
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Динамическая оптимизация с централизованной схемой обнаружения конфликтовСодержание книги
Поиск на нашем сайте
В конвейере с динамическим планированием выполнения команд все команды проходят через ступень выдачи строго в порядке, предписанном программой (упоря-доченная выдача). Однако они могут приостанавливаться и обходить друг друга на второй ступени (ступени чтения операндов) и тем самым поступать на ступени выполнения неупорядочено. Централизованная схема обнаружения конфликтов представляет собой метод, допускающий неупорядоченное выполнение команд при наличии достаточных ресурсов и отсутствии зависимостей по данным. Впервые подобная схема была применена в компьютере CDC 6600. Прежде чем начать обсуждение возможности применения подобных схем, важно заметить, что конфликты типа WAR, отсутствующие в простых конвейерах, могут появиться при неупорядоченном выполнении команд. В ранее приведенном примере регистром результата для команды SUBD является регистр R8, который одновременно является источником операнда для команды ADDD. Поэтому здесь между командами ADDD и SUBD имеет место антизависимость: если конвейер выполнит команду SUBD раньше команды ADDD, он нарушит эту антизависимость. Этот конфликт WAR можно обойти, если выполнить два правила: (1) читать регистры только во время стадии чтения операндов и (2) поставить в очередь операцию ADDD вместе с копией ее операндов. Чтобы избежать нарушений зависимостей по выходу конфликты типа WAW (например, это могло произойти, если бы регистром результата команды SUBD была бы регистр F10) все еще должны обнаруживаться. Конфликты типа WAW могут быть устранены с помощью приостановки выдачи команды, регистр результата которой совпадает с уже используемым в конвейере. Задачей централизованной схемы обнаружения конфликтов является поддержание выполнения команд со скоростью одна команда за такт (при отсутствии структурных конфликтов) посредством как можно более раннего начала выполнения команд. Таким образом, когда команда в начале очереди приостанавливается, другие команды могут выдаваться и выполняться, если они не зависят от уже выполняющейся или приостановленной команды. Централизованная схема несет полную ответственность за выдачу и выполнение команд, включая обнаружение конфликтов. Подобное неупорядоченное выполнение команд требует одновременного нахождения нескольких команд на стадии выполнения. Этого можно достигнуть двумя способами: реализацией в процессоре либо множества неконвейерных функциональных устройств, либо путем конвейеризации всех функциональных устройств. Обе эти возможности по сути эквивалентны с точки зрения организации управления. Поэтому предположим, что в машине имеется несколько неконвейерных функциональных устройств. Машина CDC 6600 имела 16 отдельных функциональных устройств (4 устройства для операций с плавающей точкой, 5 устройств для организации обращений к основной памяти и 7 устройств для целочисленных операций). В нашем случае централизованная схема обнаружения конфликтов имеет смысл только для устройства плавающей точки. Предположим, что имеются два умножителя, один сложитель, одно устройство деления и одно целочисленное устройство для всех операций обращения к памяти, переходов и целочисленных операций. Хотя устройств в этом примере гораздо меньше, чем в CDC 6600, он достаточно мощный для демонстрации основных принципов работы. Поскольку как наша машина, так и CDC 6600 являются машинами с операциями регистр-регистр (операциями загрузки/записи), в обеих машинах методика практически одинаковая. На рис.43 показана подобная машина. Каждая команда проходит через централизованную схему обнаружения конфликтов, которая определяет зависимости по данным; этот шаг соответствует стадии выдачи команд и заменяет часть стадии ID в нашем конвейере. Эти зависимости определяют затем моменты времени, когда команда может читать свои операнды и начинать выполнение операции. Если централизованная схема решает, что команда не может немедленно выполняться, она следит за всеми изменениями в аппаратуре и решает, когда команда сможет выполняться. Эта же централизованная схема определяет также когда команда может записать результат в свой регистр результата. Таким образом, все схемы обнаружения и разрешения конфликтов здесь выполняются устройством центрального управления. Каждая команда проходит четыре стадии своего выполнения. (Поскольку в данный момент мы интересуемся операциями плавающей точки, мы не рассматриваем стадию обращения к памяти). Рассмотрим эти стадии сначала неформально, а затем детально рассмотрим как централизованная схема поддерживает необходимую информацию, которая определяет обработку при переходе с одной стадии на другую.
Рис 43 – Централизованная схема управления
Следующие четыре стадии заменяют стадии ID, EX и WB в стандартном конвейере: 1) Выдача. Если функциональное устройство, необходимое для выполнения команды, свободно и никакая другая выполняющаяся команда не использует тот же самый регистр результата, централизованная схема выдает команду в функциональное устройство и обновляет свою внутреннюю структуру данных. Поскольку никакое другое работающее функциональное устройство не может записать результат в регистр результата нашей команды, мы гарантируем, что конфликты типа WAW не могут появляться. Если существует структурный конфликт или конфликт типа WAW, выдача команды блокируется и никакие следующие команды не будут выдаваться на выполнение до тех пор, пока эти конфликты существуют. Эта стадия заменяет часть стадии ID в нашем конвейере. 2) Чтение операндов. Централизованная схема следит за возможностью выборки источников операндов для соответствующей команды. Операнд-источник доступен, если отсутствует выполняющаяся команда, которая записывает результат в этот регистр или если в данный момент времени в регистр, содержащий операнд, выполняется запись из работающего функционального устройства. Если операнды-источники доступны, централизованная схема сообщает функциональному устройству о необходимости чтения операндов из регистров и начале выполнения операции. Централизованная схема разрешает конфликты RAW на этой стадии динамически и команды могут посылаться для выполнения не в порядке, предписанном программой. Эта стадия, совместно со стадией выдачи, завершает работу стадии ID простого конвейера. 3) Выполнение. Функциональное устройство начинает выполнение операции после получения операндов. Когда результат готов оно уведомляет централизованную схему управления о том, что оно завершило выполнение операции. Эта стадия заменяет стадию EX и занимает несколько тактов в рассмотренном ранее конвейере. 4) Запись результата. Когда централизованная схема управления узнает о том, что функциональное устройство завершило выполнение операции, она проверяет существование конфликта типа WAR. Если этот конфликт типа WAR не существует, централизованная схема управления сообщает функциональному устройству о необходимости записи результата в регистр назначения. Эта стадия заменяет стадию WB в простом конвейере. Основываясь на своей собственной структуре данных, централизованная схема управления управляет продвижением команды с одной ступени на другую взаимодействуя с функциональными устройствами. Но имеется небольшое усложнение: в регистровом файле имеется только ограниченное число магистралей для операндов-источников и магистралей для записи результата. Централизованная схема управления должна гарантировать, что количество функциональных устройств, которым разрешено продолжать работу на ступенях 2 и 4 не превышает числа доступных шин. Не будем вдаваться в дальнейшие подробности и упомянем лишь, что CDC 6600 решала эту проблему путем объединения 16 функциональных устройств друг с другом в четыре группы и поддержки для каждой группы устройств набора шин, называемых магистралями данных (data trunks). Только одно устройство в группе могло читать операнды или записывать свой результат в течение одного такта. Общая структура регистров состояния устройства централизованного управления состоит из 3-х частей: 1) Состояние команды - показывает каждый из четырех этапов выполнения команды. 2) Состояние функциональных устройств - имеются 9 полей, описывающих состояние каждого функционального устройства: a. Занятость - показывает, занято устройство или свободно; b. Op - выполняемая в устройстве операция; c. Fi - регистр результата; d. Fj, Fk - регистры-источники операндов; e. Qj, Qk - функциональные устройства, вырабатывающие результат для записи в регистры; f. Rj, Rk - признаки готовности операндов в регистрах Fj, Fk 3) Состояние регистров результата - показывает функциональное устройство, которое будет записывать в каждый из регистров. Это поле устанавливается в ноль, если отсутствуют команды, записывающие результат в данный регистр. Другой подход к динамическому планированию - алгоритм Томасуло Другой подход к параллельному выполнению команд при наличии конфликтов был использован в устройстве плавающей точки в машине IBM 360/91. Эта схема приписывается Р. Томасуло и названа его именем. Разработка IBM 360/91 была завершена спустя три года после выпуска CDC 6600, прежде чем кэш-память появилась в коммерческих машинах. Задачей IBM было достижение высокой производительности на операциях с плавающей точкой, используя набор команд и компиляторы, разработанные для всего семейства 360, а не только для приложений с интенсивным использованием плавающей точки. Архитектура 360 предусматривала только четыре регистра плавающей точки двойной точности, что ограничивало эффективность планирования кода компилятором. Этот факт был другой мотивацией подхода Томасуло. Наконец, машина IBM 360/91 имела большое время обращения к памяти и большие задержки выполнения операций плавающей точки, преодолеть которые и был призван разработанный Томасуло алгоритм. В конце раздела мы увидим, что алгоритм Томасуло может также поддерживать совмещенное выполнение нескольких итераций цикла. Мы поясним этот алгоритма на примере устройства ПТ. Основное различие между нашим конвейером ПТ и конвейером машины IBM/360 заключается в наличии в последней машине команд типа регистр-память. Поскольку алгоритм Томасуло использует функциональное устройство загрузки, не требуется значительных изменений, чтобы добавить режимы адресации регистр-память; основное добавление - другая шина. IBM 360/91 имела также конвейерные функциональные устройства, а не несколько функциональных устройств. Единственное отличие между ними заключается в том, что конвейерное функциональное устройство может начинать выполнение только одной операции в каждом такте. Поскольку реально отсутствуют фундаментальные отличия, мы описываем алгоритм, как если бы имели место несколько функциональных устройств. IBM 360/91 могла выполнять одновременно три операции сложения ПТ и две операции умножения ПТ. Кроме того, в процессе выполнения могли находиться до 6 операций загрузки ПТ, или обращений к памяти, и до трех операций записи ПТ. Для реализации этих функций использовались буфера данных загрузки и буфера данных записи. Хотя мы не будем обсуждать устройства загрузки и записи, необходимо добавить буфера для операндов. Схема Томасуло имеет много общего со схемой централизованного управления CDC 6600, однако имеются и существенные отличия. Во-первых, обнаружение конфликтов и управление выполнением являются распределенными - станции резервирования (reservation stations) в каждом функциональном устройстве определяют, когда команда может начать выполняться в данном функциональном устройстве. В CDC 6600 эта функция централизована. Во-вторых, результаты операций посылаются прямо в функциональные устройства, а не проходят через регистры. В IBM 360/91 имеется общая шина результатов операций (которая называется общей шиной данных (common data bus - CDB)), которая позволяет производить одновременную загрузку всех устройств, ожидающих операнда. CDC 6600 записывает результаты в регистры, за которые ожидающие функциональные устройства могут соперничать. Кроме того, CDC 6600 имеет несколько шин завершения операций (две в устройстве ПТ), а IBM 360/91 - только одну. На рис. 44 представлена основная структура устройства ПТ на базе алгоритма Томасуло. Станции резервирования хранят команды, которые выданы и ожидают выполнения в соответствующем функциональном устройстве, а также информацию, требующуюся для управления командой, когда ее выполнение началось в функциональном устройстве. Буфера загрузки и записи хранят данные поступающие из памяти и записываемые в память. Регистры ПТ соединены с функциональными устройствами парой шин и одной шиной с буферами записи. Все результаты из функциональных устройств и из памяти посылаются на общую шину данных, которая связана со