Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Классификация способов адресации по наличию адресной информации в командеСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
По наличию адресной информации в команде различают явную и неявную адресацию. При явной адресации операнда в команде есть поле адреса этого операнда, в котором задается адресный код Ак. Большинство методов адресации являются явными. При неявной адресации адресное поле в команде отсутствует, адрес операнда подразумевается кодом операции. Метод неявной адресации операндов используется во всех процессорах. Основное его назначение - уменьшение длины команды за счет исключения части адресов. При этом методе код операции точно задает адрес операнда. Например, из команды исключается адрес приемника результата. При этом подразумевается, что результат в этой команде помещается на место второго операнда.
Классификация способов адресации по кратности обращения в память Широко используются следующие методы адресации операнда с различной кратностью обращения (R) в память: 1. Непосредственная (R = 0). 2. Прямая (R = 1). 3. Косвенная (R > 2). Непосредственная адресация операнда. При этом способе операнд располагается в адресном поле команды. Обращение к регистровой памяти (РП) или оперативной памяти (ОП) не производится. Таким образом, уменьшается время выполнения операции, сокращается объем памяти. Непосредственная адресация удобна для задания констант, длина которых меньше или равна длине адресного поля команды.
Прямая адресация операндов. При этом способе (рис. 3.3) адресации обращение за операндом в РП или ОП производится по адресному коду в поле команды, т.е. исполнительный адрес операнда совпадает с адресным кодом команды (Аи = Ак).
Рис.3.3. Схема прямой адресаций Обеспечивая простоту программирования, этот метод имеет существенные недостатки, так как для адресации к ячейкам памяти большой емкости (число адресов М велико) требуется «длинное» адресное поле в команде. Прямая адресация используется широко в сочетании с другими способами адресации. В частности, вся адресация к «малой» регистровой памяти ведется только с помощью прямой адресации. Косвенная адресация операндов. При этом способе адресный код команды указывает адрес ячейки памяти, в которой находится не сам операнд, а лишь адрес операнда, называемый указателем операнда. Адресация к операнду через цепочку указателей (косвенных адресов) называется косвенной. Адрес указателя, задаваемый программой, остается неизменным, а косвенный адрес может изменяться в процессе выполнения программы. Косвенная адресация, таким образом, обеспечивает переадресацию данных, т.е. упрощает обработку массивов и списковых структур данных, упрощает передачу параметров подпрограммам, но не обеспечивает перемещаемость программ в памяти (рис. 3.4).
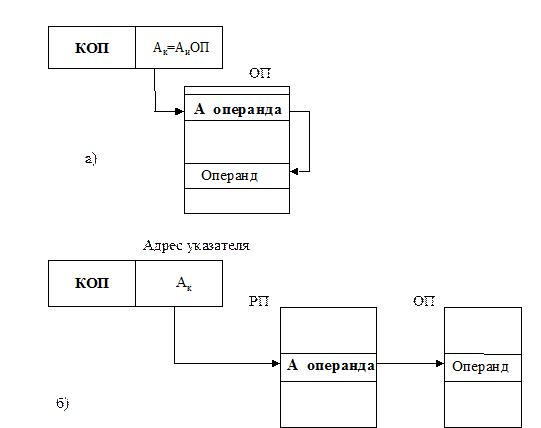
Рис. 3.4. Косвенная адресация Классификация по способу формирования исполнительных адресов ячеек памяти Способы формирования адресов ячеек памяти (Аи) можно разделить на абсолютные и относительные. Абсолютные способы формирования предполагают, что двоичный код адреса ячейки памяти - Аи может быть извлечен целиком либо из адресного поля команды (в случае прямой адресации), или из какой-либо другой ячейки (в случае косвенной адресации), никаких преобразований кода адреса не производится. Относительные способы формирования Аи предполагают, что двоичный код адреса ячейки памяти образуется из нескольких составляющих: Б - код базы, И - код индекса, С - код смещения, используемых в сочетаниях (Б и С), (И и С), (Б, И и С). При относительной адресации применяются два способа вычисления адреса Аи: - суммирование кодов составляющих адреса (Аи = Б + С; Аи - И + С; Аи = Б + И + С); - совмещение (конкатенация) кодов составляющих адреса (например Аи = Б/С).
