
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Операторы throw без параметровСодержание книги
Поиск на нашем сайте
Итак, мы увидели, как новый метод обработки ошибок удобен и прост. Блок try-catch может содержать вложенные блоки try-catch и если не будет определено соответствующего оператора catch на текущем уровен вложения, исключение будет поймано на более высоком уровне. Единственная вещь, о которой вы должны помнить, - это то, что операторы, следующие за throw, никогда не выполнятся. try { throw; // ни один оператор, следующий далее (до закрывающей скобки) // выполнен не будет } catch (...) { cout << "Исключение!" << endl; } Такой метод может применяться в случаях, когда не нужно передавать никаких данных в блок catch. Заключение Метод обработки исключений, приведенный в статье, является удобным и мощным средством, однако только вам решать, использовать его или нет. Одно можно сказать точно - приведенный метод облегчит вам жизнь. Если хотите узнать об исключениях чуть больше, посмотрите публикацию Deep C++ на сервере MSDN.
Лабораторная работа № 19. Использование исключительных ситуаций C++ для обработки ошибок. Цель работы: Овладеть навыками обработки и использования исключительных ситуаций Контрольные вопросы 1) Что такое исключительная ситуация? 2) Можно ли предусмотреть заранее все исключительные ситуации, возникающие в программе? 3) Какой способ обработки исключительных ситуаций предлагает объектно-ориентированное программирование? 4) Какие конструкции предлагает язык С++ для обработки исключительных ситуаций? 5) Имеет ли значение порядок записи блоков catch() {}? 6) Может ли исключительная ситуация возникнуть в блоке catch() {}? 7) Можно ли в блок catch () {} вложить блок try {} catch () {} для обработки возникшей там исключительной ситуации? 8) Можно ли вкладывать блоки try{} catch () {} один в другой? 9) Что должен содержать класс-исключение? 10) Где создаются объекты классов-исключений? 11) Что делает исполняющая система С++, если исключительная ситуация не обрабатывается в программе? 12) Можно ли изменить эти стандартные действия исполняющей системы С++? 13) Что делает исполняющая система С++, если метод не обрабатывает исключительную ситуацию и не декларирует это в своем заголовке? 14) Можно ли обработать одну и ту же исключительную ситуацию несколько раз?
Задание Постройте таблицу значений функции y=f(x) для
Замечание. При решении данной задачи использовать вспомогательный метод f(x), реализующий заданную функцию, а также проводить обработку возможных исключений. 1. Пример:
#include <math.h> #include <iostream> #include <iomanip>
using namespace std;
double f(double x){ try { //если х не попадает в область определения, то генерируется исключение if (x == -1) throw "х не попадает в область определения"; else return 1 /powf(1 + x, 2); } catch(char * str) { /*Исключение, перехваченное одной catch-инструкцией, можно сгенерировать повторно, чтобы обеспечить возможность его перехвата другой (внешней) catch-инструкцией. Это позволяет нескольким обработчикам получить доступ к исключению. Нужно помнить, что при повторном генерировании исключения оно не будет повторно перехватываться той же catch-инструкцией, а передается следующей (внешней) catch-инструкции.*/ throw; //повторная генерация исключения } }
void main() { setlocale(LC_ALL, "russian"); double a,b,h; cout<<"a="; cin>>a; cout<<"b="; cin>>b; cout<<"h="; cin>>h; for (double i = a; i <= b; i += h) { try { cout<<"y("<<i<<") = "<<setprecision(6)<<f(i)<<endl; } catch(char *ex) { cout<<"y("<<i<<") = error "<<ex<<endl; } } }
Содержание отчета 1) Титульный лист. 2) Наименование и цель работы. 3) Краткое теоретическое описание. 4) Задание на лабораторную работу. 5) Схема алгоритма. 6) Листинг программы. 7) Результаты выполнения программы. 14. Стандарт С++ 11 (самостоятельное изучение) Краткая теория http://habrahabr.ru/post/182920/ #1 — auto До С++11, ключевое слово auto использовалось как спецификатор хранения переменной (как, например, register, static, extern). В С++11 auto позволяет не указывать тип переменной явно, говоря компилятору, чтобы он сам определил фактический тип переменной, на основе типа инициализируемого значения. auto i = 42; // i - int auto l = 42LL; // l - long long auto p = new foo(); // p - foo*
Использование auto позволяет сократить код (если, конечно, тип не int, который на одну букву меньше). Сравним С++03 и С++11 // C++03 for (std::vector<std::map<int, std::string>>::const_iterator it = container.begin(); it!= container.end(); ++it)
{ // do smth } // C++11 for (auto it = container.begin(); it!= container.end(); ++it) { // do smth }
Стоить отметить, что возвращаемое значение не может быть auto. Однако, вы можете использовать auto вместо типа возвращаемого значения функции. В таком случае, auto не говорит компилятору, что он должен определить тип, он только дает ему команду искать возвращаемый тип в конце функции. В примере ниже, возвращаемый тип функции compose— это возвращаемый тип оператора +, который суммирует значения типа T и E.
