Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
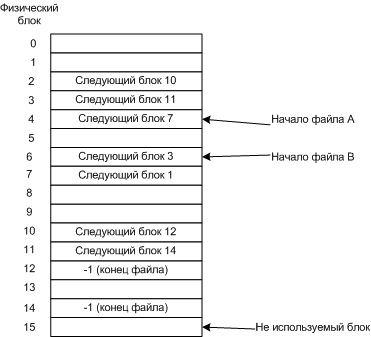
Размещение файла в виде связного списка блоков дискаСодержание книги
Поиск на нашем сайте Номер следующего блока хранится в текущем блоке. Преимущества: · Нет потерь дискового пространства на фрагментацию · Нужно хранить информацию только о первом блоке Недостатки: · Уменьшение быстродействия - для того чтобы получить информацию о всех блоках надо перебрать все блоки. · Уменьшается размер блока из-за хранения служебной информации Связные списки при помощи таблиц в памяти Чтобы избежать два предыдущих недостатка, стали хранить всю информацию о блоках в специальной таблице загружаемой в память. FAT (File Allocation Table) - таблица размещения файлов загружаемая в память. Рассмотри предыдущий пример, но в виде таблицы.
Таблица размещения файлов Здесь тоже надо собирать блоки по указателям, но работает быстрее, т.к. таблица загружена в память. Основной не достаток этого метода - всю таблицу надо хранить в памяти. Например, для 20 Гбайт диска, с блоком 1Кбайт (20 млн. блоков), потребовалась бы таблица в 80 Мбайт (при записи в таблице в 4 байта). Такие таблицы используются в MS-DOS и Windows. I - узлы С каждым файлом связывается структура данных, называемая i-узлом (index-node- индекс узел), содержащие атрибуты файла и адреса всех блоков файла.
Примеры i-узла Преимущества: · Быстродействие - имея i-узел можно получить информацию о всех блоках файла, не надо собирать указатели. · Меньший объем, занимаемый в памяти. В память нужно загружать только те узлы, файлы которых используются. Если каждому файлу выделять фиксированное количество адресов на диске, то со временем этого может не хватить, поэтому последняя запись в узле является указателем на дополнительный блок адресов и т.д. Такие узлы используются в UNIX. Реализация каталогов При открытии файла используется имя пути, чтобы найти запись в каталоге. Запись в каталоге указывает на адреса блоков диска. В зависимости от системы это может быть: · дисковый адрес всего файла (для непрерывных файлов) · номер первого блока (связные списки) · номер i-узла Одна из основных задач каталоговой системы преобразование ASCII-имени в информацию, необходимую для нахождения данных. Также она хранит атрибуты файлов. Варианты хранения атрибутов: · В каталоговой записи (MS-DOS) · В i-узлах (UNIX)
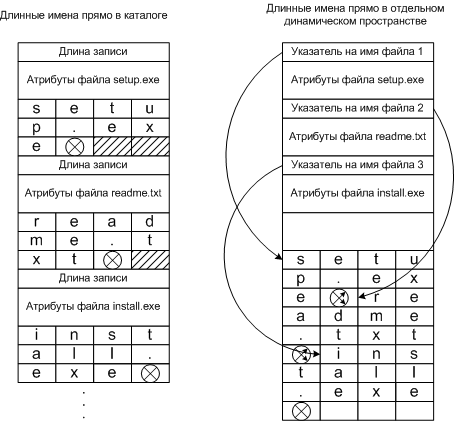
Варианты реализации каталогов Реализация длинных имен файлов Раньше операционные системы использовали короткие имена файлов, MS-DOS до 8 символов, в UNIX Version 7 до 14 символов. Теперь используются более длинные имена файлов (до 255 символов и больше). Методы реализации длинных имен файлов: · Просто выделить место под длинные имена, увеличив записи каталога. Но это займет много места, большинство имен все же меньше 255. · Применить записи с фиксированной частью (атрибуты) и динамической записью (имя файла). Второй метод можно реализовать двумя методами: · Имена записываются сразу после заголовка (длина записи и атрибутов) · Имена записываются в конце каталога после всех заголовков (указателя на файл и атрибутов)
Реализация длинных имен файлов Ускорение поиска файлов Если каталог очень большой (несколько тысяч файлов), последовательное чтение каталога мало эффективно. 1 Использование хэш-таблицы для ускорения поиска файла. Алгоритм записи файла: · Создается хэш-таблица в начале каталога, с размером n (n записей). · Для каждого имени файла применяется хэш-функция, такая, чтобы при хэшировании получалось число от 0 до n-1. · Исследуется элемент таблицы соответствующий хэш-коду. · Если элемент не используется, туда помещается указатель на описатель файла (описатели размещены вслед за хэш-таблицей). · Если используется, то создается связный список, объединяющие все описатели файлов с одинаковым хэш-кодом. Алгоритм поиска файла: · Имя файла хэшируется · По хэш-коду определяется элемент таблицы · Затем проверяются все описатели файла из связного списка и сравниваются с искомым именем файла · Если имени файла в связном списке нет, это значит, что файла нет в каталоге. Такой метод очень сложен в реализации, поэтому используется в тех системах, в которых ожидается, что каталоги будут содержать тысячи файлов.
|
||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 529; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.33 (0.006 с.) |