Относительная адресация Базирование способом суммирования. В команде адресный код Ак разделяется на две составляющие: Аб - адрес регистра в регистровой памяти, в котором хранится база Б (базовый адрес); С - код смещения относительно базового адреса (рис. 3.5). С помощью метода относительной адресации удается получить так называемый перемещаемый программный модуль, который одинаково выполняется процессором независимо от адресов, в которых он расположен. Начальный адрес программного модуля (база) загружается, при входе в модуль, в базовый регистр. Все остальные адреса программного модуля формируются через смещение относительно начального адреса (базы) модуля. Таким образом, одна и та же программа может работать с данными, расположенными в любой области памяти, без перемещения данных и без изменения текста программы только за счет изменения содержания всего одного базового регистра. Однако время выполнения каждой операции при этом возрастает. Базирование способом совмещения составляющих. Для увеличения емкости адресной ОП без увеличения длины адресного поля команды можно использовать для формирования исполнительного адреса совмещение (конкатенацию) кодов базы и смещения (рис. 3.6).
Рис. 3.5 Схема формирования относительного адреса способом суммирования кодов базы и смещения. СМ – сумматор, РАОП – регистр адреса ОП, Б – база (базовый адрес), С – смещение, Аб – адрес регистра базы
Однако в данном случае начальные адреса массивов не могут быть реализованы произвольно, а должны иметь в младших разрядах n нулей, где n – длина поля смещения. Индексная адресация. Для работы программ с массивами, требующими однотипных операций над элементами массива, удобно использовать индексную адресацию. Схема индексной адресации аналогична базированию путем суммирования (см. рис. 3.5). В этом случае адрес i-гo операнда в массиве определяется как сумма начального адреса массива (задаваемого полем смещения С) и индекса И, записанного в одном из регистров РП, называемом теперь индексным регистром. Адрес индексного регистра задается в команде полем адреса индекса — Аин (аналогично Аб). В каждом i-м цикле содержимое индексного регистра изменяется на величину постоянную (часто равную 1). Использование индексной адресации значительно упрощает программирование циклических алгоритмов. Для эффективной работы при относительной адресации применяется комбинированная индексация с базированием, при которой адрес операнда вычисляется как сумма трех величин (рис. 3.7):
Аи = Б + И + С.
Рис. 3.6.Схема формирования относительного адреса способом совмещения кодов базы и смещения.
Рис. 3.7 Схема формирования дополнительного адреса при индексной адресации и базировании: АИН - адрес индексного регистра.
Стековая адресация Стековая память (стек) является эффективным элементом современных ЭВМ, реализует неявное задание адреса операнда. Хотя адрес обращения в стек отсутствует в команде, он формируется схемой управления автоматически по специальному правилу.
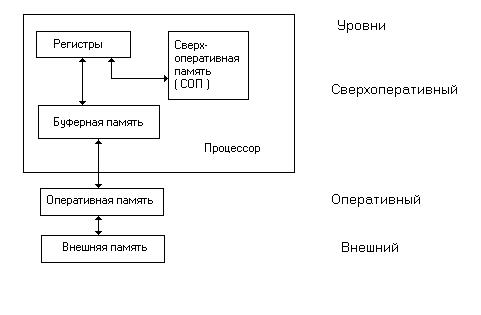
Иерархия памяти эвм Память – один из блоков ЭВМ, состоящий из ЗУ и предназначенный для запоминания, хранения и выдачи информации (алгоритма обработки данных и самих данных). Основными характеристиками отдельных устройств памяти (запоминающих устройств) являются емкость памяти, быстродействие и стоимость хранения единицы информации (бита). Быстродействие (задержка) памяти определяется временем доступа и длительностью цикла памяти. Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти. Требования к увеличению емкости и быстродействия памяти, а также к снижению ее стоимости являются противоречивыми. Чем больше быстродействие, тем технически труднее достигается и дороже обходится увеличение емкости памяти. Стоимость памяти составляет значительную часть общей стоимости ЭВМ. Как и большинство устройств ЭВМ, память имеет иерархическую структуру. Обобщённая модель такой структуры, отражающая многообразие ЗУ и их взаимодействие, представлена на рисунке 8.1. Все запоминающие устройства обладают различным быстродействием и емкостью. Чем выше уровень иерархии, тем выше быстродействие соответствующей памяти, но меньше её емкость.