template <typename T, typename E> auto compose(T a, E b) -> decltype(a+b) // decltype - позволяет определить тип на основе входного параметра { return a+b; } auto c = compose(2, 3.14); // c - double
#2 — nullptr
Раньше, для обнуления указателей использовался макрос NULL, являющийся нулем — целым типом, что, естественно, вызывало проблемы (например, при перегрузке функций). Ключевое слово nullptr имеет свой собственный тип std::nullptr_t, что избавляет нас от бывших проблем. Существуют неявные преобразования nullptr к нулевому указателю любого типа и к bool (как false), но преобразования к целочисленным типам нет. void foo(int* p) {}
void bar(std::shared_ptr<int> p) {}
int* p1 = NULL; int* p2 = nullptr;
if (p1 == p2) { }
foo(nullptr); bar(nullptr); bool f = nullptr; int i = nullptr; // ошибка: для преобразования в int надо использовать reinterpret_cast
#3 — range-based циклы Range-Based for — это цикл по контейнеру. Он аналогичен циклу for each в Java или C#. Синтаксически он повторяет for each из Java. Назван он Range-Based в первую очередь потому, чтобы избежать путаницы, ибо в STL уже давно есть алгоритм, именуемыйstd::for_each. std :: vector <int> foo;// заполняем вектор for (int x: foo) std :: cout << x << std :: endl;Модель ссылок работает также, как и везде: for (int& x: foo) x *= 2; for (const int& x: foo) std :: cout << x << std :: endl;Красиво и удобно, правда? Рассмотренный выше auto усиливает данную конструкцию: std :: vector < std :: pair <int, std :: string >> container;//... for (const auto& i: container) std :: cout << i.second << std :: endl;Range-Based for, к слову, работает и на обычных статических массивах: int foo[] = {1, 4, 6, 7, 8}; for (int x: foo) std :: cout << x << std :: endl;#4 — override и final Были добавлены два новых идентификатора (не ключевые слова): override, для указания того, что метод является переопределением виртуального метода в базовом классе и final, указывающий что производный класс не должен переопределять виртуальный метод. Первый пример теперь выглядит так:
class B { public: virtual void f(short) {std::cout << "B::f" << std::endl;} };
class D: public B { public: virtual void f(int) override {std::cout << "D::f" << std::endl;} };
Теперь это вызовет ошибку при компиляции (точно так же, если бы вы использовалиoverride во втором примере):
D::f: method with override specifier 'override' did not override any base class methods С другой стороны, если вы хотите сделать метод, не предназначенный для переопределения (ниже в иерархии), его следует отметить как final. В производном классе можно использовать сразу оба идентификатора.
class B { public: virtual void f(int) {std::cout << "B::f" << std::endl;} };
class D: public B { public: virtual void f(int) override final {std::cout << "D::f" << std::endl;} };
class F: public D { public: virtual void f(int) override {std::cout << "F::f" << std::endl;} }; Функция, объявленная как final, не может быть переопределена функцией F::f() — в этом случае, она переопределяет метод базового класса (В) для класса D. #5 — строго-типизированный enum У «традиционных» перечислений в С++ есть некоторые недостатки: они экспортируют свои значения в окружающую область видимости (что может привести к конфликту имен), они неявно преобразовываются в целый тип и не могут иметь определенный пользователем тип.
