Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Лекции 10-11. Системы управления данными (файловые системы)Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
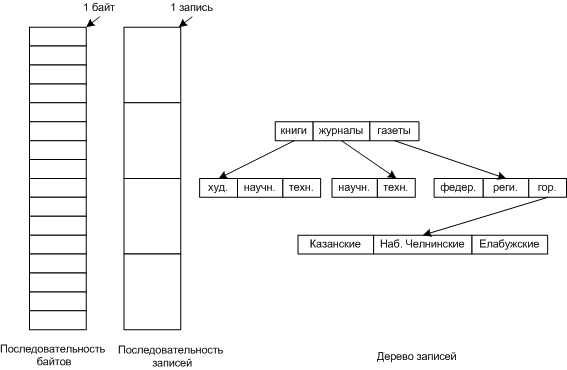
Лекции 10-11. Системы управления данными (файловые системы) Лекция 10. Организация файловых систем Файлы Требования к хранению информации: · возможность хранения больших объемов данных · информация должна сохраняться после прекращения работы процесса · несколько процессов должны иметь одновременный доступ к информации Именование файлов Длина имени файла зависит от ОС, может быть от 8 (MS-DOS) до 255 (Windows, LINUX) символов. ОС могут различать прописные и строчные символы. Например, WINDOWS и windows для MS-DOS одно и тоже, но для UNIX это разные файлы. Во многих ОС имя файла состоит из двух частей, разделенных точкой, например windows.exe. Часть после точки называют расширением файла. По нему система различает тип файла. У MS-DOS расширение составляет 3 символа. По нему система различает тип файла, а также можно его исполнять или нет. У UNIX расширение ограничено размером имени файла в 255 символов, также у UNIX может быть несколько расширений, но расширениями пользуются больше прикладные программы, а не ОС. По расширению UNIX не может определить исполняемый это файл или нет. Структура файла Три основные структуры файлов: 1. Последовательность байтов - ОС не интересуется содержимым файла, она видит только байты. Основное преимущество такой системы, это гибкость использования. Используются в Windows и UNIX. 2. Последовательность записей - записей фиксированной длины (например, перфокарта), считываются последовательно. Сейчас не используются. 3. Дерево записей - каждая запись имеет ключ, записи считываются по ключу. Основное преимущество такой системы, это скорость поиска. Пока еще используется на мэйнфреймах.
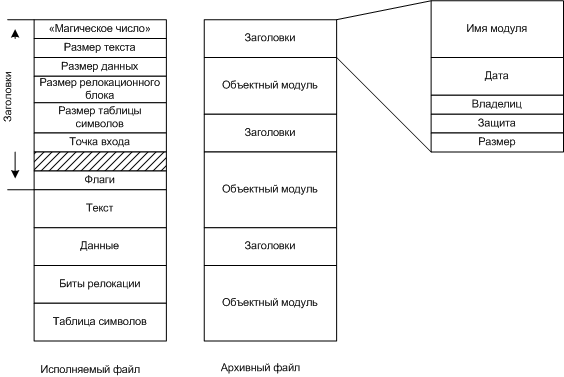
Три типа структур файла. Типы файлов Основные типы файлов: · Регулярные - содержат информацию пользователя. Используются в Windows и UNIX. · Каталоги - системные файлы, обеспечивающие поддержку структуры файловой системы. Используются в Windows и UNIX. · Символьные - для моделирования ввода-вывода. Используются только в UNIX. · Блочные - для моделирования дисков. Используются только в UNIX. Основные типы регулярных файлов: · ASCII файлы - состоят из текстовых строк. Каждая строка завершается возвратом каретки (Windows), символом перевода строки (UNIX) и используются оба варианта (MS-DOS). Поэтому если открыть текстовый файл, написанный в UNIX, в Windows, то все строки сольются в одну большую строку, но под MS-DOS они не сольются (это достаточно частая ситуация). Основные преимущества ASCII файлов: - могут отображаться на экране, и выводится на принтер без преобразований · Двоичные файлы - остальные файлы (не ASCII). Как правило, имеют внутреннею структуру. Основные типы двоичных файлов: · Исполняемые - программы, их может обрабатывать сама операционная система, хотя они записаны в виде последовательности байт. · Неисполняемые - все остальные.