Рис. 8.1. Иерархическая структура памяти К самому высокому уровню - сверхоперативному - относятся регистры управляющих и операционных блоков процессора, сверхоперативная память, управляющая память, буферная память (кэш-память). На втором оперативном уровне, более низком, находится оперативная память (ОП), служащая для хранения активных программ и данных, то есть тех программ и данных, с которыми работает ЭВМ. На следующем более низком внешнем уровне размещается внешняя память. Местная память или регистровая память процессора. Входит в состав ЦП (регистры управляющих и операционных блоков процессора) и предназначена для временного хранения информации. Она имеет малую ёмкость и наибольшее быстродействие. Построена на базе регистров общего назначения. РОН конструктивно совмещены с процессором ЭВМ. Этот тип ЗУ используется для хранения управляющих и служебных кодов, а также информации, к которой наиболее часто обращается процессор при выполнении программы. Сверхоперативная память. Иногда в архитектуре ЭВМ регистровая память организуется в виде сверхоперативного ЗУ с прямой адресацией. Такая память имеет то же назначение как и РОН, служит для хранения операндов, данных и служебной информации, необходимой процессору. Управляющая память предназначена для хранения управляющих микропрограмм процессора (см. раздел Устройство управления микропрограммного типа). Выполнена в виде постоянного ЗУ (ПЗУ) или программируемого постоянного ЗУ (ППЗУ). В системах с микропрограммным способом обработки информации УП применяется для хранения однажды записанных микропрограмм, управляющих программ, констант и т.п. Буферная память. В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти. Кэш – память от английского cashe – тайник. Она не является программно доступной. Поэтому она оказывает влияние на производительность ЭВМ, но не влияет на программирование прикладных задач. В современных ЭВМ различают кэш первого и второго уровней. Кэш первого уровня интегрирована с блоком предварительной выборки команд и данных ЦП и служит, как правило, для хранения наиболее часто используемых команд. Кэш второго уровня служит буфером между ОП и процессором. В некоторых ЭВМ существует кэш память отдельно для команд и отдельно для данных. ОП (ОЗУ) служит для хранения информации, непосредственно участвующей в вычислительном процессе (происходящем в операционном устройстве - АЛУ). Из ОЗУ в процессор поступают коды и операнды, над которыми производятся предусмотренные программой операции, из процессора в ОЗУ направляются для хранения промежуточные и конечные результаты обработки информации. ОЗУ имеет сравнительно большую ёмкость и высокое быстродействие, однако меньшее, чем ЗУ сверхоперативного уровня. Внешняя память (ВнП) используется для хранения больших массивов информации в течении продолжительного времени. Обычно ВнП не имеет непосредственной связи с процессором. Обмен информацией носит групповой характер, что значительно сокращает время обмена. ВнП обладает сравнительно низким быстродействием (поиск информации). В качестве носителя используются магнитные диски (гибкие и жёсткие), лазерные диски(CD-room) и др. Сравнительно небольшая емкость оперативной памяти (8 - 64 Мбайта) компенсируется практически неограниченной емкостью внешних запоминающих устройств. Однако эти устройства сравнительно медленные - время обращения за данными для магнитных дисков составляет десятки микросекунд. Для сравнения: цикл обращения к оперативной памяти (ОП) составляет 50 нс. Исходя из этого, вычислительный процесс должен протекать с возможно меньшим числом обращений к внешней памяти. Рост производительности ЭВМ проявляется в первую очередь в увеличении скорости работы процессора. Быстродействие ОП также растет, но все время отстает от быстродействия аппаратных средств процессора потому, что одновременно происходит опережающий рост ее емкости, что делает более трудным уменьшение