Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Особенности фон Неймановской архитектуры ЭВМ.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Особенности фон Неймановской архитектуры ЭВМ. · Данные, подлежащие обработке, и команды кодированы одинаково. Информация кодировалась одинаково, но обрабатывалась по-разному. · Сильная централизация управления. · Неэффективное использование АЛУ. · Однопрограммный последовательный режим отсутствия параллельны вычислений.
Принципы фон Неймана
1. Использование двоичной системы счисления в вычислительных машинах. Преимущество перед десятичной системой счисления заключается в том, что устройства можно делать достаточно простыми, арифметические и логические операции в двоичной системе счисления также выполняются достаточно просто.
2. Программное управление ЭВМ. Работа ЭВМ контролируется программой, состоящей из набора команд. Команды выполняются последовательно друг за другом. Созданием машины с хранимой в памяти программой было положено начало тому, что мы сегодня называем программированием.
3. Память компьютера используется не только для хранения данных, но и программ. При этом и команды программы и данные кодируются в двоичной системе счисления, т.е. их способ записи одинаков. Поэтому в определенных ситуациях над командами можно выполнять те же действия, что и над данными.
4. Ячейки памяти ЭВМ имеют адреса, которые последовательно пронумерованы. В любой момент можно обратиться к любой ячейке памяти по ее адресу. Этот принцип открыл возможность использовать переменные в программировании.
Пост – фон Неймановская архитектура ЭВМ и её характеристики.
Многоуровневая архитектура ЭВМ.
Уровень 1: уровень Микроархитектуры На этом уровне находятся совокупности 8 или 32 регистров, которые формируют локальную память и схему, называемую АЛУ (арифметико-логическое устройство). АЛУ выполняет простые арифметические операции. Регистры вместе с АЛУ формируют тракт данных, по которому поступают данные. Тракт данных работает следующим образом. Выбирается один или два регистра, АЛУ производит над ними какую-либо операцию, например сложения, после чего результат вновь помещается в один из этих регистров. На некоторых машинах работа тракта данных контролируется особой программой, которая называется микропрограммой. На других машинах тракт данных контролируется аппаратными средствами.
На машинах, где тракт данных контролируется программным обеспечением, микропрограмма — это интерпретатор для команд на уровне 2. Микропрограмма вызывает команды из памяти и выполняет их одну за другой, используя при этом тракт данных. На компьютере с аппаратным контролем тракта данных происходит такая же процедура, но при этом нет программы, интерпретирующей команды уровня 2. Уровень 2: уровень архитектуры набора команд Уровень 2 мы будем называть уровнем архитектуры набора команд. Каждый производитель публикует руководство для компьютеров, которые он продает, под названием «Руководство по машинному языку X», «Принципы работы компьютера У» и т. п. Подобное руководство содержит информацию именно об этом уровне. Описываемый в нем набор машинных команд в действительности выполняется микропрограммой-интерпретатором или аппаратным обеспечением. Если производитель поставляет два интерпретатора для одной машины, он должен издать два руководства по машинному языку, отдельно для каждого интерпретатора. Уровень 4: уровень Ассемблера Уровень 4 представляет собой символическую форму одного из языков более низкого уровня. На этом уровне можно писать программы в приемлемой для человека форме. Эти программы сначала транслируются на язык уровня 1, 2 или 3, а затем интерпретируются соответствующей виртуальной или фактически существующей машиной. Программа, которая выполняет трансляцию, называется ассемблером. Структура памяти ЭВМ.
общем случае память современной ЭВМ включает в себя следующие иерархические уровни: · Сверхоперативная память (СОП), которая называется еще местной памятью. · Кэш-память, которая обычно отсутствует в простейших процессорных устройствах. В более сложных ЭВМ кэш имеет несколько уровней, причем кэш верхнего уровня всегда находится в кристалле процессора. · Оперативная (основная) память (ОП) или оперативное запоминающее устройство (ОЗУ), а также системное ПЗУ, объединенное с ОЗУ общим полем адресов. · Память с прямым доступом на магнитных дисках. · Память с последовательным доступом на магнитных лентах.