Примеры исполняемого и не исполняемого файла «Магическое число» - идентифицирующее файл как исполняющий. Доступ к файлам Основные виды доступа к файлам: · Последовательный - байты читаются по порядку. Использовались, когда были магнитные ленты. · Произвольный - файл можно читать с произвольной точки. Основное преимущество возникает, когда используются большие файлы (например, баз данных) и надо считать только часть данных из файла. Все современные ОС используют этот доступ. Атрибуты файла Основные атрибуты файла: · Защита - кто, и каким образом может получить доступ к файлу (пользователи, группы, чтение/запись). Используются в Windows и UNIX. · Пароль - пароль к файлу · Создатель - кто создал файл · Владелец - текущий владелец файла · Флаг "только чтение" - 0 - для чтения/записи, 1 - только для чтения. Используются в Windows. · Флаг "скрытый" - 0 - виден, 1 - невиден в перечне файлов каталога (по умолчанию). Используются в Windows. · Флаг "системный" - 0 - нормальный, 1 - системный. Используются в Windows. · Флаг "архивный" - готов или нет для архивации (не путать сжатием). Используются в Windows. · Флаг "сжатый" - файл сжимается (подобие zip архивов). Используются в Windows. · Флаг "шифрованный" - используется алгоритм шифрования. Если кто-то попытается прочесть файл, не имеющий на это прав, он не сможет его прочесть. Используются в Windows. · Флаг ASCII/двоичный - 0 - ASCII, 1 - двоичный · Флаг произвольного доступа - 0 - только последовательный, 1 - произвольный доступ · Флаг "временный" - 0 - нормальный, 1 - для удаления файла по окончании работы процесса · Флаг блокировки - блокировка доступа к файлу. Если он занят для редактирования. · Время создания - дата и время создания. Используются UNIX. · Время последнего доступа - дата и время последнего доступа · Время последнего изменения - дата и время последнего изменения. Используются в Windows и UNIX. · Текущий размер - размер файла. Используются в Windows и UNIX. Операции с файлами Основные системные вызовы для работы с файлами: · Create - создание файла без данных. · Delete - удаление файла. · Open - открытие файла. · Close - закрытие файла. · Read - чтение из файла, с текущей позиции файла. · Write - запись в файл, в текущею позицию файла. · Append - добавление в конец файла. · Seek - устанавливает файловый указатель в определенную позицию в файле. · Get attributes - получение атрибутов файла. · Set attributes - установить атрибутов файла. · Rename - переименование файла. Пример копирования файла через отображение в памяти. Алгоритм: 1. Создается сегмент для файла 1 2. Файл отображается в памяти 3. Создается сегмент для файла 2 4. Сегмент 1 копируется в сегмент 2 5. Сегмент 2 сохраняется на диске Недостатки этого метода: · Тяжело определить длину выходного файла · Если один процесс отобразил файл в памяти и изменил его, но файл еще не сохранен, второй процесс откроет это же файл, и будет работать с устаревшим файлом. · Файл может оказаться большим, больше сегмента или виртуального пространства. Каталоги Имя пути Для организации дерева каталогов нужен некоторый способ указания файла. Два основных метода указания файла: · абсолютное имя пути - указывает путь от корневого каталога, например: - для Windows \usr\ast\mailbox - для UNIX /usr/ast/mailbox - для MULTICS >usr>ast>mailbox · относительное имя пути - путь указывается от текущего каталога (рабочего каталога), например: - если текущий каталог /usr/, то абсолютный путь /usr/ast/mailbox перепишется в ast/mailbox - если текущий каталог /usr/ast/, то абсолютный путь /usr/ast/mailbox перепишется в mailbox - если текущий каталог /var/log/, то абсолютный путь /usr/ast/mailbox перепишется в../../usr/ast/mailbox ./ - означает текущий каталог ../ - означает родительский каталог Операции с каталогами Основные системные вызовы для работы с каталогами: · Create - создать каталог · Delete - удалить каталог · OpenDir - закрыть каталог · CloseDir - закрыть каталог · ReadDir - прочитать следующий элемент открытого каталога · Rename - переименование каталога · Link - создание жесткой ссылки, позволяет файлу присутствовать сразу в нескольких каталогах. · Unlink - удаление ссылки из каталога
Структура файловой системы
Реализация файлов Основная проблема - сколько, и какие блоки диска принадлежат тому или иному файлу.
Непрерывные файлы Выделяется каждому файлу последовательность соседних блоков.
