
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Регрессионного и дискриминантного анализаСодержание книги
Поиск на нашем сайте
Общее: задачи каждой из перечисленных дисциплин опираются на анализ матрицы данных – матрицы наблюдений. Ее часто обозначают Х Это матрица значений (по столбцам) - регрессоров или признаков х1 х2 …xm. Но в этой матрице, наравне с столбцами х - признаки, участвуют строки d - объекты, - пэтому мы должны бы считать ее не только матрицей признаков х характеризующих объекты d но и матрицей объектов d содержащих в себе определенные значения признаков х.
признаки х характеризуют объекты d признак х1 на объект d1 принимает значение х11, признак х1 на объект d2 принимает значение х12 ………………………………………………….. признак хm на объект dn принимает значение хnm
- здесь объекты d характеризуют признаки х - объект d1 на признаке х1 принимает значение d11, - объект d1 на признаке х2 принимает значение d12 ……………………………………………….. объект dn на признаке хm принимает значение dnm.
Поэтому надо бы ее обозначать нейтральной буквой, не Х, не D а например Z.
Ну пусть будет Х – мы так привыкли, но имеем в виду, что эта матрица Х состоит равноправно из столбцов - признаков х и строк – объектов d и анализировать Х возможно, исходя из пространства столбцов х – признаков и исходя из пространства строк d – объектов. Напомню, что мы уже применяли такой подход в регрессионном анализе получая интерпретации решений и в пространстве переменных и в пространстве точек. Если это все что нам дано - то есть мы не имеем значения вектора У, который мы в РА трактовали как выход, то * анализ тесноты связей в Х естественно может сводится к анализу тесноты связей в 1. строках - объектах 2. столбцах – признаках. вопросы о структуре (направлении) связей, – более сложные вопросы - решаем в рамках статистичемкого причинно-следственного анализа И так (различия)
Именно этот аппарат позволяет выделять естественные группировки объектов которые могут реально соответствовать каким-то интерпретируемым классам.
2. второй тип анализа - степени близости признаков – проводится в пространстве объектов и результатом будут группировки (по тесноте связи) признаков. Тесноту связи определяют высокие значения парной корреляции
В пространстве объектов такие близкие связанные признаки будут образовывать пучки с не сильно отличающимися направляющими косинусами между ними. Обычно у каждой такой группы признаков существует общая причина влияющая на их вариации причем, латентная, то есть не присутстующая в нашем наборе признаков. Ее, эту причину, и называют фактором. Предметом ФА является поиск и попытки восстановления этих общих, для найденных групп признаков, и до сих пор нам неизвестных, переменных - факторов. Интересно что в факторном анализе существуют несколько техники – одна из них R-техника,основанная на анализе и выявлении общности признаков и нахождении факторов, другая Q-техника - аналогичные подходы и алгоритмы только относительно объектов.
Получается, что Q-техника, по сути, – это методы факторного анализа, примененные в целях кластеризации. Вот такая трактовка для методов ФА как инструмента Кл. анализа. Верно и обратное – специальные методы КлАнализа могут быть рассмотрены для анализа переменных и с этой точки зрения оценены для механизмов ФА. -------
Если в добавок к нашей матрице Х задан выходной вектор У
в виде значенийотносительной, абсолютной, интервальной переменных - то это предмет регрессионного (индуктивного) анализа и моделирования. Об этом мы уже говорили в 1 семестре.
А вот если е сли выходной вектор – назовем его здесь d, задан в виде значений категориальной ( порядковая или номинальная или дискретная фиктивная) переменной, группирующих объекты матрицы Х в классы -то на лицо постановка задачи классификации с учителем. То есть, задача классификации с учителем возникает, когда нам заданы группы или классы
Вот тогда вознакает классическая задача обучени с учителем которой занимается дисциплина Классификация с “Учителем ” или “Распознавание образов” Дисциплина занимается построением классификаторов У по заданной обучающей выборке Х для использования, затем, при определении класса новых объектов. ------------------ К слову – на практике мы проведем исследовательскую последовательную работу с выданным вам по вариантам матрицам наблюдений пациентов. Матрица данных по 75 признакам и характеризует состояние пациентов которым делали оперции протезирования клапанов сердца и операции аортокоронарного шунтирования. и фиксирует осложнения (норма, развитие серд недостаточности, наруш мозгового кровообращения, комби) Вы должны убедится насколько естественные группировки (по рез. кластерного анализа) соответствуют выделенным нами классам осложнений, и должны найти подклассы если они есть. Далее протащим нашу матрицу через дискриминантный анализ и факторный анализ.
Но начинаем работу с того чтобы выяснить не группируются ли в нашей матрице данные еще как нибудь, кроме как по выделенным нами классам. Именно в существовании подклассов часто возникают проблемы РО. Пример Основная гипотеза методов РО исходит того что пространство признаков подобрано целесообразно и поэтому концентрпрует в себе различия классов – а значит и отличия их средних. Поэтому основная гипотеза РО – гипотеза компактности классов в Х. Но что же происходит при наличии подклассов – см самый неприятный вариант.
Здесь средние классов совпадают и применяемый алгоритм должен строить сложную нелинейную границу. Если же выделить подклассы то задачу можно решить линейными границами.
Поэтому ваш кластерный анализ проводится сначала в полной матрице (важно – совпадут группировки по кластерам с нашими известными классами – если нет, то какие будут отличия и насколько значимы будут они) а затем проанализировать тоже самое но в каждом классе отдельно – не наблюдаются ли у нас явные подклассы
Затем прогоним данные через ЛР и получите бинарные классификаторы Затем тоже дискриминантным анализом, И завершим все поверкой как группируются наши признаки в этой задаче – то есть проведем факторный анализ. (логичнее было бы это сделатьв начале - до ЛГ и ДА но …..не играет особой роли) Особо любопытные попробуют провести клиссификацию уже не в исходном пространстве а в пространстве факторов (и канонических ДФ построенных на факторах) Это наша программа максимум на практических занятиях – и в сумме эта работа будет Вашей иллюстрацией к вопросам на экзамене. Начнем теперь с Этапа постановки задачи.
|
||||
|
|
Последнее изменение этой страницы: 2017-01-20; просмотров: 307; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.12.71.166 (0.006 с.) |

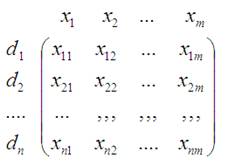 То есть в “ матрице признаков ” Х
То есть в “ матрице признаков ” Х И рассматривая ее же как “ матрицу объектов ” D
И рассматривая ее же как “ матрицу объектов ” D 1. первый анализ -степени близости строк (объектов d) проводится в пространстве признаков и это будут группы объектов D i – и вы сразу узнали тему кластерного анализа которым только что занимались.
1. первый анализ -степени близости строк (объектов d) проводится в пространстве признаков и это будут группы объектов D i – и вы сразу узнали тему кластерного анализа которым только что занимались.


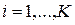 перечнем объектов
перечнем объектов 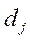 подряд по классам:
подряд по классам:
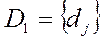 -
-  ,
,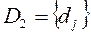
 ,….,.
,….,.
 )
)