времени цикла работы памяти. Вследствие этого быстродействие ОП оказывается недостаточным для обеспечения требуемой производительности ЭВМ. Проявляется это в несоответствии пропускных способностей процессора и памяти. Для выравнивания их пропускных способностей и предназначена сверхоперативная буферная память небольшой емкости (как правило, не более 512 Кбайт) и повышенного быстродействия. При обращении к блоку данных, находящемуся на оперативном уровне, его копия пересылается в сверхоперативную буферную память. Последующие обращения к этому блоку данных производится к буферной памяти. Поскольку время выборки из СОЗУ tСОЗУ много меньше времени выборки из оперативной памяти tОП, введение в структуру ЭВМ СОЗУ приводит к уменьшению эквивалентного времени обращения tэ по сравнению с временем обращения к оперативной памяти tОП: tЭ = tСОЗУ + αtОП, где α = 1- q, а q – вероятность попадания, т. е. вероятность того, что блок данных, к которому производится обращение, находится в СОЗУ.
10. Память КЭШ-назначения, основные структуры.
Кэш микропроцессора — кэш (сверхоперативная память), используемый микропроцессором компьютера для уменьшения среднего времени доступа к компьютерной памяти. Является одним из верхних уровней иерархии памяти. Кэш использует небольшую, очень быструю память (обычно типа SRAM), которая хранит копии часто используемых данных из основной памяти. Если большая часть запросов в память будет обрабатываться кэшем, средняя задержка обращения к памяти будет приближаться к задержкам работы кэша.
Когда процессору нужно обратиться в память для чтения или записи данных, он сначала проверяет, доступна ли их копия в кэше. В случае успеха проверки процессор производит операцию используя кэш, что быстрее использования более медленной основной памяти. Подробнее о задержках памяти см. Задержки (англ. SDRAM latency) SDRAM: tCAS, tRCD, tRP, tRAS.
Большинство современных микропроцессоров для компьютеров и серверов имеют как минимум три независимых кэша: кэш инструкций для ускорения загрузки машинного кода, кэш данных для ускорения чтения и записи данных, и буфер ассоциативной трансляции (TLB) для ускорения трансляции виртуальных (математических) адресов в физические, как для инструкций, так и для данных. Кэш данных часто реализуется в виде многоуровневого кэша (L1, L2, L3).
Кэш процессора 1го уровня (L1) — время доступа порядка нескольких тактов, размером в десятки килобайт Кэш процессора 2го уровня (L2) — большее время доступа (от 2 до 10 раз медленнее L1), около полумегабайта или более Кэш процессора 3го уровня (L3) — время доступа около сотни тактов, размером в несколько мегабайт (в массовых процессорах используется с недавнего времени)
Увеличение размера кэш-памяти положительно влияет на производительность почти всех приложений
Структура записи в кэше
Типичная структура записи в кэше
Блок данных (кэш-линия) содержит непосредственную копию данных из основной памяти. Адрес памяти разделяется (от старших бит к младшим) на Тег, индекс и смещение. Бит актуальности означает, что данная запись содержит актуальную (самую свежую) копию. Длина поля индекса равна бит и соответствует ряду (строке) кэша, используемой для записи. Длина смещения равна
14. Прерывания: определение, виды прерываний, порядок обслуживания внешних прерываний.
Прерывания представляют собой механизм позволяющий координировать параллельное функционирование отдельных устройств вычислительной системы и реагировать на особые состояния возникающие при работе процессора. Прерывания – это принудительная передача управления от выполняющейся программы к системе, а через неё к соответствующей программе обработки прерываний, происходящая при определенном событии. Основная цель введения прерываний – реализация асинхронного режима работы и распараллеливания работы отдельных устройств вычислительного комплекса. Механизм прерываний реализуется аппаратно-программными средствами.