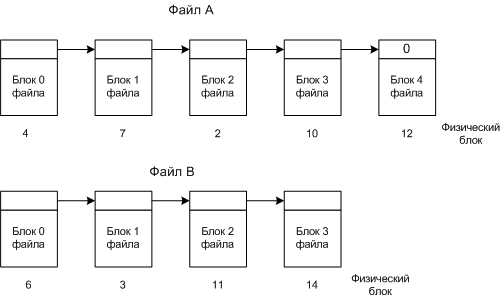
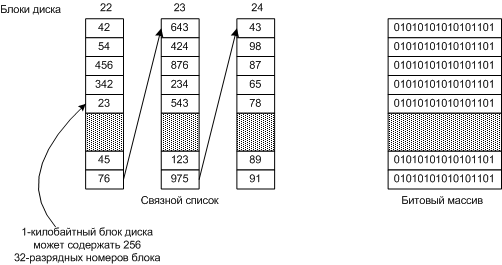
Связные списки Файлы хранятся в разных не последовательных блоках, и с помощью связных списков можно собрать последовательно файл.
Таблица размещения файлов Здесь тоже надо собирать блоки по указателям, но работает быстрее, т.к. таблица загружена в память. Основной не достаток этого метода - всю таблицу надо хранить в памяти. Например, для 20 Гбайт диска, с блоком 1Кбайт (20 млн. блоков), потребовалась бы таблица в 80 Мбайт (при записи в таблице в 4 байта). Такие таблицы используются в MS-DOS и Windows. I - узлы С каждым файлом связывается структура данных, называемая i-узлом (index-node- индекс узел), содержащие атрибуты файла и адреса всех блоков файла.
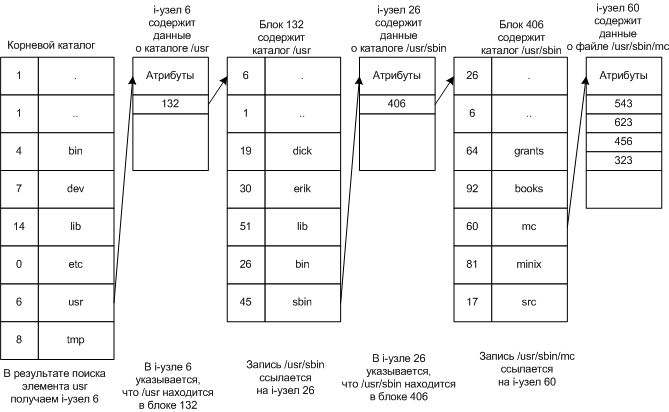
Примеры i-узла Преимущества: · Быстродействие - имея i-узел можно получить информацию о всех блоках файла, не надо собирать указатели. · Меньший объем, занимаемый в памяти. В память нужно загружать только те узлы, файлы которых используются. Если каждому файлу выделять фиксированное количество адресов на диске, то со временем этого может не хватить, поэтому последняя запись в узле является указателем на дополнительный блок адресов и т.д. Такие узлы используются в UNIX. Реализация каталогов При открытии файла используется имя пути, чтобы найти запись в каталоге. Запись в каталоге указывает на адреса блоков диска. В зависимости от системы это может быть: · дисковый адрес всего файла (для непрерывных файлов) · номер первого блока (связные списки) · номер i-узла Одна из основных задач каталоговой системы преобразование ASCII-имени в информацию, необходимую для нахождения данных. Также она хранит атрибуты файлов. Варианты хранения атрибутов: · В каталоговой записи (MS-DOS) · В i-узлах (UNIX)
Варианты реализации каталогов Ускорение поиска файлов Если каталог очень большой (несколько тысяч файлов), последовательное чтение каталога мало эффективно. 1 Использование хэш-таблицы для ускорения поиска файла. Алгоритм записи файла: · Создается хэш-таблица в начале каталога, с размером n (n записей). · Для каждого имени файла применяется хэш-функция, такая, чтобы при хэшировании получалось число от 0 до n-1. · Исследуется элемент таблицы соответствующий хэш-коду. · Если элемент не используется, туда помещается указатель на описатель файла (описатели размещены вслед за хэш-таблицей). · Если используется, то создается связный список, объединяющие все описатели файлов с одинаковым хэш-кодом. Алгоритм поиска файла: · Имя файла хэшируется · По хэш-коду определяется элемент таблицы · Затем проверяются все описатели файла из связного списка и сравниваются с искомым именем файла · Если имени файла в связном списке нет, это значит, что файла нет в каталоге. Такой метод очень сложен в реализации, поэтому используется в тех системах, в которых ожидается, что каталоги будут содержать тысячи файлов. Жесткие ссылки Может возникнуть проблема, если владелец файла удалит его (и i-узел тоже), то указатель, каталога содержащего ссылку, будет указывать на не существующий i-узел. Потом может появиться i-узел с тем же номером, а значит, ссылка будет указывать на не существующий файл. Поэтому в этом случае при удалении файла i-узел лучше не удалять. Файл будет удален только после того, как счетчик будет равен 0.
