
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Часть 1 Статистический анализ случайных величинСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Часть 1 СТАТИСТИЧЕСКИЙ АНАЛИЗ СЛУЧАЙНЫХ ВЕЛИЧИН Задача 1. Статистический анализ одномерной последовательности случайных величин Цель работы: приобрести компетенции статистического анализа одномерной последовательности случайных величин. Задание: 1. Подготовить исходные данные. 2. Построить вариационный, статистический, группированный ряды. 3. Построить гистограмму, полигон, кумуляту, огиву. 4. Определить относительные частоты последовательности. 5. Определить: среднее арифметическое (по вариационному ряду), средневзвешенное (по группированному ряду), моду, медиану, дисперсию (по группированному ряду); среднее квадратическое отклонение, коэффициент вариации. 6. Рассчитать в программе Excel характеристики описательной статистики для заданной последовательности случайных величин.
Исходные данные
В качестве исходных данных принята [ числовые характеристики из нефтегазовой сферы ] (табл. 1).
Таблицы 1- Наименование случайной величины, е.и.
Вариационный ряд Вариационный ряд – (определение) Для заданной последовательности случайных величин вариационный ряд показан в (таблица 2).
Таблица 2- Вариационный ряд для _____________________________
Характеристиками вариационного ряда: - максимальное значение ряда Хmax = ______; - минимальное значение ряда Xmin = ______; - размах ряда R = Xmax – Xmin = _________.
Статистического ряда
Статистический ряд - – (определение). Для заданной последовательности случайных величин вариационный ряд показан в таблице 3.
Таблица 3- Статистический ряд случайных величин, k
Построение группированного (интервального) ряда
Группированный ряд – (определение). Для построения группированного ряда принято t = ______ интервалов. Ширина интервалов оправляются по формуле:
rt = R/t + Δt,
где - R – размах вариационного ряда; t – количество интервалов; Δ – малая величина, позволяющая исключить повтор границ интервалов (рекомендуется назначить равной 0,1% от размаха интервала).
Таблица 4 – Значения границ интервалов
Интервальный ряд представлен в таблице 5.
Таблица 5 - Группированный ряд
Гистограмма Гистограмма - (определине). Гистограмма построена по средним значениям группированного ряда (рис. 1)
Рисунок 1 - Гистограмма
Полигон
Полигон – (определение). Полигон показан на рисунке 2.
Рисунок 2 - Полигон
Кумулята Кумулята – (определение). Кумулята показан на рисунке 3.
Рисунок 3 - Кумулята Огива
Огива – (определение). Огива показан на рисунке 4.
Рисунок 4 – Огива
Объем выборки
Объём выборки определяется по формуле (3):
N=
где: ______________.
Относительные частоты
Относительная частота определяется по формуле:
W = ni/n = ____________________ = _________,
где ________________.
Значения относительных частот приведены в таблице 6.
Таблица 6- Расчет относительный частот
11. Среднее арифметическое:
Среднее арифметическое ряда определяется по формуле:
X=
Средневзвешенное значение статистического ряда определяется по формуле:
X=
где _______________________________.
Мода
Мода – (определение). Мода может быть определена по группированному ряду и для заданного ряда случайных величин имеет значение:
M = __________.
Медиана
Медианой называется – (определение). Медиана для заданного ряда имеет значение:
Me = ______ = ______.
Коэффициент вариации Коэффициент вариации определяется по формуле:
δ =
где ____________________________.
Вывод. ________________________________________________________
Исходные данные
В качестве исходных данных принято двух последовательных случайных величин: первая - _______________________________________________; вторая - ______________________________________________ Исходные данные представлены в таблице 1.
Таблица 1 – Исходные данные
Примем: в качестве аргумента Xi - __________________________; в качестве функции Yi - __________________________.
Визуальный анализ
Определение метода анализа
По данным таблицы 1 построен точечный график (рис. 1).
Рисунок 1 – Точечный график
Корреляционный анализ
Корреляционная зависимость – (определение). Корреляционный анализ выполнен с помощью пакета «Анализ данных» программы Excel, результаты которого показаны в таблице 2.