Эти проблемы устранены в С++11 с введением новой категории перечислений, названных strongly-typed enums. Они определяются ключевым словом enum class. Они больше не экспортируют свои перечисляемые значения в окружающую область видимости, больше не преобразуются неявно в целый тип и могут иметь определенный пользователем тип (эта опция так же добавлена и для «традиционных» перечислений"). enum class Options {None, One, All}; Options o = Options::All; #6 — интеллектуальные указатели Есть много статей, как на хабре, так и на других ресурсах, написанных на эту тему, поэтому я просто хочу упомянуть об интеллектуальных указателях с подсчетом ссылок и автоматическим освобождением памяти: unique_ptr: должен использоваться, когда ресурс памяти не должен был разделяемым (у него нет конструктора копирования), но он может быть передан другому unique_ptr shared_ptr: должен использоваться, когда ресурс памяти должен быть разделяемым weak_ptr: содержит ссылку на объект, которым управляет shared_ptr, но не осуществляет подсчет ссылок; позволяет избавиться от циклической зависимости Приведенный ниже пример демонстрирует unique_ptr. Для передачи владения объектом другому unique_ptr, используйте std::move (эта функция будет обсуждаться в последнем пункте). После передачи владения, интеллектуальный указатель, который передал владение, становится нулевым и get() вернет nullptr. void foo(int* p) { std::cout << *p << std::endl; } std::unique_ptr<int> p1(new int(42)); std::unique_ptr<int> p2 = std::move(p1); // transfer ownership
if (p1) foo(p1.get());
(*p2)++;
if (p2) foo(p2.get());
Второй пример демонстрирует shared_ptr. Использование похоже, хотя семантика отличается, поскольку теперь владение совместно используемое. void foo(int* p) { } void bar(std::shared_ptr<int> p) { ++(*p); } std::shared_ptr<int> p1(new int(42)); std::shared_ptr<int> p2 = p1;
bar(p1); foo(p2.get());
И, наконец, пример с weak_ptr. Заметьте, что вы должны получить shared_ptr для объекта, вызывая lock(), чтобы получить доступ к объекту. auto p = std::make_shared<int>(42); std::weak_ptr<int> wp = p; { auto sp = wp.lock(); std::cout << *sp << std::endl; } p.reset(); if (wp.expired()) std::cout << "expired" << std::endl;
#7 — лямбды В новом стандарте наконец-то была добавлена поддержка лямбда-выражений. Мы можете использовать лямбды везде, где ожидается функтор или std::function. Лямбда, вообще говоря, представляет собой более короткую запись функтора, что-то вроде анонимного функтора. Подробнее можно почитать, например, на MSDN.
std::vector<int> v; v.push_back(1);
v.push_back(2); v.push_back(3);
std::for_each(std::begin(v), std::end(v), [](int n) {std::cout << n << std::endl;});
auto is_odd = [](int n) {return n%2==1;}; auto pos = std::find_if(std::begin(v), std::end(v), is_odd); if(pos!= std::end(v)) std::cout << *pos << std::endl;
Теперь немного более хитрые — рекурсивные лямбды. Представьте лямбду, представляющую функцию Фибоначчи. Если вы попытаетесь записать ее, используя auto, то получите ошибку компиляции:
auto fib = [&fib](int n) {return n < 2? 1: fib(n-1) + fib(n-2);};
error C3533: 'auto &': a parameter cannot have a type that contains 'auto' error C3531: 'fib': a symbol whose type contains 'auto' must have an initializer error C3536: 'fib': cannot be used before it is initialized error C2064: term does not evaluate to a function taking 1 arguments
Здесь имеет место циклическая зависимость. Чтобы избавиться от нее, необходимо явно определить тип функции, используя std::function.
std::function<int(int)> lfib = [&lfib](int n) {return n < 2? 1: lfib(n-1) + lfib(n-2);};
|
||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-11; просмотров: 799; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.224.33.83 (0.012 с.) |

 [a, b] с шагом h. Если в некоторой точке x функция не определена, то выведите на экран сообщение об этом.
