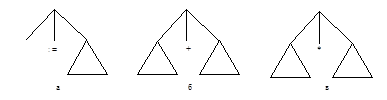Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Проблемы нисходящего разбора и их решение.Содержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Прямая левосторонняя рекурсия.
Алгоритмы, в которых цель определена с использованием левосторонней рекурсии, имеют серьезный недостаток. Если X - наша цель, а первое же правило для X имеет вид X::=X..., то мы незамедлительно усыновляем того, кто будет искать X. Он в свою очередь немедленно "заведет" себе сына, чтобы тот искал X. Таким образом, каждый будет сваливать на своего сына ответственность, и для решения этой задачи не хватит всего населения Китая. По этой причине правила грамматики пишут с применением правосторонней рекурсии вместо более привычной левосторонней. Лучший способ избавиться от прямой левосторонней рекурсии - записывать правила, используя итеративные и факультативные обозначения. Запишем правила (3.1) E::=E+T|T как E::=T{T} и T::=T*F|T/F|F как T::=F{*F|/F} Сейчас будут сформулированы два принципа, на основании которых правила языка, включающие прямую левостороннюю рекурсию, преобразуются в эквивалентные правила, использующие итерацию. Факторизация. Если существуют правила вида U::=xy|xw|...|xz, то их надо заменить правилами U::= x(y|w|...|z), где скобки являются метасимволами. Допустима факторизация и в более общей форме, такая, как в арифметических выражениях. Например, если y=y1y2 и w=y1w2, мы могли бы заменить U::=x(y|w|...|z) на U::=x(y1(y2|w2)|...|z). Заметьте, что исходные правила U::=x|xy мы преобразуем к виду U::=x(y|l), где l - пустая цепочка. Когда бы ни использовалось подобное преобразование, l всегда помещается как последняя альтернатива, так как мы принимаем условие, что если цель - l, то эта цель всегда сопоставляется. Помимо того что факторизация позволяет нам исключить прямую рекурсию, использование этого приема сокращает размеры грамматики и позволяет проводить разбор более эффективно. После факторизации в грамматике останется не более одной правой части с прямой левосторонней рекурсией для каждого из нетерминалов. Если такая правая часть есть, мы делаем следующее. Пусть U::=x|y|...|z|Uv - правила, у которых осталась леворекурсивная правая часть. Эти правила означают, что членом синтаксического класса U является x, y или z, за которыми либо ничего не следует, либо следует сколько-то v. Тогда преобразуем эти правила к виду U::=(x|y|...|z) {v}. Данное преобразование позволяет избавиться от ненужных скобок, заключающих T (см. выраж. 3.1). В качестве другого примера преобразуем A::=BC|BCD| Axz|Axy.
Рис.3.1. Деревья, использующие рекурсию и итерацию.
Применив правило факторизации, получим A::= BC(D|l) |Ax(z|y); применив последующее преобразование, получим A::= (BC(D|l){x(z|y)}. Использование итерации вместо рекурсии отчасти меняет и структуру деревьев. Таким образом, рис.3.1, a должен был бы походить на рис.3.1,b. Мы утверждаем, что эти два дерева следует рассматривать как эквивалентные; операторы "плюс" должны выполняться слева направо.
Общая левосторонняя рекурсия
Мы не решили всей проблемы левосторонней рекурсии: с прямой левосторонней рекурсией покончено, но общая левосторонняя рекурсия еще осталась. Таким образом, правила U::=Vx и V::=Uy|v Дают вывод U=>+ Uyx. Избавиться от этого не так просто, но обнаружить такую ситуацию можно. Исключим из исходной грамматики все правила с прямой левосторонней рекурсией. Символ U, получившейся в результате этих преобразований грамматики, может быть леворекурсивным тогда и только тогда, когда U FIRST+ U.
5. ОБЗОР ПРОЦЕССА КОМПИЛЯЦИИ.
5.1. АССЕМБЛЕР.
