с шиной адреса памяти данных. Однако можно выделить некоторые черты архитектуры и системы команд, общие для всех современных микроконтроллеров, это:
Микроконтроллеры обычно классифицируют по разрядности обрабатываемых чисел
Структурная организация микроконтроллера i8051. Общие характеристики. Микроконтроллер семейства 8051 имеют следующие аппаратные особенности: · внутреннее ОЗУ объемом 128 байт; · четыре двунаправленных побитно настраиваемых восьмиразрядных порта ввода-вывода; · два 16-разрядных таймера-счетчика; · встроенный тактовый генератор; · адресация 64 КБайт памяти программ и 64 Кбайт памяти данных; · две линии запросов на прерывание от внешних устройств; · интерфейс для последовательного обмена информацией с другими микроконтроллерами или персональными компьютерами. Микроконтроллер 8751 снабжен УФ ПЗУ объемом 4 Кбайт. Функциональная схема микроконтроллера семейства 8051. Микроконтроллер выполнен на основе высокоуровневой n-МОП технологии. Через четыре программируемых параллельных порта ввода/вывода и один последовательный порт микроконтроллер взаимодействует с внешними устройствами. Основу структурной схемы (рис. 1) образует внутренняя двунаправленная8-битная шина, которая связывает между собой основные узлы и устройства микроконтроллера: резидентную память программ (RPM), резидентную память данных (RDM), арифметико-логическое устройство (ALU), блок регистров специальных функций, устройство управления (CU) и порты ввода/вывода (P0-P3). 19. RISC (англ. Reduced Instruction Set Computer)— компьютер с сокращённым набором команд. Это концепция проектирования cpu, которая во главу ставит следующий принцип: более компактные и простые инструкции выполняются быстрее. Простая архитектура позволяет удешевить процессор, поднять тактовую частоту, а также распараллелить исполнение команд между несколькими блоками исполнения (т.н. суперскалярные архитектуры процессоров). Многие ранние RISC-процессоры даже не имели команд умножения и деления. Идея создания RISC процессоров пришла после того, как в 1970-х годах ученые из IBM обнаружили, что многие из функциональных особенностей традиционных ЦПУ игнорировались программистами. Отчасти это был побочный эффект сложности компиляторов. В то время компиляторы могли использовать лишь часть из набора команд процессора. Следующее открытие заключалось в том, что, поскольку некоторые сложные операции использовались редко, они, как правило, были медленнее, чем те же действия, выполняемые набором простых команд. Это происходило из-за того, что создатели процессоров тратили гораздо меньше времени на улучшение сложных команд, чем на улучшение простых. четыре основных принципа RISC-архитектуры: • каждая команда независимо от ее типа выполняется за один машинный цикл, длительность которого должна быть максимально короткой; • все команды должны иметь одинаковую длину и использовать минимум адресных форматов, что резко упрощает логику центрального управления процессором; • обращение к памяти происходит только при выполнении операций записи и чтения, вся обработка данных осуществляется исключительно в регистровой структуре процессора; • система команд должна обеспечивать поддержку языка высокого уровня. (Имеется в виду подбор системы команд, наиболее эффективной для различных языков программирования.) Как оказалось в начале 1990-х годов, RISC-архитектуры позволяют получить большую производительность, чем CISC, за счет использования суперскалярного и VLIW-подхода (инструкция cpu содержит несколько операций выполняющихся параллельно), а также за счёт возможности серьезного повышения тактовой частоты и упрощения кристалла с высвобождением площади под кеш-память, достигающую огромных размеров. Также, RISC-архитектуры позволили сильно снизить энергопотребление процессора за счет уменьшения числа транзисторов. Первое время RISC-архитектуры с трудом принимались рынком из-за отсутствия программного обеспечения для них. Эта проблема была быстро решена переносом UNIX-подобных операционных систем (SunOS) на RISC-архитектуры. Новые CPU являются CISC-процессорами с RISC-ядром!!! RISC (англ. Reduced Instruction Set Computing) — вычисления с сокращённым набором команд. Характерные особенности RISC-процессоров: 1. Фиксированная длина машинных инструкций (например, 32 бита) и простой формат команды. 2. Специализированные команды для операций с памятью — чтения или записи. Операции вида «прочитать-изменить-записать» отсутствуют. Любые операции "изменить" выполняются только над содержимым регистров (т.н. load-and-store архитектура). 3. Большое количество регистров общего назначения (32 и более). 4. Отсутствие поддержки операций вида "изменить" над укороченными типами данных - байт, 16битное слово. Так, например, система команд DEC Alpha содержала только операции над 64битными словами, и требовала разработки и последующего вызова процедур для выполнения операций над байтами, 16- и 32-битными словами. 