Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сучасні субд й їх використання для рішення завдань автоматизації зберігання та обробки інформації торгівельного підприемства.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
СУЧАСНІ СУБД Й ЇХ ВИКОРИСТАННЯ ДЛЯ РІШЕННЯ ЗАВДАНЬ АВТОМАТИЗАЦІЇ ЗБЕРІГАННЯ ТА ОБРОБКИ ІНФОРМАЦІЇ ТОРГІВЕЛЬНОГО ПІДПРИЕМСТВА.
Сучасні тенденції в області проектування й розробки баз даних. Відомі два підходи до організації інформаційних масивів: файлова організація та організація у вигляді бази даних. Файлова організація передбачає спеціалізацію та збереження інформації, орієнтованої, як правило, на одну прикладну задачу, та забезпечується прикладним програмістом. Така організація дозволяє досягнути високої швидкості обробки інформації, але характеризується рядом недоліків. Характерна риса файлового підходу - вузька спеціалізація як обробних програм, так і файлів даних, що служить причиною великої надлишковості, тому що ті самі елементи даних зберігаються в різних системах. Оскільки керування здійснюється різними особами (групами осіб), відсутня можливість виявити порушення суперечливості збереженої інформації. Розроблені файли для спеціалізованих прикладних програм не можна використовувати для задоволення запитів користувачів, які перекривають дві і більше області. Крім того, файлова організація даних внаслідок відмінностей структури записів і форматів передання даних не забезпечує виконання багатьох інформаційних запитів навіть у тих випадках, коли всі необхідні елементи даних містяться в наявних файлах. Тому виникає необхідність відокремити дані від їхнього опису, визначити таку організацію збереження даних з обліком існуючих зв'язків між ними, яка б дозволила використовувати ці дані одночасно для багатьох застосувань. Вказані причини обумовили появу баз даних. База даних може бути визначена як структурна сукупність даних, що підтримуються в активному стані та відображає властивості об'єктів зовнішнього (реального) світу. В базі даних містяться не тільки дані, але й описи даних, і тому інформація про форму зберігання вже не схована в сполученні "файл-програма", вона явним чином декларується в базі. База даних орієнтована на інтегровані запити, а не на одну програму, як у випадку файлового підходу, і використовується для інформаційних потреб багатьох користувачів. В зв'язку з цим бази даних дозволяють в значній мірі скоротити надлишковість інформації. Перехід від структури БД до потрібної структури в програмі користувача відбувається автоматично за допомогою систем управління базами даних (СУБД). Призначення та класифікація систем управління базами даних (СУБД)
СУБД - це складна програмна система накопичення та з наступним маніпулюванням даними, що представляють інтерес для користувача. Кожній прикладній програмі СУБД надає інтерфейс з базою даних та має засоби безпосереднього доступу до неї. Таким чином, СУБД відіграє центральну роль в функціонуванні автоматизованого банку даних. Архітектурно СУБД складається з двох великих компонент (рис.2.1). За допомогою мови опису даних (МОД) створюються описи елементів, груп та записів даних, а також взаємозв'язки між ними, які, як правило, задаються у вигляді таблиць. В залежності від конкретної реалізації СУБД мову опису даних підрозділяють на мову опису схеми бази даних (МОС) та мову опису підсхем бази даних (МОП). Слід особливо зазначити, що МОД дозволяє створити не саму базу даних, а лише її опис.