За исключением программы на машинном языке, состоящей из комбинации нулей и единиц, которые непосредственно дешифрирует компьютер, программа на языке ассемблера является простейшей. В языке ассемблера имеются операторы двух видов: команды, которые ассемблер транслирует в машинные команды, и директивы, которые служат указаниями ассемблеру во время процесса ассемблирования, но не транслируется в машинные команды. Для реализации одного оператора языка высокого уровня при трансляции требуются более одного оператора ассемблера. Хотя каждая ассемблерная команда порождает только одну машинную команду, ее проще писать благодаря тому, что аббревиатуры, называемые мнемониками, показывают тип команды, а символьные цепочки, называемые идентификаторами, представляют собой адреса и, возможно, числа. Типичная ассемблерная команда ADD AX,COST прибавляет содержимое ячейки памяти, ассоциируемой с идентификатором COST, к регистру АХ. Аббревиатура ADD является мнемоникой команды. Директива COST DW? Заставляет ассемблер зарезервировать слово и ассоциировать с ним идентификатор COST, но не порождает машинной команды. Поскольку ассемблер оказывается просто транслирующей программой, формат и синтаксис команд и директив определяются не компьютером, а тем, как написан ассемблер. Каждая команда языка ассемблера в исходной программе может иметь до четырех полей следующего вида:
[Метка:] Мнемокод [Операнд] [;Комментарии]
Пробелы вводятся произвольно, но минимум один пробел должен быть в тех местах, где его отсутствие ведет к неоднозначности (например, между мнемоникой и первым операндом) Кроме того, пробелы не допускаются в мнемониках и идентификаторах, а в цепочках-константах и в комментариях они должны вводиться специальными символами. Метка - это идентификатор, присваиваемый первому байту команды, у которой она появляется. Наличие метки в команде не обязательно, но если она есть, метка становится символическим именем, которое применяется в командах переходов для передачи управления отмеченной команде. При отсутствии метки двоеточия быть не должно. Во всех командах необходимо наличие мнемоники. Наличие операндов зависит от команды - некоторые команды не имеют операндов, в других командах требуется один операнд, а в некоторых - два операнда. В случае двух операндов они разделяются запятой. Поле комментария предназначено для пояснения программы и может содержать любую комбинацию символов. Оно не обязательно, и при отсутствии комментария точка с запятой не нужна. Комментарием может быть целая строка и в этом случае первым символом в строке должна быть точка с запятой. Ассемблерная команда должна иметь операнд для каждого операнда машинной команды и обозначение каждого операнда должно идентифицировать режим его адресации. При двух операндах первым указывается операнд-получатель, а вторым - операнд-источник. (Квадратные скобки вокруг полей метки, операнда и комментария показывают, что эти поля не обязательны; ни в коем случае не набирайте эти скобки при вводе программ.) Чтобы разобраться каким образом происходит преобразование исходной программы на языке высокого уровня в объектную программу, рассмотрим мнемокоды (таблица 5.1). Таблица 5.1
Мнемокоды ассемблера IBM PC
MOV – основная команда общего назначения, позволяющая пересылать байт или слово между регистром и ячейкой памяти или между двумя регистрами. Она может также пересылать непосредственно адресуемое значение в регистр или в ячейку памяти. ADD – складывает содержимое операнда – источника и операнда – приемника и помещает результат в операнд – приемник. SUB – вычитает операнд – источник из операнда – приемника и помещает результат в операнд – приемник. MUL – умножает числа без знака и заносит результат по умолчанию в регистр – аккумулятор, используемый для выполнения арифметических операций над данными. DIV – выполняет деление чисел без знака, где источник – делитель, находящийся в регистре общего назначения или в ячейке памяти, а делимое по умолчанию извлекается из регистра – аккумулятора. Слова AH, AL, AX, BH, BL, BX, BP, CH, CL, CS, DH, DL, DX, DI, DS, ES, SI, SP, ST являются зарегистрированными именами регистров (аккумуляторы). Представленные в таблице 5 мнемокоды, будем использовать далее в конкретных примерах. Например, фрагмент программы, реализующий расчет выражения W=X+Y+24-Z может выглядеть следующим образом: Директивы определения данных, команды ввода и др. X,Y,W,Z определены как переменные-слова. MOV AX, X;передать (X) в AX ADD AX, Y;прибавить (Y) к AX ADD AX, 24;прибавить 24 к сумме SUB AX,Z;вычесть (Z) из (X)+(Y)+24 MOV W, AX;запомнить результат в W