входами всех устройств за исключением буфера загрузки. Все буфера и станции резервирования имеют поля тегов, используемых для управления конфликтами. Прежде чем описывать детали станций резервирования и алгоритм, рассмотрим все стадии выполнения команды. В отличие от централизованной схемы управления, имеется всего три стадии: 1) Выдача - Берет команду из очереди команд ПТ. Если операция является операцией ПТ, выдает ее при наличии свободной станции резервирования и посылает операнды на станцию резервирования, если они находятся в регистрах. Если операция является операцией загрузки или записи, она может выдаваться при наличии свободного буфера. При отсутствии свободной станции резервирования или свободного буфера возникает структурный конфликт и команда приостанавливается до тех пор, пока не освободится станция резервирования или буфер. 2) Выполнение - Если один или более операндов команды не доступны по каким либо причинам, контролируется состояние CDB и ожидается завершение вычисления значений нужного регистра. На этой стадии выполняется контроль конфликтов типа RAW. Когда оба операнда доступны, выполняется операция. 3) Запись результата - Когда становится доступным результат, он записывается на CDB и оттуда в регистры и любое функциональное устройство, ожидающее этот результат. Хотя эти шаги в основном похожи на аналогичные шаги в централизованной схеме управления, имеются три важных отличия. Во-первых, отсутствует контроль конфликтов типа WAW и WAR - они устраняются как побочный эффект алгоритма. Во-вторых, для трансляции результатов используется CDB, а не схема ожидания готовности регистров. В-третьих, устройства загрузки и записи рассматриваются как основные функциональные устройства. Структуры данных, используемые для обнаружения и устранения конфликтов, связаны со станциями резервирования, регистровым файлом и буферами загрузки и записи. Хотя с разными объектами связана разная информация, все устройства, за исключением буферов загрузки, содержат в каждой строке поле тега. Это поле тега представляет собой четырехбитовое значение, которое обозначает одну из пяти станций резервирования или один из шести буферов загрузки. Поле тега используется для описания того, какое функциональное устройства будет поставлять результат, нужный в качестве источника операнда. Неиспользуемые значения, такие как ноль, показывают что операнд уже доступен. Важно помнить, что теги в схеме Томасуло ссылаются на буфера или устройства, которые будут поставлять результат; когда команда выдается в станцию резервирования номера регистров исключаются из рассмотрения.
Каждая станция резервирования содержит шесть полей: 1) Op - Операция, которая должна выполняться над источниками операндов S1 и S2; 2) Qj,Qk - станции резервирования, которые будут вырабатывать соответствующий операнд-источник; нулевое значение показывает, что операнд-источник уже доступен в Vj или Vk, или не является обязательным. 3) Vj,Vk - значение операндов-источников. Заметим, что для каждого операнда являются действительными только одно из полей либо поле V, либо поле Q. 4) Занято - Показывает, что данная станция резервирования и ее соответствующее функциональное устройство заняты. Регистровый файл и буфер записи имеют поле Qi, где Qi - номер функционального устройства, которое будет вырабатывать значение, которое надо записать в регистр или память. Если значение Qi равно нулю, то это означает, что ни одна текущая активная команда не вычисляет результат для данного регистра или буфера. Для регистра это означает, что значение определяется содержимым регистра. В каждом из буферов загрузки и записи требуется поле занятости, показывающее когда соответствующий буфер становится доступным благодаря завершению загрузки или записи, назначенных на этот буфер. Буфер записи имеет также поле V для хранения значения, которое должно быть записано в память. Проанализируем работу алгоритма для следующей последовательности команд: 1. LF F6,34(R2) 2. LF F2,45(R3) 3. MULTD F0,F2,F4 4. SUBD