Рисунок 1.1 - Архітектура СУБД Для виконання операцій з базою даних в прикладних програмах використовується мова маніпулювання даними (ММД). Фактична структура фізичного зберігання даних відома тільки СУБД. З метою забезпечення зв'язків між програмами користувачів і СУБД (що особливо важливо при мультипрограмному режимі роботи операційної системи) в СУБД виділяють особливу складову - резидентний модуль системи керування базами даних. Цей модуль значно менший від всієї СУБД, тому на час функціонування автоматизованого банку інформації він може постійно знаходитись в основній пам'яті ЕОМ та забезпечувати взаємодію всіх складових СУБД і програм, які до неї звертаються. Приведена структура притаманна усім СУБД, котрі розрізняються обмеженнями та можливостями по виконанню відповідних функцій. Отже, процес порівняння і оцінки таких систем для одного конкретного застосування зводиться до співставлення можливостей наявних СУБД з вимогами користувачів. До недавнього часу при організації обробки інформації на ЕОМ застосовувався підхід, при якому на основі інформації одного і того ж об'єкту управління (наприклад, матеріальних ресурсів) в залежності від її вигляду (нормативна. розцінкова тощо) і ступеню постійності формувались масиви лінійної структури двох типів: умовно-постійні (з інформацією, яка використовувалась багато разів протягом довгого часу) і умовно-перемінні (з фактичною або поточною інформацією). Створення і багаторазове використання масивів з умовно-постійною інформацією має ті переваги, які дозволяють значно спростити первинну документацію шляхом виведення з її складу ряд постійних реквізитів. знизити трудомісткість робіт на стадії заповнення первинних документів, підготовки і вроду фактичної або поточної інформації до ЕОМ. Недоліком таких масивів, які мають лінійну структуру, є то що інформація одного і того я об'єкту управління розосереджується поміж багатьох різних масивів (нормативних, планових та ін.), що неминуче веде до дублювання деяких реквізитів, ускладненню при спільній їх обробці тощо, а головне - не дає змоги реалізувати принцип незалежності від прикладних програм користувача. Лінійні масиви, сформовані традиційним способом, ефективні, як правило, а позиції одного застосування. 3 розвитком інформаційного забезпечення систем автоматизованої обробки інформації, прагненням забезпечити виконання нових режимів обробки даних у реальному часі і з мультидоступом до схованих даних позначилась нова тенденція до складення інформаційного забезпечення розподілених баз даних. В умовах використання таких баз створюються комплексні масиви нелінійної структури, які мають усі дані про ту чи іншу предметну область або про керований об'єкт як постійного, так і перемінного характеру. Взагалі база даних є сукупність даних на машинних носіях, які використовуються при функціонуванні системи обробки інформації, організовані по визначеним правилам, які передбачають загальні принципи описування збереження і маніпулювання ними, а також які незалежні від прикладних програм. В основі організації бази даних є модель даних, яка визначає правила, у відповідності з якими структуруються дані. За допомогою моделі представляється велика кількість даних і описуються взаємно зв’язки між ними. Найбільш поширені такі моделі даних: ієрархічна, сітьова, реляційна. В ієрархічній моделі зв'язок даних "один до одного" (1:1) означає, що кожному значенню (екземпляру) елемента даних А відповідає одне і тільки одне значення, пов'язаного з ним елемента В. Наприклад, поміж такими елементами пар даних, як код готової продукції і її найменуванням є вищезазначений зв'язок, так як тільки кожному коду продукції відповідає одне її найменування. Зазначимо, що ієрархічна модель даних будується на основі принципу підпорядкованості поміж елементами даних і представляє собою деревоподібну структуру, яка складається із вузлів (сегментів) і дуг (гілок). Дерево у ієрархічній структурі упорядковане за існуючими правилами розташування його сегментів і гілок: на верхньому рівні знаходиться один, кореневий (вихідний) сегмент, сегмент другого рівня, породжений, залежить від першого, вихідного; доступ до кожного породженого (крім кореневого) здійснюється через його вихідний сегмент; кожний сегмент може мати по декілька екземплярів конкретних значень елементів даних, а кожний елемент породженого сегменту пов’язаний з екземпляром вихідного і створює один логічний запис; екземпляр породженого сегменту не може існувати самостійно, тобто без кореневого сегменту; при вилученні екземпляру кореневого сегмента також вилучаються усі підпорядковані і взаємопов'язані з ним екземпляри породжених сегментів. В сітьовій моделі зв'язок "один до багатьох" (1:В) означає, що значенню елемента А відповідають багато (більше одного) значень, пов'язанню з ним елементів В. Наприклад, поміж елементами даних "код виробу" (елемент А) і "кодом матеріалів" (елементи В) існує такий взаємозв'язок бо на виготовлення одного виробу використовується багато різних матеріалів. Сітьова модель даних представляє собою орієнтований граф з пойменованими вершинами і дугами. Вершини графа - записи, які представляють собою по іменовану сукупність логічних взаємозв'язаних елементів даних або агрегатів даних. Під агрегатом даних розуміють пошановану сукупність елементів даних, які є усередині запису. Для кожного типу записів може бути кілька екземплярів конкретних значень його інформаційних елементів Два записи, взаємозв'язані дугою, створюють набір даних. Запис, з якого виходить дуга, називається власником набору, а запис, до якого вона направлена, - членом