
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 3. Парный регрессионный анализСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
3.1. Спецификация модели парной линейной регрессии 3.2. Сравнительный анализ методов определения параметров парной регрессии 3.3. Содержание и особенности применения метода наименьших квадратов (МНК) в расчете параметров парной линейной регрессионной модели. Свойства оценок МНК 3.4. Спецификация модели и вычисление параметров нелинейных парных регрессионных моделей при помощи МНК 3.5. Линеаризация нелинейных моделей 3.6. Оценка качества парных регрессионных моделей 3.7. Ограничения использования регрессионных моделей Основные положения Парная регрессионная модель (регрессия) – это эконометрическая модель, описывающая зависимость между двумя факторами. Общий вид такой модели:
Наиболее простой и часто использующейся является линейная парная регрессионная модель, имеющая вид:
Выражение 3.2 представляет собой спецификацию линейной регрессионной модели. Вообще под спецификацией модели понимают аналитическое выражение описывающей модель функции. Само уравнение линейной регрессии имеет вид:
где a0 и a1 – оценки теоретических коэффициентов регрессии α0 и α1 Следовательно, регрессионную модель можно представить в виде: Основная задача регрессионного анализа после спецификации модели – оценка неизвестных параметров – α0 и α1, дающих наибольшее приближение модели к эмпирическим данным:
где a0 и a1 – оценки неизвестных параметров; e – оценка случайной компоненты. Для определения коэффициентов можно использовать различные методы (рис. 3.1):
Рис. 3.1 Основные методы расчета коэффициентов регрессии
Метод средних применяется в том случае, когда в уравнении регрессии присутствует только один неизвестный параметр (например, a1 – y = a1x). В этом случае его значение определится следующим образом:
Метод проб заключается в том, что всем параметрам, кроме одного, задаются фиксированные значения, исходя из особенностей эмпирических данных. Значение последнего, неизвестного параметра определяется по методу средних. Например, если зафиксировать значение, принимаемое y при x, равном 0 (нулевой уровень y – y0), то параметр a1 определится по формуле:
Эта процедура может повторяться (для различных зафиксированных значений) до тех пор, пока качество теоретической модели не станет удовлетворительным. Метод выбранных точек основан на визуальном анализе корреляционного поля и выборе точек, наиболее точно отражающих тенденции развития анализируемого явления. Количество точек должно совпадать с количеством неизвестных параметров. Так, для парной линейной регрессии выбирается 2 точки. Через них проходит только одна прямая, уравнение которой определится как решение системы относительно a0 и a1:
В результате решения такой системы можно рассчитать значения a0 и a1 по формулам:
В общем виде смысл математических методов можно определить как решение задачи минимизации функционала F, формируемого на основе суммирования отклонений эмпирических данных от результата расчета (чисто случайных составляющих) по регрессионной модели:
где g() – функция, определяющая аналитическую форму измерения разброса фактических данных от модели. Наиболее распространены два вида функции g():
в том случае, если расчет выполнен по формуле (3.10), говорят о методе наименьших квадратов (МНК), если по формуле (3.11) – о методе наименьших модулей (МНМ). Результаты сравнительного анализа этих методов приведены ниже:
Рис. 3.2 Сравнительный анализ основных математических методов определения параметров уравнения регрессии.
Для совмещения достоинств этих методов разработана более сложная кусочно заданная функция Хубера:
где с – параметр, показывающий границу, начиная с которой в качестве меры отклонения используется модуль (при меньших – квадрат), чем он больше, тем сильнее чувствительность. Для снижения чувствительности g() к выбросам (значениям, выбивающимся из общей тенденции) Пиндайк и Рубинфелд ввели функцию:
Рассмотрите сущность и особенности применения метода максимального правдоподобия
Наибольшее распространение в настоящее время получил метод наименьших квадратов. Рассмотрим условия применения МНК, основной алгоритм расчета параметров и свойства оценок параметров, полученных в результате его применения. Условия применения (предпосылки) МНК (условия Гаусса – Маркова). 1. Математическое ожидание случайного отклонения равно 0 для всех наблюдений: M(ε)=0 2. Дисперсия случайных отклонений постоянна: 3. Случайные отклонения независимы друг от друга:
4. Случайное отклонение независимо от объясняющих переменных регрессионной модели: 5. Модель линейна относительно параметров Математически условие минимизации квадратов отклонений запишется следующим образом:
найдем минимум F относительно a0 и a1, вычислив частные производные F по a0 и a1 и прировняв их к 0:
преобразуем полученную систему:
раскрыв скобки, получаем стандартную форму нормальных уравнений для вычисления коэффициентов линии регрессии.
