Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Побудова ієрархії діаграм потоків данихСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Першим кроком при побудові ієрархії ДПД є побудова контекстних діаграм. Звичайно при проектуванні відносно простих ІС будується єдина контекстна діаграма із зіркоподібною топологією, в центрі якої знаходиться так званий головний процес, сполучений з приймачами і джерелами інформації, за допомогою яких з системою взаємодіють користувачі і інші зовнішні системи. Якщо ж для складної системи обмежитися єдиною контекстною діаграмою, то вона міститиме дуже велику кількість джерел і приймачів інформації, які важко розташувати на листі паперу нормального формату, і крім того, єдиний головний процес не розкриває структури розподіленої системи. Ознаками складності (у сенсі контексту) можуть бути: 1. наявність великої кількості зовнішньої суті (десять і більше); 2. розподілена природа системи; 3. багатофункціональність системи з групуванням функцій, що вже склалося або було виявлено, в окремі підсистеми. Для складних ІС будується ієрархія контекстних діаграм. При цьому контекстна діаграма верхнього рівня містить не єдиний головний процес, а набір підсистем, сполучених потоками даних. Контекстні діаграми наступного рівня деталізують контекст і структуру підсистем. Ієрархія контекстних діаграм визначає взаємодію основних функціональних підсистем проектованої ІС як між собою, так і із зовнішніми вхідними і вихідними потоками даних і зовнішніми об'єктами (джерелами і приймачами інформації), з якими взаємодіє ІС. