
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Шестая нормальная форма (6NF)Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Введена К. Дейтом в его книге,[2] как обобщение пятой нормальной формы для темпоральной базы данных. 15. Третья нормальная форма. Переменная отношения R находится в 3NF тогда и только тогда, когда выполняются следующие условия: § R находится во второй нормальной форме. § ни один неключевой атрибут R не находится в транзитивной функциональной зависимости от потенциального ключа R. Пояснения к определению: Неключевой атрибут отношения R — это атрибут, который не принадлежит ни одному из потенциальных ключей R. Функциональная зависимость множества атрибутов Z от множества атрибутов X (записывается X → Z, произносится «икс определяет зет») является транзитивной, если существует такое множество атрибутов Y, что X → Y и Y → Z. При этом ни одно из множеств X, Y и Z не является подмножеством другого, то есть функциональные зависимости X → Z, X → Y и Y → Z не являются тривиальными. Определение 3NF, эквивалентное определению Кодда, но по-другому сформулированное, дал Карло Заниоло в 1982 году. Согласно ему, переменная отношения находится в 3NF тогда и только тогда, когда для каждой из ее функциональных зависимостей X → A выполняется хотя бы одно из следующих условий: § Х содержит А (то есть X → A — тривиальная функциональная зависимость) § Х — суперключ § А — ключевой атрибут (то есть А входит в состав потенциального ключа). Запоминающееся и, по традиции, наглядное резюме определения 3NF Кодда было дано Биллом Кентом: каждый неключевой атрибут «должен предоставлять информацию о ключе, полном ключе и ни о чем, кроме ключа». Условие зависимости от «полного ключа» неключевых атрибутов обеспечивает то, что таблица находится во второй нормальной форме; а условие зависимости их от «ничего, кроме ключа» — то, что они находятся в третьей нормальной форме. 16. Нормальная форма Бойса-Кодда.
Переменная отношения находится в BCNF тогда и только тогда, когда каждая её нетривиальная и неприводимая слева функциональная зависимость имеет в качестве своего детерминанта некоторый потенциальный ключ[1]. Пусть R является переменной отношения, а X и Y — произвольными подмножествами множества атрибутов переменной отношения R. Y функционально зависимо от X тогда и только тогда, когда для любого допустимого значения переменной отношения R, если два кортежа переменной отношения R совпадают по значению X, они также совпадают и по значению Y. Подмножество X называют детерминантом, а Y — зависимой частью
17. Четвертая нормальная форма. Переменная отношения находится в 4NF, если она находится в НФБК и все нетривиальные многозначные зависимостифактически являются функциональными зависимостями[1] от её потенциальных ключей. Предположим, что рестораны производят разные виды пиццы, а службы доставки ресторанов работают только в определенных районах города. Составной первичный ключ соответствущей переменной отношения включает три атрибута: {Ресторан, Вид пиццы, Район доставки}. Такая переменная отношения не соответствует 4НФ, так как существует следующая многозначная зависимость: § {Ресторан} § {Ресторан} То есть, например, при добавлении нового вида пиццы придется внести по одному новому кортежу для каждого района доставки. Возможна логическая аномалия, при которой определенному виду пиццы будут соответствовать лишь некоторые районы доставки из обслуживаемых рестораном районов. Для предотвращения аномалии нужно декомпозировать отношение, разместив независимые факты в разных отношениях. В данном примере следует выполнить декомпозицию на {Ресторан, Вид пиццы} и {Ресторан, Район доставки}. Однако если к исходной переменной отношения добавить атрибут, функционально зависящий от потенциального ключа, например цену с учётом стоимости доставки ({Ресторан, Вид пиццы, Район доставки} → Цена), то полученное отношение будет находиться в 4НФ и его уже нельзя подвергнуть декомпозиции без потерь. Указанные выше многозначные зависимости в данном случае называются внедрёнными зависимостями. 18. Ограничения целостности. Це́лостность ба́зы да́нных (database integrity) — соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам. Каждое правило, налагающее некоторое ограничение на возможное состояние базы данных, называется ограничением целостности (integrity constraint). Примеры правил: вес детали должен быть положительным; количество знаков в телефонном номере не должно превышать 25; возраст родителей не может быть меньше возраста их биологического ребёнка и т.