набору. В реляційній моделі зв'язок "багатьох до багатьох" (В:В) указує на те, що декільком значенням елементів даних А відповідає декілька значені елементів даних В. Наприклад, поміж елементами даних "код операції технологічного процесу" і "табельний номер працівника" існує зазначені взаємозв'язок, так як багато операцій технологічного процесу можуть виконувати різні працівники (табельні номери) і навпаки. Реляційна модель даних являє собою набір двомірних плоских таблиць, що складаються з рядків і стовпців. Первинний документ або лінійний масив являє собою плоску двомірну таблицю. Така таблиця називається відношенням, кожний стовбець-атрибутом, сукупність значень одного типу (стовпця) –доменом, а рядка – кортежем. Таким чином, стовпці таблиці являються традиційними елементами даних, а рядки – записами. Таблиці (відношення) мають імена. Імена також присвоюються і стовпцям таблиці. Кожний кортеж (запис) відношення має ключ. Ключі є прості і складні. Простий ключ-це ключ, який складається з одного атомарного атрибуту, значення якого унікальне (яке не повторюються).Складний ключ складається з двох і більше атрибутів. Для зв’язків відношень друг з другом в базі даних є зовнішні ключі. Атрибут або комбінація атрибута відношення є зовнішнім ключем, якщо він не є основним (первинним) ключем цього відношення, але являється первинним ключем для другого відношення. Різновидністю баз даних, з точки зору їх зберігання і використання, є розподіленні бази даних. Ці бази даних широко використовуються при організації комплексів взаємопов’язаних АРМ фахівців, на яких застосовуються ПЕОМ. Розподілена база даних - це сукупність логічно зв’язаних баз даних або частин однієї бази, які розпаралелені поміж декількома територіально – розподіленими ПЕОМ і забезпечені відповідними можливостями для управління цими базами або їх частинами. Тобто, розподілена база даних реалізується на різних просторово розосереджених обчислювальних засобах, разом з організаційними, технічними і програмними засобами її створення і ведення. Бази даних, системи управління БД: основні поняття Одним з основних факторів впливу НТП на всі сфери діяльності людини є широке використання нових інформаційних технологій, під якими розуміють сукупність методів і засобів одержання та використання інформації на базі обчислювальної і комунікаційної техніки та широкого впровадження математичних методів. У зв’язку з використанням нових інформаційних технологій поширилося поняття „інформаційна система”. Інформаційна система (ІC) являє собою комунікаційну систему із збирання, передавання й обробки інформації про конкретний об’єкт для реалізації функцій управління. Банк даних є різновидністю ІC, у якій реалізовано функції централізованого збереження та накопичення інформації, що обробляється; організована ця інформація в одну або декілька баз даних. Банк даних складається з таких компонентів: Бази даних (БД) – сукупність спеціальним чином організованих даних, які зберігаються на машинних носіях і відображають стан об’єктів та їх взаємозв’язки в предметній галузі, яка розглядається. Система управління базою даних (СУБД) – сукупність мовних і програмних засобів, призначених для створення, ведення та використання бази даних багатьма користувачами; вона є універсальною, загального призначення, найбільш поширена й ефективна. Адміністратор бази даних є особа або група осіб, відповідальних за розробку вимог до БД, її проектування, створення, ефективне використання та супроводження. Обчислювальна система – це сукупність взаємозв’язаних і узгоджено діючих комп’ютерів або процесорів та інших пристроїв, які забезпечують автоматизацію процесів приймання, обробки та видачі інформації споживачеві. Обслуговуючий персонал виконує функції підтримки технічних і програмних засобів у робочому стані. Для класифікації СУБД можна використовувати такі основні ознаки: вид програми, характер використання, модель даних. За характером використання СУБД поділяються на персональні і багатокористувацькі. Персональні СУБД забезпечують можливість створення персональних БД і додатків, що працюють з ними. Персональні СУБД і додатки найчастіше виступають у ролі клієнтської частини багатокористувацької СУБД. До персональних СУБД належать Visual FoxPro, Paradox, Access тощо. Багатокористувацькі СУБД містять у собі сервер БД і клієнтську частину і, як правило, можуть працювати в неоднорідному обчислювальному середовищі. Моделі даних
При створенні бази даних важливу роль відіграє інформаційне забезпечення, основною функцією якого є надійне зберігання на машинних носіях усієї сукупності необхідних даних для розв’язання задач користувача та зручний доступ до цих даних. Рішення щодо складу й організації необхідної інформації приймається у зовнішній та внутрішній сфері. Це обумовлено тим, що первинна інформація зароджується у зовнішній сфері у процесі прийняття рішень управлінським персоналом, опису об’єктів, процесів та явищ предметної галузі, для якої створюється база даних. Як правило, первинна інформація фіксується в документах зовнішньої сфери, які містять як нормативно-довідкову інформацію, так і оперативну, облікову інформацію, яка відображає відомості про поточні процеси. Для створення бази даних дані зовнішньої сфери повинні бути перенесені на машинний носій, де вони утворюють внутрішню базу даних. Організація даних у внутрішній сфері характеризується двома рівнями – логічним і фізичним. Фізична організація даних визначає спосіб розміщення даних безпосередньо на машинному носії. Логічна організація даних на машинному носії залежить від програмних