Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Формирование исходного отношения.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте Формирование исходного отношения. Проектирование БД начинается с определения всех объектов, сведения о которых будут включены в базу, и определения их атрибутов. Затем атрибуты сводятся в одну таблицу – исходное отношение. Пример формирования исходного отношения: Предположим, что для учебной части факультета создается БД по преподавателям. На первом этапе проектирования БД в результате общения с заказчиком должны быть определены содержащиеся в базе сведения о том, как она должна быть использована и какую информацию заказчик хочет получать в процессе ее эксплуатации. В результате устанавливаются атрибуты, которые должны содержаться в отношениях БД и связи между ними. Имена выделенных атрибутов: Ф и о Должность Оклад Стаж Кафедра Надбавка за стаж Название предмета Группа Вид занятий
Одно из требований к атрибуту заключается в том, чтобы все атрибуты отношения имели простые значения. В исходном отношении каждый атрибут отношения также должен быть простым. Пример исходного отношения ПРЕПОДАВАТЕЛЬ:
Исходное отношение ПРЕПОДАВАТЕЛЬ содержит избыточное дублирование данных. Различают избыточность явную и неявную. Явная избыточность заключается в том, что в отношении ПРЕПОДАВАТЕЛЬ строки с данными о преподавателях, проводящих занятия в нескольких группах, повторяются соответствующее число раз. Неявная избыточность в отношении ПРЕПОДАВАТЕЛЬ проявляется в одинаковых добавках к окладу за одинаковый стаж.
Понятия объект и класс в ООБД В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом или типом, конструируемым пользователем. Значением свойства типа string является строка символов. Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса. Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов. Класс – это описание совокупности объектов с общими атрибутами, операциями, отношениями и семантикой. Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механиз мами инкапсуляции, наследования и полиморфизма.
СУБД ACCESS. Программа Microsoft Access 2002 является реляционной СУБД, которая может функционировать под управлением операционных систем Windows 95/98, Windows NT, Windows 2000 и Windows XP. СУБД Access имеет стандартизованный интерфейс приложений Windows. База данных является основным компонентом проекта приложения А и может включать в свой состав таблицы, формы, запросы, отчеты, макросы и модули. Для работы с базами данных в Access имеется стандартное окно, из которого можно вызвать любой ее объект просмотра, выполнения, разработки и модификации. Пользователь для работы с базой данных может разработать свой интерфейс, основу которого обычно составляют формы. На формах размещаются различные элементы, такие как: поля таблиц, поля со списком кнопки, раскрывающиеся списки, выключатели, переключатели, флажки' рисунки, подчиненные формы и т. д. Таблица представляет собой основную единицу хранения данных в базе. Основными операциями над таблицами являются: просмотр и обновление (ввод, модификация и удаление), сортировка, фильтрация и печать. Форма представляет собой объект базы данных Access, в котором разработчик размещает элементы управления, принимающие деист пользователей или служащие для ввода, отображения и изменения данных в полях. Запрос представляет собой формализованное требование на отбор данных из таблиц или на выполнение определенных действий с данными. ВAccess можно создавать и выполнять следующие основные типы запросов: на выборку, обновление, удаление, или добавление данных. Макрос представляет последовательность макрокоманд встроенного языка Access, задающих автоматическое выполнение некоторых операций, например: «Открыть Таблицу», «Закрыть», «Найти Запись» и «Печать». Модуль представляет совокупность описаний, инструкций и процедур на языке VBA, сохраненную под общим именем. В Access используются модули трех типов: формы, отчета и стандартный. В таблицах хранятся данные, которые можно использовать в запросах, формах и отчетах. Формы и отчеты используют данные из таблиц или через запросы. При полной установке Access версии 2002 требуется 16 Мб оперативной памяти и около 65 Мбайтов свободного пространства на жестком диске. Microsoft Access 2002 позволяет работать с данными и таблицами баз данных, созданных в предыдущих версиях Access, но его нельзя использовать для изменения объектов в базах данных предыдущих версий. Поэтому для работы с ранее созданными базами рекомендуется использовать имеющиеся в Microsoft Access 2002 средства преобразования старых форматов в новый формат. Некоторые ограничения СУБД Access 2002: • размер файла базы данных (с расширением mdb) — 2 Гб за вычетом места, необходимого системным объектам. Реально размер ограничивается доступным местом на диске, так как БД может включать присоединенные таблицы; • количество одновременно работающих пользователей — 255; • максимальный размер таблицы — 2 Гбайт;
• максимальное количество нолей в таблице — 255; • максимальное число символов в записи (не считая поля Memo и поля объектов OLE) – 2000; • максимальное количество таблиц в запросе — 32. Методы нормальных форм. Основные виды зависимостей между атрибутами отношений: функциональные, транзитивные и многозначные. Атрибут В функционально зависит от атрибута А, если каждому значению А соответствует в точности одно значение В. Если существует функциональная зависимость вида А→В и В→А, то между А и В имеется взаимно однозначное соответствие, или функциональная взаимозависимость. Частичной зависимостью называется зависимость не ключевого атрибута от части составного ключа. Атрибут С зависит от атрибута А транзитивно, если для атрибутов А, В, С выполняются условия А—»В и В—>С, но обратная зависимость отсутствует. В отношении R атрибут В многозначно зависит от атрибута А, если каждому значению А соответствует множество значений В, не связанных с другими атрибутами из R. Два или более атрибута называются взаимно независимыми, если ни один из этих атрибутов не является функционально зависимым от других атрибутов. Выделяют следующую последовательность нормальных форм: • первая нормальная форма (1НФ); • вторая нормальная форма (2НФ); • третья нормальная форма (ЗНФ); • усиленная третья нормальная форма, или нормальная форма Бойса -Кодда (БКНФ); • четвертая нормальная форма (4НФ); • пятая нормальная форма (5НФ). Отношение находится в 1НФ, если все его атрибуты являются простыми (имеют единственное значение). Исходное отношение строится таким образом, чтобы оно было в 1НФ.- Перевод отношения в следующую нормальную форму осуществляется методом «декомпозиции без потерь». Такая декомпозиция должна обеспечить то, что запросы к исходному отношению и к отношениям, получаемым в результате декомпозиции, дадут одинаковый результат Отношение находится в 2НФ, если оно находится в 1НФи каждый не ключевой атрибут функционально полно зависит от первичного ключа (составного). Для устранения частичной зависимости и перевода отношения в 2НФ необходимо, используя операцию проекции, разложить его на несколько отношений следующим образом: • построить проекцию без атрибутов, находящихся в частичной функциональной зависимости от первичного ключа; • построить проекции на части составного первичного ключа и атрибуты, зависящие от этих частей. Отношение находится в ЗНФ, если оно находится в 2НФ и каждый неключевой атрибут нетранзитивно зависит от первичного ключа. Взаимная независимость атрибутов означает отсутствие всякой зависимости между атрибутами отношения, в том числе и транзитивной зависимости между ними. Транзитивные зависимости также порождают избыточное дублирование информации в отношении. Если в отношении имеется зависимость атрибутов составного ключа от неключевых атрибутам необходимо перейти к усиленной ЗНФ. Отношение находится в нормальной форме Бойса - Кодда, если оно находится в ЗНФ и в нем отсутствуют зависимости ключей (атрибутов составного ключа) от неключевых атрибутов. Отношение R находится в 4НФ в том и только в том случае, когда существует многозначная зависимость А=»В, а все остальные атрибуты R функционально зависят от А. Отношение R находится в 5НФ в том и только том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R. Многомерная модель. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения. В развитии концепций ИС можно выделить следующие два направления: • системы оперативной обработки; • системы аналитической обработки. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных. Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью.
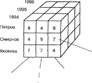
Основные понятия многомерных моделей данных: Измерение — это множество однотипных данных, образующих одну из граней гиперкуба. Примерами наиболее часто используемых временных измерений являются Дни, Месяцы, Кварталы и Годы. Ячейка или показатель — это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой.