д. Задача аналитика и проектировщика базы данных — возможно более полно выявить все имеющиеся ограничения целостности и задать их в базе данных. 19. Таблицы и представления. Представление (англ. view, в сленге программистов часто используется в качестве заимствования из английского — «вьюха», «вьюшка») — виртуальная (логическая) таблица, представляющая собой поименованный запрос (алиас к запросу), который будет подставлен как подзапрос при использовании представления. В отличие от обычных таблиц реляционной БД, представление не является самостоятельной частью набора данных, хранящегося в базе. Содержимое представления динамически вычисляется на основании данных, находящихся в реальных таблицах. Изменение данных в реальной таблице БД немедленно отражается в содержимом всех представлений, построенных на основании этой таблицы. 20. Ограничение прав доступа в базе данных. Ограничения доступа к данным могут накладываться на чтение или изменение объектов базы данных. Текущий пользователь имеет право прочитать или изменить некоторый объект базы данных только в том случае, если ограничение доступа предоставляет ему такое право. В противном случае операция чтения или изменения этого объекта базы данных выполнена не будет. 21. Команды языка управления транзакциями – TCL (Тгаnsасtiоn Соntrol Language). Эти команды позволяют определить исход транзакции. 22. Модель полуструктурированных данных. Применение и реализация. Полуструктурированными называются данные, которые не имеют постоянной четко определенной структуры, и способные динамически изменять свою структуру, свой тип и свой состав. Полуструктурированными можно также назвать данные, которые хоть и имеют некоторую структуру, но по каким-либо причинам она неизвестна пользователю, желающему ими воспользоваться. В качестве примера можно привести мультимедийные данные и документы со структурированным текстом. Замечательным примером данных, которые не ограничены какой-либо схемой, является World Wide Web. Традиционные поисковые инструменты позволяют получить Web страницы по заданным ключевым словам. Однако, так как Web не соответствует ни одной из стандартных моделей данных, то построить запрос традиционным для баз данных способом невозможно. 23. Обеспечение надежного хранения данных в базах данных. Виды отказов, транзакции и протоколы восстановления Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая Журналом транзакций. Он предназначен для обеспечения надежного хранения данных в БД. Общими принципами восстановления являются следующие:
=> восстанавливается последнее по времени согласованное состояние базы данных. Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных.
Имеются два альтернативных варианта ведения журнала транзакций: протокол с отложенными обновлениями и протокол с немедленными обновлениями. Ведение журнала по принципу отложенных изменений предполагает следующий механизм выполнения транзакций:
<Т1 Begin transaction>
Альтернативный механизм с немедленным выполнением предусматривает внесение изменений сразу в БД, а в протокол заносятся не только новые, но и все старые значения изменяемых атрибутов, поэтому каждая запись выглядит <Т1, ID_RECORD, атрибут новое значение старое значение...>. При этом запись в журнал предшествует непосредственному выполнению операции над БД. Когда транзакция фиксируется, то есть встречается команда <Т1 СОММIТ> и она выполняется, то все изменения оказываются уже внесенными в БД и не требуется никаких дальнейших действий по отношению к этой транзакции. При откате транзакции выполняется системная процедура UNDO(), которая возвращает все старые значения в отмененной транзакции, последовательно проходя по протоколу начиная с команды BEGIN TRANSACTION. 24. Методы использования языка SQL в прикладной программе
25. Модели совместного доступа к базе данных и архитектура приложений Чем больше количество одновременно работающих с базой данных пользователей, тем больше вероятность встретиться с конфликтом одновременного редактирования одной и той же строки. Что делать серверу, если два пользователя одновременно пытаются обновить одну и ту же запись? Можно принять то изменение, которое пришло позже, но тогда один из пользователей будет видеть у себя некорректные данные. А самое страшное, он будет думать, что все в порядке. Как разрешить подобные проблемы? Допустим, что два пользователя открыли для редактирования форму с одним и тем же документом. Первый пользователь изменяет важные параметры, цены, количество и нажимает сохранить. Другой пользователь не видит этих изменений, потому что он получил данные раньше. При этом, он изменяет только незначительный параметр, например, дату и тоже нажимает сохранение. Незначительное изменение второго пользователя перезаписывает важные изменения первого. В многопользовательских приложениях, к программированию можно поступать двумя способами: 1. Кто последний, тот и прав. В этом случае вы просто реализуете логику программы и не заботитесь о том, что два пользователя могут одновременно изменять какие-то данные. Прав будет тот, кто чуть позже нажмет кнопку обновления. 