Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Информационные хранилища (Data Warehouse).Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Информационное хранилище (Data Warehouse) – это самообучающаяся ИИС, которая позволяет извлекать знания из баз данных и создавать специально-организованные базы знаний. В отличие от интеллектуальной базы данных информационное хранилище представляет собой хранилище извлеченной значимой информации из оперативной базы данных, которое предназначено для оперативного анализа данных (реализации OLAP - технологии). Извлечение знаний из баз данных осуществляется регулярно, например, ежедневно. Типичными задачами оперативного ситуационного анализа являются: v Определение профиля потребителей конкретного товара; v Предсказание изменений ситуации на рынке; v Анализ зависимостей признаков ситуаций (корреляционный анализ). Для извлечения значимой информации из баз данных используются специальные методы (Data Mining или Knowledge Discovery), основанные или на применении многомерных статистических таблиц, или индуктивных методов построения деревьев решений, или нейронных сетей. Формулирование запроса осуществляется в результате применения интеллектуального интерфейса, позволяющего в диалоге гибко определять значимые признаки анализа. Применение информационных хранилищ на практике все в большей степени демонстрирует необходимость интеграции интеллектуальных и традиционных информационных технологий, комбинированное использование различных методов представления и вывода знаний, усложнение архитектуры информационных систем.
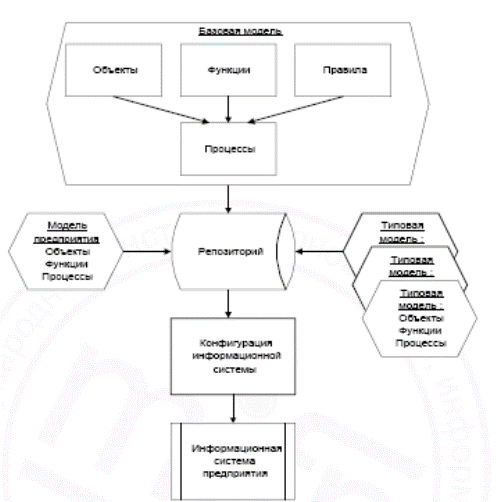
Адаптивные системы Общие сведения Адаптивная информационная система -это ИИС, которая изменяет свою структуру в соответствии с изменением модели проблемной области. Ядром адаптивной ИС является постоянно развиваемая модель проблемной области (предприятия), поддерживаемая в специальной базе знаний - репозитории, на основе которого осуществляется генерация или конфигурация программного обеспечения. Таким образом, проектирование и адаптация ИС сводится, прежде всего, к построению модели проблемной области и ее своевременной корректировке. При проектировании информационной системы обычно используются два подхода: оригинальное или типовое проектирование. Первый подход предполагает разработку информационной системы “с чистого листа” в соответствии с требованиями объекта, второй подход – адаптацию типовых разработок к особенностям объекта. Первый подход, как правило, реализуется на основе применения систем автоматизированного проектирования ИС или CASE-технологий, например, таких как, Designer 2000 (Oracle), SilverRun (SilverRun Technology), Natural LightStorm (Software AG) и др. Второй подход – на основе применения систем компонентного проектирования ИС, например, таких как R/3 (SAP), BAAN IV (Baan Corp), Prodis (Software AG), Галактика (Новый Атлант) и др. Репозиторий -хранилище метазнаний о структуре фактуального и операционного знания или модели проблемной области. Case-технология - технология, позволяющая генерировать информационную систему на основе модели проблемной области, хранимой в репозитории. Компонентная технология - технология, позволяющая конфигурировать информационную систему из готовых типовых компонентов на основе модели проблемной области, хранимой в репозитории. Отличие подходов заключается в следующем: при использовании CASE-технологии на основе репозитория при возникновении изменения выполняется каждый раз генерация (пересоздание) программного обеспечения, а при использовании компонентной технологии - конфигурация программ и только в редких случаях их переработка с помощью CASE - средств, например, использования языков четвертого поколения (4GL). В обобщенном виде конфигурация адаптивных информационных систем на основе компонентной технологии представлена на рис 2.4.
