Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Прерывание вычислений и его организация.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Выполнение прерывания в компьютере: tр - время реакции процессора на запрос прерывания; tс - время сохранения состояния прерываемой программы и вызова обработчика прерывания; tв - время восстановления прерванной программы
После появления сигнала запроса прерывания ЭВМ переходит к выполнению программы -обработчика прерывания. Обработчик выполняет те действия, которые необходимы в связи с возникшей особой ситуацией. Например, такой ситуацией может быть нажатие клавиши на клавиатуре компьютера. Тогда обработчик должен передать код нажатой клавиши из контроллера клавиатуры в процессор и, возможно, проанализировать этот код. По окончании работы обработчика управление передается прерванной программе. Время реакции-это время между появлением сигнала запроса прерывания и началом выполнения прерывающей программы (обработчика прерывания) в том случае, если данное прерывание разрешено к обслуживанию. Шины. Структура, характеристики. Важным критерием, определяющим характеристики шины, может служить ее целевое назначение. По этому критерию можно выделить: • шины «процессор-память»; • шины ввода/вывода; • системные шины.
Шина «процессор-память» Шина обеспечивает непосредственную связь между центральным процессором (ЦП) вычислительной машины и основной памятью (ОП). В со-} временных микропроцессорах такую шину часто называют шиной переднего плана и обозначают аббревиатурой FSB (Front-Side Bus). Интенсивный трафик процессором и памятью требует, чтобы полоса пропускания шины, то есть количе- ство информации, проходящей по шине в единицу времени, была Роль этой шины иногда выполняет системная шина (см. ниже), однако в пла-. не эффективности значительно выгоднее, если обмен между ЦП и ОП ведется по отдельной шине. К рассматриваемому виду можно отнести также шину, зывающую процессор с кэш-памятью второго уровня, известную как шина зад- '" него плана - BSB (Back-Side Bus). BSB позволяет вести обмен с большей скоростью, чем FSB, и полностью реализовать возможности более скоростной] кэш-памяти.
Шина ввода/вывода Шина ввода/вывода служит для соединения процессора (памяти) с устройствами ввода/вывода (УВВ). Учитывая разнообразие таких устройств, шины ввода/вывода унифицируются и стандартизируются. Связи с большинством УВВ (но не] с видеосистемами) не требуют от шины высокой пропускной способности. При проектировании шин ввода/вывода в учет берутся стоимость конструктива и соединительных разъемов. Такие шины содержат меньше линий по сравнению с ва- риантом «процессор-Память», но длина линий может быть весьма большой. Типичными примерами подобных шин могут служить шины PCI и SCSI.
Системная шина С целью снижения стоимости некоторые ВМ имеют общую шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Системная шина служит для физического и логического объединения всех устройств ВМ. Поскольку основные устройства машины, как правило, размещаются на общей монтажной плате, системную шину часто называют объединительной шиной (backplane bus), хотя эти термины нельзя считать строго эквивалентными. Системная, шина в состоянии содержать несколько сотен линий. Совокупность линий шины можно подразделить три функциональные группы (рис. 4.4): шину данных, шину адреса и шину управления. К последней обычно относят также линии для подачи питающего напряжения на подключаемые к системной шине модули.
Основные характеристики шины Разрядность шины определяется числом параллельных проводников, входящих в нее. Первая шина ISA для IBM PC была восьмиразрядной, т. е. по ней можно было одновременно передавать 8 бит. Системные шины современных ПК, например, Pentium IV — 64-разрядные. Пропускная способность шины определяется количеством байт информации, передаваемых по шине за секунду. Для определения пропускной способности шины необходимо умножить тактовую частоту шины на ее разрядность. Например, для 16-разрядной шины ISA пропускная способность определяется так: (16 бит * 8,33 МГц): 8 = 16,66 Мбайт/с.