Структуры систем прерываний могут быть самыми различными, но все они имеют общую особенность – прерывание непременно ведет за собой изменение порядка выполнения команд процессором. Механизм обработки прерываний включает в себя следующие элементы:
1. Установление факта прерывания (прием и идентификация сигнала на прерывание). 2. Запоминание состояния прерванного процесса (состояние процесса определяется значением счетчика команд, содержимым регистра процессора, спецификацией режима: пользовательский или привилегированный) 3. Управление аппаратно передается программе обработки прерывания. В этом случае, в счетчик команд заносится начальный адрес подпрограммы обработки прерывания, а в соответствующие регистры из слова состояния.??? 4. Сохранение информации прерванной программе, которую не удалось спасти с помощью действий аппаратуры. 5. Обработка прерывания. Работа может быть выполнена той же подпрограммой, которой было передано управление на 3-ем шаге, но в ОС чаще всего эта обработка реализуется путем вызова соотв. подпрограммы. 6. восстановление информации относящейся к прерванному процессу. 7. Возврат в прерванную программу.
Первые 3 шага реализуются аппаратными средствами, а остальные – программно. Классификация прерываний
Механизм обработки прерываний, по которому процессор прекращает выполнение команд в обычном режиме и, частично сохранив свое состояние, ответвляется на выполнение других действий, оказался настолько удобен, что зачастую разработчики процессоров используют их и для других целей. Хотя эти случаи и не относятся к операциям ввода-вывода, мы вынуждены упомянуть их здесь, для того, чтобы их не путали с прерываниями. Похожим образом процессор обрабатывает исключительные ситуации и программные прерывания.
Для внешних прерываний характерны следующие особенности: Внешнее прерывание обнаруживается процессором между выполнением команд (или между итерациями в случае выполнения цепочечных команд). Процессор при переходе на обработку прерывания сохраняет часть своего состояния перед выполнением следующей команды. Прерывания происходят асинхронно с работой процессора и непредсказуемо, программист ни коим образом не может предугадать, в каком именно месте работы программы произойдет прерывание.
Исключительные ситуации возникают во время выполнения процессором команды. К их числу относятся ситуации переполнения, деления на ноль, обращения к отсутствующей странице памяти (см. часть III) и т.д. Для исключительных ситуаций характерно следующее: Исключительные ситуации обнаруживаются процессором во время выполнения команд. Процессор при переходе на выполнение исключительной ситуации сохраняет часть своего состояния перед выполнением текущей команды. Исключительные ситуации возникают синхронно с работой процессора, но непредсказуемо для программиста, если только тот специально не заставил процессор делить некоторое число на ноль.
Программные прерывания возникают после выполнения специальных команд, как правило, для выполнения привилегированных действий внутри системных вызовов. Программные прерывания имеют следующие свойства: Программное прерывание происходит в результате выполнения специальной команды. Процессор при выполнении программного прерывания сохраняет свое состояние перед выполнением следующей команды. Программные прерывания, естественно, возникают синхронно с работой процессора и абсолютно предсказуемы программистом.
Надо честно сказать, что похожие механизмы обработки внешних прерываний, исключительных ситуаций и программных прерываний лежат целиком на совести разработчиков процессоров. Существуют вычислительные системы, где все эти три ситуации обрабатываются по-разному
Главные функции механизма прерывания:
1. Распознавание или классификация прерывания. 2. Передача управления обработчику прерывания. 3. Корректное возвращение к прерванной программе
Обычно в микропроцессорных системах запросы на прерывание могут поступать от нескольких устройств, поэтому возникает проблема идентификации устройства, приславшего запрос с тем, чтобы можно было выполнить действия по обслуживанию именно этого устройства. Для увеличения гибкости системы прерывания вводят дополнительные условия:
1) система приоритетов; 2) вложенность прерываний; 3) способ маскирования; 4) режим обслуживания прерывания; 5) способ определения начального адреса программы обработки прерывания; 6) вид сигнала от устройства ввода/вывода, вызывающего прерывание.