Символьные ссылки Удаление файла не влияет на ссылку, просто по ссылке будет не возможно найти файл (путь будет не верен). Удаление ссылки тоже никак не скажется на файле. Но возникают накладные расходы, чтобы получить доступ к i-узлу, должны быть проделаны следующие шаги: · Прочитать файл-ссылку (содержащий путь) · Пройти по всему этому путь, открывая каталог за каталогом Размер блока Если принято решение хранить файл в блоках, то возникает вопрос о размере этих блоков. Есть две крайности: · Большие блоки - например, 1Мбайт, то файл даже 1 байт займет целый блок в 1Мбайт. · Маленькие блоки - чтение файла состоящего из большого числа блоков будет медленным.
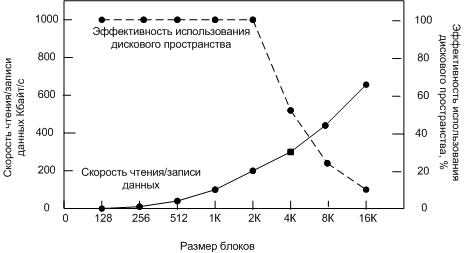
Скорости чтения/записи и эффективность использования диска, В UNIX системах размер блока фиксирован, и, как правило, равен от 1Кбайта до 4Кбайт. В MS-DOS размер блока может быть от 512 до 32 Кбайт в зависимости от размера диска, поэтому FAT16 использовать на дисках больше 500 Мбайт не эффективно. В NTFS размер блока фиксирован (от 512байт до 64 Кбайт), как правило, равен примерно 2Кбайтам (от 512байт до 64 Кбайт). Учет свободных блоков Основные два способа учета свободных блоков: · Связной список блоков диска, в каждом блоке содержится номеров свободных блоков столько, сколько вмешается в блок. Часто для списка резервируется нужное число блоков в начале диска. · Битовый массив (бит-карта) - для каждого блока требуется один бит.
Дисковые квоты Чтобы ограничить пользователя, существует механизм квот. Два вида лимитов: · Жесткие - превышены быть не могут · Гибкие - могут быть превышены, но при выходе пользователь должен удалить лишние файлы. Если он не удалил, то при следующем входе получит предупреждение, после получения нескольких предупреждений он блокируется. Наиболее распространенные квоты: · Объем использования диска · Количество файлов · Количество открытых файлов Надежность файловой системы Резервное копирование Случаи, для которых необходимо резервное копирование: · Аварийные ситуации, приводящие к потере данных на диске · Случайное удаление или программная порча файлов Основные принципы создания резервных копий: · Создавать несколько копий - ежедневные, еженедельные, ежемесячные, ежеквартальные. · Как правило, необходимо сохранять не весь диск, а толь выборочные каталоги. · Применять инкрементные резервные копии - сохраняются только измененные файлы · Сжимать резервные копии для экономии места · Фиксировать систему при создании резервной копии, чтобы вовремя резервирования система не менялась. · Хранить резервные копии в защищенном месте, не доступном для посторонних. Существует две стратегии: · Физическая архивация - поблочное копирование диска (копируются блоки, а не файлы) Недостатки: - копирование пустых блоков - проблемы с дефектными блоками - не возможно применять инкрементное копирование - не возможно копировать отдельные каталоги и файлы Преимущества: - высокая скорость копирования - простота реализации · Логическая архивация - работает с файлами и каталогами. Применяется чаще физической. Кэширование Блочный кэш (буферный кэш) - набор блоков хранящиеся в памяти, но логически принадлежащие диску. Перехватываются все запросы чтения к диску, и проверяется наличие требуемых блоков в кэше. Ситуация схожа со страничной организацией памяти, можно применять те же алгоритмы. Нужно чтобы измененные блоки периодически записывались на диск. В UNIX это выполняет демон update (вызывая системный вызов sync). В MS-DOS модифицированные блоки сразу записываются на диск (сквозное кэширование). Опережающее чтение блока Если файлы считываются последовательно, и когда получен к-блок, можно считать блок к+1 (если его нет в памяти). Что увеличивает быстродействие. Лекция 11. Примеры файловых систем Файловой системы CD-дисков
