
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Иерархическая модель данных.Стр 1 из 3Следующая ⇒
Сетевая модель данных. Сетевой подход к организации данных является расширением иерархического. В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. Иерархическая модель данных. Иерархическая структура представляет совокупность элементов, связанных между собой поопределенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рис. 7. К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем, и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи Реляционная модель данных. Понятие реляционный (англ. relation - отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: - каждый элемент таблицы - одни элемент данных; - все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и тд.) и длину; - каждый столбец имеет уникальное имя; - одинаковые строки в таблице отсутствуют; - порядок следования строк и столбцов может быть произвольным. Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы - атрибутам отношений, доменам, полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ - ключ второй таблицы.
Объектно-ориентированная Основу составляют следующие компоненты.- Объекты модели данных являются абстракциями сущностей и событий мира. В общих чертах любой объект может рассматриваться как эквивалент сущности ER-модели. Точнее, любой объект представляет только один экземпляр сущности.(семантическое наполнение объекта определяется через несколько элементов этого списка). - Объекты, которые совместно используют одни и те же характеристики, группируются в классы. Класс представляет собой совокупность подобных объектов со структурой совместного доступа (атрибуты) и поведением (методы). Преимущества: Добавление семантического наполнения. Добавление семантического наполнения делает модель данных более значимой. Во внешнее представление включено семантическое наполнение. модель представляет отношения в наглядной форме. Это упрощает визуализацию сложных отношений внутри и между объектами. Целостность базы данных. Так же как и иерархическая, объектно-ориентированная модель использует наследование для защиты целостности базы данных. Структурная независимость и независимость по данным. Автономия объекта объектно-ориентированной модели гарантирует структурную независимость и независимость по данным.
4. Этапы проектирования баз данных Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобныеER-диаграммам. Чаще всего концептуальная модель базы данных включает в себя: § описание информационных объектов, или понятий предметной области и связей между ними. § описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними. Логическое (даталогическое) проектирование Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи. Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован. На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД. Физическое проектирование Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т.д.
5. Понятие отношения в реляционной модели данных. Связи между отношениями. Определение 1. Атрибут отношения есть пара вида <Имя_атрибута: Имя_домена>. Определение 2. Отношение
Тело отношения содержит множество кортежей отношения. Каждый кортеж отношения представляет собой множество пар вида <Имя_атрибута: Значение_атрибута>:
таких что значение Отношение обычно записывается в виде:
или короче
или просто
Число атрибутов в отношении называют степенью (или -арностью) отношения. Возвращаясь к математическому понятию отношения, введенному в предыдущей главе, можно сделать следующие выводы: Вывод 1: Заголовок отношения описывает декартово произведение доменов, на котором задано отношение. Заголовок статичен, он не меняется во время работы с базой данных. Если в отношении изменены, добавлены или удалены атрибуты, то в результате получим уже другое отношение (пусть даже с прежним именем).
