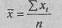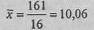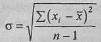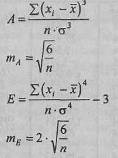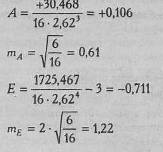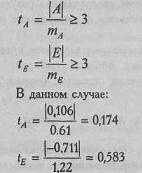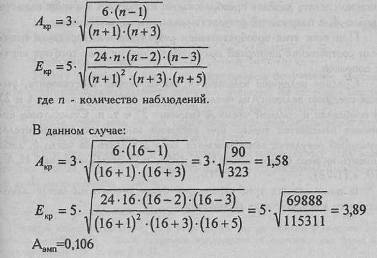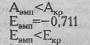Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Проверка нормальности распределения результативного признака.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Дисперсионный анализ относится к группе параметрических методов и поэтому его следует применять только тогда, когда известно илидоказано, что распределение признака является нормальным (Суходольский Г.В., 1972; Шеффе Г., 1980 и др.). Строго говоря, перед тем, как применять дисперсионный анализ, мы должны убедиться в нормальности распределения результативного признака. Нормальность распределения результативного признака можно проверить путем расчета показателей асимметрии и эксцесса и сопоставления их с критическими значениями (Пустыльник Е.И., 1968* Плохинский Н.А., 1970 и др.). Произведем необходимые расчеты на примере параграфа 8.3, в котором анализируется длительность мышечного волевого усилия. Действовать будем по следующему алгоритму: а) определим показатели асимметрии и эксцесса по формулам Н.А. Плохинского и сопоставим их с критическими значениями, указанными Н.А. Плохинским; б) рассчитаем критические значения показателей асимметрии и эксцесса по формулам Е.И. Пустыльника и сопоставим с ними эмпирические значения; в) если эмпирические значения показателей окажутся ниже критических, сделаем вывод о том, что распределение признака не отличается от нормального. Таблица 7.1 Вычисление показателей асимметрии и эксцесса по показателю длительности попыток решения анаграмм
Для расчетов в Табл. 7.1 необходимо сначала определить среднюю арифметическую по формуле:
где хi - каждое наблюдаемое значение признака; n - количество наблюдений. В данном случае:
Стандартное отклонение (сигма) вычисляется по формуле:
где хi - каждое наблюдаемое значение признака;
Показатели асимметрии и эксцесса с их ошибками репрезентативности определяются по следующим формулам:
где (хi – σ - стандартное отклонение; п - количество испытуемых. В данном случае:
Показатели асимметрии и эксцесса свидетельствуют о достоверном отличии эмпирических распределений от нормального в том случае, если они превышают по абсолютной величине свою ошибку репрезентативности в 3 и более раз:
Мы видим, что оба показателя не превышают в три раза свою ошибку репрезентативности, из чего мы можем заключить, что распределение данного признака не отличается от нормального. Теперь произведем проверку по формулам Е.И. Пустыльника. Рассчитаем критические значения для показателей А и Е:
Итак, оба варианта проверки, по Н.А. Плохинскому и по Е.И. Пустыльнику, дают один и тот же результат: распределение результативного признака в данном примере не отличается от нормального распределения. Можно выбрать любой из двух предложенных вариантов проверки и придерживаться его. При больших объемах выборки, по-видимому, стоит производить расчет первичных статистик (оценок параметров) на ЭВМ.
4) Преобразование эмпирических данных с целью упрощения расчетов Н.А. Плохинский указывает на возможность следующих преобразований: 1) все наблюдаемые значения можно разделить на одно и то же число k, например перевести показатели из миллиметров в сантиметры и т.п.; 2) все наблюдаемые значения можно умножить на одно и то же число k, например для того, чтобы избавиться от дробных значений; 3) от всех наблюдаемых значений можно отнять одно и то же число А, например наименьшее значение; 4) можно сделать двойное преобразование: из каждого значения вычесть число А, а полученный результат разделить на другое число k. При всех этих преобразованиях результативного признака показатели соотношения дисперсий получаются точными и не требуют никаких поправок. Средние величины изменяются, но их можно восстановить, умножая среднюю величину на число k или деля ее на k (варианты 1 и 2) или прибавляя к средней число А (вариант 3) и т. п. Стандартное отклонение изменяется только при введении множителя или делителя; полученный результат затем придется либо разделить на число к, либо умножить на него (Плохинский Н.А.,1964, с.34-36; Плохинский Н.А., 1970, с.71-72). В последующих трех параграфах будет рассмотрен метод одно-факторного анализа в двух вариантах: а) для дисперсионных комплексов, представляющих данные одной и той же выборки испытуемых, подвергнутой влиянию разных условий (разных градаций фактора); б) для дисперсионных комплексов, в которых влиянию разных условий (градаций фактора) были подвергнуты разные выборки испытуемых. Первый вариант называется однофакторным дисперсионным анализом для связанных выборок, второй - для несвязанных выборок. Все предложенные алгоритмы расчетов предназначены для равномерных комплексов, где в каждой ячейке представлено одинаковое | число наблюдений. 7.3. Однофакторный дисперсионный анализ для несвязанных выборок Назначение метода Метод однофакторного дисперсионного анализа применяется в тех |случаях, когда исследуются изменения результативного признака под [влиянием изменяющихся условий или градаций какого-либо фактора. В данном варианте метода влиянию каждой из градаций фактора подвергаются разные выборки испытуемых. Градаций фактора должно быть не менее трех4. Непараметрическим вариантом этого вида анализа является критерий Н Крускала-Уоллиса. Описание метода Работу начинаем с того, что представляем полученные данные в виде столбцов индивидуальных значений. Каждый из столбцов соответствует тому или иному из изучаемых условий (см. Табл. 7.2). После этого нам нужно просуммировать индивидуальные значения по столбцам и суммы возвести в квадрат. Суть метода состоит в том, чтобы сопоставить сумму этих возведенных в квадрат сумм с суммой квадратов всех значений, полученных во всем эксперименте. ___________ 4 Градаций может быть и две, но в этом случае мы не сможем установить нелинейных зависимостей и более разумным представляется использование более простых критериев (см. главы 2 и 3).
Гипотезы H0: Различия между градациями фактора (разными условиями) являются не более выраженными, чем случайные различия внутри каждой группы. H1: Различия между градациями фактора (разными условиями) являются более выраженными, чем случайные различия внутри каждой группы.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-19; просмотров: 424; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.146.255.135 (0.006 с.) |

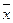 )
)