
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Виды гипотез и методы их математического обоснованияСодержание книги
Поиск на нашем сайте
Важным условием для выбора методов является способ измерения и характер распределения полученных данных, о чем будет сказано далее. Измерение В процессе изучения психологических особенностей большое значение имеют точность и обоснованность выводов, которые зачастую отражаются на профессиональной и индивидуальной составляющей жизни обследуемых. Заключение специалиста-практика об индивидуально-психологических особенностях личности, как и диагноз врача, не может быть ошибочным, подразумевать неоднозначное или неправильное его толкование. Точность и объективность заключения психолога во многом связаны с точностью и объективностью психодиагностического измерения. Измерение, в наиболее общем виде, – это процедура сопоставления частной характеристики с объективным эталоном и приписывание количественных значений данной характеристике в определенном масштабе или шкале. Измерение опирается на ряд правил, выполнение которых обеспечивает валидность и надежность получаемых сведений, в конечном итоге обуславливая результативность всей последующей работы психолога. Исторически о принципиальной возможности измерения психических явлений, процессов и состояний высказался известный немецкий философ Густав Теодор Фехнер (1801–1887). В своем фундаментальном труде «Элементы психофизики» он писал так: «...трудно возразить против того, что духовное вообще подчинено количественным отношениям. Ведь можно говорить не только о большей или меньшей силе ощущения, но и о разной силе влечений, о том, что существует большая или меньшая степень внимания, живости воспоминаний или образов фантазии, ясности сознания в целом, а также интенсивности отдельных мыслей... Таким образом, высшее духовное не в меньшей степени, чем чувственное... может быть охарактеризовано количественно» (Fechner, 1966). В естественно-научном измерении выделяются два основных этапа: сопоставление с эталоном и преобразование в форму, удобную для использования (различные способы индикации). Любой вид измерения предполагает наличие вполне определенных единиц. Исторически при изучении объективной реальности была разработана собственная шкала измерения. Так, длина измеряется в метрах (сантиметрах, миллиметрах), время – в секундах (часах, минутах), масса – в килограммах (тоннах, граммах). В физике и других естественно-научных дисциплинах используют основные и производные единицы измерения. Основных единиц измерения относительно немного: в Международной системе единиц (СИ) это килограмм (кг) – единица массы, метр (м) – единица расстояния, секунда (с) – единица времени, градус Кельвина (°К) – единица температуры, ампер (А) – единица силы тока, кандела (кд) – единица силы света и моль – единица количества вещества. В психологическом измерении отсутствуют самостоятельные единицы, а применяются четыре вида измерительных шкал: 1) номинативная (наименований); 2) порядковая (ординарная, ранговая); 3) интервальная; 4) отношений. Каждая из этих шкал предназначена для кодирования[13] информации определенного рода и имеет, соответственно, особую форму числового представления. Измерение, выполненное при помощи номинативной и порядковой шкал, относится к качественному (идеографическому, объяснительному), а при помощи шкалы интервалов и отношений – к количественному (описательному). Нужно отметить, что использование определенного способа кодирования обуславливает способ интерпретации, т. е. специальные статистические и логические процедуры, применяемые для описания выявленных фактов и представления результатов исследования. Таким образом, процедура кодирования способствует классификации выявленных эмпирических фактов и отнесению их к определенному виду психических явлений. Неправильное использование измерительных шкал, их смешение или нестандартизованное применение способствуют искажению результатов. Обратимся к анализу измерительных шкал. 1. Номинативная шкала (наименований). Измерение в номинативной шкале заключается в приписывании (наименовании) какому-либо объекту определенного обозначения (символа). Примером такого рода операции может служить представление типов темперамента по Гиппократу (холерик, сангвиник, флегматик, меланхолик), Айзенку (экстраверт, интроверт, нейротик), Кречмеру (пикнический, лептосомный, атлетический и диспластический). Простейшим видом номинативной шкалы, где применяются всего два пункта, является дихотомическая шкала. Примером дихотомической шкалы будут пункты («да» – «нет»), («согласен» – «не согласен»). При измерении в дихотомической шкале исследуемые признаки называются иначе альтернативными. Отметим, что номинативная шкала ограничивает исследователя в математико-статистических методах, применяемых для анализа данных. Допустимыми методами статистики являются число случаев, мода, корреляция случайных событий, коэффициент и др. 2. Порядковая шкала (ординарная, ранговая). Применяется при отражении порядка изучаемых явлений. С этой целью признаки ранжируются, т. е. получают определенное числовое значение, отражающее порядок проявления их свойств. В порядковой шкале отражаются: уровень учебной успеваемости в школе (от «1» до «5»); звания в системе военной службы (рядовой, ефрейтор, сержант, прапорщик и пр.); спортивные разряды (третий, второй, первый, кандидат в мастера спорта, мастер спорта и пр.). При кодировании информации в порядковой шкале необходимо соблюдать порядок (последовательность) приписывания чисел таким образом, чтобы значения располагались по степени убывания или возрастания. Например: Таблица 5 Варианты ранжирования
Как видно из таблицы, альтернативные ранги, несмотря на различие в числовом представлении, сохраняют свою последовательность (возрастания или убывания), что говорит о верности приписывания рангов. Для проверки правильности ранжирования применяют также формулы:
где N – число ранжируемых признаков. В случае, если количество ранжируемых признаков велико, формула (1) может быть модифицирована:
где X – число строк, Y – число столбцов. Зачастую при ранжировании признаков может возникнуть ситуация одинаковых рангов, т. е. несколько величин могут иметь сходные числовые обозначения. В этом случае ранжирование производится следующим образом: 1. Выявляются наименьшее и наибольшее значение числового ряда. 2. Наименьшему значению присваивается ранг, равный 1, наибольшему – равный количеству ранжируемых величин. 3. В случае совпадений рангов величин они ранжируются последовательно таким образом, чтобы каждая из них имела ранг, превышающий предыдущий на единицу ранжирования. Для проверки правильности ранжирования проводится расчет по формулам (1) или (2). Допустимыми методами статистики являются медиана, проценты, ранговая корреляция по Спирмену, Кендаллу. 3. Интервальная шкала. В основе шкалы лежит понятие интервала – части измеряемого свойства между позициями шкалы. Измерение заключается в присвоении измеряемому свойству определенного значения, равного количеству единиц измерения, соответствующих имеющемуся свойству. Размер интервала – фиксированная величина, постоянная для всех участков шкалы. Важной особенностью шкалы интервалов является отсутствие нуля – единой точки отсчета. Для использования шкалы интервалов нередко применяют специальные единицы измерения – стэны, станайны. Из табл. 6 видно, что приведенная шкала интервалов имеет семиуровневую градацию трех вариантов утверждения, доступных испытуемому. Таблица 6 Шкала интервалов
Классическим примером измерения в шкале интервалов является методика «Семантический дифференциал» Ч. Осгуда, где испытуемый сопоставляет субъективные представления с заранее определенной шкалой интервалов, тем самым определяя их выраженность. 4. Шкала отношений. В отличие от шкалы интервалов в шкале отношений вводится фиксированная точка отсчета, т. е. понятие ноля. В связи с этим измерение в шкале отношений предполагает сопоставление объектов в зависимости от степени выраженности измеряемого свойства. Шкала отношений используется в естественно-научном измерении (вес, объем, протяженность, сила и пр.). Данная шкала обладает максимальной мощностью,т. е.способностью дифференцировать большинство признаков или свойств психического явления, в отличие от номинативной, порядковой или интервальной. Распределение В результате измерения накапливается совокупность значений свойства, выраженных в определенной шкале. Закономерность, с которой данные значения представлены на всем пространстве шкалы, называется распределением[14]. В работах Ф. Гальтона впервые было установлено, что психологические явления подчиняются закону нормальности распределения, т. е. могут быть описаны формулой:
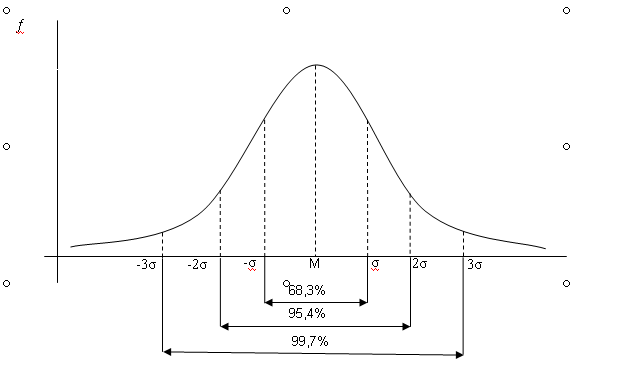
где Мх (математическое ожидание) и σ 2х (дисперсия) – параметры распределения; λх – интервал группировки данных (отличный от единицы); π = 3,14…; е = 2,17. Данная формула претерпела множество изменений, прежде чем утвердилась в своем окончательном виде в психологии. П. Лаплас сформулировал функцию симметричного распределения интегральных вероятностей, послужившего фундаментом для работ Ф. Гаусса, открывшего закон распределения вероятностей – закон нормального распределения, что было подтверждено работами А. Кеттле. Кеттле указывал, что средняя величина встречается в совокупности измерений чаще, чем отклоняющаяся от среднего. Причем чем больше это отклонение, тем реже данная величина встречается. Графически это показано на рис. 1. Интервал М ± σ описывает площадь под кривой, в которую входит 68,3 % проявлений психического явления. Интервал М ± 2σ – 95,4 %, а интервал М ± 3σ соответствует 99,7 % площади. Таким образом, кривая нормального распределения описывает частоту интенсивности изучаемого психического явления и представляет собой графическое выражение формулы (3). Важное следствие закона о нормальности распределения – возможность стандартизации измерений, т. е. графически, приведения их к некоей стандартной, эталонной кривой. Так как результаты любого измерения могут быть выражены через М – среднее и σ – стандартное отклонение, то возникает возможность стандартизации измерения согласно формуле (4):
где Z = стандартизованное значение; х i – значение переменой, значение среднего для х. Полученное распределение характеризуется следующими свойствами: – среднее (М) для такого распределения = 0, σ = 1; – кривая приближается к оси z асимптоматически; – кривая симметрична при М = 0, ее асимметрия и эксцесс равны 0; – площадь между кривой и осью z равна 1. Алгоритм приведения к нормальному виду, по О. А. Попову, выглядит следующим образом, учитывая, что при нормальном распределении в интервал m ± 1σ попадает 68,26 % всей выборки, этот интервал и принимается за средние баллы. Все значения до него относятся к низким, а выше него – к высоким. Таким образом, получаем три градации баллов. Для подобной стандартизации можно использовать интервал m ± 2/3σ, тогда 50 % выборки попадает в средние и по 25 % – в низкие и высокие баллы. Каким будет интервал – выбирает сам исследователь. Разделение на 4 интервала осуществляется подобным образом, граница между вторым и третьим интервалом проходит по среднему арифметическому. Разделение на пять уровней применяется при сильном разбросе данных. В подобном случае добавляется интервал m ± 2σ. Недостатком «уровневой» стандартизации является то, что полученные уровни с трудом поддаются последующей статистической обработке и слишком малоинформативны. Применение закона нормальности распределения – важный этап при проведении математико-статистической обработки эмпирических данных.
Рис. 1. Кривая нормального распределения М – среднее значение, σ – стандартное отклонение, Именно характер распределения определяет стратегию дальнейшего анализа данных. Так, если эмпирическое распределение соответствует нормальному, возникает возможность применения параметрических методов статистического анализа. В обратном случае используются непараметрические методы. Причины несоответствия полученного распределения нормальному могут заключаться как в объективной природе регистрируемого явления, так и в самой процедуре измерения. Вопрос о нормальности распределения значений психических явлений актуален на протяжении всего периода применения математических методов в психологии. К примеру, И. Кант отрицал возможность применения статистического анализа для изучения психических явлений, утверждая, что человеческая душа метафизична и не может подлежать формальному исследованию. Противники этой точки зрения утверждают, в свою очередь, что без эксперимента, процедуры измерения психология не может являться подлинно научной дисциплиной. Процедура исследования, в свою очередь, влияет на нормальность распределения, к примеру, в связи с неравномерной «чувствительностью» инструментария. Таким