[a, b] с шагом h. Если в некоторой точке x функция не определена, то выведите на экран сообщение об этом.
 .
.
 ;
;
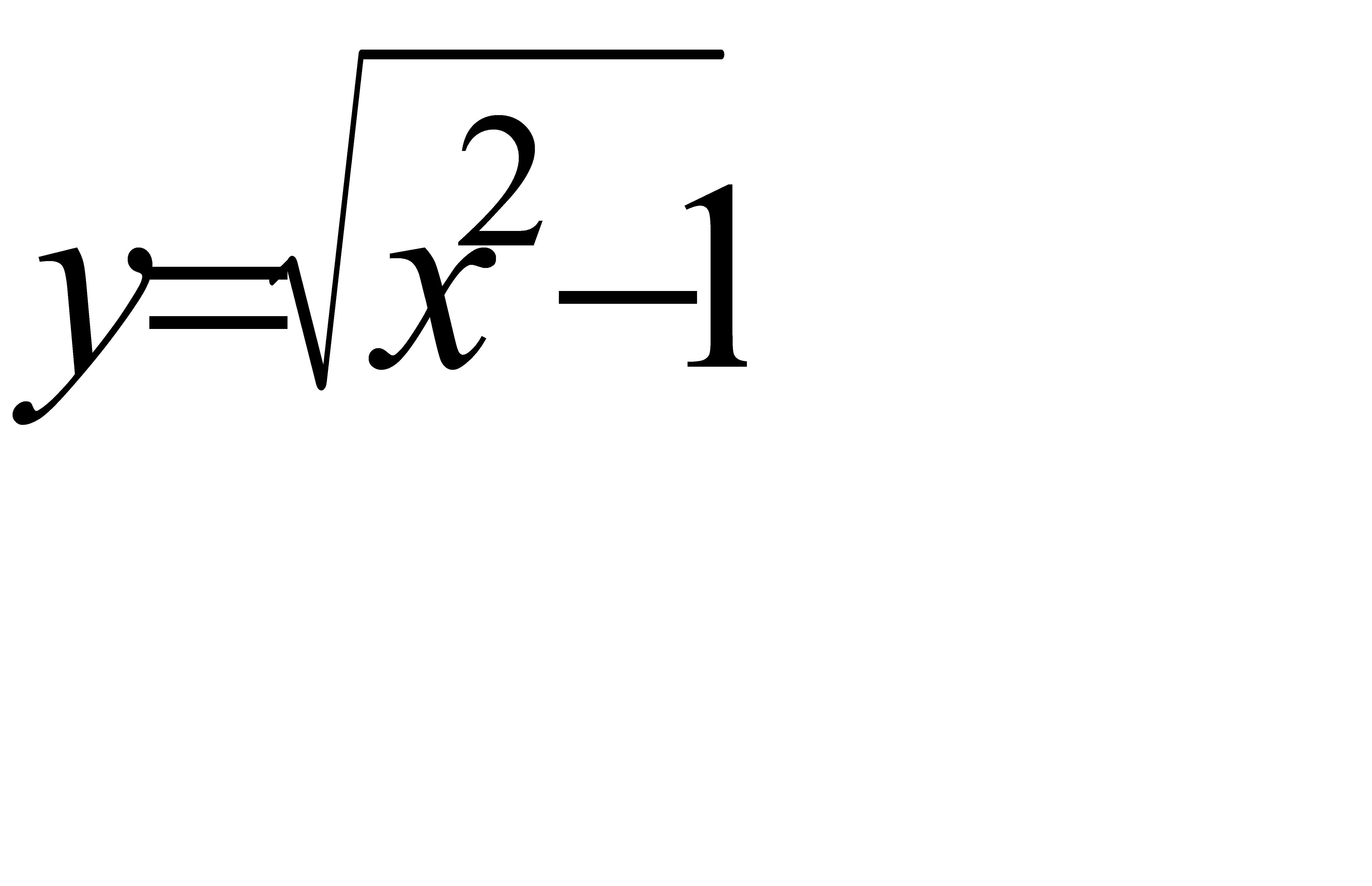 ;
;
 ;
;
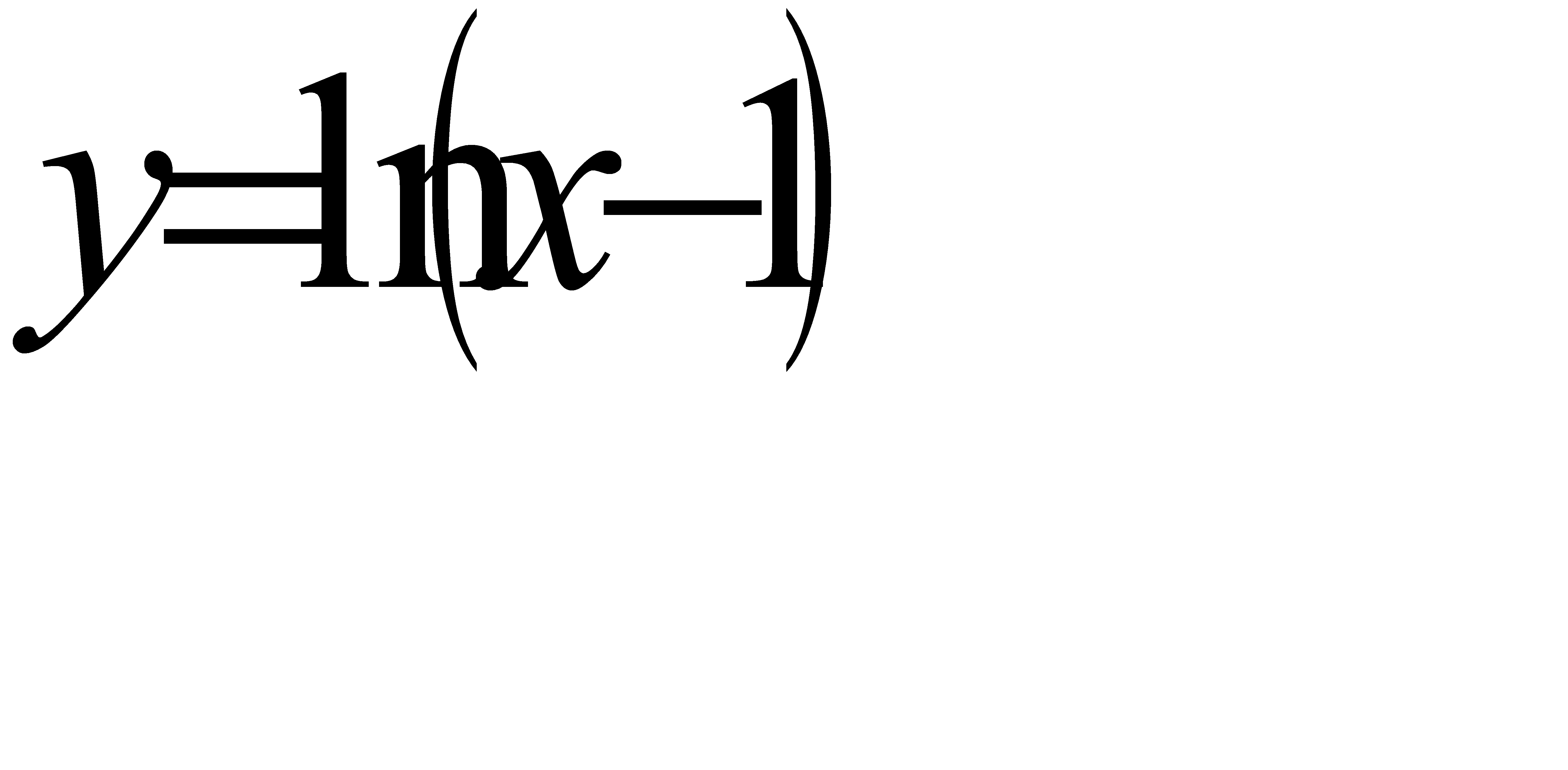 ;
;
 ;