1. Сущность системы приоритетов состоит в том, что каждому из устройств ввода/вывода присваивается число (1,2,3,…), называемое приоритетом. При одновременном поступлении нескольких запросов на прерывание обслуживается тот из них, который имеет старший приоритет.
2. Вложенность прерываний означает, что при поступлении прерывания с некоторым приоритетом в момент обслуживания прерывания с низшим приоритетом осуществляется переход на обслуживание этого нового прерывания. После выполнения программы с более высоким приоритетом производится возврат к выполнению программы с низким приоритетом, а после ее завершения осуществляется возврат к выполнению основной программы.
3. Маскирование применяется для запрета прерывания выполняемой программы. Замаскированное устройство не чувствительно к запросам на прерывание. Эти запросы либо теряются, либо запоминаются, и будут обслужены, когда система выйдет из состояния маскирования. Для указания маскированных запросов служит регистр масок. Обычно процессор имеет 1 немаскируемый вход и 1 или несколько маскируемых. Немаскируемый вход используется для обслуживания экстренных ситуаций, например, пропадание питания. Для расширения числа обслуживаемых прерываний используется специальное устройство — контроллер прерывания. В его состав обычно входят: регистр запроса прерывания, дешифратор приоритетов, регистр масок, регистр обслуживаемых прерываний и регистр адресов прерываний. Регистр адресов прерываний позволяет реализовать векторную систему прерывания. Контроллер представляет из себя устройство, на которое подаются запросы. INT – сигнал запроса прерывания процессору. INTA – подтверждение прерывания от процессора. По сигналу INTA из контроллера прерывания считывается вектор или адрес подпрограммы прерывания по шине данных
4. По режиму обслуживания прерывания различают: 1) режим прерываний с последующим программным опросом; 2) режим векторной системы прерывания; 3) режим программного опроса регистра состояния. В схеме прерываний с программным опросом все запросы на прерывание поступают по одной управляющей линии. Эта линия является выходом схемы ИЛИ, на входы которой поступают запросы от индивидуальных устройств. У каждого устройства есть порт состояния, хранящий бит запроса прерывания. После поступления прерывания микропроцессор опрашивает по порядку все внешние устройства на предмет наличия запроса прерывания. Главный недостаток – это время, затрачиваемое программой на опрос состояния отдельных устройств. В векторной системе прерывания устройство, вызвавшее прерывание, идентифицируется с помощью внешних по отношению к микропроцессору схем. В этом режиме процессор после получения сигнала запроса прерывания считывает начальный адрес программы обработки прерывания. Этот адрес называется еще вектором прерывания. Обычно этот адрес выдает контроллер прерывания. Режим опроса регистра состояния: При работе в режиме опроса регистра состояния прерывания процессора запрещены. И для определения наличия поступления запроса от внешнего устройства ему приходится их опрашивать. Этот режим характеризуется большим временем реакции на прерывание, но обеспечивает более простое написание программ обработки.
5. По способу определения начального адреса программы обслуживания прерывания различают прерывания, у которых начальный адрес всегда находится в строго закрепленной за ним ячейке памяти, и прерываний, начальный адрес подпрограммы обработки которых определяется числом, подаваемым в процессор по его требованию.
6. По виду сигнала различают входы прерывания по уровню и по фронту. В первом случае, если поступил сигнал прерывания, а перехода на программу обработки не произошло (вход был замаскирован или в это время выполнялась подпрограмма с более высоким приоритетом) за время его присутствия, то по его снятию запрос теряется. С другой стороны, если за время присутствия сигнала запроса прерывания была выполнена программа его обработки, а он не снялся, то вновь осуществится переход на эту программу. Прерывания по фронту запоминаются в регистре запросов и сбрасываются самим процессором после обслуживания запроса. Таким образом, система прерывания микропроцессорного устройства может выглядеть следующим образом.
