Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Поиск записи с заданным значением ключа и чтениеСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
По заданному значению ключа x подсчитывается значение функции f(x). Далее из ВП считывается блок, находящийся по адресу f(x). В ОП внутри этого блока перебором ищется нужная запись. Если записей в блоке нет, то по указателю в блоке (адресу связи) читается первая запись списка переполнения, относящаяся к этому блоку. Далее необходимая запись ищется по этому списку. Число обращений к ВП при этом равно: · единице, если запись находится в блоке; · единице плюс число записей в соответствующем этому блоку списке области переполнения (как правило, небольшое число). Модификации записи Осуществляется поиск и чтение записи, затем в ОП модифицируются поля записи (не являющиеся первичным ключом), запись заносится на свое место. Число обращений к ВП в этом случае на единицу больше, чем при чтении записи. Если модифицируется значение ключа, то занесение записи осуществляется как ввод новой записи (добавление). Удаление записи Осуществляется поиск и чтение записи. Если удаляемая запись находилась в блоке основной памяти, на ее место заносится «пустая» запись (или признак «пустой» записи). Если удаляемая запись находилась в списке области переполнения, удаление ее производится по правилам удаления элемента списка. Число обращений к ВП при удалении находится примерно в тех же пределах, что и для предыдущих операций. Добавление записи При добавлении записи со значением ключа x подсчитывается адрес соответствующего блока f(x). Блок считывается в ОП. Если в нем есть место, запись заносится в блок, блок записывается в ВП по своему адресу. Если блок заполнен, из него выбирается адрес начала списка записей, переполняющих блок. Далее добавление записи в список производится по правилам добавления элемента в список. Число обращений к ВП при добавлении записей находится примерно в тех же пределах, что и для предыдущих операций. Таким образом, описанная структура хранения с использованием хэширования является наиболее эффективной (из рассмотренных выше) по критерию минимизации числа обращений к ВП при реализации основных операций. 9.4.6. Комбинированные структуры хранения Необходимо заметить, что в СУБД могут использоваться как каждая из вышерассмотренных структур в отдельности, так и их комбинация. Так, например, в ряде промышленных систем UNIBAD, БАНК для ЭВМ типа IBM 360/370 (ЕС ЭВМ), PARADOX для персональных ЭВМ используются следующие комбинации методов: · размещение записей по первичному ключу организовано с использованием хэширования; · последовательность записей по вторичному ключу задается с помощью списковой структуры. Краткие итоги: Лекция посвящена вопросам физической организации данных в памяти компьютера (организации структур хранения). Физические модели представления данных жестко заложены в структуру конкретной СУБД и различны в различных системах управления базами данных. Заметим, что в данной лекции рассматриваются не структуры хранения конкретной СУБД, а некоторые типовые структуры хранения, на основе которых и реализуются физические модели организации данных в конкретных СУБД. Здесь описывается двухуровневая структура памяти компьютера как среда размещения данных; организация обмена между внешней и оперативной памятью, определяющая специфику обработки данных. Представлены типовые физические модели (структуры хранения данных) во внешней памяти ЭВМ (последовательное размещение физических записей, размещение физических записей в виде списковой структуры, использование индексов, организация данных в виде В-дерева, размещение записей с использованием хэширования, атакже комбинированные структуры хранения). Для основных структур хранения сделана оценка числа действий при выполнении операций поиска данных, чтения, занесения данных, модификации (корректировки), удаления.
Более подробно с материалами этой лекции можно ознакомиться в [1-7].
Контрольные тесты.
Задача 1. Общая характеристика внутреннего уровня базы данных.
Вариант 1. Что такое внутренний уровень базы данных?
ð концептуальное представление ð концептуальная модель, специфицированная в терминах СУБД ð+ структура хранения данных в памяти компьютера ð+ отображение концептуальной модели базы данных в физическую организацию данных
Вариант 2. Что такое физическая модель данных? ð+ внутренний уровень базы данных ð концептуальная модель, специфицированная в терминах СУБД ð структура памяти компьютера ð+ отображение концептуальной модели базы данных в физическую организацию данных.
Вариант 3. В каком виде концептуальная модель базы данных представляется в памяти компьютера?
ð в виде модели данных ð+ в виде физической модели ð+ в виде структуры хранения ð+ как наборы физических записей
Задача 2. Представление экземпляра логической записи
Вариант 1. В каком виде представляется экземпляр логической записи?
ð линейная последовательность байтов переменной длины ð+ линейная последовательность байтов фиксированной длины ð линейная последовательность байтов фиксированной длины с возможным указателем на другую область памяти ð линейная последовательность байтов переменной длины с возможным указателем на другую область памяти
Вариант 2. Какие параметры характеризуют поле логической записи при его физическом представлении?
ð+ количество занимаемых байтов ð+ тип представления данных ð наименование поля ð количество символов в значении поля
Вариант 3. Какие параметры поля логической записи не являются характеристиками его физическом представлении?
ð количество занимаемых байтов ð тип представления данных ð+ наименование поля ð+ количество символов в значении поля
Задача 3. Организация обмена между оперативной и внешней памятью.