Рис. 2.4 Нейронные сети Иску́сственные нейро́нные се́ти (ИНС) ‒ математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей ‒ сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети Маккалока и Питтса [1]. Впоследствии, после разработки алгоритмов обучения, получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др. ИНС представляют собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты, особенно в сравнении с процессорами, используемыми в персональных компьютерах. Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие локально простые процессоры вместе способны выполнять довольно сложные задачи. С точки зрения машинного обучения, нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, методов кластеризации и т. п. С математической точки зрения, обучение нейронных сетей ‒ это многопараметрическая задача нелинейной оптимизации. С точки зрения кибернетики, нейронная сеть используется в задачах адаптивного управления и как алгоритмы для робототехники. С точки зрения развития вычислительной техники и программирования, нейронная сеть ‒ способ решения проблемы эффективного параллелизма [2]. А с точки зрения искусственного интеллекта, ИНС является основой философского течения коннективизма и основным направлением в структурном подходе по изучению возможности построения (моделирования) естественного интеллекта с помощью компьютерных алгоритмов.
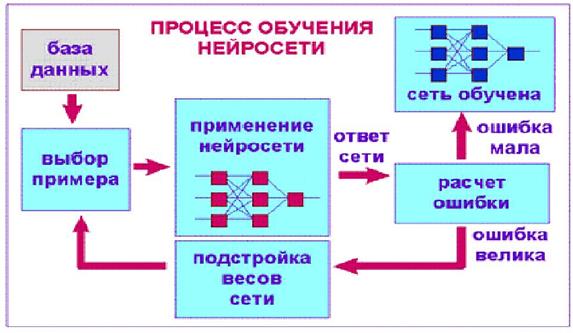
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения ‒ одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение. Это значит, что в случае успешного обучения сеть сможет вернуть верный результат на основании данных, которые отсутствовали в обучающей выборке, а также неполных и/или «зашумленных», частично искаженных данных. Этапы решения задач: 1. Сбор данных для обучения; 2. Подготовка и нормализация данных; 3. Выбор топологии сети; 4. Экспериментальный подбор характеристик сети; 5. Экспериментальный подбор параметров обучения; 6. Собственно обучение; 7. Проверка адекватности обучения; 8. Корректировка параметров, окончательное обучение.
Сбор данных для обучения Выбор данных для обучения сети и их обработка является самым сложным этапом решения задачи. Набор данных для обучения должен удовлетворять нескольким критериям: Репрезентативность ‒ данные должны иллюстрировать истинное положение вещей в предметной области; Непротиворечивость ‒ противоречивые данные в обучающей выборке приведут к плохому качеству обучения сети. Выбор топологии сети Выбирать тип сети следует исходя из постановки задачи и имеющихся данных для обучения. 3. После выбора общей структуры нужно экспериментально подобрать параметры сети. Для сетей, подобных перцептрону, это будет число слоев, число блоков в скрытых слоях (для сетей Ворда), наличие или отсутствие обходных соединений, передаточные функции нейронов. При выборе количества слоев и нейронов в них следует исходить из того, что способности сети к обобщению тем выше, чем больше суммарное число связей между нейронами. С другой стороны, число связей ограничено сверху количеством записей в обучающих данных. 4.Экспериментальный подбор параметров обучения После выбора конкретной топологии, необходимо выбрать параметры обучения нейронной сети. Этот этап особенно важен для сетей, обучающихся с учителем. От правильного выбора параметров зависит не только то, насколько быстро ответы сети будут сходиться к правильным ответам. Например, выбор низкой скорости обучения увеличит время схождения, однако иногда позволяет избежать паралича сети. Собственно обучение сети В процессе обучения сеть в определенном порядке просматривает обучающую выборку. Порядок просмотра может быть последовательным, случайным и т. д. Некоторые сети, обучающиеся без учителя, например, сети Хопфилда просматривают выборку только один раз. Другие, например, сети Кохонена, а также сети, обучающиеся с учителем, просматривают выборку множество раз, при этом один полный проход по выборке называется эпохой обучения. При обучении с учителем набор исходных данных делят на две части ‒ собственно обучающую выборку и тестовые данные; принцип разделения может быть произвольным. Обучающие данные подаются сети для обучения, а проверочные используются для расчета ошибки сети (проверочные данные никогда для обучения сети не применяются). Таким образом, если на проверочных данных ошибка уменьшается, то сеть действительно выполняет обобщение. Если ошибка на обучающих данных продолжает уменьшаться, а ошибка на тестовых данных увеличивается, значит, сеть перестала выполнять обобщение и просто «запоминает» обучающие данные.
|
||||
|
|
Последнее изменение этой страницы: 2016-06-07; просмотров: 900; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.113 (0.012 с.) |