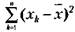Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Логика доказательства в психолого-педагогическом экспериментеСодержание книги
Поиск на нашем сайте
Доказательство экспериментальной гипотезы состоит из трех основных компонентов: фактов, аргументов и демонстрации справедливости предложенной гипотезы, вытекающей из этих аргументов и фактов. Факты и аргументы, как правило, представляют собой идеи, истинность которых уже проверена или доказана. В силу этого они могут без специального доказательства их справедливости приводиться в обоснование истинности или ложности гипоте- Часть II. Введение в научное психологическое исследование зы. Демонстрация — это совокупность логических рассуждений, в процессе которых из аргументов и фактов выводится справедливость гипотезы. Для того чтобы доказательство было убедительным, в нем также необходимо следовать определенным правилам. Одно из них гласит: гипотеза, аргументы и факты должны быть суждениями, ясно и точно определенными. В противном случае оно может быть опровергнуто или подвергнуто сомнению. Доказываемое положение — в нашем случае гипотеза — на всем протяжении доказательства должно оставаться тождественным, т.е. одним и тем же. Нарушение этого правила обычно ведет к тому, что, несмотря на затраченные усилия, гипотеза остается недоказанной. Факты и аргументы, приводимые в процессе доказательства - гипотезы, не должны противоречить друг другу, так как это также сводит доказательство на нет. Необходимо строго следить за тем, чтобы соблюдалось следующее правило: аргументы и факты, приводимые в подтверждение гипотезы, сами должны быть истинными и не подлежать сомнению. Часто встречающаяся ошибка в доказательстве заключается в том, что экспериментально установленная последовательность событий или фактов, их статистически достоверная связь (корреляция) ошибочно принимаются за свидетельство существования причинно-следственной зависимости между этими событиями или фактами. Например, из того, что за некоторым событием А всегда и неизменно следует другое событие Б (скажем, за весной — лето; за положением часовой стрелки на цифре 1 — ее переход на цифру 2), нередко делают вывод о том, что предшествующее событие является причиной наступления последующего (что в приведенных выше примерах, очевидно, неверно). Причинной считается такая зависимость, при которой появление события А не только неизбежно ведет за собой появление события Б, но и само событие Б может явиться лишь тогда, когда до него уже имело место событие А. В двух приведенных выше примерах это не так. Вполне можно представить себе такой случай, что часы остановятся после того, как стрелка окажется на цифре 1, и тогда она не попадет на цифру 2; может случиться экологическая ката- _____ Глава 2. Виды научных психолого-педагогических исследований _ строфа, которая сделает климат постоянным, например, превратит его в вечную зиму или в вечное лето, и в этом случае закономерная смена времен года не наступит. В том и в другом примерах подлинные причины последовательного появления событий находятся вне тех событий, которые мы рассматриваем; они-то и придают закономерный характер временной последовательности этих событий. Ошибки могут иметь место не только в доказательстве, но и в интерпретации связей как причинно-следственных, и для того, чтобы избежать подобных ошибок, рекомендуется организовывать и проводить психолого-педагогический эксперимент в соответствии с одной из заранее продуманных логических схем доказательства, гарантирующих установление именно причинно-следственных зависимостей между изучаемыми переменными. Основная логическая схема, позволяющая добиться такого результата, довольно простая. Она включает в себя проведение исследования не на одной, а на двух и более группах испытуемых, одна из которых является экспериментальной, а друше — контрольными. При этом экспериментальная группа предназначается для установления достоверных статистических зависимостей между изучаемыми переменными, а контрольные группы — для того, чтобы, сравнивая получаемые в них результаты с теми, которые установлены на экспериментальной группе, отклонять альтернативные причинно-следственному объяснения выявленной статистической зависимости. В простейшем случае реализации этой схемы берутся одна экспериментальная и одна контрольная группы. В экспериментальной группе выделяется и целенаправленно изменяется переменная, которая рассматривается как вероятная причина объясняемого явления, а в контрольной группе ничего этого не происходит. По завершении эксперимента оцениваются и сравниваются между собой изменения, которые в экспериментальной и контрольной группах произошли в другой переменной — зависимой, и если окажется, что в экспериментальной группе эти изменения больше, чем в контрольной, то делается вывод о том, что подлинной их причиной являются именно те вариации независимой переменной, которые имели место в экспериментальной группе. ______ Часть II. Введение в научное психологическое исследование ___ Существует несколько вариантов практической реализации этой общей схемы. Рассмотрим их. 1. Метод единственного различия. Схематически он представляется следующим образом:
В данном случае фиксируется единственное различие между экспериментальной и контрольной группами по признаку Г, которое по завершении эксперимента приводит к появлению единственного различия по признаку Е. На этом основании делается вывод о том, что изменение Г и есть причина замеченных изменений в Е. 2. Метод сопутствующих изменений (обобщенный вариант метода единственного различия).