засобів, організації даних і ведення даних у внутрішній сфері. Метод логічної організації даних визначається використовуваним типом структур даних і видом моделі, яка підтримується програмними засобами. Модель даних – це сукупність взаємозв’язаних структур даних і операцій над цими структурами. Для розміщення однієї і тієї ж інформації у внутрішній сфері можуть бути використані різні структури та моделі даних. Це залежить від користувача, від технічного та програмного забезпечення, визначається складністю автоматизованих задач і обсягом інформації. Існують такі моделі даних: ієрархічна, реляційна, постреляційна, багатомірна, об’єктно орієнтована. Ієрархічні та мережні моделі. Перша ІC, яка використала базу даних, з’явилася в середині 60-х років і ґрунтувалася на ієрархічній моделі, яка означає, що відносини між даними мають ієрархічну структуру. До кожного клієнта може відноситися декілька рахунків, а кожний рахунок може складатися з декількох рядків. Ієрархічна модель – це модель даних, у якій зв’язки між даними мають вигляд ієрархій. Клієнту „підпорядковані” рахунки, яким у свою чергу „підпорядковані” рядки рахунків. В ієрархічній базі даних ці три файли будуть пов’язані між собою фізичними покажчиками або полями даних, доданих до окремих записів. Мережна модель – це такі відносини між даними, коли кожний запис може бути підпорядкований записам більш ніж з одного файла. У зв’язку з необхідністю обробляти такі відносини в кінці 60-х років XX століття з’явилися мережні системи управління базами даних. Як і в ієрархічних, у мережних схемах баз даних для зв’язування файлів використовуються фізичні покажчики. Реляційна модель. У 1970 р. Е.Ф.Кодд опублікував революційну за змістом статтю, яка серйозно похитнула стале уявлення про бази даних. Йому належить ідея про те, що дані слід зв’язувати відповідно до їх внутрішніх логічних взаємовідносин, а не фізичних покажчиків. Завдяки цьому користувачі зможуть комбінувати дані з різних джерел, якщо логічна інформація, необхідна для такого комбінування, присутня в початкових даних. У своїй статті Кодд запропонував просту модель даних, згідно з якою всі дані зведено в таблиці, які складаються з рядків і стовпців. Ці таблиці одержали назву реляцій, а модель стала називатися реляційною. Логічний підхід до даних зробив також можливим створення мов запитів, більш доступних для користувачів, які не є спеціалістами з мов програмування. Розглядаючи дані з концептуальної, а не з фізичної точки зору, Кодд запропонував ще одну революційну ідею. У реляційних системах баз даних цілі файли даних можуть оброблятися однією командою, тоді як у традиційних системах за один раз обробляється тільки один запис. Підхід Кодда надзвичайно підвищив ефективність програмування в базах даних. Публікації Кодда викликали вибух активності як серед учених, так і серед розробників комерційних систем із створення реляційних СУБД. Результатом цієї діяльності стала поява в другій половині 70-х років реляційних систем, які підтримують такі мови як SQL – мова структурованих запитів. Реляційні СУБД продовжують удосконалювати-ся і їх внутрішня природа значно змінюється, даючи користувачам можливість вирішувати все більш складні задачі. Постреляційна модель. Класична реляційна модель передбачає неподільність даних, які зберігаються в полях записів таблиць. Існує ряд випадків, коли це обмеження заважає ефективній реалізації програм. ІІостреляційна модель даних є розширеною реляційною моделлю, яка змінює обмеження неподільності даних у записах таблиць. Ця модель даних допускає багатозначні поля – поля, значення яких складаються з підзначень. Набір значень багатозначних полів вважається самостійною таблицею, вбудованою в основну таблицю. Перевагою постреляційної моделі є можливість подання сукупності реляційних таблиць однією постреляційною таблицею. Це забезпечує високу наочність інформації та підвищення ефективності її обробки. Недоліком постреляційної моделі є складність забезпечення цілісності та несуперечливості даних, які зберігаються. Багатомірна модель даних – така модель, яка забезпечує багатомірне логічне подання структури інформації при її опису і в операціях маніпулювання даними. Багатомірні системи дозволяють оперативно обробляти інформацію для проведення аналізу та прийняття рішення. Основною перевагою цієї моделі є зручність та ефективність аналітичної обробки даних, пов’язаних з часом, недоліком – громіздкість для простих задач звичайної оперативної обробки інформації. В об’єктно орієнтованої моделі взаємозв’язки між записами бази даних і функціями їх обробки встановлюються за допомогою механізмів, подібних до відповідних засобів в об’єктно орієнтованих мовах програмування. Логічна структура цієї моделі зовні схожа на структуру ієрархічної БД. Основна різниця між ними полягає в методах маніпулювання даними. Основною перевагою об’єктно орієнтованої моделі даних порівняно з реляційними є можливість відображення інформації про складні взаємозв’язки об’єктів. Недоліками є висока понятійна складність, незручність обробки даних і низька швидкість виконання запитів. Етапи розробки бази даних Метою розробки (поектування) бази даних є визначення її логічної структури, розробка проводиться на основі опису предметної галузі. Цей опис повинен мати сукупність документів з даними, необхідними для заповнення БД, та інші відомості про процеси, які характеризують предметну галузь. Розробка БД повинна починатися з вивчення складу даних, які підлягають зберіганню в базі даних для забезпечення виконання запитів користувачів. Далі слід проводити їх аналіз і структурування.