5.2. ОСНОВНЫЕ ЧАСТИ КОМПИЛЯТОРА. Перевод (трансляция) — это некоторое отношение между цепочками, или, другими словами, это некоторое множество пар цепочек. Компилятор определяет перевод, образуемый парами вида (исходная программа, объектная программа). Существуют два фундаментальных метода организации перевода. Первый из них предполагает перевод программы написанной на языке высокого уровня в программу на машинном языке или на языке ассемблера (объектную программу), что предполагает разработку компилятора. Второй пооператорно считывает исходную программу, переводит их в машинные коды и сразу выполняет, минуя объектную программу, что предполагает разработку интерпретатора. Желательные качества транслятора таковы: 1) эффективность трансляции - время необходимое для обработки входной цепочки (программы) линейно зависит от ее длины; 2) небольшой объем; 3) корректность – желательно иметь небольшой конечный тест, такой, что если транслятор прошел через него, то правильность работы транслятора гарантированна для всех входных программ. Во многих компиляторах для многих языков программирования есть общие процессы. Попытаемся выделить сущность некоторых из этих процессов. При этом мы постараемся устранить из них по возможности все, что связано с конкретной реализацией и зависит от машины и операционной системы. Хотя соображения, относящиеся к реализации, важны (плохая реализация может испортить хороший алгоритм), нам кажется, что понимание фундаментальной природы проблемы существенно само по себе и позволяет применить технику, созданную для решения этой проблемы, к другим проблемам, по существу сходным с нею. Исходная программа, написанная на некотором языке программирования, есть не что иное, как цепочка знаков. Компилятор в конечном итоге превращает эту цепочку знаков в цепочку битов — объектный код. В этом процессе часто можно выделить подпроцессы со следующими названиями: (1) Лексический анализ. (2) Работа с таблицами. (3) Синтаксический анализ, или разбор. (4) Генерация кода, или трансляция в промежуточный код (например, язык ассемблера). (5) Оптимизация кода. (6) Генерация объектного кода (например, ассемблирование). В конкретных компиляторах порядок этих процессов может несколько отличаться от указанного, а некоторые из них могут объединяться в одну фазу. Кроме того, никакая входная цепочка не должна нарушать работу компилятора, т.е. он должен обладать способностью, реагировать на любую из них. Для входных цепочек, не являющихся синтаксически правильными программами, компилятор должен выдать соответствующие сообщения об ошибках. Мы кратко опишем первые пять фаз компиляции. В реальном компиляторе они не обязательно разделены. Однако методически часто оказывается удобным расчленить компилятор на эти фазы, чтобы изолировать проблемы, присущие именно этим частям процесса компиляции.
ЛЕКСИЧЕСКИЙ АНАЛИЗ.
Первая фаза — лексический анализ. Входом компилятора, а следовательно, и лексического анализатора, служит цепочка символов некоторого алфавита. Алфавит Pascal А В С... Z 0... 9 _ пробел + - / * = < > [ ].,;: () ’ Основные символы языка (терминалы) подразделяются на буквы цифры и специальные символы – знаки, имеющие фиксированный смысл. Зарезервированное cлово = and array begin case const div downto do else end file for function goto if in label mod nil not of or packed procedure program record repeat set then to type until var while with. В программе некоторые комбинации символов часто рассматриваются как единые объекты. Среди типичных примеров можно указать следующие: 1) В таких языках, как Pascal, цепочка, состоящая из одного или более пробелов, обычно рассматривается как один пробел. 2) В языках есть ключевые слова, такие, как Begin, End, integer, и составные знаки:=, <=,>= и т.д. каждое из которых считается одним символом (зарезервированные слова). 3) Каждая цепочка, представляющая числовую константу, рассматривается как один элемент текста. 