2. Попытаться реализовать одновременный пользователь собственными средствами, с помощью журналов. Если в журнале есть запись, что кто-то открыл документ, но не закрыл, то не разрешать повторное открытие другим пользователям. Может быть, где-то это будет удобно и быстро, но в Oracle реализованы хорошие встроенные средства блокировок, которые работают быстрее, эффективнее и надежнее, поэтому данный метод мы не рекомендуем к использованию. 3. Блокировать записи, которые пользователь собирается изменять средствами базы данных. Заблокированную запись невозможно изменить, поэтому все запросы на редактирование будут отклоняться. Данный подход является более правильным и именно ему посвящена данная статья. 26. Команды манипулирования данными Data Manipulation Language (DML) (язык управления (манипулирования) данными) — это семейство компьютерных языков, используемых в компьютерных программах или пользователями баз данных для получения, вставки, удаления или изменения данных в базах данных. На текущий момент наиболее популярным языком DML является SQL, используемый для получения и манипулирования данными в РСУБД. Другие формы DML использованы в IMS/DL1, базах данных CODASYL (таких как IDMS), и других. Языки DML изначально использовались только компьютерными программами, но с появлением SQL стали также использоваться и людьми. Функции языков DML определяются первым словом в предложении (часто называемом запросом), которое почти всегда является глаголом. В случае с SQL эти глаголы — «select» («выбрать»), «insert» («вставить»), «update» («обновить»), и «delete» («удалить»). Это превращает природу языка в ряд обязательных утверждений (команд) к базе данных. Языки DML могут существенно различаться у различных производителей СУБД. Существует стандарт SQL, установленный ANSI, но производители СУБД часто предлагают свои собственные «расширения» языка. Языки DML разделяются в основном на два типа: Procedural DMLs — описывают действия над данными. Declarative DMLs — описывают сами данные. 27. Физическая организация индексов в базах данных Как бы не были организованы индексы в конкретной СУБД, их основное назначение состоит в обеспечении эффективного прямого доступа к кортежу таблицы по ключу. Обычно индекс определяется для одной таблицы, и ключом является значение ее поля (возможно, составного). Если ключом индекса является возможный ключ таблицы, то индекс должен обладать свойством уникальности, т.е. не содержать дубликатов ключа. На практике ситуация выглядит обычно противоположно: при объявлении первичного ключа таблицы автоматически заводится уникальный индекс, а единственным способом объявления возможного ключа, отличного от первичного, является явное создание уникального индекса. Это связано с тем, что для проверки сохранения свойства уникальности возможного ключа, так или иначе, требуется индексная поддержка. Общей идеей любой организации индекса, поддерживающего прямой доступ по ключу и последовательный просмотр в порядке возрастания или убывания значений ключа является хранение упорядоченного списка значений ключа с привязкой к каждому значению ключа списка идентификаторов кортежей. Одна организация индекса отличается от другой, главным образом, в способе поиска ключа с заданным значением. B+-деревья Наиболее популярным подходом к организации индексов в базах данных является использование техники B+-деревьев. Техника B- и B+-деревьев была предложена в начале 1970-х гг. Рудольфом Байером (Rudolf Bayer) и Эдом Маккрейтом (Ed McCreight) [3.17]. С точки зрения внешнего логического представления B-дерево – это сбалансированное сильно ветвистое дерево во внешней памяти. Сбалансированность означает, что длина пути от корня дерева к любому его листу одна и та же. Ветвистость дерева – это свойство каждого узла дерева ссылаться на большое число узлов-потомков. С точки зрения физической организации B-дерево представляется как мультисписочная структура страниц внешней памяти, т.е. каждому узлу дерева соответствует блок внешней памяти (страница). В B+-дереве внутренние и листовые страницы обычно имеют разную структуру. Типовая структура внутренней страницы B+-дерева показана на рис. 12.2.