Розробка моделі реляційних баз даних грунтується на нормалізації предметної галузі, представленої в документах позамашинної сфери. Цей процес виконується на основі розробки інформаційно-логічної моделі даних предметної галузі.
Опис та аналіз складу даних. Спочатку визначається склад і структура предметної галузі, даних, які повинні знаходитися в базі даних і забезпечувати виконання необхідних запитів, а також звітів користувача. Основним джерелом інформації для розробки БД є матеріал обстеження інформаційної системи предметної галузі. Необхідно вивчити всю систему звітних показників, які повинні бути одержані при автоматизованій обробці. Виділення інформаційних об’єктів. Об’єкти – це все те, що користувач вважає важливим при моделюванні предметної галузі. Інформаційні об’єкти визначаються рядом якісних і кількісних характеристик, представлених відповідними реквізитами. Тобто інформаційні об’єкти створюються сукупністю логічно взаємопов’язаних реквізитів, які характеризують деяку суть предметної галузі. Визначення логічних зв’язків і побудова інформаційно-логічної моделі. Інформаційно-логічна модель є моделлю даних, яка відображає предметну галузь у вигляді інформаційних об’єктів і структурних зв’язків між ними.
Визначення логічної структури реляційної бази даних. При створенні бази засобами СУБД з реляційною моделлю інформаційно-логічна модель практично не потребує перетворення. Кожний інформаційний об’єкт відображається відповідною реляційною таблицею. Зв’язки об’єктів – логічними зв’язками реляційних таблиць у логічній структурі БД. Логічна структура реляційної таблиці визначається згідно з реквізитним складом об’єктів. У таблиці кожний стовпець (поле) відповідає одному з реквізитів у заданій послідовності. Опис структури кожної таблиці повинен мати:
· унікальне ім’я таблиці; · склад і послідовність атрибутів; · унікальне ім’я атрибута всередині таблиці; · тип даних; · властивості даних; · властивості ключів.
Бази даних потребують контролю та захисту. Як правило, відповідальність за це лежить на адміністраторі бази даних. Він повинен координувати процес проектування БД, навчати користувачів роботі з БД, керувати проектуванням і реалізацією процедур захисту даних, підтримувати цілісність даних і забезпечувати задовільну швидкодію системи. Після розробки проекту бази даних можна створити базу даних програмними засобами і заповнити її даними з документів зовнішньої сфери.
Оператори повинні мати можливість систематизувати заключенніе договору, тобто розподіляти товарі по різних категоріях, додавати нові договори й товарі, видаляти старі, вести облік покупок, записувати нових постачальників або видаляти записи про їх. Розробка бази даних Реалізація бази даних На основі моделі даних була створена база даних у форматі обраної СУБД.
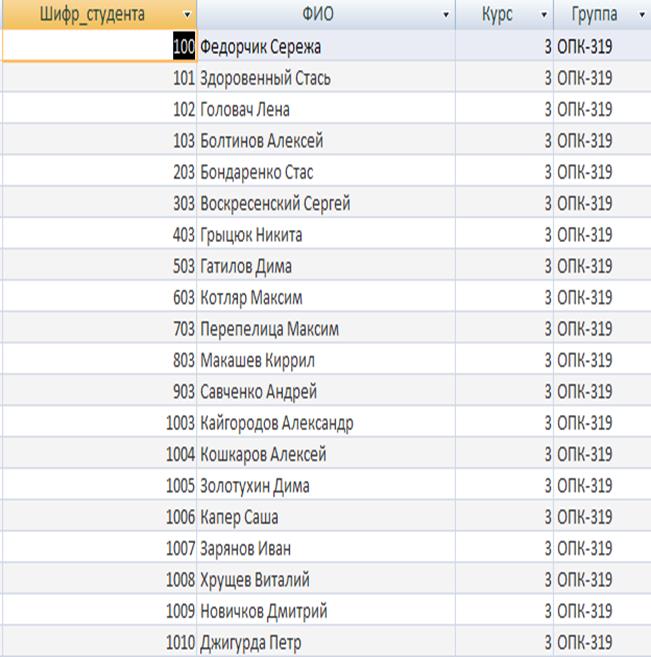
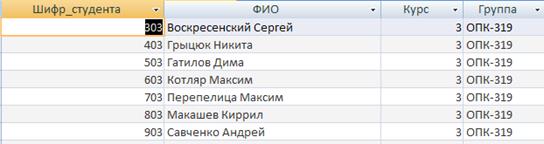
Таблиця «Студенти» призначена для зберігання інформації про студента, який буде здавати екзамени, заліки по деяким дисциплінам. Кожний запис складається з наступних полів, опис яких наведено в таблиці.