4) Идентификаторы, используемые как имена переменных, функций, процедур, меток и т. п., также считаются лексическими единицами языка программирования. Работа лексического анализатора состоит в том, чтобы сгруппировать определенные терминальные символы в единые синтаксические объекты, называемые лексемами. Какие объекты считать лексемами, зависит от определения языка программирования. Лексема - это цепочка терминальных символов, с которой мы связываем лексическую структуру, состоящую из пары вида (тип лексемы, некоторые данные). Первой компонентой пары является синтаксическая категория, такая как «константа» или «идентификатор», а вторая - указатель: в ней указывается адрес ячейки, хранящей информацию об этой конкретной лексеме. Для данного языка число типов лексем предполагается конечным. Пару (тип лексемы, указатель) тоже будем называть лексемой, когда это не будет вызывать недоразумений. Таким образом, лексический анализатор - это транслятор, входом которого служит цепочка символов, представляющая исходную программу, а выходом - последовательность лексем. Этот выход образует вход синтаксического анализатора. П р и м е р 5.1. Рассмотрим следующий оператор присваивания из языка, подобного Pascal: COST:= (PRICE + TAX) * 30 На этапе лексического анализа будет обнаружено, что COST, PRICE и TAX - лексемы типа идентификатора, а 30 - лексема типа константы. Знаки:= (+) * сами являются лексемами. Допустим, что все константы и идентификаторы нужно отобразить в лексемы типа <ид>. Мы предполагаем, что вторая компонента лексемы представляет собой указатель элемента таблицы, содержащего фактическое имя идентификатора вместе с другими, собранными нами данными об этом конкретном идентификаторе. Первая компонента используется синтаксическим анализатором для разбора. Вторая компонента используется на этапе генерации кода для изготовления подходящего машинного кода. Таким образом, выходом лексического анализатора, работающего на нашей входной цепочке, будет последовательность лексем <ид>1:= (<ид>2 + <ид>3) * <ид>4 Здесь вторая компонента лексемы (указатель данных) показана в виде нижнего индекса. Символы:=, +, * трактуются как лексемы, тип которых представлен ими самими. Они не имеют связанных с ними данных и, значит, не имеют указателей. Лексический анализ провести легко, если лексемы, состоящие более чем из одного знака, изолированы с помощью знаков, которые сами являются лексемами. В примере знаки:=, +,* не могут быть частью идентификатора, так что COST, PRICE и TAX легко выделяются как лексемы. Мы определим два крайних подхода к лексическому анализу. Большинство известных способов основано на том или другом из этих подходов, а некоторые на их комбинации. (1) Говорят, что лексический анализатор работает прямо, если для данного входного текста (цепочки) и положения указателя в этом тексте анализатор определяет лексему, расположенную непосредственно справа от указываемого места, и сдвигает указатель вправо от части текста, образующей эту лексему. (2) Говорят, что лексический анализатор работает не прямо, если для данного текста, положения указателя в этом тексте и типа лексемы он определяет, образуют ли знаки, расположенные непосредственно справа от указателя, лексему этого типа. Если да, то указатель передвигается вправо от части текста, образующей эту лексему. Вообще мы будем описывать алгоритмы синтаксического анализа в предположении, что лексический анализ прямой. В случае непрямого лексического анализа можно использовать “недетерминированные” алгоритмы или алгоритмы с возвратами. После того как в результате лексического анализа лексемы распознаны, информация о некоторых из них собирается и запасается в одной или нескольких таблицах. Какова эта информация, зависит от языка. В случае Pascal, например, мы хотели бы знать, что COST, PRICE и TAX – переменные с плавающей точкой, а 30 – целая константа. В сложных языках, таких, как Pascal, объем сведений, которые надо запомнить о данной переменной, может быть очень велик. Рассмотрим несколько упрощенный пример таблицы, в которой хранится информация об идентификаторах. Такую таблицу часто называют таблицей имен (а также таблицей идентификаторов и таблицей символов). В ней перечислены, в частности, все идентификаторы вместе с относящейся к ним информацией. Допустим, что в тексте встречается оператор COST:= (PRICE + TAX) * 30 После просмотра этого оператора таблица может иметь вид таблицы 5.2. Если позднее во входной цепочке попадется идентификатор, надо справиться в этой таблице, не появлялся ли он раньше. Если да, то лексема, соответствующая новому вхождению этого идентификатора, будет той же, что и у предыдущего вхождения. Например, если в программе, написанной на Pascal, после указанного выше оператора следует оператор, содержащий переменную COST, то лексемой для второго вхождения COST должна быть <ид>1 - та же, что и для первого вхождения.
Таблица 5.2
Таким образом, эта таблица должна обеспечивать (1) быстрое добавление новых идентификаторов и новых сведений о них, (2) быстрый поиск информации, относящейся к данному идентификатору. Обычно применяют метод хранения данных с помощью таблиц расстановки.