решив это уравнение относительно a0 и a1, получим оценки параметров теоретического уравнения α0 и α1, обладающие всеми основными свойствами качественных оценок: (по теореме Гаусса-Маркова): несмещенность, эффективность, состоятельность. Это обуславливает широкое использование МНК в эконометрических расчетах. Для линейной модели существует упрощенный способ расчета параметров, основанный на решении системы (3.14)
Однако не все фактические данные могут быть описаны при помощи линейной модели. В этом случае используется нелинейная регрессия. Для того, чтобы определить, какую аналитическую форму регрессионной модели выбрать, используют следующий алгоритм (применяется для каждой гипотезы об определенной аналитической форме регрессии) (рис. 3.3). Следует отметить, что этот алгоритм применим только в случае монотонной зависимости между факторами.
Рис. 3.3 Алгоритм определения аналитической формы регрессии Расчет параметров нелинейных регрессионных моделей основан на том же методе, что и для линейной регрессии. Основное требование – уравнение регрессии должно быть либо линейно относительно параметров, либо преобразуемо в такое уравнение (это преобразование называется линеаризацией). В случае параболической модели и полиномиальной модели более высокой степени система уравнений для определения параметров претерпевает очевидные изменения (3.20):
где a0, a1 и a2 – оценки параметров в уравнении регрессии В случае линеаризации происходит замена переменных в уравнении регрессии с тем, чтобы привести его к линейному виду. Обратите внимание, что линеаризованы могут быть функции с числом параметров, равным числу параметров в соответствующей линейной модели (для парной регрессии – с двумя параметрами), поэтому по сравнению с таблицей 1.1 аналитические выражения для основных функций претерпели определенные изменения. Рассмотренные модели также можно комбинировать, получая линейные преобразования для других исходных моделей. Таблица 3.2 Линеаризация основных видов регрессионных моделей
В оценке качества парных регрессионных моделей можно выделить следующие основные этапы (рис. 3.4): 1. Анализ адекватности модели в целом 2. Анализ точности определения оценок коэффициентов регрессии 3. Проверка статистической значимости коэффициентов регрессионного уравнения 4. Интервальная оценка коэффициентов регрессионного уравнения при заданном уровне значимости 5. Определение доверительных интервалов для зависимой переменной (для среднего значения и для индивидуальных значений)
Рис. 3.4 Анализ качества регрессионной модели
Рассмотрим каждый этап подробно: I. Для определения адекватности модели в целом используется теоретический коэффициент детерминации(коэффициент детерминации, R2). Коэффициент детерминации показывает, какая доля вариации независимой переменной объяснена на основе построенной регрессионной модели:
где
R2 принимает значения от 0 до 1, причем чем ближе его значение к 1, тем лучше построенная модель описывает фактическую зависимость. Так как
где В этом случае формула (3.21) будет иметь вид:
откуда можно сделать вывод, что качество модели будет тем выше, чем меньше вариация случайного остатка. После несложных преобразований получаем формулы, часто используемые в практических расчетах:
Значение теоретического коэффициента детерминации связано со значением линейного коэффициента корреляции между теоретическими и фактическими значениями результативного признака:
Вывод о приемлемости регрессионной модели для описания фактических данных можно сделать, учитывая объем анализируемой совокупности, число переменных и прочие факторы. Обычно значение R2 не превышает 0,7 (исключение составляют временные ряды с четко выраженным трендом, для которых это значение приближается к 1). Для точной оценки статистической значимости коэффициента детерминации используют F-критерий:
Полученное фактическое значение сравнивают с критическим Fα; 1; n-2, если расчетное значение оказывается больше критического, то нулевая гипотеза отвергается и делается вывод о статистической значимости коэффициента детерминации. Для статистически значимого коэффициента детерминации может быть проведена интервальная оценка при помощи z -распределения Фишера. Порядок оценки следующий: рассчитывают величину II. Анализ точности определения оценок регрессии осуществляется путем вычисления дисперсий коэффициентов регрессии. Для линейной регрессионной модели
Таким образом, оценки коэффициентов будут тем точнее, чем меньше значение необъясненной дисперсии. Значения дисперсий коэффициентов регрессии и корни квадратные из них – стандартные ошибки коэффициентов регрессии – используются на следующем этапе для проверки статистической значимости коэффициентов регрессии. III. Оценка статистической значимости коэффициента регрессии осуществляется путем проверки гипотезы о равенстве этого коэффициента 0. Для коэффициента a1 такая гипотеза будет иметь вид: H0: a1 = 0 H1: a1 ≠ 0 Для проверки этой гипотезы пользуются t-статистикой:
это соотношение имеет распределение Стьюдента с числом степеней свободы, равным (n – 2). Расчетное значение t сравнивают с критическим Для предварительной «грубой» оценки статистической значимости коэффициентов регрессии можно пользоваться следующим правилом: Таблица 3.2 Правило «грубой» оценки статистической значимости
Это правило позволяет достаточно точно установить значимость коэффициентов регрессии при n > 10. IV. Интервальная оценка коэффициентов регрессионного уравнения осуществляется для того, чтобы получить более полное представление о характере регрессионной зависимости между переменными. Ее результатом будут доверительные интервалы для каждого коэффициента: для α0 – для α1 – Доверительный интервал определяет границы, в которых будет находиться значение теоретического коэффициента регрессии с уровнем значимости α. Уровень значимости α определяется исходя из требуемой точности. Обычно – 0.1, 0.05 или 0.01. V. Расчет доверительных интервалов для зависимой переменной позволяет решить две задачи: во-первых, провести интервальную оценку математического ожидания зависимой переменной для конкретного значения независимой переменной и заданного уровня значимости, и, во-вторых, определить границы, за пределами которых может оказаться не более чем α-ая доля индивидуальных значений зависимой переменной для конкретного значения независимой переменной. Первая задача решается путем нахождения доверительного интервала для зависимой переменной по формуле:
Для каждого значения xp из области, в которой находятся значения независимой переменной, определяются доверительные интервалы. Они будут наименьшими при
Рис. 3.5 Доверительные интервалы для зависимой переменной. Более широкие интервалы – для индивидуальных значений, более узкие – для средних (уровень значимости 1 %). По данным Госкомстата за 1999 – 2003 год Вторая задача решается путем вычисления доверительного интервала
Как видно, во втором случае доверительные пределы будут шире, что свидетельствует о том, что оценка индивидуальных значений осуществляется с меньшей точностью. (см. рис. 3.5) Регрессионный анализ является эффективным инструментом познания экономической действительности, однако существуют ограничения, нарушение которых может привести к неверным выводам и некачественной трактовке результатов. Эти ограничения связаны со следующими ошибками: 1. Использование регрессионной модели для прогнозирования вне границ изменения наблюдаемых данных. Прогнозирование на основе регрессионных моделей может осуществляться только на основе экстраполяции, в противном случае возможны серьезные ошибки. 2. Смешение понятий причинно-следственной и регрессионной зависимости. По наличию статистической связи нельзя делать вывод о том, что взаимосвязанные явления влияют друг на друга. 