Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модель на основе нечеткой логикиСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
В модели мы используем следующие функция (функции) принадлежности: § Z-образная функция принадлежности может быть описана различными способами:
§ S-образная функция принадлежности также могут (может) быть описаны (описана) двумя различными аналитическими выражениями:
§ Треугольная функция принадлежности описывается следующим образом:
где
в которой значения входных н выходной переменных заданы нечеткими множествами.
Введем следующие обозначения:
где В результате получаем такое нечеткое множество
Особенностью этого нечеткого множества является то, что универсальным множеством для него является терм-множество выходной переменной 1) "срезать” функции принадлежности 2) объединить (агрегировать) полученные нечеткие множества.
где Основные этапы нечеткого логического вывода (см. рисунок 1.7 на первой главе): Ø Формирование базы правил систем нечеткого логического вывода; Ø Фаззификация входных переменных; Ø Агрегирование подусловий в нечетких правилах продукций; Ø Активизация (композиция) подзаключений в нечетких правилах продукций; Ø Аккумулирование заключений нечетких правил продукций; Ø Дефаззификация выходных переменных. Все этапы применение (применения) нечеткой логики для оценки качества обслуживания системы электронного здоровья будут рассмотрены для случая, в котором в качестве входных лингвистических переменных используются скорость передачи информации, задержка и доля потери пакетов, в качестве выходной лингвистической переменной – предоставление услуги физиологического мониторинга. v При формировании базы правил используются формализованные экспертные знания, созданные с привлечением специалистов в области оценки качеством (качества) обслуживания в сетях связи. Конечное множество правил образуют базу правил нечетких продукций и описываются для большинства алгоритмов нечеткого логического вывода в следующем виде: ПРАВИЛО 1: ЕСЛИ "Условие 1" ТО "Заключение 1"(F1),
... ПРАВИЛО n: ЕСЛИ "Условие n" ТО "Заключение n"(Fn). где База правил нечеткого логического вывода при оценке качества предоставления услуги физиологического мониторинга машинных агрегатов формируется на основании следующего алгоритма. В таблице 2.2. сформированы правила системы нечеткого логического вывода. Таблица 2.2 – Правила нечеткого логического вывода для оценки качества предоставления услуги физиологического мониторинга
На первом этапе генерируются, множество правил исходя из всех возможных сочетаний входных и выходных переменных. При этом разработанная база нечетких правил соответствует структуре MISO (Multiple Input – Single Output), в которой трём входным переменным соответствует одна выходная переменная. На втором этапе каждому правилу присваивается свой весовой коэффициент, позволяющий ранжировать правила по степени важности. При первоначальном составлении правил значения весовых коэффициентов принимаются равными единице. В дальнейшем, при необходимости оптимизации базы правил нечеткого логического вывода, значения весовых коэффициентов уточняются. На третьем этапе проводится исключение противоречащих друг другу правил, в которых одинаковые предпосылки приводят к разным заключениям. Правила нечеткого логического вывода должны удовлетворять требованию слабой согласованности, которое предполагает, что произвольные малые приращения входных параметров не должны приводить к скачкообразному изменению выходного параметра. База правил нечеткого логического вывода включает в себя множество правил нечетких продукций, наименование входных и выходных лингвистических переменных. v Фаззификация (введение нечеткости) необходима для установления связи между нечетким значением входной переменной и значением функции принадлежности для соответствующего терма входной лингвистической переменной, используемой в подусловиях базы правил. v Агрегирование представляет собой процедуру определения степени истинности условий по каждому из правил системы нечеткого логического вывода. v В процедуре активации функции принадлежности для подзаключений могут быть найдены при помощи использования одного из методов нечеткой композиции: prod-активизация, min-активизация, average-активизация. v С целью нахождения функции принадлежности для выходных лингвистических переменных используется процедура аккумуляции. На данном этапе происходит аккумулирование всех степеней истинности заключений. v Для нахождения числовых значений для выходных переменных нечетких множеств используется процедура дефаззификации (процедура приведения к четкости). Четкое значение опасности эксплуатации у, соответствующее входному вектору факторов определяется в результате дефаззификации нечеткого множества. Наиболее распространённым методом дефаззификации является метод центра тяжести. Параметры функций принадлежности лингвистических переменных при оценке качества предоставления услуги физиологического мониторинга представлены в таблице 2.3. Таблица 2.3 – Параметры функций принадлежности лингвистических переменных при оценке качества предоставления услуги физиологического мониторинга
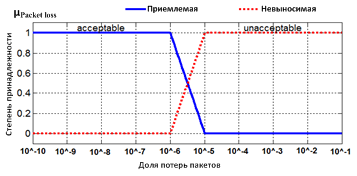
На рисунке 2.1. представлены функции принадлежности для термов входной лингвистической переменной «Скорость передачи информации», на рисунке 2.2 – для термов входной лингвистической переменной «Задержка», на рисунке 2.3 – для термов входной лингвистической переменной «Доля потери пакетов», на рисунке 2.4 – для термов выходной лингвистической переменной «Качество предоставления услуги физиологического мониторинга». На данных графиках по оси абсцисс откладывается значение исследуемого параметра, а по оси ординат определяется степень принадлежности (μData rate, μDelay, μPacket loss, μQoS) искомого значения к соответствующему терму множества.
Рисунок 2.1. Графики функций принадлежности для термов входной лингвистической переменной «Скорость передачи информации»
Рисунок 2.2. Графики функций принадлежности для термов входной лингвистической переменной «Задержка»
Рисунок 2.3. Графики функций принадлежности для термов входной лингвистической переменной «Доля потери пакетов»
Рисунок 2.4. Графики функций принадлежности для термов выходной лингвистической переменной «Качество предоставления услуги физиологического мониторинга»
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 673; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.223.159.237 (0.006 с.) |






