Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение дискриминантной моделиСодержание книги
Поиск на нашем сайте Построение дискриминантной модели заключается в расчете и анализе коэффициентов дискриминантной функции. Построенная дискриминантная модель должна максимально четко разделять исследуемые группы. Качество построенной дискриминантной модели в рассматриваемом примере характеризуется данными, представленными в табл. 7.5 и 7.6.
Значение коэффициента корреляции между рассчитанными значениями дискриминантной функции и реальной принадлежностью к группе «0,321» является неудовлетворительным. В табл. 7.6 также представлен такой показатель, как собственное значение дискриминантной функции (Eigenvalue). Высокое значение этого показателя свидетельствует о высокой точности построенной дискриминантной модели. В рассматриваемом примере этот показатель имеет весьма низкое значение 0,115, что является негативным фактором. Показатель «Лямбда Уилкса» используется для проведения теста на значимость различий средних значений дискриминантной функции в исследуемых группах. В нашем примере значение показателя «Sign flcance» составляет 0,000 (табл. 7.7), что свидетельствует о высокой значимости различий средних значений (см. раздел 3 «Сравнение средних величин в SPSS»).
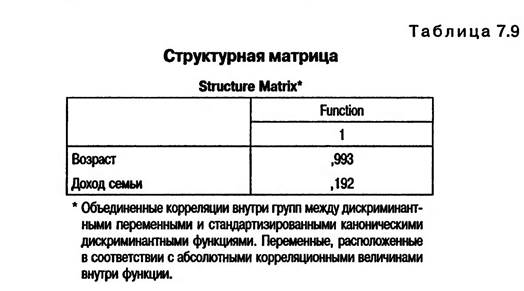
В табл. 7.8 и 7.9 представлены коэффициенты, значения которых были рассчитаны в обеих группах по отдельности и затем усреднены.
При помощи стандартизированных коэффициентов дискриминантной функции, представленных в табл. 7.8, можно оценить относительный вклад каждой дискриминационной переменной в различие двух исследуемых групп. В рассматриваемом примере возраст респондентов в 8,4 (0,984/0,117) раза больше влияет на желание туристов посещать дискотеки, чем доход их семьи.
Корреляционные коэффициенты, представленные в табл. 7.9, позволяют оценить, насколько сильна связь дискриминационных переменных со стандартизированными значениями дискриминантной функции. В табл. 7.10 представлены нестандартизированные (канонические) коэффициенты дискриминантной функции, именно они используются для построения дискриминантной модели. Таблица 7.10 Канонические коэффициенты дискриминантной функции Canonical Discriminant Function Coefficients*
* Нестандартизированные коэффициенты. В соответствии с данными, представленными в табл. 7.10, дискриминантная модель, построенная в результате проведения дискриминантного анализа, имеет следующий вид: d = -4,2 — 0,076л: - 0,062; 2, где х, — возраст; х2 — доход семьи. Как отмечалось ранее, построенная дискриминантная модель должна как можно более четко разделять исследуемые группы. Четкость разделения исследуемых групп характеризуется расстоянием между средними значениями дискриминантной функции в исследуемых группах (табл. 7.11). Функции групповых центройдов
* Нестандартизированные канонические дискриминантные функции, которые оцениваются по групповым средним значениям. Как видно из данных, представленных в табл. 7.11, средние значение дискриминантной функции для группы туристов, посещающих дискотеки, составляет -1,104, а среднее значение дискриминантной функции для группы туристов, не посещающих дискотеки, составляет 0,104. Чем больше расстояние между средними значениями дискриминантной функции в исследуемых группах, тем более четко прослеживается различие между исследуемыми группами. Четкость различия между исследуемыми группами зависит также от рассеяния значений дискриминантной функции в исследуемых группах. Это рассеяние показано на графиках распределения значений дискриминантной функции в исследуемых группах (рис. 7.9 и 7.10).
Чем больше рассеяние значений дискриминантной функции в исследуемых группах, тем шире область их пересечения и слабее четкость различия между исследуемыми группами. Следовательно, чем больше такое рассеяние, тем сложнее однозначно определить принадлежность респондента к одной из исследуемых трупп. На основе построенной нами дискриминантной модели, можно сделать прогнозы посещения дискотек определенным туристом исходя из его возраста и уровня дохода семьи. Например, для туриста в возрасте 20 лет, принадлежащего по уровню дохода семьи к категории «7» (2800 — 3300 евро), значение дискриминантной функции составит
Согласно данным, представленным на рис. 7.9, в исследуемую группу «туристы, посещающие дискотеки» входят 88 туристов. Значение дискриминантной функции близкое к -2,246 имеют 15 человек. Поданным, представленным на рис. 7.10, исследуемая группа «туристы, не посещающие дискотеки» включает 935 человек. Значение дискриминантной функции, близкое к -2,246, имеют примерно 10 человек. На основании вышеизложенного можно сделать вывод, что турист в возрасте 20 лет, принадлежащий по уровню дохода семьи к категории «7» (2800—3300 евро), скорее всего, будет посещать дискотеки.
|
|||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 513; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.008 с.) |