;
 ;
;
 ;
;
 ;
;
 ;
;
 ;
;
 ;
;
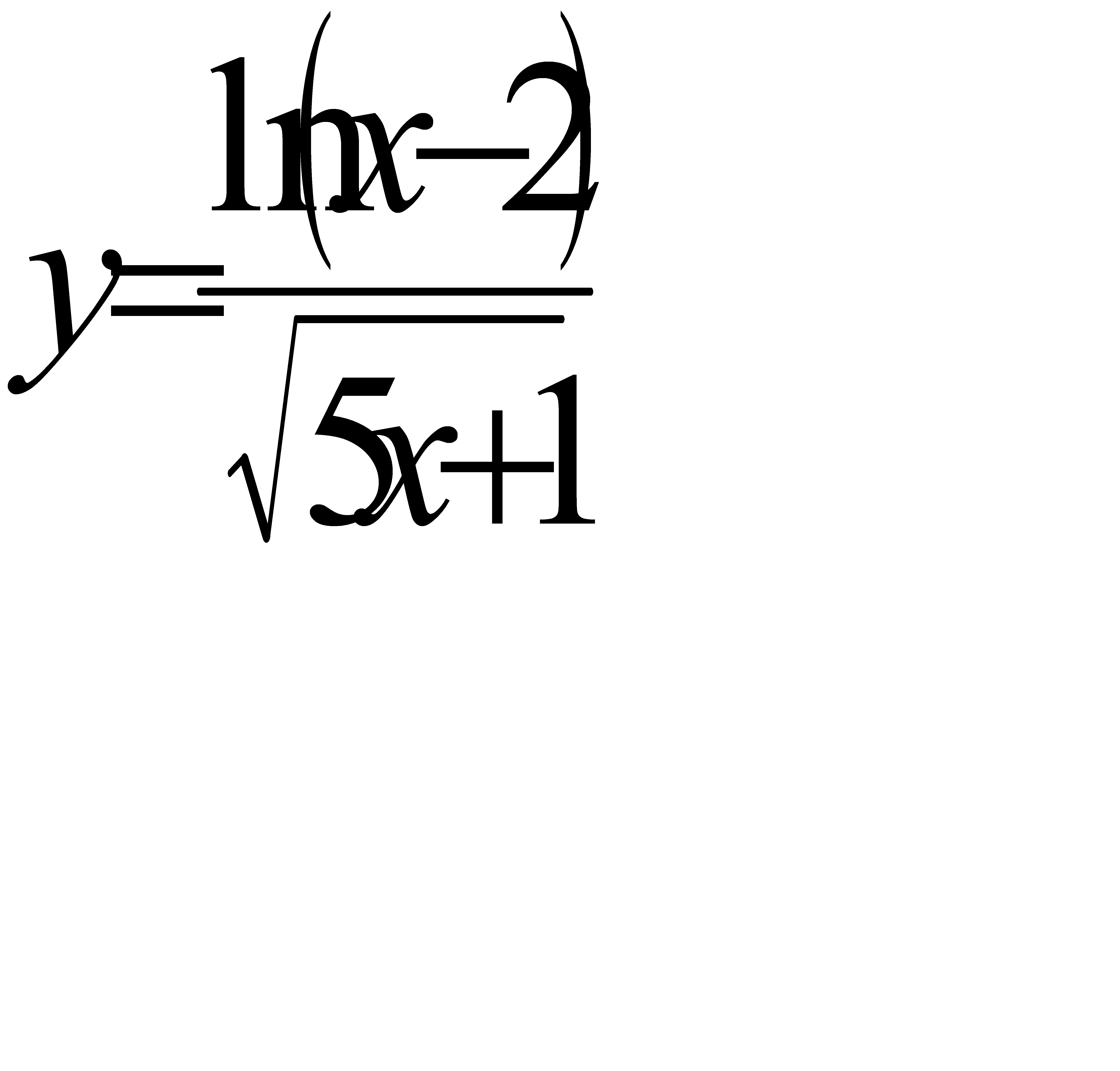 ;
;
 ;
;
 ;
;
 ;
;
 ;
;
 ;
;