Если, варьируя величину признака Г, мы неизменно получаем изменения только одного признака Е, то Г можно рассматривать в качестве наиболее вероятной причины Е. 3. Метод единственного сходства.
если при разноооразных вариациях признаков неизменным остается единственное сходство (в данном случае: Г—»Е), то составляющие его переменные рассматриваются как причина (Г) и следствие (Е). Для того, чтобы получаемые в экспериментальной и контрольной группах результаты были сопоставимыми, необходимо, чтобы эти группы по существенным признакам были эквивалентными, т.е. такими, в которых уравнено влияние всех других релевантных переменных, кроме предполагаемой причины. Глава 2. Виды научных психолого-педагогических исследований Помимо общих логических схем, следование которым в организации и проведении эксперимента помогает выявлению причинно-следственных связей, этой же цели могут служить планы экспериментов. Таких основных планов имеется два: 1. Эксперимент, организованный по плану типа «только после». В подобного рода исследовании экспериментальные и контрольные группы оцениваются только по окончании эксперимента и не оцениваются в его начале. Если в итоге обнаруживается существенная разница между экспериментальной и контрольной группами, не имевшая место вначале, то можно сделать вывод о том, что отмеченные после эксперимента различия между этими группами были вызваны именно теми экспериментальными действиями, которые предпринимались в отношении экспериментальной группы. Однако в этом случае в качестве альтернативной остается и требует специального опровержения гипотеза о том, что изначально экспериментальная и контрольные группы не были одинаковыми, что и вызвало зафиксированные между ними различия по окончании эксперимента. 2. Эксперимент, организованный по плану типа «до и после». В данном случае предполагаемые причины и следствия оцениваются и до, и после эксперимента и делается это как в экспериментальной, так и в контрольной группах. Тем самым заранее отбрасывается альтернативная гипотеза о том, что обнаруженные по окончании эксперимента различия между экспериментальной и контрольной группами были вызваны теми различиями между ними, которые имелись еще до начала проведения эксперимента. Контрольные вопросы 1. Виды психолого-педагогических исследований и их особенности. 2. Отличие экспериментального психолого-педагогического исследования от всех остальных исследований. 3. Взаимосвязь и преемственность разных видов психолого-педагогических исследований.
4. Что такое цели, задачи и гипотезы эксперимента? 5. Логические требования, предъявляемые к гипотезам экспериментального психолого-педагогического исследования. Часть II. Введение в научное психологическое исследование 6. Ошибки в доказательствах, направленных на выяснение причинно-следственных связей между переменными, изучаемыми в эксперименте. 7. Способы избежать ошибок в доказательстве существования причинно-следственной зависимости между переменными. 8. Логика организации и проведения экспериментов, направленных на доказательство причинно-следственных связей. 9. Экспериментальная и контрольная группы, их назначение в психолого-педагогическом эксперименте. ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА 1. Фресс П., Пиаже Ж. Экспериментальная психология. Вып. I и II. [Формулировка гипотез: 116-120. Эксперимент: 120-148. Наблюдение (как метод экспериментального исследования): 106-115. Обработка и обобщение результатов (эксперимента): 148-193]. 2. Роговин М.С. Психологическое исследование. Ярославль, 1979. 3. Роговин М.С, Залевский Г.В. Теоретические основы психологического и патопсихологического исследования. Томск, 1988. 4. СочивкоД.В., Якунин В.А. Математические модели в психолого-педагогических исследованиях: Учебное пособие. Л., 1988. (Постановка проблемы. Предмет, объект и задачи исследования: 40-42. Проведение пилотажного исследования: 42-48. Общие сведения о планировании эксперимента: 56-62.) Глава 3. СТАТИСТИЧЕСКИЙ АНАЛИЗ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ И СПОСОБЫ НАГЛЯДНОГО ПРЕДСТАВЛЕНИЯ РЕЗУЛЬТАТОВ Краткое содержание Методы первичной статистической обработки результатов эксперимента. Общее представление о методах статистического анализа экспериментальных данных, назначение этих методов. Деление статистических методов на ______ Глава 3. Статистический анализ экспериментальных данных ___ первичные и вторичные. Основные показатели, получаемые в результате первичной