Таблица 2 - результаты корреляционного анализа
Вывод: _________________________________________________
Регрессионный анализ
Регрессионный анализ – (определение). Регрессионный анализ заданных последовательностей выполнен с помощью режима Регрессия пакета «Анализ данных» программы MS Excel. Сгенерируются результаты по регрессионной статистике, представленные в таблице 3.
Таблица 3- Результаты регрессионного анализа
Расчитанные в таблицах характеристики представляют собой: Дать описание приведенных в таблицах характеристик.
Регрессионные модели
Построение регрессионных моделей выполнено с помощью команды «Построение линии тренда» программы Excel. На нижеприведенных рисунках показаны различные регрессионные модели, описывающие связь между двумя заданными последовательностями случайных величин.
Рисунок 2 – Экспоненциальная модель
Рисунок 3 – Линейная модель
Рисунок 4 – Логарифмическая модель
Рисунок 5 – Полиномиальная модель
Рисунок 6 – Полиномиальная модель
В таблице 3 показаны сводные данные по всем построенным моделям.
Вывод: _______________________________________________
Заключение
________________________________________________________
Часть 2 ПЛАНИРОВАНИЕ ЭКСПЕРИМЕНТОВ
1. Реалистичное содержание целевой функции В качестве целевой функции (функции отклика, зависимой переменной, реакции системы на воздействие факторов Xi) Y принята _______________:
Y = f(Х1, Х2, Х3).
2. Реалистичное содержание (сущность) факторов
В качестве факторов функции отклика Xi принимаются:
X1 - _______________________________; X2 - _______________________________; Х3 - _______________________________.
Среднее значение фактора Среднее значение фактора определяется по формуле:
X10 = ______________________; X20 = ______________________; X30 = ______________________.
Заключение _________________________________________________________ Литература 1. Сидняев Н.И. Теория планирования эксперимента и анализ статистических данных: учебн. пособ. / Н.И. Сидняев. – М.: Изд-во Юрайт, 2011.- 399 с. 2. 2.Гмурман В.Е. Теория вероятностей и математическая статистика: учеб.пособ.-12-е изд., перераб. / В.Е. Гмурман.- М.: Изд-во Юрайт, 2010.- 479 с. 3. Гмурман В.Е. Руководство к решению задач по теории вероятностей и математической статистике: Учебн. пособ. -12-е изд., перераб. / В.Е. Гмурман. – М.: Высшобраз.,2006. – 476 с. 4. Боровков, А.А. Математическая статистика: Учебник / А. А. Боровков. – Изд. 4-е, стер. – Санкт-Петербург; М.; Краснодар: Лань, 2010. – 703 с. (электронный ресурс). 5. Адлер Ю.П., Маркова Е.В., Грановский Ю.В. Планирование эксперимента при поиске оптимальных условий. М.: Наука, 1976. 6. Асатурян В.И. Теория планирования эксперимента: Учеб. пособие для втузов. М.: Радио и связь, 1983. 7. Налимов В.В. Теория эксперимента. М.: Наука, 1971. 8. Планирование и организация измерительного эксперимента / Е.Т. Володаpский, Б.Н. Малиновский, Ю.М. Туз.-К.: В.ш. Головное изд-во, 1987.
Часть 1 СТАТИСТИЧЕСКИЙ АНАЛИЗ СЛУЧАЙНЫХ ВЕЛИЧИН
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-27; просмотров: 488; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.149.244.92 (0.007 с.) |




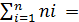 ___________________________.= _________,
___________________________.= _________,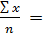 _______________ = ___________,
_______________ = ___________,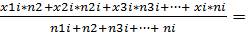 ______________________ = _____,
______________________ = _____,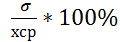 = ________= ______.
= ________= ______.
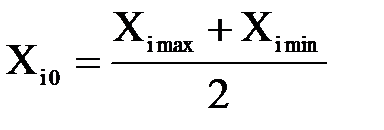 .
.