Таблиця 2.1 - Опис структури таблиці «Студенти»
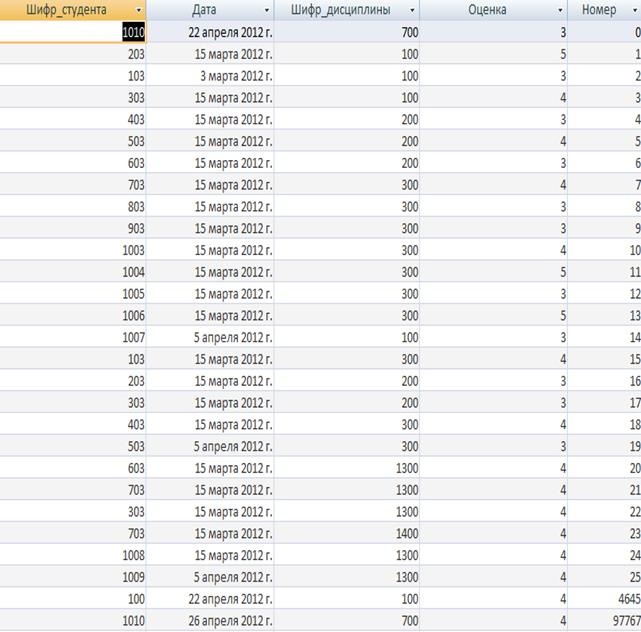
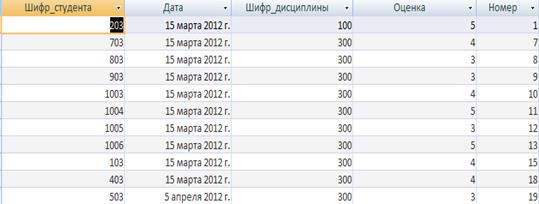
Таблиця «Екзамени» зберігає інформацію про інформацію про ідентифікатор здаваючого студента, дату коли був зданний екзамен, унікальний номер дисципліни, по якій було здано екзамен, оцінка отримана за екзамен, унікальний номер екзамену.. Кожен запис таблиці складається з полів, наведених у таблиці.
Таблиця 2.2 - Опис структури таблиці «Екзамени»
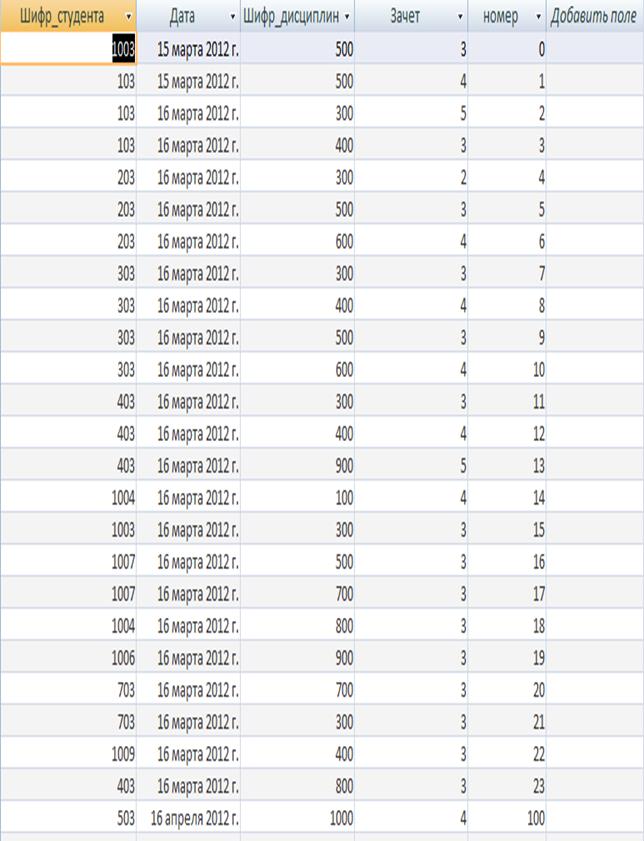
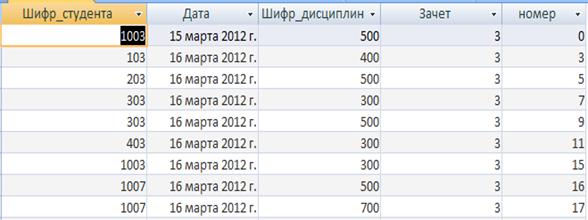
Таблиця «Заліки» зберігає інформацію про унікальний код студента, дата здачі заліку, унікальний код дисципліни, по якій здавався залік, оцінка заліку, номер заліку.. Кожен запис таблиці складається з полів, наведених у таблиці.