Устройства перечислены в порядке убывания быстродействия и увеличения объема.
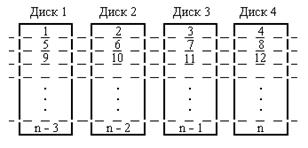
Использование кэш-памяти Организация дисковых массивов (RAID) Если просто объединить несколько дисков в (неизбыточный) массив, то среднее время между отказами (СВМО) будет равно СВМО одного диска, деленному на количество дисков. Такой показатель слишком мал для приложений, критичных к аппаратным сбоям. Улучшить его можно применяя реализуемую различным образом избыточность при хранение информации.
Стековая организация памяти Стековая память реализующая безадресное задание операндов, является эффективным элементом архитектуры ЭВМ. Стек представляет собой группу последовательно пронумерованных регистров (аппаратный стек) или ячеек памяти, снабженных указателем стека (обычно регистром), в котором автоматически при записи и считывании устанавливается номер (адрес) первой свободной ячейки стека (вершина стека). При операции записи заносимое в стек слово помещается в свободную ячейку стека, а при считывании из стека извлекается последнее поступившее в него слово. Таким образом, в стеке реализуется принцип LIFO «последний пришел - первый ушел».
Механизм стековой адресации поясняется на рис.8.4.
Предполагается, что область памяти для стека находится в сегменте стека, база которого определяется регистром SS - сегментным регистром стека. При добавлении записи в стек вначале проверяется, содержит ли указатель стека (ESP) значение, не меньше длины помещаемой в стек записи. При извлечении данных из стека содержимое ESP сравнивается с пределом SS. Когда обращение оказывается разрешенным, считываются данные по адресу SS:[ESP] и осуществляется инкремент ESP на 4. Извлечь данные из стека можно в регистр.
Таблица страниц виртуальной памяти и её характеристика. Номер виртуальной страницы используется в качестве индекса внутри таблицы страниц, который нужен для поиска записи для этой виртуальной страницы. Из записи в таблице страниц берется номер страничного блока. Номер страничного блока присоединяется к старшим битам смещения, заменяя собой номер виртуальной страницы, чтобы сформировать физический адрес, который может быть послан к памяти. Таким образом, предназначение таблицы страниц заключается в отображении виртуальных страниц на страничные блоки. С математической точки зрения таблица страниц — это функция, в которой в качестве аргумента выступает номер виртуальной страницы, а результатом является номер физического блока. При использовании результата этой функции поле виртуальной страницы в виртуальном адресе можно заменить полем страничного блока, формируя таким образом адрес физической памяти. Виртуальный адрес Page Global Directory(далее —PGD) — таблица (здесь и далее — то же самое, что директория) самого высокого уровня, каждая запись в ней — ссылка наPage Middle Directory(PMD), записи которой, в свою очередь, ссылаются на таблицуPage Table Entry(PTE). Записи вPTEссылаются на реальные физические адреса, а также хранят флаги состояния страницы. То есть, при трёхуровневой иерархии памяти виртуальный адрес будет выглядеть так:
Значения полей PGD, PMD и PTE — это индексы в соответствующих таблицах (то есть сдвиги от начала этих таблиц), а offset — это смещение адреса от начала страницы. В зависимости от архитектуры и режима страничной адресации, количество битов, выделяемых для каждого из полей, может отличаться. Кроме того, сама страничная иерархия может иметь число уровней, отличное от трёх: например, на x86 нет PMD.
