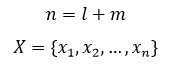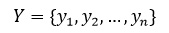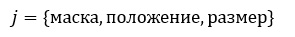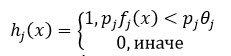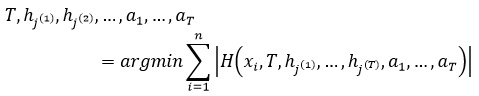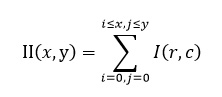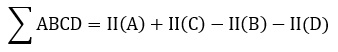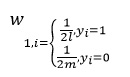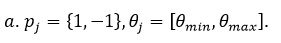Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
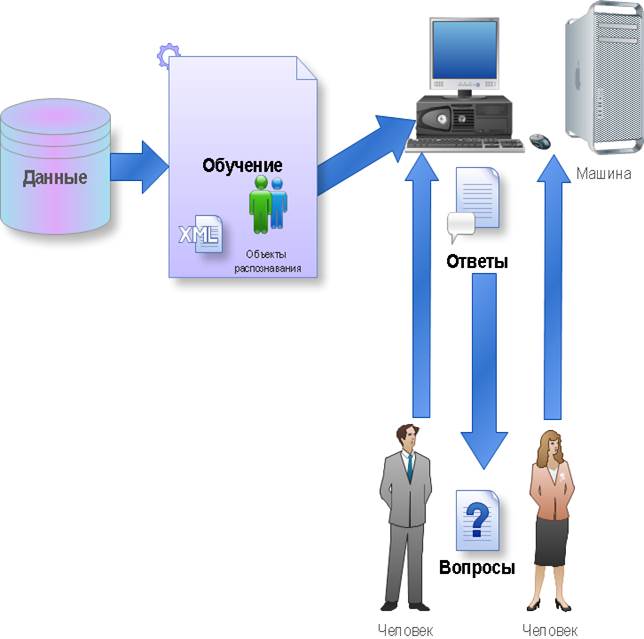
Используемая в алгоритме модель машинного обученияСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
«Машинное обучение — это наука, изучающая компьютерные алгоритмы, автоматически улучшающиеся во время работы» (Michel, 1996) . Ниже показан процесс обучения машины:
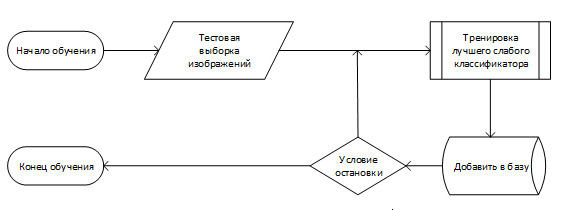
Схема обучения Обобщенная схема алгоритма обучения выглядит следующим образом. Имеется тестовая выборка изображений. Размер тестовой выборки около 10 000 изображений. На рисунке показан пример обучающих изображений лиц. Алгоритм обучения работает с изображениями в оттенках серого.
При размере тестового изображения 24 на 24 пикселя количество конфигураций одного признака около 40 000 (зависит от минимального размера маски). Современная реализация алгоритма использует порядка 20 масок. Для каждой маски, каждой конфигурации тренируется такой слабый классификатор, который дает наименьшую ошибку на всей тренировочной базе. Он добавляется в базу данных. Таким образом алгоритм обучается. И на выходе алгоритма получается база данных из T слабых классификаторов. Обобщённая схема алгоритма обучения показана на рисунке.
Обучение алгоритма Виола-Джонса – это обучение алгоритма с учителем. Для него возможно такая проблема как переобучение. Показано, что AdaBoost может использоваться для различных проблем, в том числе к теории игр, прогнозировании. В данной работе условие остановки является достижение заранее заданного количества слабых классификаторов в базе. Для алгоритма необходимо заранее подготовить тестовую выборку из l изображений, содержащих искомый объект и n не содержащих. Тогда количество всех тестовых изображений будет
где X – множество всех тестовых изображений, где для каждого заранее известно присутствует ли искомый объект или нет и отражено во множестве Y.
где
Под признаком j будем понимать структуру вида
Тогда откликом признака будет f_j (x), который вычисляется как разность интенсивностей пикселей в светлой и темной областях. Слабый классификатор имеет вид:
Задача слабого классификатора – угадывать присутствие объекта в больше чем 50% случаев. Используя процедуру обучения AdaBoost создается очень сильный классификатор состоящий из T слабых классификаторов и имеющий вид:
Целевая функция обучения имеет следующий вид:
Интегральное представление изображений Интегральное представление можно представить в виде матрицы, размеры которой совпадают с размерами исходного изображения I, где каждый элемент рассчитывается так:
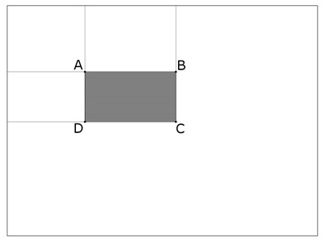
где I(r,c) — яркость пиксела исходного изображения. Каждый элемент матрицы II[x,y] представляет собой сумму пикселов в прямоугольнике от (0,0) до (x,y). Расчет такой матрицы занимает линейное время. Для того, чтобы вычислить сумму прямоугольной области в интегральном представлении изображения требуется всего 4 операции обращения к массиву и 3 арифметические операции. Это позволяет быстро рассчитывать признаки Хаара для изображения в обучении и распознавании. Например, рассмотрим прямоугольник ABCD.
Сумму внутри прямоугольника ABCD можно выразить через суммы и разности смежных прямоугольников по формуле:
Обучение Перед началом обучения инициализируются веса w_(q,i), где q – номер итерации, i-номер изображения.
После процедуры обучения получится T слабых классификаторов и T значений.
На каждой итерации цикла происходит обновление весов так, что их сумма будет равна 1. Далее для всех возможных признаков происходит подбор таких значений p,θ,j что значение ошибки e_j будет минимально на этой итерации. Полученный признак J(t) (на шаге t) сохраняется в базу слабых классификаторов, обновляются веса и вычисляется коэффициент a_t. В предложенном в 2001 году оригинальном алгоритме не была описана процедура получения оптимального признака на каждой итерации. Предполагается использование алгоритма AdaBoost и полный перебор возможных параметров границы и паритета. Распознавание После обучения на тестовой выборке имеется обученная база знаний из T слабых классификаторов. Для каждого классификатора известны: признак Хаара, использующийся в этом классификаторе, его положение внутри окна размером 24х24 пикселя и значение порога E. На вход алгоритму поступает изображение I(r,c) размером W х H, где I(r,c) – яркостная составляющая изображения. Результатом работы алгоритма служит множество прямоугольников R(x,y,w,h), определяющих положение лиц в исходном изображении I. Алгоритм сканирует изображение I на нескольких масштабах, начиная с базовой шкалы: размер окна 24х24 пикселя и 11 масштабов, при этом каждый следующий уровень в 1.25 раза больше предыдущего, по рекомендации авторов. Алгоритм распознавания выглядит следующим образом:
|
||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 594; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.011 с.) |