5. Отсутствие микропрограмм внутри самого процессора. То, что в CISC процессоре исполняется микропрограммами, в RISC процессоре исполняется как обыкновенный (хотя и помещенный в специальное хранилище) машинный код, не отличающийся принципиально от кода ядра ОС и приложений. Это концепция проектирования процессоров, которая во главу ставит следующий принцип: более компактные и простые инструкции выполняются быстрее. Простая архитектура позволяет удешевить процессор, поднять тактовую частоту, а также распараллелить исполнение команд между несколькими блоками исполнения (т.н. суперскалярные архитектуры процессоров). Многие ранние RISC-процессоры даже не имели команд умножения и деления. Идея создания RISC процессоров пришла после того, как в 1970-х годах ученые из IBM обнаружили, что многие из функциональных особенностей традиционных ЦПУ игнорировались программистами. Отчасти это был побочный эффект сложности компиляторов. В то время компиляторы могли использовать лишь часть из набора команд процессора. Следующее открытие заключалось в том, что, поскольку некоторые сложные операции использовались редко, они как правило были медленнее, чем те же действия, выполняемые набором простых команд. Это происходило из-за того, что создатели процессоров тратили гораздо меньше времени на улучшение сложных команд, чем на улучшение простых. Первые RISC-процессоры были разработаны в начале 1980-х годов в Стэнфордском и Калифорнийском университетах США. Они выполняли небольшой (50 - 100) набор команд, тогда как обычные CISC (Complex Instruction Set computer) выполняли 100 - 200.
Предсказатель переходов Модуль предсказания условных переходов (англ. Branch Prediction Unit) — устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, определяющее направление ветвлений (предсказывающее, будет ли выполнен условный переход) в исполняемой программе. Предсказание ветвлений позволяет осуществлять предварительную выборку инструкций и данных из памяти, а также выполнять инструкции, находящиеся после условного перехода, до того, как он будет выполнен. Предсказатель переходов является неотъемлемой частью всех современных суперскалярных микропроцессоров, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора.[1] Существует два основных метода предсказания переходов: статический и динамический. Статическое предсказание Статические методы предсказания ветвлений являются наиболее простыми. Суть этих методов состоит в том, что различные типы переходов либо выполняются всегда, либо не выполняются никогда. В современных процессорах статические методы используются лишь в том случае, когда невозможно использование динамического предсказания. Примерами статического предсказания могут служить тривиальное предсказание переходов, применявшееся в ранних процессорах архитектуры SPARC и MIPS (предполагается, что условные переходы никогда не выполняются), а также статическое предсказание, использующееся в современных процессорах в качестве «подстраховки» (предполагается, что любой обратный переход, т.е. переход на более младшие адреса, является циклом и выполняется, а любой прямой переход, т.е. на более старшие адреса, не выполняется). Динамическое предсказание Динамические методы, широко используемые в современных процессорах, подразумевают анализ истории ветвлений. Примером динамического предсказания может служить двухуровневый адаптивный исторический алгоритм (англ. Bimodal branch prediction), использовавшийся процессорами архитектуры P6 (анализируется таблица истории переходов, содержащая младшие значимые биты адреса инструкции и соответствующую им вероятность условного перехода: «скорее всего, будет выполнен», «возможно, будет выполнен», «возможно, не будет выполнен», «скорее всего, не будет выполнен» и обновляемая после каждого перехода).
Основные архитектуры многопроцессорных систем (ОКОД, ОКМД, МКОД, МКМД) Общая классификация архитектур ЭВМ по признакам наличия параллелизма в потоках команд и данных. Была предложена в 70-е годы Майклом Флинном (Michael Flynn). Все разнообразие архитектур ЭВМ в этой таксономии Флинна сводится к четырем классам:
Типичными представителями SIMD являются векторные архитектуры. К классу MISD ряд исследователей относит конвейерные ЭВМ, однако это не нашло окончательного признания, поэтому можно считать, что реальных систем — представителей данного класса не существует. Класс MIMD включает в себя многопроцессорные системы, где процессоры обрабатывают множественные потоки данных. Отношение конкретных машин к конкретному классу сильно зависит от точки зрения исследователя. Так, конвейерные машины могут быть отнесены и к классу SISD (конвейер — единый процессор), и к классу SIMD (векторный поток данных с конвейерным процессором) и к классу MISD (множество процессоров конвейера обрабатывают один поток данных последовательно), и к классу MIMD — как выполнение последовательности различных команд (операций ступеней конвейера) на множественным скалярным потоком данных (вектором).