Файловая система ISO 9660 Более подробная информация - http://ru.wikipedia.org/wiki/ISO_9660 Стандарт принят в 1988 г. По стандарту диски могут быть разбиты на логические разделы, но мы будем рассматривать диски с одним разделом. Как вы знаете блоки записываются последовательно; по спирали; сектора по 2352 байта. Порядок записи информации: 1. Каждый CD-ROM начинается с 16 блоков (неопределенных ISO 9660), эта область может быть использована для размещения загрузчика ОС или для других целей. 2. Дальше один блок основного описателя тома - хранит общую информацию о CD-ROM, в нее входит: · идентификатор системы (32байта) · идентификатор тома (32байта) · идентификатор издателя (128байт) · идентификатор лица, подготовившего данные (128байт) · имена трех файлов, которые могут содержать краткий обзор, авторские права и библиографическая информация. · ключевые слова: размер логического блока (как правило, 2048, но могут быть 4096, 8192 и т.д.); количество блоков; дата создания; дата окончания срока службы диска. · описатель корневого каталога (номер блока содержащего каталог). 3. Могут быть дополнительные описатели тома, подобные основному. Каталоговая запись стандарта ISO 9660.
Файловая система CP/M CP/M (Control Program for Microcomputers) - операционная система, предшественник MS-DOS. В ее файловой системе только один каталог, с фиксированными записями по 32 байта. Имена файлов - 8+3 символов верхнего регистра. После каждой перезагрузки рассчитывается битовый массив занятых и свободных блоков. Массив находится постоянно в памяти (для 180Кбайтного диска 23 байта массива). После завершения работы, он не записывается на диск.
Каталоговая запись CP/M Видно, что максимальный размер файла 16Кбайт (16*1Кбайт). Для файлов размером от 16 до 32 Кбайт можно использовать две записи. Для до 48 Кбайт три записи и т.д. Порядковый номер записи хранится в поле экстент. Код пользователя - каждый пользователь мог работать только со своими файлами. Порядок чтения файлов: 1. Файл открывается системным вызовом open 2. Читается каталоговая запись, из которой получает информацию о всех блоках. 3. Вызывается системный вызов read FAT-12 В первой версии MS-DOS использовалась FAT-12 с 512 байтовыми блоками, поэтому максимальный размер раздела мог достигать 2Мбайта (2^12*512байта). С увеличением дисков, этого стало не хватать, стали увеличивать размер блоков 1,2 и 4 Кбайта (2^12) (при этом эффективность использования диска падает). FAT-12до сих пор применяется для гибких дисков. FAT-16 Особенности: · 16-разрядные дисковые указатели · Размеры кластеров 512, 1, 2, 4, 8, 16 и 32Кбайт (2^15) Таблица постоянно занимала в памяти 128 Кбайт. Максимальный размер раздела диска мог достигать 2Гбайта (2^16*32Кбайта). Причем кластер в 32 Кбайта для файлов со средним размером в 1Кбайт, не эффективен. FAT-32 Особенности: · 28-разрядные адреса · Размеры кластеров 512, 1, 2, 4, 8, 16 и 32Кбайт Максимальный размер раздела диска мог бы достигать 2^28*2^15, но здесь уже вступает другое ограничение - 512 байтные сектора адресуются 32-разрядным числом, а это 2^32*2^9, т.е. 2 Тбайта. Максимальный размер раздела для различных размеров кластеров
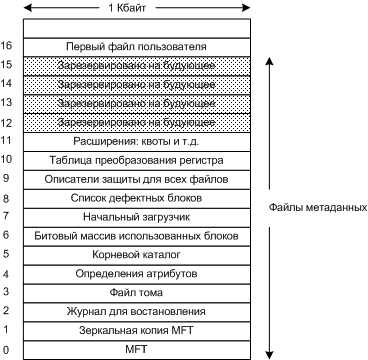
Из таблицы видно, что FAT-16 использовать не эффективно уже при разделах в 256 Мбайт, учитывая, что средний размер файла 1Кбайт. Файловая система NTFS Файловая система NTFS была разработана для Windows NT. Особенности: · 64-разрядные адреса, т.е. теоретически может поддерживать 264*216 байт (1 208 925 819 Mбайт~1Tбайт(280)). · Размеры блока (кластера) от 512байт до 64 Кбайт, для большинства используется 4Кбайта. · Поддержка больших файлов. · Имена файлов ограничены 255 символами Unicode. · Длина пути ограничивается 32 767 (215) символами Unicode. · Имена чувствительны к регистру, my.txt и MY.TXT это разные файлы (но из-за Win32 API использовать нельзя), это заложено на будущее. · Журналируемая файловая система, т.е. не попадет в противоречивое состояние после сбоев. · Контроль доступа к файлам и каталогам. · Поддержка жестких и символических ссылок. · Поддержка сжатия и шифрования файлов. · Поддержка дисковых квот. Главная файловая таблица MFT (Master File Table) - главная структура данных в каждом томе, записи фиксированные по 1Кбайту. Каждая запись описывает один каталог или файл. Для больших файлов могут использоваться несколько записей, первая запись называется - базовой записью. MFT представляет собой обычный файл (размером до 248 записей), который может располагаться в любом месте на диске.
