Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Команды SPSS на выполнение дискриминантного анализаСодержание книги
Похожие статьи вашей тематики
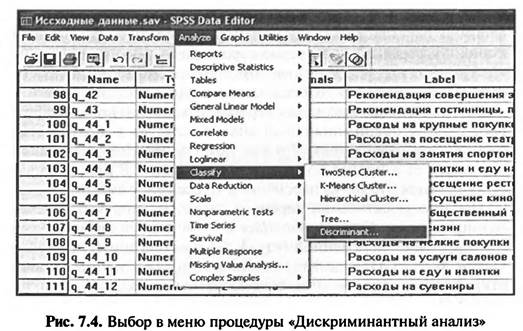
Поиск на нашем сайте Дискриминантный анализ, как и кластерный, относится к классификационным видам анализа. Для задания процедуры его выполнения в меню методов анализа, предлагаемых пакетом SPSS, следует выбрать группу методов «Classify», которая имеет собственное меню, включающее некоторые виды кластерного анализа и дискриминантный анализ (рис. 7.4).
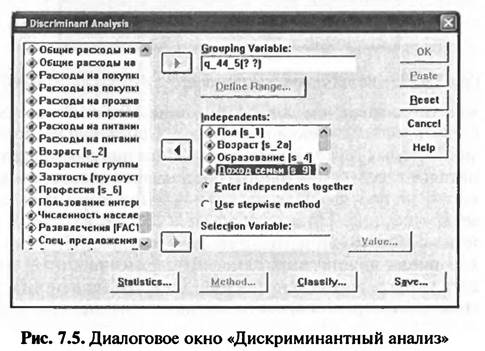
При выборе меню «Analyze > Classify > Discriminant» открывается диалоговое окно «Дискриминантный анализ», в котором формируется задание на выполнение дискриминантного анализа (рис. 7.5).
В левом поле диалогового окна «Дискриминантный анализ» находится список меток всех переменных, занесенных в исходный файл данных. Из этого списка следует выбрать метки независимых переменных дискриминантной модели и при помощи кнопки со стрелкой поочередно перенести их в правое поле окна «Independents». В рассматриваемом примере это метки переменных: «Пол», «Возраст», «Образование» и «Доход семьи». Затем из списка всех меток переменных в левом поле диалогового окна «Дискриминантный анализ» следует выбрать метку группирующей переменной и при помощи кнопки со стрелкой перенести ее в правое поле «Group ng Variable». В рассматриваемом примере это метка переменной «Посещение дискотек». После осуществления переноса метки группирующей переменной в поле «Grouping Variable» в этом поле появляется имя группирующей переменной («q_44_ 5») и активизируется кнопка «Define Range» («Определить область»). При нажатии этой кнопки открывается одноименное вспомогательное диалоговое окно (рис. 7.6).
Во вспомогательном диалоговом окне «Define Range» следует определить минимальное и максимальное значения числовых кодов исследуемых групп. В рассматриваемом примере исследуемых групп только две: «1» — «туристы, посещающие дискотеки» и «2» — «туристы, не посещающие дискотеки». После нажатия кнопки «Continue» (см. рис. 7.6) осуществляется возврат в главное диалоговое окно «Дискриминантный анализ» (см. рис. 7.5). В главном диалоговом окне «Дискриминантный анализ» следует указать метод построения дискриминантной модели. Возможен выбор пошагового метода («Use stepwise method») (см. рис. 7.5), который предполагает поэтапное включение независимых переменных в дискриминантную модель. В результате применения этого метода создается несколько дискриминантных моделей по количеству независимых переменных. В рассматриваемом примере выбран метод «Enter independents together» (см. рис. 7.5). Этот метод предполагает одновременное включение в дискриминантную модель всех заданных независимых переменных. При нажатии кнопки «Statistics» в главном диалоговом окне «Дискриминантный анализ» открывается вспомогательное диалоговое окно «Статистические показатели» (рис. 7.7).