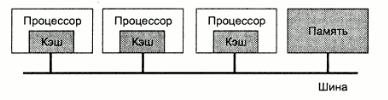
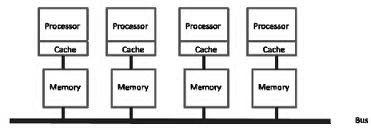
См фото лекций Мультипроцессорные системы Типичная архитектура, используемая в мультипроцессорных системах - шинная. Характерная особенность - все процессоры имеют прямой доступ к общей памяти. Когда процессор А записывает слово в память, а процессор В микросекундой позже считывает слово из памяти, процессор В получает в точности информацию, записанную туда процессором А. Память, обладающая таким поведением называется согласованной (coherent). Проблема такой схемы в том, что уже при наличии 4-5 процессоров шина данных оказывается сильно перегруженной и общая производительность системы резко падает. Решением этой проблемы является размещение между процессором и шиной высокоскоростной кэш-памяти.
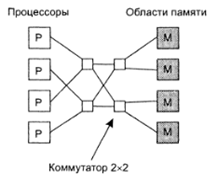
Если запрашиваемые данные находятся в кэше, то не произойдет обращения к шине. Если размер кэш-памяти достаточно велик, вероятность успеха (коэффициент кеш-попаданий, hit rate) велика и трафик на шине снижается, позволяя включить в систему большее количество процессоров. Однако очевидно, что введение кэша порождает проблему несогласованности памяти. Изменение данных в памяти одним процессором должно каким-то образом синхронизироваться с кэшем всех процессоров. Шинная архитектура накладывает ограничение на количество процессоров в системе. Ориентировочно 256 процессоров - реальный потолок таких систем, не смотря на использование кэша. Один из вариантов решения проблемы этого ограничения шинной архитектуры - разделение общей памяти на модули и связь их с процессорами с помощью коммутирующей решетки (crossbar switch). С ее помощи каждый процессор может быть связан с каждым модулем памяти.
Достоинство узловых коммутаторов также и в том, что к памяти могут одновременно получить доступ несколько процессоров (естественно не любые комбинации допустимы). Недостаток данного подхода в том, что при N процессорах и M модулей памяти потребуется NxM узлов решетки. Соответственно при росте количества процессоров/блоков памяти опять возникает проблема физической реализуемости системы. Один их вариантов решения данной проблемы - коммутирующая омега-сеть, например такая:
Еще один способ уменьшения затрат на коммутацию - переход к иерархическим системам. В таких системах с каждым процессором ассоциируется некоторая область памяти, к которой данный процессор получает максимально быстрый доступ. Доступ-же к памяти, ассоциированной с другими процессорами происходит существенно медленнее. Термин - NUMA (Non-Uniform Memory Access):
Мультикомпьютерные системы
Наибольшее число существующих в настоящее время распределенных систем построено по схеме гетерогенных мультикомпьютерных. Это означает, что компьютеры, являющиеся частями этой системы, могут быть крайне разнообразны, например, по типу процессора, размеру памяти и производительности каналов ввода-вывода. Другим примером гетерогенности является создание крупных мультикомпьютерных систем с использованием существующих сетей и каналов. В глобальных системах различные станции могут, в свою очередь, соединяться общедоступными сетями, например сетевыми службами, предлагаемыми коммерческими операторами связи В мультикомпьютерах каждый процессор имеет свою собственную память, к которой другие процессоры не могут получить прямой доступ (NORMA – NO-Rremote Memory Access). Программы на разных процессорах в мультикомпьютере взаимодействуют друг с другом с помощью примитивов send и receive, которые используются для передачи сообщений. Все мультикомпьютеры сходны в одном: когда программа выполняет примитив send, процессор передачи данных получает уведомление и передает блок данных в целевую машину (воможно, после предварительного запроса и получения разрешения). Мультикомпьютеры очень трудно нормально классифицировать. Однако можно выделить два наиболее общих типа: МРР и COW.
Массивно-параллельная система (на рисунке) – высокопроизводительная параллельная вычислительная система, создаваемая с использованием специализированных вычислительных модулей и систем связи. Второй тип мультикомпьютеров – это системы COW (Cluster of Workstations – кластер рабочих станций) или NOW (Network of Workstations – сеть рабочих станций). Обычно кластер состоит из множества ПК или рабочих станций, соединенных посредством сетевых плат.
|
||||
|
|
Последнее изменение этой страницы: 2016-08-26; просмотров: 456; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.58.52.94 (0.011 с.) |