Таблиця 2.3 - Опис структури таблиці «Заліки»
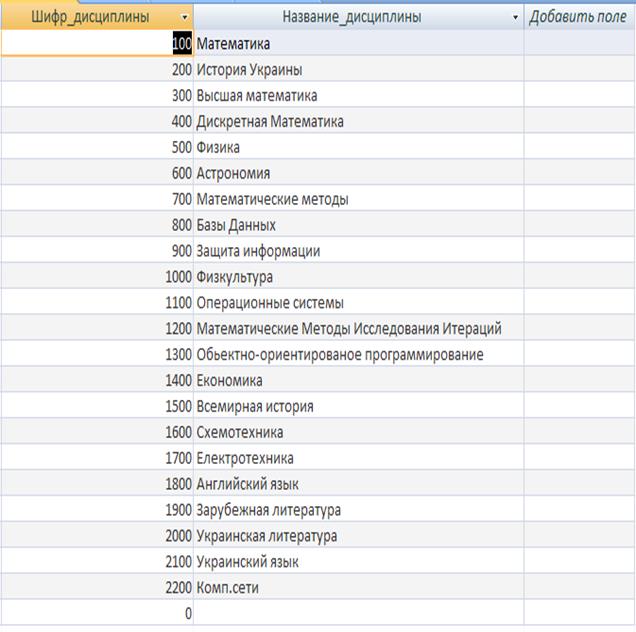
Таблиця «Дисципліни» зберігає інформацію про прізвище, ім’я, по батькові та його дата народження. Кожен запис таблиці складається з полів, наведених у таблиці. Таблиця 2.4 - Опис структури таблиці «Дисципліни»
Таблиця «Дисципліни»
Таблиця «Екзамени»
Таблиця «Студенти»
Таблиця «Заліки»
ДОДАТОК Б ЗАСОБИ ОБРОБКИ ІНФОРМАЦІЇ, ЩО ЗБЕРІГАЮТЬСЯ В БАЗІ ДАНИХ І РЕЗУЛЬТАТИ, ОТРИМАНІ ПРИ ЇХ ВИКОРИСТАННІ
1. Показати шифр студента, дату,шифр дисципліни,оцінку,номер зданого екзамену та показати ті дисципліну шифр якої дорівнює 300, або ж той екзамен, по якому була отримана п’ятірка.Текст запиту на SQL: SELECT *FROM Экзамены WHERE Шифр_дисциплины=300 OR Оценка>4;
2. Показати усі поля таблиці студенти. Текст запиту на SQL: SELECT Студенты.Шифр_студента, Студенты.ФИО, Студенты.Курс, Студенты.Группа FROM Студенты;
3. Показати список дисциплін, із їхніми унікальними ID. Текст запиту на SQL:
SELECT Дисциплины.[Шифр_дисциплины] ,Дисциплины.[Название_дисциплины] FROM Дисциплины;
4. Показати шифр студентів, дату заліку, шифр дисципліни, залік та номер заліку, усіх студентів, які здали залік з будь-якої дисципліни на 3 бали. Текст запиту на SQL: SELECT *FROM Зачеты WHERE Зачет=3;
5. Показати данні, з таблиці «Студенти», а точніше: прізвище ім`я-по-батькові студентів, курс, группу, та шифр студентів.Данні показати про студентів, шифр яких дорівнює більше 300 і менше 1000.Текст запиту на SQL: SELECT *FROM Студенты WHERE Шифр_студента>300 AND Шифр_студента<1000;
6. Вивести шифр дисциплін та назву дисциплін, які починаються на букву «А», а далі йде будь яка послідовність букв. Текст запиту на SQL: SELECT Шифр_дисциплины, Название_дисциплины FROM Дисциплины WHERE Название_дисциплины Like 'А*';
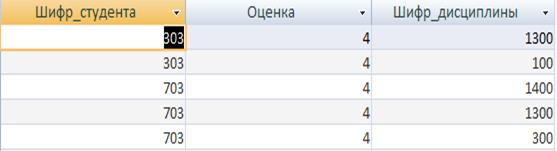
7. Знайти повторювальні записи у таблиці «Заліки».При цьому вивівши на монітор такі доповнюючи данні: прізвище ім`я-по-батькові студента, шифр студента, шифр дисципліни, по якій знайденно повторний запис, оцінку по заліку. Текст запиту на SQL: SELECT Зачеты.[Шифр_студента], Зачеты.[Шифр_дисциплины], Зачеты.[Зачет], Зачеты.[Дата], Зачеты.[номер], Студенты.ФИО FROM Студенты INNER JOIN Зачеты ON Студенты.Шифр_студента = Зачеты.Шифр_студента WHERE (((Зачеты.[Шифр_студента]) In (SELECT [Шифр_студента] FROM [Зачеты] As Tmp GROUP BY [Шифр_студента],[Шифр_дисциплины],[Зачет] HAVING Count(*)>1 And [Шифр_дисциплины] = [Зачеты].[Шифр_дисциплины] And [Зачет] = [Зачеты].[Зачет]))) ORDER BY Зачеты.[Шифр_студента], Зачеты.[Шифр_дисциплины], Зачеты.[Зачет];