Вариант 1. Что является единицей обмена между внешней и оперативной памятью?
ð экземпляр логической записи ð логический файл ð физический файл ð+ физическая запись ð+ страница
Вариант 2. Почему обмен между оперативной и внешней памятью осуществляется страницами или физическими записями? ð+ для сокращения времени обработки ð для сокращения занимаемого объема оперативной памяти ð для сокращения занимаемого объема внешней памяти ð+ для сокращения числа обращений к внешней памяти Вариант 3. Почему обмен между оперативной и внешней памятью нецелесообразно осуществлять отдельными экземплярами логических записей?
ð+ затрачивается большое время на обработку данных ð используется чрезмерно много оперативной памяти ð используется чрезмерно много внешней памяти ð трудно осуществлять поиск необходимых данных
Задача 4. Последовательное размещение физических записей во внешней памяти.
Вариант 1. Как осуществляется поиск записи с заданным значением ключа при последовательном размещении физических записей во внешней памяти?
ð+ полным перебором ð по заданному адресу ð дихотомическим методом ð чтением записи с заданным значением ключа
Вариант 2. Какой формулой оценивается среднее число обращений к внешней памяти при поиске записи с заданным значением ключа при последовательном размещении физических записей во внешней памяти (N - число экземпляров логических записей, k - коэффициент блокировки)?
ð+ (1+ ð N ð log2 (1+ ð Вариант 3. Когда при добавлении новой физической записи при последовательном размещении физических записей во внешней памяти требуется затратить меньше действий?
ð+ при добавлении в конец физического файла ð при вставке в нужное место физического файла ð при вставке в начало физического файла ð при добавлении новой физической записи на место удаляемой физической записи.
Задача 5. Размещение физических записей в виде списковой структуры.
Вариант 1. Как осуществляется поиск записи с заданным значением ключа при размещении физических записей в виде списковой структуры?
ð+ полным перебором ð по заданному адресу ð дихотомическим методом ð чтением записи с заданным значением ключа
Вариант 2. Какой формулой оценивается среднее число обращений к внешней памяти при поиске записи с заданным значением ключа при размещении физических записей в виде списковой структуры? (N число экземпляров логических записей, k коэффициент блокировки)?
ð+ (1 + ð N ð log2 (1+ ð log2 N / k
Вариант 3. Как примерно соотносится объем затрачиваемых действий при добавлении новой физической записи при размещении физических записей в виде списковой структуры?
ð меньше при добавлении в конец физического файла ð больше при вставке в нужное место физического файла ð меньше при вставке в начало физического файла ð больше при добавлении новой физической записи на место удаляемой физической записи ð+ примерно равны
Задача 6. Использование индексов
Вариант 1. Как хранятся физические записи в памяти при использовании индексации?
ð упорядочены по значениям ключа ð+ в виде неупорядоченной последовательности ð в виде списка ð+ используется дополнительный файл
Вариант 2. Что такое индекс?
ð+ дополнительная таблица ð адрес связи у физической записи основного файла ð В-дерево ð Хэш-функция
Вариант 3. К чему приводит использование индекса?
ð+ к сокращению времени поиска ð к сокращению времени добавления записи ð+ к сокращению числа обменов между оперативной и внешней памятью ð+ к увеличению объема занимаемой памяти ð+ к дублированию информации
Задача 7. Использование В-дерева.
Вариант 1. Из каких полей состоит запись всех уровней В-дерева, кроме нижнего?
ð+ из поля ключа и поля ссылки на нижележащий уровень ð из поля ключа и поля ссылки на вышележащий уровень ð из полей логической записи и поля ссылки на нижележащий уровень ð из полей логической записи и поля ссылки на вышележащий уровень
Вариант 2. Что происходит при добавлении записи в В-дерево? ð+ может увеличиться число блоков нижнего уровня ð+ может увеличиться число блоков всех уровней ð+ может увеличиться число уровней ð структура дерева не меняется
Вариант 3. К чему приводит использование В-дерева? ð+ к сокращению времени поиска ð к сокращению времени добавления записи ð+ к сокращению числа обменов между оперативной и внешней памятью ð+ к увеличению объема занимаемой памяти ð+ к дублированию информации
Задача 8. Размещение физических записей с использованием хэширования
Вариант 1. Как осуществляется поиск записи с заданным значением ключа при размещении физических записей с использованием хэширования?
ð полным перебором ð+ по вычисленному адресу ð дихотомическим методом ð чтением записи с заданным значением ключа
Вариант 2. Как примерно оценивается среднее число обращений к внешней памяти при поиске записи с заданным значением ключа при размещении физических записей с использованием хэширования? (N ‑ число экземпляров логических записей)? ð пропорционально N ð+ небольшое число ð пропорционально log 2 N ð как некоторая функция f (N)
Вариант 3. Как примерно соотносится объем затрачиваемых действий при добавлении новой физической записи при размещении физических записей с использованием хэширования?