В случае многомерной модели данных применяется ряд специальных операций: «Срез» представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Операция «вращение» заключается в изменении порядка измерений при визуальном представлении данных. Операции «агрегация» и «детализация» означают соответственно переход к более общему и к более детальному представлению информации пользователю из гиперкуба. Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации. Примерами систем, поддерживающих многомерные модели данных, являются Essbase, Media Multi-matrix, Oracle Express Server и Cache. Этапы проектирования. Процесс проектирования базы данных – это процесс, допускающим возврат к предыдущим этапам для пересмотра ранее принятых решений и включает следующие этапы: 1. Выделение сущностей и связей между ними. 2. Построение диаграмм ER-типа с учетом всех сущностей и их связей. 3. Формирование набора предварительных отношений с указанием предполагаемого первичного ключа для каждого отношения и использованием диаграмм ER-типа. 4. Добавление неключевых атрибутов в отношения. 5. Приведение предварительных отношений к нормальной форме Бойса-Кодда, например, с помощью метода нормальных форм. 6. Пересмотр ER-диаграмм в следующих случаях: • некоторые отношения не приводятся к нормальной форме Бойса-Кодда; • некоторым атрибутам не находится логически обоснованных мест в предварительных отношениях. После преобразования ER-диаграмм осуществляется повторное выполнение предыдущих этапов проектирования (возврат к этапу 1). Одним из узловых этапов проектирования является этап формирования отношений. Рассмотрим процесс формирования предварительных отношений, составляющих первичный вариант схемы БД. В рассмотренных выше примерах связь ВЕДЕТ всегда соединяет две сущности и поэтому является бинарной. Сформулированные ниже правила формирования отношений из диаграмм ER-типа распространяются именно на бинарные связи. Поэтому, когда речь идет о связях, слово «бинарные» далее опускается.
Проблемы проектирования. Проектирование ИС, включающих в себя БД, осуществляется на физ. и лог. уровнях. Решение проблем проектирования на физ. уровне во многом зависит от используемой СУБД, зачастую автоматизирована и скрыта от пользователя. Логическое проектирование заключается в определении числа и структуры таблиц, формировании запросов к БД, определении типов отчетных документов, разработке алгоритмов обработки информации, создании форма для ввода и редактирования данных в базе и решения ряда др. задач. Решение задач логического проектирования БД в основном определяется спецификой задач предметной области. Наиболее важной здесь является проблема структуризации данных. При проектировании структур данных для автоматизированных систем можно выделить 3 основных подхода: 1) сбор информации об объектах решаемой задачи в рамках одной таблицы и последующая декомпозиция ее на несколько взаимосвязанных таблиц на основе процедуры нормализации отношений; 2) формулирование знаний о системе и требований к обработке данных, получение с помощью CASE-системы готовой схемы БД или даже готовой прикладной ИС; 3) структурирование информации для использования в ИС в процессе проведения системного анализа на основе совокупности правил и рекомендаций. Следует различать простое и избыточное дублирование данных. Наличие первого из них допускается в БД, а избыточное дублирование данных может приводить к проблемам при обработке данных. Пример неизбыточного дублирования данных представляет собой отношение С (Т) с атрибутами «сотрудник» и «телефон». для сотрудников, находящихся в одном помещении, номера телефонов совпадают. Номер телефона 4328 встречается несколько раз, хотя для каждого служащего номер телефона уникален. поэтому ни один из номеров не является избыточным. С_Т
Пример избыточного дублирования представляет отношение С_Т_Н, которое в отличие от отношения С_Т дополнено атрибутом Н_комн. Все служащие в одной комнате имеют один телефон. Следовательно, в рассматриваемом отношении имеется избыточное дублирование данных. С_Т_Н
Избыточное дублирование данных создает проблеиы при обработке кортежей отношения, названные Коддом «аномалиями обновления отношений». Реляционная модель. Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение. Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица. Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения. С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного, информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми. Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей. Примерами зарубежных реляционных СУБД являются следующие:, DB2 (IBM), R:BASE (Microrim), FoxPro, Paradox и dBASE for Windows (Borland),, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), и Oracle (Oracle). К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН УССР), а также система HyTech (МИФИ).