СИНТАКСИЧЕСКИЙ АНАЛИЗ. Как уже упоминалось, выходом лексического анализатора является цепочка лексем. Эта цепочка образует вход синтаксического анализатора, исследующего только первые компоненты лексем - их типы. Информация о каждой лексеме (вторая компонента) используется на более позднем этапе процесса компиляции для генерации машинного кода. Синтаксический анализ, или разбор, как его еще называют, - это процесс, в котором исследуется цепочка лексем и устанавливается, удовлетворяет ли она структурным условиям, явно сформулированным в определении синтаксиса языка. Какова синтаксическая структура данной цепочки, существенно знать также и при генерации кода. Например, синтаксическая структура выражения А+В*С должна отражать тот факт, что сначала перемножаются В и С, а потом результат складывается с А. При любом другом порядке операций нужное вычисление не получится. Разбор - одна из наиболее понятных фаз компиляции. По совокупности синтаксических правил можно автоматически построить синтаксический анализатор, который будет проверять, имеет ли исходная программа синтаксическую структуру, определяемую этими правилами. Изложим несколько различных методов разбора и алгоритмов построения синтаксических анализаторов по заданной грамматике. Выходом анализатора служит дерево, которое представляет синтаксическую структуру, присущую исходной программе. В некотором отношении синтаксический анализ программы напоминает разбор предложений, который все мы проводили в школе. П р и м е р 5.2. Допустим, что выход лексического анализатора — цепочка лексем: <ид>1:= (ид>2 + <ид>3)*<ид>4 Эта цепочка передает информацию о том, что необходимо выполнить в точности следующее: (1) <ид>3 прибавить к <ид>2, (2) результат (1) умножить на <ид>4, (3) результат (2) поместить в ячейку, зарезервированную для <ид>1 Эту последовательность шагов можно представить наглядно с помощью помеченного дерева, показанного на рис.5.1 Внутренние вершины дерева представляют те действия, которые надо выполнить. Прямые потомки каждой вершины либо представляют аргументы, к которым нужно применить действие (если соответствующая вершина помечена идентификатором или является внутренней), либо помогают определить, каким должно быть это действие (в частности, это делают знаки +, *,:=)• Заметим, что скобки в цепочке в дереве явно не указаны, хотя мы могли бы изобразить их в качестве прямых потомков вершины n1. Роль скобок только в том, что они влияют на порядок операций. Если бы в рассматриваемой цепочке их не было, следовало бы поступить согласно обычному соглашению о том, что умножение “предшествует” сложению, и на первом шаге перемножить <ид>3 и <ид>4.
Рис. 5.1 Древовидная структура. ГЕНЕРАЦИЯ КОДА.
Дерево, построенное синтаксическим анализатором, используется для того, чтобы получить перевод входной программы. Этот перевод может быть программой в машинном языке, но чаще он бывает программой в промежуточном языке, таком, как язык ассемблера или „трехадресный код” (последний образуется из простых операторов, каждый из которых включает не более трех идентификаторов, например, А = В, А = В + С). Если требуется, чтобы компилятор произвел существенную оптимизацию кода, то предпочтительнее код трехадресного типа. Так как трехадресный код не привязывает вычисления к конкретным регистрам вычислительной машины, регистры легче использовать для более эффективной оптимизации. Если предполагается малая оптимизация или никакая, то в качестве промежуточного языка лучше взять язык ассемблера или даже машинный код. Для того чтобы проиллюстрировать узловые моменты процесса трансляции, рассмотрим пример трансляции на язык ассемблерного типа. Пусть в этом примере наша машина имеет один рабочий регистр (сумматор, или регистр результата) и команды языка ассемблера, вид которых определен в таблице 5.3. Запись „с (m)—> сумматор” означает, что содержимое ячейки памяти m надо поместить в сумматор. Через = m обозначено численное значение m. Из этих замечаний ясен смысл преобразований кодирования. Таблица 5.3