F8,F6,F2 5. DIVD F10,F0,F6 6. ADDD F6,F8,F2 Имеются два важных отличия от централизованной схемы управления. Во-первых, значение операнда хранится в станции резервирования в одном из полей V как только оно становится доступным; оно не считывается из регистрового файла во время выдачи команды. Во-вторых, за счет первого отличия сокращается число структурных конфликтов по сравнению с централизованной схеме управления. Большие преимущества схемы Томасуло заключаются в распределении логики обнаружения конфликтов и устранении приостановок, связанных с конфликтами типа WAW и WAR. Первое преимущество возникает из-за наличия распределенных станций резервирования и использования CDB. Если несколько команд ожидают один и тот же результат и каждая команда уже имеет свой другой операнд, то команды могут выдаваться одновременно посредством трансляции по CDB. В централизованной схеме управления ожидающие команды должны читать свои операнды из регистров когда станут доступными регистровые шины. Конфликты типа WAW и WAR устраняются путем переименования регистров используя станции резервирования. Например, в нашей кодовой последовательности мы выдали на выполнение как команду DIVD, так и команду ADDD, даже хотя имелся конфликт типа WAR по регистру F6. Конфликт устраняется одним из двух способов. Если команда, поставляющая значение для команды DIVD, завершилась, тогда Vk будет хранить результат, позволяя DIVD выполняться независимо от команды ADDD. С другой стороны, если выполнение команды LF не завершилось, то Qk будет указывать на LOAD1 и команда DIVD будет независимой от ADDD. Таким образом, в любом случае команда ADDD может быть выдана и начать выполняться. Любое использование результата команды MULTD будет указывать на станцию резервирования, позволяя ADDD завершить и записать свое значение в регистры без воздействия DIVD. Чтобы понять полную мощность устранения конфликтов типа WAW и WAR посредством динамического переименования регистров мы должны рассмотреть цикл. Рассмотрим следующую простую последовательность команд для умножения элементов вектора на скалярную величину, находящуюся в регистре F2: Loop: LD F0,0(R1) MULTD F4,F0,F2 SD 0(R1),F4 SUBI R1,R1,#8 BNEZ R1,Loop; условный переход при R1 /=0 Со стратегией выполняемого перехода использование станций резервирования позволит сразу же продолжить выполнение нескольких итераций этого цикла. Это преимущество дается без статического разворачивания цикла программными средствами: в действительности цикл разворачивается динамически аппаратурой. В архитектуре 360 наличие всего 4 регистров ПТ сильно ограничивало бы использование статического разворачивания цикла. (Вскоре мы увидим, что при статическом разворачивании и планировании выполнения цикла для обхода взаимных блокировок требуется значительно большее число регистров). Алгоритм Томасуло поддерживает выполнение с перекрытием нескольких копий одного и того же цикла при наличии лишь небольшого числа регистров, используемых программой. Давайте предположим, что мы выдали для выполнения все команды двух последовательных итераций цикла, но еще не завершилось выполнение ни одной операции загрузки/записи в память. Проигнорируем операции целочисленного АЛУ и предположим, что условный переход был спрогнозирован как выполняемый. Когда система достигла такого состояния могут поддерживаться две копии цикла с CPI близким к единице при условии, что операции умножения могут завершиться за четыре такта. Если мы игнорируем накладные расходы цикла, которые не снижены в этой схеме, достигнутый уровень производительности будет соответствовать тому, который мы могли бы достигнуть посредством статического разворачивания и планирования цикла компилятором при условии наличия достаточного числа регистров. В этом примере демонстрируется дополнительный элемент, который является важным для того, чтобы алгоритм Томасуло работал. Команда загрузки из второй итерации цикла может легко закончиться раньше команды записи из первой итерации, хотя нормальный последовательный