Вывод 2: Тело отношения представляет собой набор кортежей, т.е. подмножество декартового произведения доменов. Таким образом, тело отношения собственно и является отношением в математическом смысле слова. Тело отношения может изменяться во время работы с базой данных - кортежи могут изменяться, добавляться и удаляться. 6. Реляционная модель данных. Понятие реляционный (англ. relation - отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: - каждый элемент таблицы - одни элемент данных; - все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и тд.) и длину; - каждый столбец имеет уникальное имя; - одинаковые строки в таблице отсутствуют; - порядок следования строк и столбцов может быть произвольным. Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы - атрибутам отношений, доменам, полям. Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. 7. Теоретико-множественные операции реляционной алгебры. Объединением двух совместимых по типу отношений Объединение, как и любое отношение, не может содержать одинаковых кортежей. Поэтому, если некоторый кортеж входит и в отношение Пересечением двух совместимых по типу отношений
Вычитанием двух совместимых по типу отношений
8. Специальные операции реляционной алгебры. Операция ограничения требует наличия двух операндов: ограничиваемого отношения и простого условия ограничения. Простое условие ограничения может иметь либо вид (a comp-op b), где а и b - имена атрибутов ограничиваемого отношения, для которых осмысленна операция сравнения comp-op, либо вид (a comp-op const), где a - имя атрибута ограничиваемого отношения, а const - литерально заданная константа. В результате выполнения операции ограничения производится отношение, заголовок которого совпадает с заголовком отношения-операнда, а в тело входят те кортежи отношения-операнда, для которых значением условия ограничения является true. Операция взятия проекции также требует наличия двух операндов - проецируемого отношения A и списка имен атрибутов, входящих в заголовок отношения A. Результатом проекции отношения A по списку атрибутов a1, a2,..., an является отношение, с заголовком, определяемым множеством атрибутов a1, a2,..., an, и с телом, состоящим из кортежей вида <a1:v1, a2:v2,..., an:vn> таких, что в отношении A имеется кортеж, атрибут a1 которого имеет значение v1, атрибут a2 имеет значение v2,..., атрибут an имеет значение vn. Тем самым, при выполнении операции проекции выделяется "вертикальная" вырезка отношения-операнда с естественным уничтожением потенциально возникающих кортежей-дубликатов. операция соединения (называемая также соединением по условию) требует наличия двух операндов - соединяемых отношений и третьего операнда - простого условия. Пусть соединяются отношения A и B. Как и в случае операции ограничения, условие соединения comp имеет вид либо (a comp-op b), либо (a comp-op const), где a и b - имена атрибутов отношений A и B, const - литерально заданная константа, а comp-op - допустимая в данном контексте операция сравнения. Тогда по определению результатом операции сравнения является отношение, получаемое путем выполнения операции ограничения по условию comp прямого произведения отношений A и B. Деление отношений. Эта операция наименее очевидна из всех операций реляционной алгебры и поэтому нуждается в более подробном объяснении. Пусть заданы два отношения - A с заголовком {a1, a2,..., an, b1, b2,..., bm} и B с заголовком {b1, b2,..., bm}. Будем считать, что атрибут bi отношения A и атрибут bi отношения B не только обладают одним и тем же именем, но и определены на одном и том же домене. Назовем множество атрибутов {aj} составным атрибутом a, а множество атрибутов {bj} - составным атрибутом b. После этого будем говорить о реляционном делении бинарного отношения A(a,b) на унарное отношение B(b). Результатом деления A на B является унарное отношение C(a), состоящее из кортежей v таких, что в отношении A имеются кортежи <v, w> такие, что множество значений {w} включает множество значений атрибута b в отношении B.
9. Иерархическая и сетевая модели данных. Реализация иерархических и сетевых связей в реляционной модели. Сетевая модель данных. Сетевой подход к организации данных является расширением иерархического. В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. Первые разработки В начале 1970-х годов в одной из исследовательских лабораторий компании IBMбыла разработана экспериментальная реляционная СУБД IBM System R, для которой затем был создан специальный язык SEQUEL, позволявший относительно просто управлять данными в этой СУБД. Аббревиатура SEQUEL расшифровывалась как Structured English QUEry Language — «структурированный английский язык запросов». Позже по юридическим соображениям[3] язык SEQUEL был переименован в SQL. Когда в 1986 году первый стандарт языка SQL был принят ANSI (American National Standards Institute), официальным произношением стало [,es kju:' el] — эс-кью-эл. Несмотря на это, даже англоязычные специалисты зачастую продолжают читать SQL как сиквел (по-русски также часто говорят «эс-ку-эль» или используют жаргонизм «скуль»). Целью разработки было создание простого непроцедурного языка, которым мог воспользоваться любой пользователь, даже не имеющий навыков программирования. Собственно разработкой языка запросов занимались Дональд Чэмбэрлин (Donald D. Chamberlin) и Рэй Бойс (Ray Boyce). Пэт Селинджер (Pat Selinger) занималась разработкой стоимостного оптимизатора (cost-based optimizer), Рэймонд Лори (Raymond Lorie) занимался компилятором запросов. Стоит отметить, что SEQUEL был не единственным языком подобного назначения. В Калифорнийском Университете Берклибыла разработана некоммерческая СУБД Ingres (являвшаяся, между прочим, дальним прародителем популярной сейчас некоммерческой СУБД PostgreSQL), которая являлась реляционной СУБД, но использовала свой собственный язык QUEL, который, однако, не выдержал конкуренции по количеству поддерживающих его СУБД с языком SQL. Первыми СУБД, поддерживающими новый язык, стали в 1979 году Oracle V2 для машин VAX от компании Relational SoftwareInc. (впоследствии ставшей компанией Oracle) и System/38 от IBM, основанная на System/R. SQL является, прежде всего, информационно-логическим языком, предназначенным для описания, изменения и извлечения данных, хранимых в реляционных базах данных. SQL нельзя назвать языком программирования [ источник не указан 437 дней ].[6] Изначально, SQL был основным способом работы пользователя с базой данных и позволял выполнять следующий набор операций: § создание в базе данных новой таблицы; § добавление в таблицу новых записей; § изменение записей; § удаление записей; § выборка записей из одной или нескольких таблиц (в соответствии с заданным условием);
Язык SQL представляет собой совокупность § операторов; § инструкций; § и вычисляемых функций Преимущества Наличие стандартов Декларативность Недостатки Сложность Отступления от стандартов Процессы работы с данными Источниками данных могут быть: 1. Традиционные системы регистрации операций 2. Отдельные документы 3. Наборы данных Операции с данными: 1. Извлечение – перемещение информации от источников данных в отдельную БД, приведение их к единому формату. 2. Преобразование – подготовка информации к хранению в оптимальной форме для реализации запроса, необходимого для принятия решений. 3. Загрузка – помещение данных в хранилище, производится атомарно, путем добавления новых фактов или корректировкой существующих. 4. Анализ – OLAP, Data Mining, сводные отчёты. 5. Представление результатов анализа Сетевая модель данных. Сетевой подход к организации данных является расширением иерархического. В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. Иерархическая модель данных. Иерархическая структура представляет совокупность элементов, связанных между собой поопределенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рис. 7. К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем, и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи Реляционная модель данных. Понятие реляционный (англ. relation - отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: - каждый элемент таблицы - одни элемент данных; - все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и тд.) и длину; - каждый столбец имеет уникальное имя; - одинаковые строки в таблице отсутствуют; - порядок следования строк и столбцов может быть произвольным. Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы - атрибутам отношений, доменам, полям. Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ - ключ второй таблицы.
Объектно-ориентированная Основу составляют следующие компоненты.- Объекты модели данных являются абстракциями сущностей и событий мира. В общих чертах любой объект может рассматриваться как эквивалент сущности ER-модели. Точнее, любой объект представляет только один экземпляр сущности.(семантическое наполнение объекта определяется через несколько элементов этого списка). - Объекты, которые совместно используют одни и те же характеристики, группируются в классы. Класс представляет собой совокупность подобных объектов со структурой совместного доступа (атрибуты) и поведением (методы). Преимущества: Добавление семантического наполнения. Добавление семантического наполнения делает модель данных более значимой. Во внешнее представление включено семантическое наполнение. модель представляет отношения в наглядной форме. Это упрощает визуализацию сложных отношений внутри и между объектами. Целостность базы данных. Так же как и иерархическая, объектно-ориентированная модель использует наследование для защиты целостности базы данных. Структурная независимость и независимость по данным. Автономия объекта объектно-ориентированной модели гарантирует структурную независимость и независимость по данным.
4. Этапы проектирования баз данных Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности. Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобныеER-диаграммам. Чаще всего концептуальная модель базы данных включает в себя: § описание информационных объектов, или понятий предметной области и связей между ними. § описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 585; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.74.54 (0.088 с.) |
 , определенное на множестве доменов
, определенное на множестве доменов  (не обязательно различных), содержит две части: заголовок и тело.
(не обязательно различных), содержит две части: заголовок и тело.

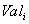 атрибута
атрибута 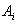 принадлежит домену
принадлежит домену 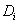
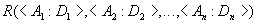 ,
, ,
,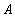 и
и 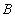 называется отношение с тем же заголовком, что и у отношений
называется отношение с тем же заголовком, что и у отношений 