Иерархическая модель. В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева).
Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево». Тип «дерево» является составным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит из одного «корневого» типа и упорядоченного набора (возможно, пустого) подчиненных типов. Каждый из элементарных типов, включенных в тип «дерево», является простым или составным типом «запись». Простая «запись» состоит из одного типа, например числового, а составная «запись» объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу. В целом тип «дерево» представляет собой иерархически организованный набор типов «запись». Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа «дерево» (деревьев), содержащих экземпляры типа «запись» (записи). Для организации физического размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов: • представление линейным списком с последовательным распределением памяти; • представление связными линейными списками; К основным операциям манипулирования иерархически организованными данными относятся следующие: • поиск указанного экземпляра БД; • переход от одного дерева к другому; • переход от одной записи к другой внутри дерева; • вставка новой записи в указанную позицию; • удаление текущей записи и т. д. Между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией. Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Зарубежные СУБД на основе иерархической модели: IMS, PC/Focus, Team-Up и Data Edge; отечественные СУБД: Ока, ИНЭС и МИРИС. Архитектура ИС. Эффективность функционирования информационной системы (ИС) во многом зависит от ее архитектуры. В настоящее время перспективной является архитектура клиент-сервер. В достаточно распространенном варианте она предполагает наличие компьютерной сети и распределенной базы данных, включающей корпоративную базу данных (КБД) и персональные базы данных (ПБД). КБД размещается на компьютере-сервере, ПБД размещаются на компьютерах сотрудников подразделении, являющихся клиентами корпоративной БД. Сервером определенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом, клиентом — компьютер (программа), использующий этот ресурс. Достоинством организации информационной системы по архитектуре клиент-сервер является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации с индивидуальной работой пользователей над персональной информацией. Исторически первыми появились распределенные ИС с применением файл-сервера.
В таких ИС по запросам пользователей файлы базы данных передаются на персональные компьютеры, где и производится их обработка. Недостатком такого варианта архитектуры является высокая интенсивность передачи обрабатываемых данных. Причем зачастую передаются избыточные данные. Файлы базы данных передаются целиком. При архитектуре с использованием сервера БД сервер обеспечивает выполнение основного объема обработки данных. Формируемые пользователем или приложением запросы поступают к серверу БД в виде инструкций языка SQL. Сервер базы данных выполняет поиск и извлечение нужных данных, которые затем передаются на компьютер пользователя. Достоинством такого подхода в сравнении предыдущим является заметно меньший объем передаваемых данных. Использование архитектуры клиент-сервер дает возможность постепенного наращивания информационной системы предприятия, во-первых, по мере развития предприятия; во-вторых, по мере развития самой информационной системы.