образом, при изучении умственных способностей путем решения задач, ряд из них может быть неразрешим или, наоборот, чрезвычайно прост для испытуемых. В подобном случае на графике распределения будет отражена асимметрия (смещение) линии графа от среднего в сторону меньших или больших значений. Показатель эксцесса (плосковершинности или остроты) графика распределения свидетельствует о преобладании определенного частотного диапазона значений изучаемого явления по выборке. Проверка полученного распределения на нормальность базируется на вычислении ряда дескриптивных статистик. Дескриптивная (описательная) статистика – это различные статистические показатели, описывающие распределение данных. К ним относятся среднее, мода, медиана, разброс, дисперсия и стандартное отклонение. Среднее (арифметическое):
где х i – значение изучаемого явления (i указывает на порядковый номер зафиксированного значения); n – количество наблюдений. Мода (Мо) – наиболее часто встречающееся значение признака в выборке. Мо вычисляется определением частоты ƒ встречаемости признака. В случае если несколько близких членов ряда обладают одинаковой частотой встречаемости, то Мо выборки определяется их среднеарифметическим значением. В выборке могут существовать несколько мод, в данном случае выборка является бимодальной, или есть возможность выделения генеральной моды и нескольких локальных. Медиана (Md) – значение признака, разделяющее выборку на две симметричные части. Md определяется путем ранжирования значений по выборке. В случае, если количество значений нечетное, то медиана – центральное (симметричное) значение, в противном случае медиана – среднее арифметическое нескольких центральных значений. Разброс (R) определяет разброс значений по выборке от максимального к минимальному. Разброс вычисляется вычитанием из максимального значения минимального. Дисперсия – мера рассеивания значений изучаемого явления (признака), характеризующая степень разобщенности измеряемых значений вокруг среднего.
где n – количество измерений; Х – среднее арифметическое, вычисляемое по формуле (5). Стандартное отклонение (σ) – среднее квадратическое отклонение, вычисляемое путем выделения квадратного корня из дисперсии:
Вычисление среднеквадратического отклонения – важный этап проверки предположения о нормальности распределения, принятия решения о выборе метода последующей статистической обработки данных. Коэффициент вариации (V) есть отношение стандартного отклонения к среднему арифметическому значению, выраженное в процентах:
где s – среднеквадратическое отклонение; Х – среднее арифметическое вариативного ряда. Коэффициент вариации используется для характеристики однородности исследуемой совокупности. Статистическая совокупность считается количественно однородной, если коэффициент вариации не превышает 33 % [15]. Исследование формы распределения. Выяснение общего характера распределения предполагает не только оценку степени его однородности, но и исследование формы распределения, т. е. оценку симметричности и эксцесса. В статистике различают одновершинные и многовершинные виды кривых распределения. Однородные совокупности описываются одновершинными распределениями. Многовершинность распределения свидетельствует о неоднородности изучаемой совокупности или о некачественном выполнении группировки[16]. Одновершинные кривые распределения делятся на симметричные, умеренно асимметричные и крайне асимметричные. Распределение называется симметричным, если частоты любых 2 вариантов, равноотстоящих в обе стороны от центра распределения, равны между собой. В таких распределениях x = Mo = Me. Асимметрия – показатель, отражающий перекос распределения относительно среднего арифметического влево или вправо. В тех случаях, когда какие-нибудь причины влияют на появление значений, которые выше или, наоборот, ниже среднего, образуются асимметричные распределения[17]. На графике распределения, таким образом, будет отражена асимметрия (смещение) линии графа от среднего в сторону меньших или больших значений. Положительно асимметричным считается распределение с более крутым левым и более пологим правым крылом, распределение с отрицательной асимметрией, напротив, имеет более пологий левый фронт нарастания и более крутой правый (см. рис. 2).