8. Знайти повторювальні записи у таблиці «Екзамени».При цьому вивівши на монітор такі доповнюючи данні: шифр студента, шифр дисципліни, по якій знайденно повторний запис,оцінку за екзамен. Текст запиту на SQL: SELECT Экзамены.[Шифр_студента], Экзамены.[Оценка], Экзамены.[Шифр_дисциплины] FROM Экзамены WHERE (((Экзамены.[Шифр_студента]) In (SELECT [Шифр_студента] FROM [Экзамены] As Tmp GROUP BY [Шифр_студента],[Оценка] HAVING Count(*)>1 And [Оценка] = [Экзамены].[Оценка]))) ORDER BY Экзамены.[Шифр_студента], Экзамены.[Оценка];
9. Показати, список студентів, з іх шифром,прізвищем,ім`ям, ім`ям-по-батькові, курсом, на якому вони навчаються, групи в якій перебувають,заліками, та оцінками, які були отримані по залікам. Текст запиту на SQL: SELECT Студенты.Шифр_студента, Студенты.ФИО, Студенты.Курс, Студенты.Группа, Зачеты.Дата, Зачеты.Зачет FROM Студенты INNER JOIN Зачеты ON Студенты.[Шифр_студента] = Зачеты.[Шифр_студента]; Показати данні, про екзамени,для кожного студенту. Вивести поля: шифр студенту, оцінку, та шифр самого студенту, який здавав екзамен. Текст запиту на SQL: SELECT Экзамены.Шифр_студента, Экзамены.Оценка, Экзамены.Шифр_дисциплины FROM Экзамены;
1 Гарсиа-Молина Г., Ульман Д., Уидом Д. Системи баз даних. Повний курс.: Пер. с англ. - М.: Видавничий будинок "Вільямс", 2004. - 1088 с. 2 Дейт К. Дж. Введення в системи баз даних.:Пер. с англ. - 6-і изд. - К.: Діалектика, 1998. - 784 с. 3 Калянов Г.Н. CASE-технології. Консалтинг в автоматизації бізнесів-процесів. - 3-і изд. - М.: Гаряча линия-телеком,2002. - 320 с. 4. Кренке Д. Теорія й практика побудови баз даних. 9-і изд. - Спб.: Питер, 2005. - 859 с. 5. Маклаков С.В. BPWin й ERWin. CASE-засоби розробки інформаційних систем. - 2-і изд., испр. і дополн. - М.: ДИАЛОГ-МИФИ, 2001. - 304 с. 9 Маклаков С.В. Створення інформаційних систем з AllFusion Modeling Suite. - М.: ДИАЛОГ-МИФИ, 2003. - 432 с. 10 Роб П., Коронел К. Системи баз даних: проектування, реалізація й керування. - 5-і изд., перераб. і доп.: Пер. с англ. - Спб.: Бхв-петербург, 2004. - 1040 с. 11 Ситник Н.В., Краснюк М.Т. Проектування баз і сховищ даних: Навч.-метод. посіб. для самост. вивч. дисц. - К.: КНЕУ, 2005. - 264 с.
СУЧАСНІ СУБД Й ЇХ ВИКОРИСТАННЯ ДЛЯ РІШЕННЯ ЗАВДАНЬ АВТОМАТИЗАЦІЇ ЗБЕРІГАННЯ ТА ОБРОБКИ ІНФОРМАЦІЇ ТОРГІВЕЛЬНОГО ПІДПРИЕМСТВА.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 917; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.116.15.124 (0.019 с.) |