3. Перенесение прошлых тенденций в ряде динамики на будущее. Поскольку исторические условия в прошлом и будущем различаются. 4. Выявление нереальных (ошибочных) связей. Для проведения регрессионного анализа и трактовки его результатов необходима теоретическая гипотеза о взаимосвязи исследуемых переменных. В том случае, если удастся избежать перечисленных выше ошибок, результаты регрессионного анализа могут с успехом использоваться при выявлении экономических закономерностей, социально-экономическом прогнозировании и разработке экономической политики. Вопросы для самоконтроля 1) Дайте определение спецификации модели 2) Сколько параметров в спецификации модели линейной парной регрессии? 3) Запишите уравнение парной линейной регрессии. 4) Назовите основные методы расчета коэффициентов регрессии. 5) Какие достоинства и недостатки МНК по сравнению МНМ Вы можете назвать? 6) Каким образом задается функция Хубера? Для чего она используется? 7) Перечислите предпосылки МНК. 8) На каком основном принципе основан МНК? 9) Каким образом можно установить наиболее подходящую аналитическую форму регрессионной модели? 10) Для чего используется линеаризация? Каким образом она осуществляется? 11) Какие этапы оценки качества регрессионных моделей Вы знаете? 12) Что показывает коэффициент детерминации? 13) Как зависит коэффициент детерминации от суммы квадратов случайных отклонений? 14) Каким образом связаны между собой линейный коэффициент корреляции и коэффициент детерминации? 15) Что показывают дисперсии коэффициентов регрессии? 16) Как проверяется статистическая значимость коэффициентов регрессии? 17) Какие задачи решаются в ходе интервальной оценки зависимой переменной? Какая из них, на ваш взгляд, имеет большую практическую значимость и почему? 18) Перечислите ограничения использования регрессионных моделей. Задания и задачи 1. Запишите спецификацию линейной регрессии зависимости экспорта от импорта. По представленным в таблице данным о внешнеэкономической деятельности РФ в 2002 году определите значения параметров модели, используя различные методы.
Для каждой модели рассчитайте значения коэффициента детерминации. По результатам расчета заполните таблицу:
2. Проведите линеаризацию следующих функций:
3. По данным из задания 1 постройте 3 нелинейные парные регрессии. Обоснуйте выбор моделей при помощи соответствующего алгоритма. Оцените качество моделей по коэффициенту детерминации и сравните с моделью линейной регрессии. 4. Оцените статистическую значимость коэффициентов уравнения линейной регрессии, построенной в задании 1, при уровне значимости 0,05; 0,01. 5. Проведите интервальную оценку параметров линейной регрессионной модели по данным из задания 1. 6. Произведите расчет и постройте графики доверительных интервалов для зависимой переменной (для среднего значения и для индивидуальных значений) при 5%-м уровне значимости. Сделайте выводы. 7. Для данных из таблицы выполните задания 1, 3 – 5.
Тесты 1. Какая из мер отклонения аппроксимирующей функции от набора наблюдений наиболее чувствительна к выбросам: a. сумма модулей отклонений b. сумма квадратов отклонений c. сумма отклонений d. разница отклонений 2. Какому условию удовлетворяет решение линейной регрессионной модели по методу наименьших квадратов: a. построенная функция наилучшим образом отражает реальную зависимость b. уравнение регрессии наилучшим образом подходит для аппроксимации зависимости c. сумма квадратов отклонений фактических значений от значений регрессионной модели – наименьшая из возможных 3. Коэффициент детерминации R2: a. показывает точность соответствия регрессионной модели фактическим данным b. дает представление о том, как часто фактические значения оказываются больше расчетных c. является абсолютной величиной 4. Что из перечисленного относится к причинам возникновения ошибки e в уравнении линейной парной регрессии: 1) линейный характер регрессионной модели 2) учет ограниченного числа переменных в модели 3) трудности в измерении данных 4) вариация эндогенных факторов модели Варианты ответа b. 1,2,3,4 c. 1,2 d. 2,3 e. 1,3,4 5. Какая из приведенных формул связи коэффициента детерминации с коэффициентом корреляции верна ( a. b. c. 6. Какой из этапов оценки качества регрессии позволяет судить об адекватности модели в целом? a. расчет доверительных интервалов для параметров b. расчет доверительных интервалов для зависимой переменной c. расчет коэффициента детерминации d. расчет ошибок коэффициентов 7. Что из перечисленного относится к ограничениям регрессионного анализа? 