Рис. 2 Типы асимметрии Рассчитываемый по соответствующим формулам коэффициент асимметрии (As) может быть использован в качестве одного из критериев соответствия экспериментального распределения теоретическому. Вычисление коэффициента асимметрии: Коэффициент асимметрии вычисляется по следующей формуле:
где zx – мера Пирсона
Соответствие эмпирического распределения нормальному находится по соответствующим таблицам. При этом эмпирическое распределение считается соответствующим теоретическому (нормальному), если асимметрия при данной выборке не превышает граничного значения. Причины асимметрии могут быть различными. Во-первых, это возможное действие побочных однонаправленных факторов. Так, например, в тестах на измерение интеллекта могут преобладать сложные задания, с которыми большинство испытуемых не справляется. Это может явиться причиной положительной асимметрии (центральная тенденция лежит слева от среднего значения). Во-вторых, это ограничение (сверху или снизу) размаха вариаций. Например, при измерении времени сенсомоторной реакции нижний предел реагирования лимитирован физиологическими возможностями субъекта, в то время как верхний жестко не ограничен. Наконец, третьей причиной асимметрии может быть неоднородность выборки (например, если исследование проводится в смешанной группе разного возраста). При этом имеет место наложение друг на друга двух или нескольких разных по численности и сдвинутых относительно друг друга по моде распределений. Показатель эксцесса (плосковершинности или остроты) графика распределения свидетельствует о преобладании определенного частотного диапазона значений изучаемого явления по выборке. В отличие от коэффициента асимметрии, коэффициент (показатель) эксцесса характеризует компактность или «размытость» распределения, его островершинность или плосковершинность, что связано с разным характером группирования значений переменной вокруг среднего (рис. 3).
Рис. 3. Типы эксцесса Причинами эксцесса могут быть большая или меньшая степень тяготения переменных к центральной тенденции, неоднородность выборки, наложение друг на друга нескольких распределений с одинаковой модой и разной дисперсией и т. д. Вычисление показателя эксцесса:
Теоретически величина эксцесса может варьироваться от – 3 до + ¥. Критерий согласия с нормальным распределением аналогично коэффициенту асимметрии определяется по таблицам граничных значений. Аналогично определению асимметрии распределение соответствует нормальному (согласуется с нормальным), если Ex < Exкр. При обратном соотношении принято говорить, что по показателю эксцесса эмпирическое распределение статистически достоверно отличается от нормального. При анализе эмпирического распределения может возникнуть такая ситуация, когда по одному из показателей (асимметрии или эксцессу) распределение соответствует нормальному, по другому же – отличается от него. В этом случае следует использовать следующее правило: если хотя бы по одному из вышеуказанных показателей распределение достоверно отличается от нормального, то следует делать вывод о том, что экспериментальное распределение отличается от теоретического (нормального). Кроме коэффициента асимметрии и показателя эксцесса, для сравнения экспериментального распределения с теоретическим используют и другие критерии, в частности критерий хи-квадрат и критерий l Колмогорова – Смирнова. Вычисление дескриптивных показателей – важный этап математико-статистического анализа, позволяющий с минимальными временными затратами дать общую описательную характеристику особенностей проявления изучаемого показателя в выборке.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-04-12; просмотров: 84; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.12.34.96 (0.013 с.) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

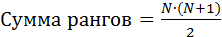 ,
,
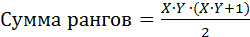 ,
,
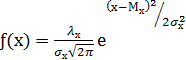 ,
,
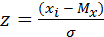 ,
,
 ,
,
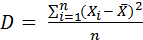 ,
,

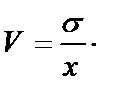 100 %, (8)
100 %, (8)
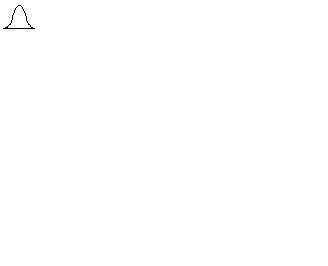
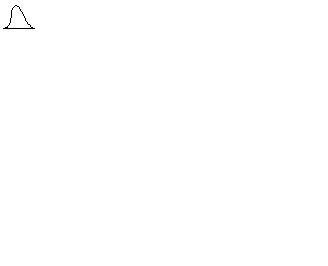
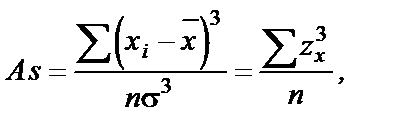 (9)
(9)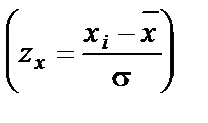 .
. При больших выборках (n > 50) можно использовать упрощенную формулу:
При больших выборках (n > 50) можно использовать упрощенную формулу:


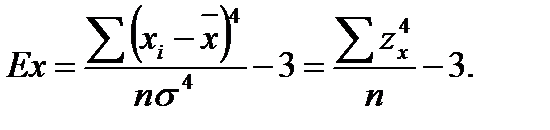 (11)
(11)