В диалоговом окне «Статистические показатели» можно задать команды на расчет различных статистических показателей в процессе выполнения процедуры дискриминантного анализа. В рассматриваемом примере в поле «Descriptives» («Описательные статистические методы») поставлены отметки напротив команд «Means» и «Univariate A NOVAs». В результате выполнения команды «Means» рассчитываются средние значения дискриминационных переменных для каждой исследуемой группы. Результаты выполнения этой команды будут представлены далее (см. табл. 7.2). В результате выполнения команды «Univariate ANOVAs» («Одномерные тесты ANOVA») производится тест на равенство средних значений дискриминационных переменных в исследуемых группах (см. подраздел 3 «Сравнение средних величин в SPSS»). Результаты выполнения этой команды будут представлены далее (см. табл. 7.2 и 7.3). В рассматриваемом примере в поле «Matrices»(«Таблицы») диалогового окна «Статистические показатели» поставлена отметка напротив команды «Withi i-groups corretauon» (см. рис. 7.7). В результате выполнения этой команды на экран компьютера выводится таблица «Объединенные матрицы внутри групп», содержащая данные о корреляционных связях между дискриминационными переменными (см. далее табл. 7.5). Также в рассматриваемом примере в поле «Function Coefficients» диалогового окна «Статистические показатели» поставлена отметка напротив команды «Unstandardized» (см. рис. 7.7). Это означает, что при построении дискриминантной функции будут использованы нестандартизированные коэффициенты. Значения нестандарт!жированных коэффициентов дискриминантной функции в рассматриваемом примере будут представлены далее (см. табл. 7.10). При нажатии кнопки «Continue» в диалоговом окне «Статистические показатели» данное окно закрывается и осуществляется возврат в главное диалоговое окно «Дискриминантный анализ» (см. рис. 7.5). При нажатии кнопки «Classify» е главном диалоговом окне «Дискриминантный анализ» открывается вспомогательное диалоговое окно «Классификация» (рис. 7.8).
В диалоговом окне «Классификация» задаются условия и форма представления классификации объектов исследования, т.е. распределения их по группам. В рассматриваемом примере речь идет о разделении туристов на две группы: «посещающие дискотеки» и «не посещающие дискотеки». В поле «Plots» («Графики») диалогового окна «Классификация» можно задать построение графиков, иллюстрирующих результаты классификации. В рассматриваемом примере поставлена отметка напротив команды «Separate-groups» («Разделенные группы») (см. рис. 7.8). В результате выполнения этой команды на экран выводятся графики распределения дискриминантной функции для каждой исследуемой группы. Результаты выполнения этой команды будут представлены далее (см. табл. 7.9 и 7.10). В поле «Display» диалогового окна «Классификация» задается форма представления результатов классификации. В рассматриваемом примере отмечена команда «Casewise results» («Результаты отдельно по каждому наблюдению»). Таким образом, на экран выводятся результаты классификации отдельно по каждому респонденту, а именно к какой группе и с какой вероятностью он может быть причислен исходя из значения дискриминантной функции. Следует ограничить число респондентов, по которым представляются результаты классификации. Это можно сделать при помощи команды «Lim teases to first...» («Ограничить наблюдения по первым...»). В нашем примере задано ограничение по первым 20 респондентам (см. рис. 7.8). Результаты классификации по первым 20 респондентам будут представлены далее (см. табл. 7.12). В поле «Display» диалогового окна «Классификация» также поставлена отметка напротив команды «Summary table» («Сводная таблица»). В результате выполнения этой команды на экран компьютера выводится сводная таблица результатов классификации (см. далее табл. 7.13). При нажатии кнопки «Continue» в диалоговом окне «Классификация» данное окно закрывается и осуществляется возврат в главное диалоговое окно «Дискриминантный анализ» (см. рис. 7.5). При нажатии кнопки «Save» («Сохранить») в диалоговом окне «Дискриминантный анализ» открывается одноименное вспомогательное диалоговое окно, в котором можно задать команды на сохранение результатов дискриминантного анализа в виде новых переменных в исходном файле данных, В рассматриваемом примере такие операции не производятся. Запуск процедуры выполнения дискриминантного анализа осуществляется путем нажатия кнопки «ОК» в главном диалоговом окне «Дискриминантный анализ».
|
||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 725; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.01 с.) |