Выходом синтаксического анализатора служит дерево (или некоторое представление дерева), представляющее синтаксическую структуру цепочки лексем, полученной на выходе лексического анализатора. С помощью этого дерева и информации, хранящейся в таблице имен, можно построить объектный код. На практике построение дерева и генерация кода часто осуществляются одновременно, но методически удобнее считать, что они происходят последовательно. Существует несколько методов построения промежуточного кода по синтаксическому дереву. Один из них, называемый синтаксически управляемым переводом (трансляцией), особенно изящен и эффективен. В нем с каждой вершиной n связывается цепочка С (n) промежуточного кода. Код для вершины n строится сцеплением в фиксированном порядке кодовых цепочек, связанных с прямыми потомками вершины n, и некоторых других фиксированных цепочек. Процесс перевода идет, таким образом, снизу вверх. Фиксированные цепочки и фиксированный порядок задаются используемым для перевода алгоритмом. Здесь возникает важная проблема: для каждой вершины n выбрать код С (n) так, чтобы код, приписываемый корню, оказался искомым кодом всего оператора. Вообще говоря, нужна какая-то интерпретация кода С (n), которой можно было бы единообразно пользоваться во всех ситуациях, где может встретиться вершина n. Для арифметических операторов присваивания нужная интерпретация получается весьма естественно; мы опишем ее в следующих абзацах. В общем случае при применении синтаксически управляемой трансляции интерпретация должна задаваться создателем компилятора. Эта задача может оказаться легкой или трудной, и в трудных случаях, возможно, придется учитывать структуру всего дерева. В качестве характерного примера опишем синтаксически управляемую трансляцию арифметических выражений. Заметим, что на рис. ** есть три типа внутренних вершин, зависящих от того, каким из знаков:=, +, * помечен средний потомок. Эти три типа вершин показаны на рис.5.2, где треугольниками изображены произвольные поддеревья (возможно, состоящие из единственной вершины). Для любого арифметического оператора присваивания, включающего только арифметические операции + и * можно построить дерево с. одной вершиной (корнем) типа а и остальными внутренними вершинами только типов б и в.
Рис. 5.2. Типы внутренних вершин. Код, соответствующий вершине n, будет иметь следующую интерпретацию: (1) Если n — вершина типа а, то С (n) будет кодом, который вычисляет значение выражения, соответствующего правому поддереву, и помещает его в ячейку, зарезервированную для идентификатора, которым помечен левый потомок. (2) Если n — вершина типа б или в, то цепочка MOV С (n) будет кодом, засылающим в сумматор значение выражения, соответствующего поддереву, над которым доминирует вершина n. Так, для дерева, изображенного на рис. 5.1, код MOV С (n1) засылает в сумматор значение выражения <ид>2+<ид>3, код MOV С (n2) засылает в сумматор значение выражения (<ид>2 +<ид>3)* <ид>4, а код С(n3) засылает в сумматор значение последнего выражения и помещает его в ячейку, предназначенную для <ид>1. Теперь надо показать, как код С (n) строится из кодов потомков вершины n. В дальнейшем мы будем предполагать, что операторы языка ассемблера записываются в виде одной цепочки и отделяются друг от друга точкой с запятой или началом новой строки. Кроме того, мы будем предполагать, что каждой вершине n дерева приписано число l(n), называемое ее уровнем, которое означает максимальную длину пути от этой вершины до листа. Таким образом, l(n) = 0, если n — лист, а если n имеет потомков n1,..., nk, то l(n) = max l (ni.)+1,при 1<i<k. Уровни l(n) можно вычислять снизу вверх одновременно с вычислением кодов С (n). Уровни записываются для того, чтобы контролировать использование временных ячеек памяти. Две нужные нам величины нельзя засылать в одну и ту же ячейку памяти. На рис.5.3 показаны уровни вершин дерева, изображенного на рис. 5.1. Теперь определим синтаксически управляемый алгоритм генерации кода, предназначенный для вычисления кодов С (n) всех вершин дерева, состоящего из листьев, корня типа а и внутренних вершин типов б и в.
Рис. 5.3 Дерево с уровнями.