1) возможность прогнозирования только внутри границ измеряемых данных 2) возможность учета не более двух факторов 3) вероятность получения нереальных связей 4) сложности расчета значений параметров Варианты ответа a. 1,2,3,4 b. 1,2 c. 2,3 d. 1,4 e. 2,4 8. Согласно правила «грубой» оценки статистической значимости коэффициентов регрессионного уравнения, какое из значений t-статистики свидетельствует о существенной значимости коэффициента? a. –0,2 b. 0,91 c. 1,34 d. 2,12 e. 7,22 9. Какую функциональную форму модели следует выбрать, если известно, что:
a. линейная b. гиперболическая c. показательная d. логарифмическая 10. Значим ли коэффициент детерминации, если его значение – 0,60 а n=22 (F0,05;2;20 = 3,49, F0,01;2;20 = 5,85) a. значим на 5 %-м уровне b. значим на 1 %-м уровне c. не значим d. недостаточно данных для ответа 11. Какой из доверительных интервалов для зависимой переменной шире: для индивидуального значения или для среднего? a. для среднего b. для индивидуальных значений c. нельзя сказать однозначно 12. Можно ли сделать вывод о том, что коэффициент a1 статистически значим, если a. можно в любом случае b. можно, если a1 > 0,2 a0 c. можно, если n > 30 d. нельзя 13. Какая из представленных моделей не может быть линеаризована? a. b. c. d. Список литературы 1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. – М.ЮНИТИ, 1998. – с. 621 – 632; 751 – 766. 2. Бородич С.А. Эконометрика: Учебное пособие. – Мн.: Новое знание, 2001. – с. 98 – 115; 121 – 147; 200 – 222 3. Доугерти К. Введение в эконометрику: Пер. с англ. – М.: ИНФРА-М, 1999. – XIV, с. 53 – 111 4. Кремер Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов / Под ред. Проф. Н.Ш. Кремера. – М.: ЮНИТИ-ДАНА, 2002. – с. 50 – 80 5. Кулинич Е.И. Эконометрия. – М.: Финансы и статистика, 2001. с. 43 – 83 6. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. 2-е изд. – М.: Дело, 1998. – с. 17 – 42 7. Практикум по эконометрике: Учебное пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2002. – с. 5 – 48 8. Теория статистики: Учебник / под редакцией Р.А. Шмойловой. – 3-е изд. – М.: Финансы и статистика, 1999. – с. 289 – 295 9. Эконометрика: Учебник / Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2002. – с.34 – 88
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-01; просмотров: 1118; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.133.143.118 (0.014 с.) |

 (3.1)
(3.1) (3.2)
(3.2) (3.3)
(3.3) , где
, где  – объясненная на основе построенной модели составляющая y, а ε – чисто случайная составляющая.
– объясненная на основе построенной модели составляющая y, а ε – чисто случайная составляющая. (3.4)
(3.4)
 (3.5)
(3.5) (3.6)
(3.6) , где (x1;y1) и (x2;y2) – координаты выбранных точек.
, где (x1;y1) и (x2;y2) – координаты выбранных точек. Перечисленные методы могут применяться для «быстрого», поверхностного анализа параметров уравнения регрессии. Полученные на их основе оценки не обладают свойствами несмещенности, эффективности, состоятельности и достаточности, поэтому для серьезного исследования необходимо применять другие методы. Наибольшее распространение получили такие математические методы, как метод наименьших модулей и метод наименьших квадратов. Существуют также методы, совмещающие достоинства этих методов, и преодолевающие их недостатки (в частности, функция Хубера).