MIMD (англ. Multiple Instruction stream, Multiple Data stream — Множественный поток Команд, Множественный поток Данных, сокращённо МКМД) — концепция архитектуры компьютера, используемая для достижения параллелизма вычислений. Машины имеют несколько процессоров, которые функционируют асинхронно и независимо. В любой момент, различные процессоры могут выполнять различные команды над различными частями данных. MIMD-архитектуры могут быть использованы в целом ряде областей, таких как системы автоматизированного проектирования / автоматизированное производство, моделирование, а также коммуникатор связей (communication switches). MIMD машины могут быть либо с общей памятью, либо с распределяемой памятью. Эта классификация основана на том как MIMD-процессоры получают доступ к памяти. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Обработка разделена на несколько потоков, каждый с собственным аппаратным состоянием процессора, в рамках единственного определённого программным обеспечением процесса или в пределах множественных процессов. Поскольку система имеет несколько потоков, ожидающих выполнения (системные или пользовательские потоки), эта архитектура эффективно использует аппаратные ресурсы. В MIMD могут возникнуть проблемы взаимной блокировки и состязания за обладание ресурсами, так как потоки, пытаясь получить доступ к ресурсам, могут столкнуться непредсказуемым способом. MIMD требует специального кодирования в операционной системе компьютера, но не требует изменений в прикладных программах, кроме случаев когда программы сами используют множественные потоки (MIMD прозрачен для однопоточных программ под управлением большинства операционных систем, если программы сами не отказываются от управления со стороны ОС). И системное и пользовательское программное обеспечение, возможно, должны использовать программные конструкции, такие как семафоры, чтобы препятствовать тому, чтобы один поток вмешался в другой, в случае если они содержат ссылку на одни и те же данные. Такое действие увеличивает сложность кода, снижает производительность и значительно увеличивают количество необходимого тестирования, хотя обычно не настолько чтобы свести на нет преимущества многопроцессорной обработки. Подобные конфликты могут возникнуть на аппаратном уровне между процессорами, и должен обычно решаться аппаратными средствами, или с комбинацией программного обеспечения и оборудования.
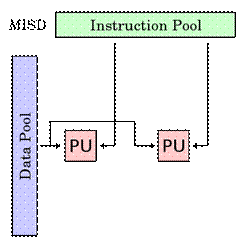
SIMD (англ. single instruction, multiple data — одиночный поток команд, множественный поток данных, ОКМД) — принцип компьютерных вычислений, позволяющий обеспечить параллелизм на уровне данных. SIMD-компьютеры состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами. Управляющий модуль принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все процессорные элементы команду, и эта команда выполняется на нескольких или на всех процессорных элементах. Каждый процессорный элемент имеет свою собственную память для хранения данных. Одним из преимуществ данной архитектуры считается то, что в этом случае более эффективно реализована логика вычислений. До половины логических инструкций обычного процессора связано с управлением выполнением машинных команд, а остальная их часть относится к работе с внутренней памятью процессора и выполнению арифметических операций. В SIMD компьютере управление выполняется контроллером, а «арифметика» отдана процессорным элементам. SIMD-процессоры называются также векторными. MISD-Архитектура (англ. M ultiple I nstruction stream, S ingle D ata stream, Множественный поток Команд, Одиночный поток Данных, МКОД) — тип архитектуры параллельных вычислений, где несколько функциональных модулей (два или более) выполняют различные операции над одними данными. Отказоустойчивые компьютеры, выполняющие одни и те же команды избыточно с целью обнаружения ошибок, как следует из определения, принадлежат к этому типу. К этому типу иногда относят конвейерную архитектуру, но не все с этим согласны, так как данные будут различаться после обработки на каждой стадии в конвейере. Некоторые относят систолический массив процессоров к архитектуре MISD. Было создано немного ЭВМ с MISD-архитектурой, поскольку MIMD и SIMD чаще всего являются более подходящими для общих методик параллельных данных. Они обеспечивают лучшее масштабирование и использование вычислительных ресурсов, чем архитектура MISD.
SISD (англ. Single Instruction, Single Data) или ОКОД (Одиночный поток Команд, Одиночный поток Данных) — архитектура компьютера, в которой один процессор выполняет один поток команд, оперируя одним потоком данных. Относится к фон-Неймановской архитектуре.
SISD компьютеры это обычные, «традиционные» последовательные компьютеры, в которых в каждый момент времени выполняется лишь одна операция над одним элементом данных (числовым или каким-либо другим значением). Большинство персональных ЭВМ до последнего времени, например, попадает именно в эту категорию. Иногда сюда относят и некоторые типы векторных компьютеров, это зависит от того, что понимать под потоком данных.
|
||||
|
|
Последнее изменение этой страницы: 2016-08-15; просмотров: 1132; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.237.229 (0.01 с.) |