Главная файловая таблица MFT, каждая запись ссылается на файл или каталог. Первые 16 записей MFT зарезервированы для файлов метаданных. Каждая запись описывает нормальный файл, имена этих файлов начинаются с символа "$". Каждая запись представляет собой последовательность пар (заголовок атрибута, значение). Некоторые записи метаданных в MFT: 0) Первая запись описывает сам файл MFT, и содержит все блоки файла MFT. Номер первого блока файла MFT содержится в загрузочном блоке. 1) Дубликат файла MFT, резервная копия. 2) Журнал для восстановления, например, перед созданием, удалением каталога делается запись в журнал. Система не попадет в противоречивое состояние после сбоев. 3) Информация о томе (размер, метка и версия) 4) Определяются атрибуты для MFT записей. 6) Битовый массив использованных блоков - для учета свободного места на диске 7) Указывает на файл начальной загрузки Атрибуты, используемые в записях MFT: · Стандартная информация - флаговые биты (только чтение, архивный), временные штампы и т.д. · Имя файла - имя файла в кодировке Unicode, файлы могут повторятся в формате MS-DOS 8+3. · Список атрибутов - расположение дополнительных записей MFT · Идентификатор объекта - 64-разрядный идентификатор файла, уникальный для данного тома. · Точка повторного анализа - используется для символьных ссылок и монтирования устройств. · Название тома · Версия тома · Корневой индекс - используется для каталогов · Размещение индекса - используется для очень больших каталогов · Битовый массив - используется для очень больших каталогов · Поток данных утилиты регистрации - используется для шифрования · Данные - поточные данные, может повторяться, используется для хранения самого файла. За заголовком следует список дисковых адресов, определяющий положение файла на диске, если файл очень маленький (несколько сотен байт), то следует сам файл (такой файл называется - непосредственный файл). Как привило, все данные файла не помещаются в запись MFT. Дисковые блоки файлам назначаются по возможности в виде серий последовательных блоков (сегментов файлов). В идеале файл должен быть записан в одну серию (не фрагментированный файл), файл, состоящий из n блоков, может быть записан от 1 до n серий.
Запись MFT для 9-блочного файла, состоящего из трех сегментов (серий). Заголовок содержит количество блоков (9 блоков). Каждая серия записывается в виде пары, дисковый адрес - количество блоков (20-4, 64-2, 80-3). Каждая пара, при отсутствие сжатия, это два 64-разрядные числа (16 байт на пару). Многие адреса содержат большое количество нулей, сжатие делается за счет убирания нулей в старших байтах. В результате для пары требуется чаще всего 4байта. Если файл сильно фрагментирован, требуется несколько записей MFT.