Перечисленные методы могут применяться для «быстрого», поверхностного анализа параметров уравнения регрессии. Полученные на их основе оценки не обладают свойствами несмещенности, эффективности, состоятельности и достаточности, поэтому для серьезного исследования необходимо применять другие методы. Наибольшее распространение получили такие математические методы, как метод наименьших модулей и метод наименьших квадратов. Существуют также методы, совмещающие достоинства этих методов, и преодолевающие их недостатки (в частности, функция Хубера). , (3.9)
, (3.9) , (3.10)
, (3.10) (3.11)
(3.11)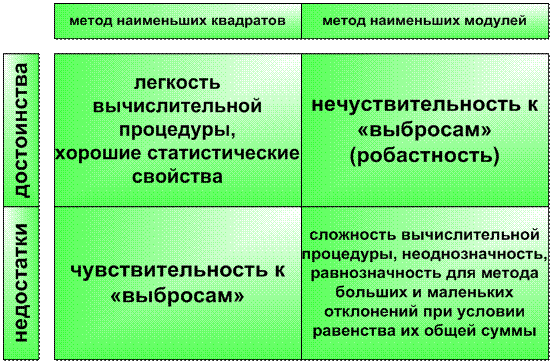
 (3.12)
(3.12) (3.13)
(3.13)



 (3.14)
(3.14) (3.15)
(3.15) , (3.16)
, (3.16) (3.17)
(3.17) (3.18)
(3.18)
 , (3.20)
, (3.20)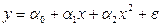



 ,
,

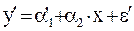
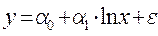
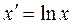



 ,
,


 ,
,







 (3.21)
(3.21) – фактическая дисперсия зависимой переменной,
– фактическая дисперсия зависимой переменной, 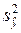 – дисперсия оценочных значений зависимой переменной, полученных на основании модели:
– дисперсия оценочных значений зависимой переменной, полученных на основании модели: (3.22)
(3.22) (3.23)
(3.23) , общая дисперсия
, общая дисперсия  :
: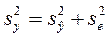 (3.24)
(3.24) (3.25)
(3.25) , (3.26)
, (3.26) (3.27)
(3.27) (3.28)
(3.28)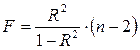 (3.29)
(3.29) , и для нее проводят оценку по тому же алгоритму, что и для коэффициента корреляции (см. тему 2). Затем полученные значения доверительных пределов возводятся в квадрат и получаем искомую интервальную оценку.
, и для нее проводят оценку по тому же алгоритму, что и для коэффициента корреляции (см. тему 2). Затем полученные значения доверительных пределов возводятся в квадрат и получаем искомую интервальную оценку. значения выборочных дисперсий будут равны:
значения выборочных дисперсий будут равны: (3.30)
(3.30) (3.31)
(3.31) (3.32)
(3.32) , взятым из таблицы (ПРИЛОЖЕНИЕ 2) где α – уровень значимости. Если фактическое значение оказывается больше критического, то нулевая гипотеза отвергается, и делается вывод о статистической значимости коэффициента регрессии. В противном случае считается, его значением можно пренебречь, и рассматривать модель с меньшим числом параметров.
, взятым из таблицы (ПРИЛОЖЕНИЕ 2) где α – уровень значимости. Если фактическое значение оказывается больше критического, то нулевая гипотеза отвергается, и делается вывод о статистической значимости коэффициента регрессии. В противном случае считается, его значением можно пренебречь, и рассматривать модель с меньшим числом параметров.



 (3.33)
(3.33) (3.34)
(3.34) (3.35)
(3.35) и увеличиваться по мере удаления от среднего значения (рис. 3.5).
и увеличиваться по мере удаления от среднего значения (рис. 3.5).
 (3.36)
(3.36)
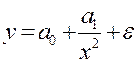
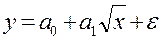

 – значения регрессионной модели):
– значения регрессионной модели):
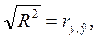
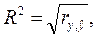


 ,
,  , а коэффициент a0 статистически значим на однопроцентном уровне
, а коэффициент a0 статистически значим на однопроцентном уровне