Размер страницы В реальных (то есть не в учебных) системах используются страницы от 512 байт до 64 килобайт. Чаще всего размер страницы определяется архитектурой и является фиксированным для всей системы, например — 4 KiB. С одной стороны, при меньшем размере страницы память меньше фрагментируется. Ведь наименьшая единица виртуальной памяти, которая может быть выделена процессу — это одна страница, а программам очень редко требуется целое число страниц. А значит, в последней странице, которую запросил процесс, скорее всего останется неиспользуемая память, которая, тем не менее, будет выделена, а значит — использована неэффективно. С другой стороны, чем меньше размер страницы, тем больше размер страничных таблиц. Более того, при отгрузке на HDD и при чтении страниц с HDD быстрее получится записать несколько больших страниц, чем много маленьких такого же суммарного размера. АЛУ и его характеристика. АЛУ – одна из основных функциональных частей процессора, осуществляющая непосредственное преобразование информации.
Все операции, выполняемые в АЛУ, можно разделить на следующие группы: ¨ операции двоичной арифметики для чисел с фиксированной точкой; ¨ операции двоичной (шестнадцатеричной) арифметики для чисел с плавающей точкой; ¨ операции десятичной арифметики над числами, представленными в двоично-десятичном коде; ¨ операции адресной арифметики (при модификации адресов команд); ¨ операции специальной арифметики (нормализация, сдвиг); ¨ логические операции; ¨ операции над алфавитно-цифровыми полями.
Для выполнения перечисленных операций в АЛУ включают следующие функциональные узлы: ¨ сумматор (для выполнения суммирования и других действий над кодами операндов); ¨ регистры (для хранения кодов операндов на время выполнения действия над ними); ¨ сдвигатели (для сдвига кода на один или несколько разрядов вправо или влево); ¨ преобразователи (для преобразования прямого кода числа в обратный или дополнительный); ¨ комбинационные схемы (для реализации логических операций, мультиплексирования данных, управляемой передачи информации, формирования признаков результата).
Регистры и в некоторых случаях сумматоры имеют цепи управления приемом, выдачей и сбросом кодов операндов. Логические операции, операции сдвига и преобразования кодов могут выполняться не только специальными устройствами, но и с помощью дополнительных связей регистров и сумматора.
Центральной частью является сумматор. · Параллельный · Последовательный Сумматор параллельный, если операция сложения выполняется одновременно для всех цифр во всех разделах всех чисел. Сумматор последовательный, если операция сложения выполняется только с цифрами одного разряда.
Структура алу
Обобщенная структурная схема АЛУ (рис. 7.1) включает: - блок регистров для приема и размещения операндов и результатов; - операционный блок, в котором осуществляется преобразование операндов в соответствии с реализуемыми алгоритмами; - схемы контроля, обеспечивающие непрерывный оперативный контроль и диагностирование ошибок; - блок управления (БУ), в котором после приема кода операции (КОП) из центрального устройства управления формируются управляющие сигналы (УС), координирующие взаимодействие всех узлов АЛУ между собой и с другими блоками процессора.
Блок регистров связан с РОН центрального процессора и кэш-памятью данных.
Иногда АЛУ не содержит своего БР, в этом случае операционный блок непосредственно работает с регистрами общего назначения процессора. Для оперативного управления выполнением операции в ОБ на разных этапах анализируется преобразуемая информация и формируются сигналы признаков (флаги), которые используются в БУ для выработки и посылки в процессор сигнала признака результата (ПРез).
Для оценки АЛУ используются следующие характеристики: множество выполняемых операций, разрядность, время выполнения операций, надежностные и энергетические характеристики.
Быстродействие АЛУ. Быстродействие АЛУ во многом определяет производительность процессора. Причем важна не только частота тактового сигнала, которым тактируется АЛУ, но и количество тактов, необходимое для выполнения той или иной команды. Для повышения производительности разработчики стремятся довести время выполнения команды до одного такта, а также обеспечить работу АЛУ на возможно более высокой частоте. Один из путей решения этой задачи состоит в уменьшении количества выполняемых АЛУ команд, создание процессоров с уменьшенным набором команд (так называемые RISC-процессоры). Другой путь повышения производительности процессора — использование нескольких параллельно работающих АЛУ. Методы повышения быстродействия: Одним из таких методов является реализация принципа локального параллелизма. Суть этого принципа – в распараллеливании во времени алгоритма выполняемой отдельно команды на ряд независимых этапов и их реализации на различных операционных блоках АЛУ.