Алгоритм. Синтаксически управляемая трансляция простых операторов присваивания. Вход. Помеченное упорядоченное дерево, представляющее оператор присваивания, включающий только арифметические операции + и *. Предполагается, что уровни всех вершин уже вычислены. Выход. Код в языке ассемблера, вычисляющий этот оператор присваивания. Метод. Делать шаги (1) и (2) для всех вершин уровня 0, затем для вершин уровня 1 и т. д., пока не будут обработаны все вершины дерева. (1) Пусть n—лист с меткой <ид>j. (1.1) Допустим, что элемент j таблицы идентификаторов является переменной. Тогда С (n) — имя этой переменной. (1.2) Допустим, что элемент j таблицы идентификаторов является константой k. Тогда С (n) — k. (2) Если n— лист с меткой:=, * или +, то С (n) — пустая цепочка. (В этом алгоритме нам не нужно или мы не хотим выдавать выход для листьев, помеченных:=, * или +.) (3) Если n — вершина типа а и ее прямые потомки — это вершины n1, n2 и n3, то С(n) — цепочка MOV С(n1), AX. (4) Если n — вершина типа б и ее прямые потомки — вершины n1,n2 и n3, то С(n) — цепочка MOV AX, C(n1); ADD AX, C(n3) (5) Если n —вершина типа в, а все остальное, как в (4), то С (n) — цепочка MOV AX, C(n1); MUL AX, C(n3) Рассмотрим использование данного алгоритма на примере. П р и м е р 5.3. Применим данный алгоритм к дереву, изображенному на рис. 5.3. То же дерево, на котором явно выписаны коды, сопоставляемые с каждой его вершиной, показано на рис. 5.4. С вершинами, помеченными <ид>1,..., <ид>4, связаны соответственно коды COST, PRICE, TAX и 30. Теперь мы можем вычислить C(n1). Формула из правила (4) дает C(n1) = MOV AX, PRICE; ADD AX, TAX
Рис.5.4. Дерево с генерированными кодами.
Таким образом, вычисляется в сумматоре сумма значений переменных PRICE и TAX. Далее можно вычислить С (n2) по правилу (5) и получить С(n2) = MUL AX, 30 Затем вычисляем С (n3) по правилу (3) и получаем С (n3) = MOV COST, AX Список команд языка ассемблера (вместо точки с запятой разделителем в нем служит новая строка), который является переводом нашего первоначального оператора COST:= (PRICE + TAX)*30, таков: MOV AX, PRICE ADD AX, TAX MUL AX, 30 MOV COST, AX Предполагается, что дрективы определения данных, команды ввода и др. выполнены ранее.
ОПТИМИЗАЦИЯ КОДА.
Во многих ситуациях желательно иметь компилятор, который создает эффективно работающие объектные программы. Термин оптимизация кода обычно применяется к попыткам сделать объектные программы более „эффективными”, т. е. быстрее работающими или более компактными. Для оптимизации кода существует широкий спектр возможностей. На одном его конце находится истинно оптимизирующий алгоритм. В этом случае компилятор пытается составить представление о функции, определяемой алгоритмом, программа которого записана на исходном языке. Если он догадается, что это за функция, то может попытаться заменить прежний алгоритм новым, более эффективным алгоритмом, вычисляющим ту же функцию, и уже для этого алгоритма генерировать машинный код. К сожалению, оптимизация этого типа чрезвычайно трудна. Дело в том, что нет алгоритмического способа нахождения самой короткой или самой быстрой программы, эквивалентной данной. На самом деле можно математически доказать, что существуют алгоритмы, вычисления которых можно ускорять во сколько угодно раз. Иначе говоря, существуют рекурсивные функции, обладающие тем свойством, что для любого алгоритма, вычисляющего такую функцию, найдется другой вычисляющий ее алгоритм, который для достаточно больших входов работает в произвольное число раз быстрее. Таким образом, термин “оптимизация” совершенно неправильный — на практике мы должны довольствоваться улучшением кода. На разных стадиях процесса компиляции применяются различные приемы улучшения кода. Вообще все, что мы можем делать, это выполнить над данной программой последовательность преобразований в надежде повысить ее эффективность. Эти преобразования должны, разумеется, сохранять эффект, создаваемый во внешнем мире исходной программой. Преобразования можно производить в различные моменты процесса компиляции. Например, можно оперировать с самой входной программой, со структурами, порождаемыми на стадии синтаксического анализа, с кодом, порождаемым в качестве выхода фазы генерации кода. Проведем преобразования, с помощью которых можно сделать код более коротким: (1) Если + — коммутативная операция, можно заменить последовательность команд вида MOV AX, A ADD AX, B последовательностью MOV AX, A+B (2) Подобным же образом, если * — коммутативная операция, можно заменить MOV AX, A MUL AX, B последовательностью MOV AX, A*B Пример 5.4. Эти преобразования выбраны из-за их применимости к рассмотренному ранее примеру. Вообще таких преобразований много и надо пробовать применять их в разных комбинациях. MOV AX, PRICE+TAX MUL AX, 30 MOV COST, AX
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-14; просмотров: 518; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 52.15.241.87 (0.011 с.) |