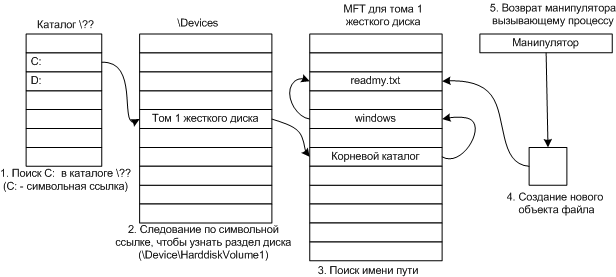
Поиск файла по имени При создании файла, программа обращается к библиотечной процедуре CreateFile("C:\windows\readmy.txt",...) Этот вызов попадает в совместно используемую библиотеку уровня пользователя kernel32.dll, где \??\ помещается перед именем файла, и получается строка: \??\C:\windows\readmy.txt Это имя пути передается системному вызову NtFileCreate в качестве параметра.
Этапы поиска файла C:\windows\readmy.txt Сжатие файлов Если файл помечен как сжатый, то система автоматически сжимает при записи, а при чтении происходит декомпрессия. Алгоритм работы: 1. Берутся для изучения первые 16 блоков файла (не зависимо от сегментов файла). 2. При меняется к ним алгоритм сжатия. 3. Если полученные данные можно записать хотя бы в 15 блоков, они записываются в сжатом виде. 4. Алгоритм повторяется для следующих 16 блоков.
Пример 48-блочного файла, сжатого до 32 блоков
Шифрование файлов Любую информацию, если она не зашифрована, можно прочитать, получив доступ. Поэтому самая надежная защита информации от несанкционированного доступа - шифрование. Даже если у вас украдут винчестер, прочесть данные не смогут (большинство не сможет). Если файл помечен как шифрованный, то система автоматически шифрует при записи, а при чтении происходит дешифрация. Шифрование и дешифрование выполняет не сама NTFS, а специальный драйвер EFS (Encrypting File System). Каждый блок шифруется отдельно. В Windows 2000 используется случайно сгенерированный 128-разрядный ключ для каждого файла. Этот ключ шифруется открытым ключом пользователя и сохраняется на диске.
Шифрование файлов в NTFS Файловая система UNIX V7 Хотя это старая файловая система основные элементы используются и современных UNIX системах. Особенности: · Имена файлов ограничены 14 символами ASCII, кроме косой черты "/" и NUL - отсутствие символа. (в последующих версиях расширены до 255) · Поддержка ссылок. · Контроль доступа к файлам и каталогам. · Имена чувствительны к регистру, my.txt и MY.TXT это разные файлы. · Используется схема i-узлов. · Не делается различий между разными файлами (текстовыми, двоичными и д.р.). · Поддерживаются символьные специальные файлы (для символьных устройств ввода-вывода). · Поддерживаются блочные специальные файлы (для блочных устройств ввода-вывода, например /dev/hd1). · Позволяет монтировать разделы в любое место дерева системы.
Структура i-узела
Первые 10 дисковых блоков файла хранятся в самом i-узле, при блоке в 1Кбайт, файл может быть 10Кбайт. Дополнительные блоки для i-узла, в случае больших файлов: · Одинарный косвенный блок -дополнительный блок с адресами блоков файла, если файл не сильно большой, то один из адресов в i-узле указывает на дополнительный блок с адресами. Файл может быть 266Кбайт=10Кбайт+256Кбайт (256Кбайт <= 256 (2^8)-адресов блоков = 1Кбайт-размер блока / 4байта-размер адреса) · Двойной косвенный блок - дополнительный блок с адресами одинарных косвенных блоков, если одного дополнительного блока не хватает. Файл может быть 65Мбайт=10Кбайт+28Кбайт+216Кбайт. · Тройной косвенный блок - дополнительный блок с адресами двойных косвенных блоков, если одного одинарного косвенного блока не хватает. Файл может быть 16Гбайт=10Кбайт+28Кбайт+216Кбайт+224Кбайт.
I-узел UNIX V7 Поиск файла
Блокировка данных файла Блокирование осуществляется по блочно. Стандартом POSIX два типа блокировки: · Блокировка с монополизацией - больше ни один процесс эти блоки заблокировать не может. · Блокировка без монополизации - могут блокировать и другие процессы.
Создание и работа с файлом fd=creat("abc", mode) - Пример создания файла abc с режимом защиты, указанном в переменной mode (какие пользователи имеют доступ). Используется системный вызов creat. Успешный вызов возвращает целое число fd - дескриптор файла. Который хранится в таблице дескрипторов файла, открывшегопроцесса. После этого можно работать с файлом, используя системные вызовы write и read. n=read(fd, buffer, nbytes) n=write(fd, buffer, nbytes) У обоих вызовов всего по три параметра: · fd - дескриптор файла, указывающий на открытый файл · buffer - адрес буфера, куда писать или откуда читать данные · nbytes - счетчик байтов, сколько прочитать или записать байт Теперь нужно по дескриптору получить указатель на i-узел и указатель на позицию в файле для записи или чтения. Таблица открытых файлов - создана для хранения указателей на i-узел и на позицию в файле. И позволяет родительскому и дочернему процессам совместно использовать один указатель в файле, но для посторонних процессов выделять отдельные указатели.