порядок отличается. Загрузка и запись могут надежно (безопасно) выполняться в различном порядке при условии, что загрузка и запись обращаются к разным адресам. Это контролируется путем проверки адресов в буфере записи каждый раз при выдаче команды загрузки. Если адрес команды загрузки соответствует одному из адресов в буфере записи мы должны остановиться и подождать до тех пор, пока буфер записи не получит требуемое значение; затем мы можем к нему обращаться или выбирать значение из памяти. Это динамическое сравнение адресов является альтернативой технике, которая может использоваться компилятором при перестановке команд загрузки и записи. Динамическая схема Томасуло может достигать очень высокой производительности при условии того, что стоимость переходов может поддерживаться небольшой. Главный недостаток этого подхода заключается в сложности схемы Томасуло, которая требует для своей реализации очень большого объема аппаратуры. Особенно это касается большого числа устройств ассоциативной памяти, которая должна работать с высокой скоростью, а также сложной логики управления. Наконец, увеличение производительности ограничивается наличием одной шины завершения (CDB). Хотя дополнительные шины CDB могут быть добавлены, каждая CDB должна взаимодействовать со всей аппаратурой конвейера, включая станции резервирования. В частности, аппаратуру ассоциативного сравнения необходимо дублировать на каждой станции для каждой CDB. В схеме Томасуло комбинируются две различных методики: методика переименования регистров и буферизация операндов-источников из регистрового файла. Буферизация источников операндов разрешает конфликты типа WAR, которые возникают когда операнды доступны в регистрах. Как мы увидим позже, возможно также устранять конфликты типа WAR посредством переименования регистра вместе с буферизацией результата до тех пор, пока остаются обращения к старой версии регистра; этот подход будет использоваться, когда мы будем обсуждать аппаратное выполнение по предположению. Схема Томасуло является привлекательной, если разработчик вынужден делать конвейерную архитектуру, для которой трудно выполнить планирование кода или реализовать большое хранилище регистров. С другой стороны, преимущество подхода Томасуло возможно ощущается меньше, чем увеличение стоимости реализации, по сравнению с методами планирования загрузки конвейера средствами компилятора в машинах, ориентированных на выдачу для выполнения только одной команды в такте. Однако по мере того, как машины становятся все более агрессивными в своих возможностях выдачи команд и разработчики сталкиваются с вопросами производительности кода, который трудно планировать (большинство кодов для нечисловых расчетов), методика типа переименования регистров и динамического планирования будет становиться все более важной. Также эти методы являются одним из важных компонентов большинства схем для реализации аппаратного выполнения по предположению. Ключевыми компонентами увеличения параллелизма уровня команд в алгоритме Томасуло являются динамическое планирование, переименование регистров и динамическое устранение неоднозначности обращений к памяти. Трудно оценить значение каждого из этих свойств по отдельности. Динамической аппаратной технике планирования загрузки конвейера при наличии зависимостей по данным соответствует и динамическая техника для эффективной обработки переходов. Эта техника используется для двух целей: для прогнозирования того, будет ли переход выполняемым, и для возможно более раннего нахождения целевой команды перехода. Эта техника называется аппаратным прогнозированием переходов.
|
||||
|
|
Последнее изменение этой страницы: 2016-08-12; просмотров: 614; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.3 (0.071 с.) |

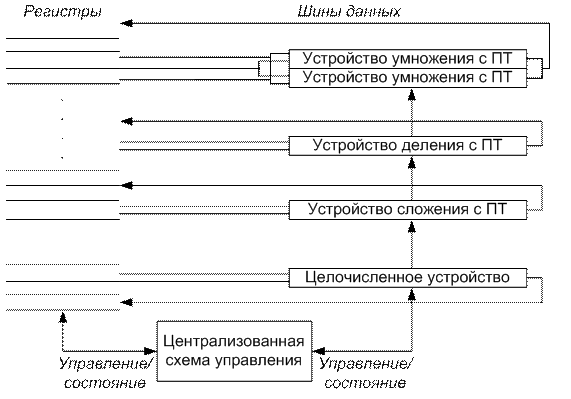
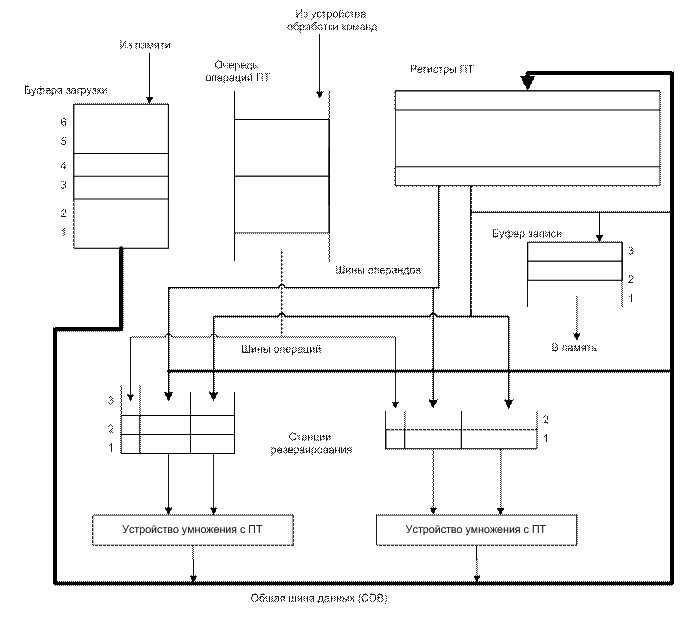 Рис. 44 – Структура устройства вычислений с ПТ на основе алгоритма Томасуло
Рис. 44 – Структура устройства вычислений с ПТ на основе алгоритма Томасуло