 – числовые параметры, удовлетворяющие условию
– числовые параметры, удовлетворяющие условию 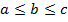 .
. Нечеткий логический вывод по алгоритму Мамдани выполняется по нечеткой базе знаний:
Нечеткий логический вывод по алгоритму Мамдани выполняется по нечеткой базе знаний:
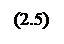
 - функция принадлежности входа
- функция принадлежности входа  нечеткому терму
нечеткому терму  , т.е.
, т.е.

 - функция принадлежности выхода у нечеткому терму
- функция принадлежности выхода у нечеткому терму  , т.е.
, т.е.
 Степени принадлежности входного вектора
Степени принадлежности входного вектора  нечетким термам
нечетким термам 
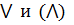 - операция из s-конормы (t-нормы), т.е. из множества реализаций логической операции ИЛИ (И). Наиболее часто используются следующие реализации: для операции ‘ИЛИ’ - нахождение максимума и для операции ‘И’ – нахождение минимума.
- операция из s-конормы (t-нормы), т.е. из множества реализаций логической операции ИЛИ (И). Наиболее часто используются следующие реализации: для операции ‘ИЛИ’ - нахождение максимума и для операции ‘И’ – нахождение минимума. , соответствующее входному вектору
, соответствующее входному вектору  :
:

 . Такие нечеткие множества называются нечеткими множествами второго порядка. Для перехода от нечеткого множества, заданного на универсальном множестве нечетких термов
. Такие нечеткие множества называются нечеткими множествами второго порядка. Для перехода от нечеткого множества, заданного на универсальном множестве нечетких термов  к нечеткому множеству на интервале
к нечеткому множеству на интервале  необходимо:
необходимо: на уровне;
на уровне; Математически это записывается следующим образом:
Математически это записывается следующим образом:
 где agg - агрегирование нечетких множеств, в системе нечеткого логического вывода по Мамдани наиболее часто оно реализуется операцией нахождения максимума. Четкое значение выхода
где agg - агрегирование нечетких множеств, в системе нечеткого логического вывода по Мамдани наиболее часто оно реализуется операцией нахождения максимума. Четкое значение выхода 
 ,
,  – значения, задающие область определения.
– значения, задающие область определения.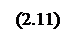 ПРАВИЛО 2: ЕСЛИ "Условие 2" ТО "Заключение 2"(F2),
ПРАВИЛО 2: ЕСЛИ "Условие 2" ТО "Заключение 2"(F2),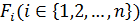 – весовые коэффициенты соответствующих правил, принимающие значения из интервала [0; 1].
– весовые коэффициенты соответствующих правил, принимающие значения из интервала [0; 1].