Второй хорошо известный метод – конвейерная обработка. Операционный блок разделяется на несколько частей – уровней конвейера. На каждой ступени выполняется определенная стадия операции (например, считывание операндов, сравнение порядков чисел, сложение мантисс чисел и так далее). Совмещение стадий выполнения нескольких операций на различных ступенях конвейера приводит к тому, что реализация следующей операции начинается до окончания предыдущей. Это значительно увеличивает быстродействие операционного блока. Другой способ сокращения длительности выполнения многотактных операций – использование эффективных алгоритмов. При использовании таких алгоритмов сочетается использование быстродействующих блоков, одновременно анализа нескольких разрядов операндов и реализация конвейерного метода обработки. Наиболее новый способ увеличения быстродействия всех блоков процессора ЭВМ – введение векторных операций – операций над упорядоченными массивами данных (в суперЭВМ векторные операции появились давно, в связи с чем в составе процессоров появилась специализация устройств по типам операндов – скалярные и векторные).
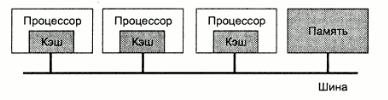
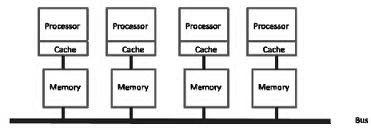
Задание формата микрокоманд. Всего в алгоритме 45 вершины, включая выдачу сигнала начала, и сигнала окончания работы. Следовательно нам потребуется ПЗУ с количеством >32 адресов. Существует ПЗУ 32х8 (К155РЕ3), его и будем использовать(4 шт). Рассмотрим формат управляющей МК. Формат МК включает пять полей: РСЛ[0/5] - АДРПЕР - адрес перехода, причем разряд РСЛ[5] используется для принудительной модификации адреса. РСЛ[6/8] - поле логического условия ЛУ. Для кодирования ЛУ используются 4 комбинации, а пятая (все нули) - для организации безусловного формирования пятого разряда адреса; РСЛ[9/15] - поле управляющего сигнала (необходимо 6 бита) См фото лекций Мультипроцессорные системы Типичная архитектура, используемая в мультипроцессорных системах - шинная. Характерная особенность - все процессоры имеют прямой доступ к общей памяти. Когда процессор А записывает слово в память, а процессор В микросекундой позже считывает слово из памяти, процессор В получает в точности информацию, записанную туда процессором А. Память, обладающая таким поведением называется согласованной (coherent). Проблема такой схемы в том, что уже при наличии 4-5 процессоров шина данных оказывается сильно перегруженной и общая производительность системы резко падает. Решением этой проблемы является размещение между процессором и шиной высокоскоростной кэш-памяти.
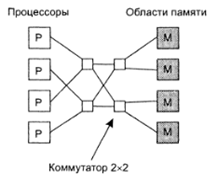
Если запрашиваемые данные находятся в кэше, то не произойдет обращения к шине. Если размер кэш-памяти достаточно велик, вероятность успеха (коэффициент кеш-попаданий, hit rate) велика и трафик на шине снижается, позволяя включить в систему большее количество процессоров. Однако очевидно, что введение кэша порождает проблему несогласованности памяти. Изменение данных в памяти одним процессором должно каким-то образом синхронизироваться с кэшем всех процессоров. Шинная архитектура накладывает ограничение на количество процессоров в системе. Ориентировочно 256 процессоров - реальный потолок таких систем, не смотря на использование кэша. Один из вариантов решения проблемы этого ограничения шинной архитектуры - разделение общей памяти на модули и связь их с процессорами с помощью коммутирующей решетки (crossbar switch). С ее помощи каждый процессор может быть связан с каждым модулем памяти.
