Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Команды SPSS на выполнение иерархического кластерного анализаСодержание книги
Поиск на нашем сайте
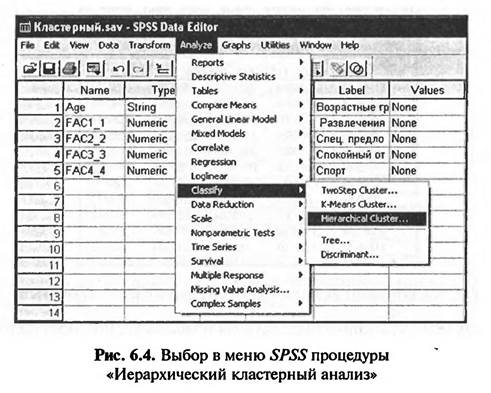
Кластерный анализ является одним из видов классификационного анализа. Для задания команд на выполнение кластерного анализа в SPSS в меню различных видов анализа (Analyze) следует выбрать «Классификационный аиапиз» (Class fy) (рис. 6.4).
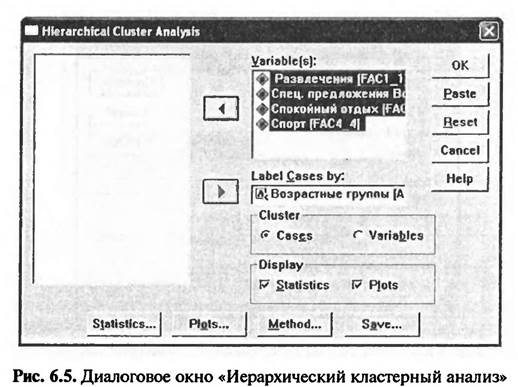
«Классификационный анализ», в свою очередь, имеет собственное меню, содержащее различные виды классификационного анализа, в том числе три вида кластерного анализа. В рассматриваемом примере применяется иерархический кластерный анализ, наиболее часто применяемый на практике. Иерархический кластерный анализ отличается от других видов кластерного анализа тем, что алгоритм его проведения является многоступенчатым. Алгоритм иерархического кластерного анализа может быть дивизионным или агломеративным. Дивизионный алгоритм проведения иерархического кластерного анализа предполагает, что все объекты исследования в начале объединены в один кластер, который поэтапно делится на более мелкие кластеры. Агломеративный алгоритм, напротив, предполагает, что все объекты исследования вначале рассматриваются как мелкие кластеры, которые затем объединяются в более крупные. На практике чаще всего используются агломеративные методы формирования кластеров. В результате выбора меню «Analyze> Classify> Hierarchical Cluster» на экране появится диалоговое окно «Иерархический кластерный анализ» (Нierarchical Cluster Analyze) (рис. 6.5).
В левом поле открывшегося диалогового окна «Иерархический кластерный анализ» представлен список пяти переменных исходного массива данных. Из них следует выбрать переменные, по которым будет производиться формирование кластеров, и перенести их в правое поле «Variable(s)». В рассматриваемом примере — это переменные, характеризующие интересы (мотивы поведения) туристов: «Развлечения», «Специальные предложения Восточной Баварии», «Спокойный отдых» и «Спорт». Также из списка всех переменных исходной базы данных следует выбрать переменную, значения которой являются объектами исследования, и перенести ее в правое поле «Label Cases by». В рассматриваемом примере это переменная «возрастные группы». В поле «Cluster» следует выбрать один из двух предлагаемых вариантов: «Cases» или «Variables» (см. рис. 6.5). В нашем примере выбран вариант «Cases». Это означает, что в ходе кластерного анализа будут классифицироваться (собираться в кластеры) возрастные группы туристов, а не их интересы (мотивы поведения).
В диалоговом окне «Иерархический кластерный анализ» также есть четыре кнопки, нажав которые открываются вспомогательные диалоговые окна:«Statistics», «Plots», «Method» и «Save». При нажатии кнопки «Statistics» на экране появляется одноименное диалоговое окно «Статистические показатели» (рис. 6.6).
Во вспомогательном диалоговом окне «Статистические показатели» отмечены команды «Agglomeration schedule» и «Proximity matrix» (см. рис. 6.6). После запуска процедуры выполнения кластерного анализа данные команды позволяют вывести на экран в качестве результатов анализа таблицу, содержащую результаты сравнения объектов исследования (Proximity matrix), и таблицу, отображающую алгоритм формирования кластеров (Agglomeration schedule). Путем нажатия кнопки «Сопи те» осуществляется возврат в главное диалоговое окно «Иерархический кластерный анализ». После нажатия кнопки «Plots» в главном диалоговом окне «Иерархический кластерный анализ» на экране появляется одноименное вспомогательное диалоговое окно «Диаграммы» (рис. 6.7).
В диалоговом окне «Диаграммы» представлены команды на построение различных графиков и диаграмм, описывающих процедуру формирования кластеров. В данном диалоговом окне отмечена команда «Dendogram». После запуска процедуры выполнения кластерного анализа данная команда выводит на экран дендограмму, которая является графическим отображением выполнения алгоритма формирования кластеров. Путем нажатия кнопки «Continue» (см. рис. 6.7) осуществляется возврат в главное диалоговое окно «Иерархический кластерный анализ» (см. рис. 6.5). При нажатии кнопки «Method» в главном диалоговом окне «Иерархический кластерный анализ» (см. рис. 6.5) на экране появляется одноименное вспомогательное диалоговое окно «Методы» (рис. 6.8).
В поле «Cluster Method» вспомогательного диалогового окна «Методы» из списка, предлагаемого SPSS, следует выбрать метод формирования кластеров. В рассматриваемом примере выбран метод «Ward». В поле «Measure» из списка возможных вариантов следует выбрать показатель, который будет использоваться в целях определения степени схожести (различия) объектов исследования. Выбор этого показателя зависит от типа переменных, участвующих в кластерном анализе в качестве критериев сегментации. Данные переменные могут быть интервальными (Interval), номинальными (Counts) или дихотомическими (Binary).
В рассматриваемом примере переменные, по которым совокупность объектов исследования разделяется на кластеры, являются интервальными, поскольку респонденты в ходе опроса да- оали балльные оценки значимости для них различных мотивов проведения времени на отдыхе. Поэтому в поле «Measure» диалогового окна «Method» отмечается тип переменной «Interval». В качестве показателя, характеризующего степень схожести (различия) объектов исследования, выбирается квадрат евклидова расстояния (,Squared EucL iean Distance). Путем нажатия кнопки «Continue» в диалоговом окне «Method» осуществляется возврат в главное диалоговое окно «Иерархический кластерный анализ» (см. рис. 6.5). В диалоговом окне «Иерархический кластерный анализ» имеется кнопка «Save», при нажатии которой активизируется одноименное диалоговое окне. В этом окне представлены команды, позволяющие сохранить результаты кластерного анализа как новые переменные в исходной базе данных. В результате выполнения этих команд после запуска процедуры выполнения кластерного анализа создается новая переменная, значения которой представляют собой номера кластеров, к которым относится тот или иной объект исследования. Запуск процедуры выполнения иерархического кластерного анализа осуществляется путем нажатия кнопки «ОК» в главном диалоговом окне «Иерархический кластерный анализ» (см. рис. 6.5).
|
||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 529; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.133.152.151 (0.006 с.) |