обработки экспериментальных данных. Вычисление средней арифметической. Определение дисперсии. Установление примерного распределения данных. Определение моды. Характеристика нормального распределения. Вычисление интервалов. Методы вторичной статистической обработки результатов эксперимента. Способы вторичной статистической обработки результатов исследования. Регрессионное исчисление. Сравнение средних величин разных выборок. Сравнение частотных распределений данных. Сравнение дисперсий двух выборок. Установление корреляционных зависимостей и их интерпретация. Понятие о факторном анализе как методе статистической обработки. Способы табличного и графического представления результатов эксперимента. Виды таблиц и их построение. Графическое представление экспериментальных данных. Гистограммы и их применение на практике. МЕТОДЫ ПЕРВИЧНОЙ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ РЕЗУЛЬТАТОВ ЭКСПЕРИМЕНТА Методами статистической обработки результатов эксперимента называются математические приемы, формулы, способы количественных расчетов, с помощью которых показатели, получаемые в ходе эксперимента, можно обобщать, приводить в систему, выявляя скрытые в них закономерности. Речь идет о таких закономерностях статистического характера, которые существуют между изучаемыми в эксперименте переменными величинами. Некоторые из методов математико-статистического анализа позволяют вычислять так называемые элементарные математические статистики, характеризующие выборочное распределение данных, например выборочное среднее, выборочная дисперсия, мода, медиана и ряд других. Иные методы математической статистики, например дисперсионный анализ,регрессионный анализ, позволяют судить о динамике изменения отдельных статистик выборки. С помощью третьей группы методов, скажем, корреляционного анализа, факторного анализа, методов сравнения выборочных данных, можно достоверно судить о статистических связях, существующих между переменными величинами, которые исследуют в данном эксперименте. ______ Часть II. Введение в научное психологическое исследование ___ Все методы математико-статистического анализа условно делятся на первичные и вторичные1. Первичными называют методы, с помощью которых можно получить показатели, непосредственно отражающие результаты производимых в эксперименте измерений. Соответственно под первичными статистическими показателями имеются в виду те, которые применяются в самих психодиагностических методиках и являются итогом начальной статистической обработки результатов психодиагностики. Вторичными называются методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. К первичным методам статистической обработки относят, например, определение выборочной средней величины, выборочной дисперсии, выборочной моды и выборочной медианы. В число вторичных методов обычно включают корреляционный анализ, регрессионный анализ, методы сравнения первичных статистик у двух или нескольких выборок. Рассмотрим методы вычисления элементарных математических статистик, начав с выборочного среднего. Выборочное среднее значение как статистический показатель представляет собой среднюю оценку изучаемого в эксперименте психологического качества. Эта оценка характеризует степень его развития в целом у той группы испытуемых, которая была подвергнута психодиагностическому обследованию. Сравнивая непосредственно средние значения двух или нескольких выборок, мы можем судить об относительной степени развития у людей, составляющих эти выборки, оцениваемого качества. Выборочное среднее определяется при помощи следующей формулы:
1 Приводимые здесь определения и высказывания не всегда являются достаточно строгими с точки зрения теории вероятностей и математической статистики как сложившихся областей современной математики. Это сделано для лучшего понимания данного текста студентами, не подготовленными в области математики: ______ Глава 3. Статистический анализ экспериментальных данных ___ где х — выборочная средняя величина или среднее арифметическое значение по выборке; п — количество испытуемых в выборке или частных психодиагностических показателей, на основе которых вычисляется средняя величина; хк — частные значения показателей у отдельных испытуемых. Всего таких показателей п, поэтому индекс k данной переменной принимает значения от 1 до п; Е — принятый в математике знак суммирования величин тех переменных, которые находятся справа от этого знака. Выражение X хк соответственно означает сумму всех х с индексом k от 1 до п. Пример. Допустим, что в результате применения психодиагностической методики для оценки некоторого психологического свойства у десяти испытуемых мы получили следующие частные показатели степени развитости данного свойства у отдельных испытуемых: xi = 5, х2 = 4, х3 = 5, х4 = 6, х5 = 7, *6 = 3, х7 = 6, х& = 2, хд= 8, хт = 4. Следовательно, п = 10, а индекс k меняет свои значения от 1 до 10 в приведенной выше формуле. Для данной выборки среднее значение1, вычисленное по этой формуле, будет равно:
В психодиагностике и в экспериментальных психолого-педагогических исследованиях среднее, как правило, не вычисляется с точностью, превышающей один знак после запятой, т.е. с большей, чем десятые доли единицы. В психодиагностических обследованиях большая точность расчетов не требуется и не имеет смысла, если принять во внимание приблизительность тех оценок, которые в них получаются, и достаточность таких оценок для производства сравнительно точных расчетов. Дисперсия как статистическая величина характеризует, насколько частные значения отклоняются от средней величины в данной выборке. Чем больше дисперсия, тем больше отклонения 1 В дальнейшем, как это и принято в математической статистике, с целью сокращения текста мы будем опускать слова «выборочное» и «арифметическое» и просто говорить о «среднем» или «среднем значении». ______ Часть II. Введение в научное психологическое исследование ____ или разброс данных. Прежде чем представлять формулу для расчетов дисперсии, рассмотрим пример. Воспользуемся теми первичными данными, которые были приведены ранее и на основе которых вычислялась в предыдущем примере средняя величина. Мы видим, что все они разные и отличаются не только друг от друга, но и от средней величины. Меру их общего отличия от средней величины и характеризует дисперсия. Ее определяют для того, чтобы можно было отличать друг от друга величины, имеющие одинаковую среднюю, но разный разброс. Представим себе другую, отличную от предыдущей выборку первичных значений, например такую: 5, 4, 5, 6, 5, 6, 5, 4, 5, 5. Легко убедиться в том, что ее средняя величина также равна 5,0. Но в данной выборке ее отдельные частные значения отличаются от средней гораздо меньше, чем в первой выборке. Выразим степень этого отличия при помощи дисперсии, которая определяется по следующей формуле:
где S — выборочная дисперсия, или просто дисперсия;
— выражение, означающее, что для всех хк от перво- го до последнего в данной выборке необходимо вычислить разности между частными и средними значениями, возвести эти разности в квадрат и просуммировать; п — количество испытуемых в выборке или первичных значений, по которым вычисляется дисперсия.
Определим дисперсии для двух приведенных выше выборок частных значений, обозначив эти дисперсии соответственно индексами 1 и 2:' ______ Глава 3, Статистический анализ экспериментальных данных ___ Мы видим, что дисперсия по второй выборке (0,4) значительно меньше дисперсии по первой выборке (3,0). Если бы не было дисперсии, то мы не в состоянии были бы различить данные выборки. Иногда вместо дисперсии для выявления разброса частных данных относительно средней используют производную от дисперсии величину, называемую выборочное отклонение. Оно равно квадратному корню, извлекаемому из дисперсии, и обозначается тем же самым знаком, что и дисперсия, только без квадрата— S:
Медианой называется значение изучаемого признака, которое делит выборку, упорядоченную по величине данного признака, пополам. Справа и слева от медианы в упорядоченном ряду остается по одинаковому количеству признаков. Например, для выборки 2, 3, 4, 4, 5, 6, 8, 7, 9 медианой будет значение 5, так как слева и справа от него остается по четыре показателя. Если ряд включает в себя четное число признаков, то медианой будет среднее, взятое как полусумма величин двух центральных значений ряда. Для следующего ряда 0, 1,1, 2, 3, 4, 5, 5, 6, 7 медиана будет равна 3,5. Знание медианы полезно для того, чтобы установить, является ли распределение частных значений изученного признака симметричным и приближающимся к так называемому нормальному распределению. Средняя и медиана для нормального распределения обычно совпадают или очень мало отличаются друг от друга. Если выборочное распределение признаков нормально, то к нему можно применять методы вторичных статистических расчетов, основанные на нормальном распределении данных. В противном случае