При этом выдерживаются следующие свойства:
Листовая страница обычно имеет следующую структуру, показанную на рис. 12.3.
Листовая страница обладает следующими свойствами:
Поиск в B+-дереве – это прохождение от корня к листу в соответствии с заданным значением ключа. Заметим, что поскольку B+-деревья являются сильно ветвистыми и сбалансированными, для выполнения поиска по любому значению ключа потребуется одно и то же (и обычно небольшое) число обменов с внешней памятью. Более точно, в сбалансированном дереве, где длины всех путей от корня к листу одни и те же, если во внутренней странице помещается n ключей, то при хранении m записей требуется дерево глубиной logn(m). Если n достаточно велико (обычный случай), то глубина дерева невелика, и производится быстрый поиск. Основной «изюминкой» B+-деревьев является автоматическое поддержание свойства сбалансированности. 29.Язык SQL. Модификация данных. SQL (ˈɛsˈkjuˈɛl; англ. Structured Query Language — «язык структурированных запросов») — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. SQL основывается на исчислении кортежей. Первые разработки В начале 1970-х годов в одной из исследовательских лабораторий компании IBMбыла разработана экспериментальная реляционная СУБД IBM System R, для которой затем был создан специальный язык SEQUEL, позволявший относительно просто управлять данными в этой СУБД. Аббревиатура SEQUEL расшифровывалась как Structured English QUEry Language — «структурированный английский язык запросов». Позже по юридическим соображениям[3] язык SEQUEL был переименован в SQL. Когда в 1986 году первый стандарт языка SQL был принят ANSI (American National Standards Institute), официальным произношением стало [,es kju:' el] — эс-кью-эл. Несмотря на это, даже англоязычные специалисты зачастую продолжают читать SQL как сиквел (по-русски также часто говорят «эс-ку-эль» или используют жаргонизм «скуль»). Целью разработки было создание простого непроцедурного языка, которым мог воспользоваться любой пользователь, даже не имеющий навыков программирования. Собственно разработкой языка запросов занимались Дональд Чэмбэрлин (Donald D. Chamberlin) и Рэй Бойс (Ray Boyce). Пэт Селинджер (Pat Selinger) занималась разработкой стоимостного оптимизатора (cost-based optimizer), Рэймонд Лори (Raymond Lorie) занимался компилятором запросов. Стоит отметить, что SEQUEL был не единственным языком подобного назначения. В Калифорнийском Университете Берклибыла разработана некоммерческая СУБД Ingres (являвшаяся, между прочим, дальним прародителем популярной сейчас некоммерческой СУБД PostgreSQL), которая являлась реляционной СУБД, но использовала свой собственный язык QUEL, который, однако, не выдержал конкуренции по количеству поддерживающих его СУБД с языком SQL. Первыми СУБД, поддерживающими новый язык, стали в 1979 году Oracle V2 для машин VAX от компании Relational SoftwareInc. (впоследствии ставшей компанией Oracle) и System/38 от IBM, основанная на System/R. SQL является, прежде всего, информационно-логическим языком, предназначенным для описания, изменения и извлечения данных, хранимых в реляционных базах данных. SQL нельзя назвать языком программирования [ источник не указан 437 дней ].[6] Изначально, SQL был основным способом работы пользователя с базой данных и позволял выполнять следующий набор операций: § создание в базе данных новой таблицы; § добавление в таблицу новых записей; § изменение записей; § удаление записей; § выборка записей из одной или нескольких таблиц (в соответствии с заданным условием);
Язык SQL представляет собой совокупность § операторов; § инструкций; § и вычисляемых функций Преимущества
|
||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 702; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.129.63.214 (0.011 с.) |

 {Вид пиццы}
{Вид пиццы}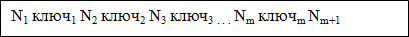
 ключ2
ключ2 