19. Поколения БД, принципы и основные понятия. Основы построения БД. Жизненный цикл БД. Жизненный цикл БД делится на 2 фазы: 1 фаза - проектирование системы 2 фаза- заполнение системы информацией, расширение БД С точки зрения проектировщика систем БД проектирование системы - объединение системы БД, ППО, программного обеспечения СУБД,ОС и комплексы технических средств в единую систему информации сервиса пользователя Жизненный цикл системы БД состоит из 2 фаз: 1- анализа и проектирования системы БД 2- эксплуатация Первая фаза включает следующими этапы: 1- формирование, анализ требований пользователей 2- концептуальное проектирование 3- проектирование и реализация 4- физическое проектирование системы Вторая фаза (эксплуатации) включает этапы: 1- реализация БД 2- поддержка функционирования 3- модификация и адаптация системы Access 2002. Программа Microsoft Access 2002 является реляционной СУБД, которая может функционировать под управлением операционных систем Windows 95/98, Windows NT, Windows 2000 и Windows XP. СУБД Access имеет стандартизованный интерфейс приложений Windows. База данных является основным компонентом проекта приложения А и может включать в свой состав таблицы, формы, запросы, отчеты, макросы и модули. Для работы с базами данных в Access имеется стандартное окно, из которого можно вызвать любой ее объект просмотра, выполнения, разработки и модификации. Пользователь для работы с базой данных может разработать свой интерфейс, основу которого обычно составляют формы. На формах размещаются различные элементы, такие как: поля таблиц, поля со списком кнопки, раскрывающиеся списки, выключатели, переключатели, флажки' рисунки, подчиненные формы и т. д. Таблица представляет собой основную единицу хранения данных в базе. Основными операциями над таблицами являются: просмотр и обновление (ввод, модификация и удаление), сортировка, фильтрация и печать. Форма представляет собой объект базы данных Access, в котором разработчик размещает элементы управления, принимающие деист пользователей или служащие для ввода, отображения и изменения данных в полях. Запрос представляет собой формализованное требование на отбор данных из таблиц или на выполнение определенных действий с данными. ВAccess можно создавать и выполнять следующие основные типы запросов: на выборку, обновление, удаление, или добавление данных. Макрос представляет последовательность макрокоманд встроенного языка Access, задающих автоматическое выполнение некоторых операций, например: «ОткрытьТаблицу», «Закрыть», «НайтиЗапись» и «Печать». Модуль представляет совокупность описаний, инструкций и процедур на языке VBA, сохраненную под общим именем. В Access используются модули трех типов: формы, отчета и стандартный. В таблицах хранятся данные, которые можно использовать в запросах, формах и отчетах. Формы и отчеты используют данные из таблиц или через запросы. При полной установке Access версии 2002 требуется 16 Мб оперативной памяти и около 65 Мбайтов свободного пространства на жестком диске. Microsoft Access 2002 позволяет работать с данными и таблицами баз данных, созданных в предыдущих версиях Access, но его нельзя использовать для изменения объектов в базах данных предыдущих версий. Поэтому для работы с ранее созданными базами рекомендуется использовать имеющиеся в Microsoft Access 2002 средства преобразования старых форматов в новый формат. Некоторые ограничения СУБД Access 2002: • размер файла базы данных (с расширением mdb) — 2 Гб за вычетом места, необходимого системным объектам. Реально размер ограничивается доступным местом на диске, так как БД может включать присоединенные таблицы; • количество одновременно работающих пользователей — 255; • максимальный размер таблицы — 2 Гбайт;
• максимальное количество нолей в таблице — 255; • максимальное число символов в записи (не считая поля Memo и поля объектов OLE) – 2000; • максимальное количество таблиц в запросе — 32. СУБД. В общем случае под СУБД можно понимать любой программный продукт, поддерживающий процессы создания, ведения и использования БД. К СУБД относятся следующие основные виды программ: • полнофункциональные СУБД; • серверы БД; • клиенты БД; • средства разработки программ работы с БД. Полнофункциональные СУБД (ПФСУБД) представляют собой традиционные СУБД, которые сначала появились для больших машин, затем для мини-машин и для ПЭВМ. Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Эта группа БД в настоящее время менее многочисленна, но их количество постепенно растет. Серверы БД реализуют функции управления базами данных. В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т. д. Средства разработки программ работы с БД могут использоваться для создания разновидностей следующих программ: • клиентских программ; • серверов БД и их отдельных компонентов; • пользовательских приложений. По характеру использования СУБД делят на персональные и многопользовательские. Персональные СУБД обычно обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. Многопользовательские СУБД включают в себя сервер БД и клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде. С точки зрения пользователя, СУБД реализует функции хранения, изменения и обработки информации, а также разработки и получения различных выходных документов. Функции СУБД используют низкоуровневые функции: • управление данными во внешней памяти; • управление буферами оперативной памяти; • управление транзакциями; • ведение журнала изменений в БД; • обеспечение целостности и безопасности БД. Методы и алгоритмы управления данными являются «внутренним делом» СУБД и прямого отношения к пользователю не имеют. Необходимость буферизации данных и как следствие реализации функции управления буферами оперативной памяти обусловлено тем, что объем оперативной памяти меньше объема внешней памяти. Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью. Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала и до завершения. Ведение журнала изменений в БД (журнализация изменений) выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных сбоев и отказов, а также ошибок в программном обеспечении. Журнал СУБД — это особая БД или часть основной БД, непосредственно недоступная пользователю и используемая для записи информации обо всех изменениях базы данных. Обеспечение целостности БД составляет необходимое условие успешного функционирования БД, особенно для случая использования БД в сетях. Целостность БД есть свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Обеспечение безопасности достигается в СУБД шифрованием прикладных программ, данных, защиты паролем, поддержкой уровней доступа к базе данных и к отдельным ее элементам. ЯЗЫК QBE. В современных СУБД широко используются табличные языки запросов. Наиболее распространенным среди них является язык QBE. Язык QBE предназначен для работы с терминала и ориентирован на конечного пользователя. Суть подхода, воплощенного в языке QBE, заключается в следующем. На экране высвечивается «скелет» (образ, форма, структура) одной из нескольких таблиц (файлов баз данных, отношений), данные из которых будут участвовать в запросе. «Скелет» выбранной пользователем таблицы выводится на экран дисплея в виде «шапки», в крайнем левом столбце которой написано название файла базы данных, а в остальных - имена полей файла. В этой форме пользователь определяет условия запроса. В некоторых случаях при формулировке запроса необходимо использовать так называемы «переменные для примера» («наполнители»). Они также записываются в определенных графах таблицы, но они означают не какое-то определенное значение, а любое. Константы, применяемые для задания значений ключей поиска, и переменные, указываемы для примера, должны при записи запроса отличаться друг от друга. В разных СУБД они отличаются по-разному: в одних системах «наполнители» подчеркиваются, в других - используются специальные ограничители и т.п. Кроме собственно поисковых запросов язык QBE позволяет выполнять и другие операции, например корректировку данных. Операции, которые надо выполнить, указываются в крайнем левом столбце под именем файла базы данных. ЯЗЫК SQL. SQL является одним из самых распространенных языков запросов. Он реализован в целом ряде популярных СУБД для различных типов ЭВМ. В таких СУБД, как ORACLE, INGRES, SQL Base и др., SQL является базовым языком. Язык SQL обладает развитыми возможностями и может использоваться как конечными пользователями для формулировки не очень сложных запросов, так и специалистами в области обработки данных. SQL оперирует данными, представленными в виде таблицы. Таблица состоит из множества строк, каждая из которых представляет собой непустую последовательность значений. Различают базовые таблицы - таблицы, определенные с помощью ее описания данных, и производственные таблицы, получаемые из одной или нескольких других таблиц путем выполнения некоторого запроса. База данных обычно содержит несколько таблиц. Одновременно можно работать только с одной базой данных. SQL - язык высокого уровня. SQL включает в себя небольшое число операторов. Каждый оператор оканчивается точкой с запятой. Основным оператором языка SQL, выполняющим отбор информации из базы данных, является оператор SELECT, который может быть задан следующим образом: SELECT<список столбцов, включаемых в ответ> FROM<список таблиц> WHERE<условие> Предложения SELECT (отобрать) и FROM (из) должны присутствовать обязательно. Сложные условия формируются с помощью операторов OR и AND. SQL позволяет запрашивать вычисляемые значения. В этом случае в предложении SELECT указывается выражение для вычисления значения столбца. SQL позволяет выполнять такие операции, как ввод, удаление или изменение данных.
Классификация БД. Модели и типы данных. Хранимые в базе данные имеют определенную логическую структуру — иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. К числу классических относятся следующие модели данных: • иерархическая, • сетевая, • реляционная. Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных: • постреляционная, • многомерная, • объектно-ориентированная. Разрабатываются также всевозможные системы, основанные на других моделях данных, расширяющих известные модели. В их числе можно назвать объектно-реляционные, дедуктивно-объектно-ориентирова
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 864; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.011 с.) |