этого делать нельзя, так как в расчеты могут вкрасться серьезные ошибки. Если в книге по математической статистике, где Описывается тот или иной метод статистической обработки, имеются указания на то, что его можно применять только к нормальному или близкому к нему распределению признаков, то необходимо не- ______ Часть II. Введение в научное психологическое исследование ___ укоснительно следовать этому правилу и полученное эмпирическое распределение признаков проверять на нормальность. Если такого указания нет, то статистика применима к любому распределению признаков. Приблизительно судить о том, является или не является полученное распределение близким к нормальному, можно, построив график распределения данных, похожий на те, которые представлены на рис. 72. Если график оказывается более или менее симметричным, значит, к анализу данных можно применять статистики, предназначенные для нормального распределения. Во всяком случае, допустимая ошибка в расчетах в данном случае будет относительно небольшой. Приблизительные картины симметричного и несимметричного распределений признаков показаны на рис. 72, где точками mi и т2 на горизонтальной оси графика обозначены те величины признаков, которые соответствуют медианам, а х\ и Х2 — те, которые соответствуют средним значениям.
Мода еще одна элементарная математическая статистика и характеристика распределения опытных данных. Модой называют количественное значение исследуемого признака, наиболее часто встречающееся в выборке. На графиках, представленных на рис. 72, моде соответствуют самые верхние точки кривых, вернее, те значения этих точек, которые располагаются на горизонтальной оси. Для симметричных распределений признаков,' в том числе для нормального распределения, значение моды совпадает со значениями среднего и медианы. Для других типов распределений, несимметричных, это не характерно. К примеру, в последовательности значений признаков 1,2, 5,2,4, 2,6,7,2 модой Глава 3. Статистический анализ экспериментальных данных является значение 2, так как оно встречается чаще других значений — четыре раза. Иногда исходных частных первичных данных, которые подлежат статистической обработке, бывает довольно много, и они требуют проведения огромного количества элементарных арифметических операций. Для того чтобы сократить их число и вместе с тем сохранить нужную точность расчетов, иногда прибегают к замене исходной выборки частных эмпирических данных на интервалы. Интервалом называется группа упорядоченных по величине значений признака, заменяемая в процессе расчетов средним значением. Пример. Представим следующий ряд частных признаков: О, 1,1,2,2,3,3,3,4,4,5,5,5,5,6,6,6,7,7,8,8,8,9,9,9,10,10,11,11, 11. Этот ряд включает в себя 30 значений. Разобьем представленный ряд на шесть подгрупп по пять признаков в каждом. Первая подгруппа включит в себя первые пять цифр, вторая — следующие пять и т.д. Вычислим средние значения для каждой из пяти образованных подгрупп чисел. Они соответственно будут равны 1,2; 3,4; 5,2; 6,8; 8,6; 10,6. Таким образом, нам удалось свести исходный ряд, включающий тридцать значений, к ряду, содержащему всего шесть значений и представленному средними величинами. Это и будет интервальный ряд, а проведенная процедура — разделением исходного ряда на интервалы. Теперь все статистические расчеты мы можем производить не с исходным рядом признаков, а с полученным интервальным рядом, и результаты в равной степени будут относиться к исходному ряду. Однако число производимых в ходе расчетов элементарных арифметических операций будет гораздо меньше, чем количество тех операций, которые с этой же целью пришлось бы проделать в отношении исходного ряда признаков. На практике, составляя интервальный ряд, рекомендуется руководствоваться следующим правилом: если в исходном ряду признаков больше чем тридцать, то этот ряд целесообразно разделить на пять-шесть интервалов и в дальнейшем работать только с ними. Для проверки сказанного проведем пробное вычисление среднего значения по приведенному выше ряду, составляющему тридцать чисел, и по ряду, включающему только интервальные сред- Часть II. Введение в научное психологическое исследование ние значения. Полученные цифры с точностью до двух знаков после запятой будут соответственно равны 5,97 и 5,97, т.е. являются одинаковыми.
|
||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 406; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.119.117.77 (0.195 с.) |