Достоинство узловых коммутаторов также и в том, что к памяти могут одновременно получить доступ несколько процессоров (естественно не любые комбинации допустимы). Недостаток данного подхода в том, что при N процессорах и M модулей памяти потребуется NxM узлов решетки. Соответственно при росте количества процессоров/блоков памяти опять возникает проблема физической реализуемости системы. Один их вариантов решения данной проблемы - коммутирующая омега-сеть, например такая:
Еще один способ уменьшения затрат на коммутацию - переход к иерархическим системам. В таких системах с каждым процессором ассоциируется некоторая область памяти, к которой данный процессор получает максимально быстрый доступ. Доступ-же к памяти, ассоциированной с другими процессорами происходит существенно медленнее. Термин - NUMA (Non-Uniform Memory Access):
Мультикомпьютерные системы
Наибольшее число существующих в настоящее время распределенных систем построено по схеме гетерогенных мультикомпьютерных. Это означает, что компьютеры, являющиеся частями этой системы, могут быть крайне разнообразны, например, по типу процессора, размеру памяти и производительности каналов ввода-вывода. Другим примером гетерогенности является создание крупных мультикомпьютерных систем с использованием существующих сетей и каналов. В глобальных системах различные станции могут, в свою очередь, соединяться общедоступными сетями, например сетевыми службами, предлагаемыми коммерческими операторами связи В мультикомпьютерах каждый процессор имеет свою собственную память, к которой другие процессоры не могут получить прямой доступ (NORMA – NO-Rremote Memory Access). Программы на разных процессорах в мультикомпьютере взаимодействуют друг с другом с помощью примитивов send и receive, которые используются для передачи сообщений. Все мультикомпьютеры сходны в одном: когда программа выполняет примитив send, процессор передачи данных получает уведомление и передает блок данных в целевую машину (воможно, после предварительного запроса и получения разрешения). Мультикомпьютеры очень трудно нормально классифицировать. Однако можно выделить два наиболее общих типа: МРР и COW.
Массивно-параллельная система (на рисунке) – высокопроизводительная параллельная вычислительная система, создаваемая с использованием специализированных вычислительных модулей и систем связи. Второй тип мультикомпьютеров – это системы COW (Cluster of Workstations – кластер рабочих станций) или NOW (Network of Workstations – сеть рабочих станций). Обычно кластер состоит из множества ПК или рабочих станций, соединенных посредством сетевых плат. Особенности фон Неймановской архитектуры ЭВМ. · Данные, подлежащие обработке, и команды кодированы одинаково. Информация кодировалась одинаково, но обрабатывалась по-разному. · Сильная централизация управления. · Неэффективное использование АЛУ. · Однопрограммный последовательный режим отсутствия параллельны вычислений.
Принципы фон Неймана
1. Использование двоичной системы счисления в вычислительных машинах. Преимущество перед десятичной системой счисления заключается в том, что устройства можно делать достаточно простыми, арифметические и логические операции в двоичной системе счисления также выполняются достаточно просто.
2. Программное управление ЭВМ. Работа ЭВМ контролируется программой, состоящей из набора команд. Команды выполняются последовательно друг за другом. Созданием машины с хранимой в памяти программой было положено начало тому, что мы сегодня называем программированием.
3. Память компьютера используется не только для хранения данных, но и программ. При этом и команды программы и данные кодируются в двоичной системе счисления, т.е. их способ записи одинаков. Поэтому в определенных ситуациях над командами можно выполнять те же действия, что и над данными.
4. Ячейки памяти ЭВМ имеют адреса, которые последовательно пронумерованы. В любой момент можно обратиться к любой ячейке памяти по ее адресу. Этот принцип открыл возможность использовать переменные в программировании.
|
||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-26; просмотров: 2799; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.118.218 (0.016 с.) |