ð меньше при добавлении в конец физического файла ð больше при вставке в нужное место физического файла ð меньше при вставке в начало физического файла ð больше при добавлении новой физической записи на место удаляемой физической записи ð+ примерно равны
Литература
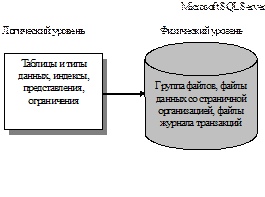
1. Мартин Дж. Организация баз данных в вычислительных системах: Пер. с англ. /Под ред. А.А. Стогния и А.Л. Щерса. – М.: Мир, 1980. – 664 с. 2. Дейт К.Дж. Введение в системы баз данных: Пер. с англ. – 6-е изд. – К.: Диалектика, 1998. – 784 с 3. Хансен Г., Хансен Дж. Базы данных: разработка и управление: Пер. с англ. – М.: ЗАО «Издательство «БИНОМ», 1999. – 704 с. 4. Конноли Т., Бэгг К., Страчан А. Базы данных: проектирование, реализация и сопровождение. Теория и практика. 2-е изд.: Пер. с англ. – М.: Издательский дом «Вильямс», 2000. – 1120 с 5. Карпова Т. Базы данных. Модели, разработка, реализация. – СПб.: Питер, 2001. – 304 с. 6. Крёнке Д. Теория и практика построения баз данных. 8-е изд. – СПб.: Питер, 2003. – 800 с. 7. Швецов В.И., Визгунов А.Н., Мееров И.Б. Базы данных. Учебное пособие. Н.Новгород: Изд-во ННГУ, 2004. 271 с. Лекция 10. Структура современной СУБД В лекции рассматривается архитектура системы управления базами данных на примере одной из наиболее распространенных клиент-серверных СУБД - Microsoft SQL Server 2008 (логический и физический уровни). Ключевые термины: структура СУБД, архитектура СУБД, логический уровень, архитектура СУБД, физический уровень СУБД, архитектура Microsoft SQL Server 2008. Цель лекции: показать основные элементы структуры современной СУБД (архитектуры базы данных и структуры программного обеспечения) на примере Microsoft SQL Server 2008. 10.1 Общая структура СУБД Для лучшего понимания принципов работы современных СУБД рассмотрим структуру одной из наиболее распространенных клиент-серверных СУБД - Microsoft SQL Server 2008. Несмотря на то, что каждая коммерческая СУБД имеет свои отличительные особенности, информации о том, как устроена какая-то из СУБД, обычно бывает достаточно для быстрого первоначального освоения другой СУБД. Краткий обзор возможностей Microsoft SQL Server - 2008 был приведен в разделе, посвященном краткому обзору современным СУБД. В данном разделе рассмотрим основные моменты, связанные со структурой соответствующей СУБД (архитектурой базы данных и структурой программного обеспечения) Под архитектурой (структурой) базы данных конкретной СУБД будем понимать основные модели представления данных, используемые в соответствующей СУБД а также взаимосвязи между этими моделями. В соответствии с рассмотренными в лекции 3 различными уровнями описания данных различают разные уровни абстракции архитектуры базы данных Логический уровень (уровень модели данных СУБД) - средство представления концептуальной модели). Здесь каждая СУБД имеет некоторые отличия, но они являются не очень значительными. Отметим, что у разных СУБД существенно отличаются механизмы перехода от логического к физическому уровню представления. § Физический уровень (внутреннее представление данных в памяти ЭВМ - физическая структура базы данных). Данный уровень рассмотрения подразумевает изучение базы данных на уровне файлов, хранящихся на жестком диске. Структура этих файлов – особенность каждой конкретной СУБД, в т.ч. и Microsoft SQL Server.[s5]
Рис. 10.1. Архитектура базы данных в Microsoft SQL Server 2008
10.2. Архитектура базы данных. Логический уровень Рассмотрим логический уровень представления базы данных (http://msdn.microsoft.com). Microsoft SQL Server 2008 представляет собой реляционную СУБД (данные представляются в виде таблиц). Таким образом, основной структурой модели данных этой СУБД являются таблицы. Таблицы и типы данных Таблицы содержат данные о всех сущностях концептуальной модели базы данных. При описании каждого столбца (поля) пользователь должен определить тип соответствующих данных. Microsoft SQL Server 2008 поддерживает как уже ставшие традиционными типы данных (символьная строка с разным представлением, число с плавающей точкой длиной 8 или 4 байта, целое число длины 2 или 4 байта, дата и время, поле примечаний, булево значение и т. д.), так и новые типы данных. Кроме этого Microsoft SQL Server 2008 предоставляет специальный аппарат для создания пользовательских типов данных. Рассмотрим краткую характеристику некоторых новых типов данных, значительно расширяющих возможности пользователя (www.oszone.net). Тип данных hierarchyid Тип данных hierarchyid позволяет создавать отношения между элементами данных в таблице, для того, чтобы задать позицию в иерархии связей между строками таблицы. В результате использования этого типа данных в таблице строки таблицы могут отображать определенную иерархическую структуру, соответствующую связям между данными этой таблицы.
|
||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 693; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.129.23.110 (0.013 с.) |

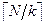 )/2
)/2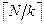 )/2
)/2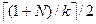
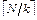 )/2
)/2