Переход от прерванной программе к обработчику и обратно должен производится как можно быстрее. Одним из быстрых методов является использование таблицы сод. перечень всех допустимых для компьютера прерываний и адреса соотв. обработчиков. Для корректного возвращения к прерванной программе, перед передачей управления обработчику, содержимое регистров процессора запоминается либо в памяти с прямым доступом либо в системном стеке.
Обслуживание прерываний. Наличие сигнала прерывания не обязательно должно вызывать прерывание исполняющейся программы, процессор может обладать системой защиты от прерываний: отключение системы прерываний либо запрет или маскирование отдельных сигналов прерываний. Программное управление этими средствами позволяет ОС регулировать обработку сигналов прерывания. Процессор может обрабатывать прерывания сразу по приходу прерывания, откладывать их обработку на некоторое время, полностью игнорировать. Обычно операции прерывания выполняются только после завершения выполнения текущей команды. Поскольку сигналы прерывания возникают в произвольные моменты времени, то на момент прерывания может существовать несколько сигналов прерывания, которые могут быть обработаны только последовательно. Чтобы обработать сигналы прерывания в разумном порядке им присваиваются приоритеты. Программы управляя специальными регистрами маски, позволяют реализовать различные дисциплины обслуживания:
1) с относительным приоритетом. При этом обслуживание не прерывается даже при наличии запросов с более высокими приоритетами. после окончания обслуживания данного запроса (текущего) обслуживается запрос с наивысшим приоритетом. для организации такой дисциплины необходимо в программе обслуживания данного запроса наложить маски на все остальные прерывания или просто отключить систему прерываний.
2)с абсолютным приоритетом. Всегда обслуживаются задачи с наивысшим приоритетом. Для реализации этой дисциплины при запросе на обработку прерываний маскируются все прерывания с низшим приоритетом. При этом возможно многоуровневое прерывание, т. е. прерывание программы обработки прерывания. Число уровней прерывания в этом режиме изменяется и зависит от приоритета запроса по принципу стека: LCFS – last come first served, т. е. запрос с более высоким приоритетом может прервать запрос с более низким приоритетом. При появлении запроса на прерывание система прерываний идентифицирует сигнал и если прерывания разрешены, то управление передается на соотв. программу обработки прерываний.
15. Приоритетные прерывания. Контроллер прерываний.
Поскольку сигналы прерывания возникают в произвольные моменты времени, то на момент прерывания может существовать несколько сигналов прерывания, которые могут быть обработаны только последовательно. Чтобы обработать сигналы прерывания в разумном порядке им присваиваются приоритеты. Программы управляя специальными регистрами маски, позволяют реализовать различные дисциплины обслуживания:
1) с относительным приоритетом. При этом обслуживание не прерывается даже при наличии запросов с более высокими приоритетами. после окончания обслуживания данного запроса (текущего) обслуживается запрос с наивысшим приоритетом. для организации такой дисциплины необходимо в программе обслуживания данного запроса наложить маски на все остальные прерывания или просто отключить систему прерываний. 2) с абсолютным приоритетом. Всегда обслуживаются задачи с наивысшим приоритетом. Для реализации этой дисциплины при запросе на обработку прерываний маскируются все прерывания с низшим приоритетом. При этом возможно многоуровневое прерывание, т. е. прерывание программы обработки прерывания. Число уровней прерывания в этом режиме изменяется и зависит от приоритета запроса по принципу стека: LCFS – last come first served, т. е. запрос с более высоким приоритетом может прервать запрос с более низким приоритетом. При появлении запроса на прерывание система прерываний идентифицирует сигнал и если прерывания разрешены, то управление передается на соотв. программу обработки прерываний.
Программируемый контроллер прерываний 8259 предназначен для обработки до восьми приоритетных уровней прерываний. Возможно каскадирование микросхем, при этом общее число уровней прерываний будет достигать 64.
Контроллер 8259 имеет несколько режимов работы, которые устанавливаются программным путем. В персональных компьютерах XT и AT за первоначальную установку режимов работы микросхем 8259 отвечает BIOS. У программиста скорее всего не возникнет потребность перепрограммировать контроллер - это небезопасно, так как неправильное программирование контроллера приведет к нарушению логики работы всей системы.