Файловая система BSD Основу составляет классическая файловая система UNIX. Особенности (отличие от предыдущей системы): · Увеличена длина имени файла до 255 символов · Реорганизованы каталоги · Было добавлено кэширование имен файлов, для увеличения производительности. · Применено разбиение диска на группы цилиндров, чтобы i-узлы и блоки данных были поближе друг к другу, для каждой группы были свои: - суперблок - i-узлы - блоки данных. Это сделано для уменьшения перемещений головок. · Используются блоки двух размеров, для больших файлов использовались большие блоки, для маленьких маленькие. Каталоговые записи ни как не отсортированы и следуют друг за другом.
Файловые системы LINUX Изначально использовалась файловая система MINIX с ограничениями: 14 символов для имени файла и размер файла 64 Мбайта. После была создана файловая система EXT с расширением: 255 символов для имени файла и размер файла 2Гбайта. Система была достаточно медленной. Файловая система EXT2 Эта файловая система стала основой для LINUX, она очень похожа BSD систему. Вместо групп цилиндров используются группы блоков.
Файловая система EXT3 В отличие от EXT2, EXT3 является журналируемой файловой системой, т.е. не попадет в противоречивое состояние после сбоев. Но она полностью совместима с EXT2. Разработанная в Red Hat В данный момент является основной для LINUX. Драйвер Ext3 хранит полные точные копии модифицируемых блоков (1КБ, 2КБ или 4КБ) в памяти до завершения операции. Это может показаться расточительным. Полные блоки содержат не только изменившиеся данные, но и не модифицированные. Такой подход называется " физическим журналированием ", что отражает использование "физических блоков" как основную единицу ведения журнала. Подход, когда хранятся только изменяемые байты, а не целые блоки, называется " логическим журналированием " (используется XFS). Поскольку ext3 использует "физическое журналирование", журнал в ext3 имеет размер больший, чем в XFS. За счет использования в ext3 полных блоков, как драйвером, так и подсистемой журналирования нет сложностей, которые возникают при "логическом журналировании". Типы журналирования поддерживаемые Ext3, которые могут быть активированы из файла /etc/fstab: · data=journal (full data journaling mode)- все новые данные сначала пишутся в журнал и только после этого переносятся на свое постоянное место. В случае аварийного отказа журнал можно повторно перечитать, приведя данные и метаданные в непротиворечивое состояние. Самый медленный, но самый надежный. · data=ordered - записываются изменения только мета-данных файловой системы, но логически metadata и data блоки группируются в единый модуль, называемый transaction. Перед записью новых метаданных на диск, связанные data блоки записываются первыми. Этот режим журналирования ext3 установлен по умолчанию. При добавлении данных в конец файла режим data=ordered гарантированно обеспечивает целостность (как при full data journaling mode). Однако если данные в файл пишутся поверх существующих, то есть вероятность перемешивания "оригинальных" блоков с модифицированными. Это результат того, что data=ordered не отслеживает записи, при которых новый блок ложится поверх существующего и не вызывает модификации метаданных. · data=writeback (metadata only) - записываются только изменения мета-данных файловой системы. Самый быстрый метод журналирования. С подобным видом журналирования вы имеете дело в файловых системах XFS, JFS и ReiserFS. Файловая система XFS XFS - журналируемая файловая система разработанная Silicon Graphics, но сейчас выпущенная открытым кодом (open source). Официальная информация на http://oss.sgi.com/projects/xfs/ XFS была создана в начале 90ых (1992-1993) фирмой Silicon Grapgics (сейчас SGI) для мультимедийных компьютеров с ОС Irix. Файловая система была ориентирована на очень большие файлы и файловые системы. Особенностью этой файловой системы является устройство журнала - в журнал пишется часть метаданных самой файловой системы таким образом, что весь процесс восстановления сводится к копированию этих данных из журнала в файловую систему. Размер журнала зад
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 423; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.140.185.250 (0.012 с.) |