Однако часто возникает необходимость изменения текущего режима работы (запрет или разрешение прерываний определенного или всех уровней, обработка конца прерывания) или опроса состояния внутренних регистров контроллера. Для этого необходимо ознакомиться со справочными данными на микросхему 8259, где детально описано как первоначальное программирование контроллера, так и управление им во время работы.
Каждому приоритетному уровню прерывания микросхема ставит в соответствие определенный, задаваемый программно, номер прерывания. В разделе книги, посвященном особенностям обработки аппаратных прерываний, приводится такое соответствие для машин типа XT и AT.
Если контроллеры 8259 каскадированы, то ведомой микросхеме присваивается код (выдачей в микросхему соответствующего командного слова). Этот код равен номеру входа IRQ ведущей микросхемы, с которым соединен выход запроса прерывания INT ведомой микросхемы. Внутри микросхемы приоритет зависит от номера IRQ и задается программно. Для компьютеров XT и AT самым высоким приоритетом внутри группы, обслуживаемой каждым контроллером, является вход IRQ0. Однако возможно программное изменение приоритетов в рамках так называемого приоритетного кольца. При этом дно приоритетного кольца имеет самый низкий приоритет.
Для обработки прерываний контроллер имеет несколько внутренних регистров. Это регистр запросов прерываний IRR, регистр обслуживания прерываний ISR, регистр маски прерываний IMR. В регистре IRR хранятся запросы на обслуживание прерываний от аппаратуры. После выработки сигнала прерывания центральному процессору соответствующий разряд регистра ISR устанавливается в единичное состояние, что блокирует обслуживание всех запросов с равным или более низким приоритетом. Устранить эту блокировку можно либо сбросом соответствующего бита в ISR, либо командой специального маскирования.
Имеется два типа команд, посылаемых программой в контроллер 8259 - команды инициализации и команды операции. Возможны следующие операции: индивидуальное маскирование запросов прерывания; специальное маскирование обслуженных запросов; установка статуса уровней приоритета (по установке исходного состояния, по обслуженному запросу, по указанию); операции конца прерывания (обычный конец прерывания, специальный конец прерывания, автоматический конец прерывания); чтение регистров IRR, ISR, IMR.
Мы не будем подробно описывать команды инициализации контроллера 8259, так как программистам они скорее всего не понадобятся. Желающих разобраться во всех тонкостях задания начального режима работы контроллера прерываний мы отсылаем к справочной литературе по микросхеме 8259 или ее отечественному аналогу.
Рассмотрим команды операций. Существуют три типа команд операций: Маскирование запросов прерывания. Команды обработки конца прерывания. Опрос регистров и специальное маскирование.
Байты команды маскирования запросов прерывания выводятся соответственно в порты 21h и A1h для первого и второго контроллера 8259 компьютера AT. Команды операций второго и третьего типа используют порты с адресами 20h и A0h.
Маскирование запросов прерываний мы уже описывали в главе, посвященной прерываниям. Для маскирования какого-либо уровня прерывания надо записать в регистр маски IMR по адресу 21h или A1h единицу в соответствующий разряд регистра.
Команда специального конца прерывания устанавливает в нулевое состояние тот разряд ISR, номер которого указан в разрядах B0...B2 команды.
Команда циклического сдвига уровней приоритета с обычным концом прерывания устанавливает в ноль разряд ISR, соответствующий последнему обслуженному запросу и этому же номеру запроса присваивается низший уровень приоритета.
Аналогично работает команда циклического сдвига уровней приоритета со специальным концом прерывания, только низший уровень приоритета присваивается тому входу IRQ, номер которого указан в разрядах B0...B2 команды.
Команда циклического сдвига уровней приоритета устанавливает статус уровней приоритета без выполнения операции конца прерывания. Разряды B0...B2 указывают дно приоритетного кольца.
После выполнения команд разрешения чт
|
|||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-15; просмотров: 1322; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.149.243.29 (0.017 с.) |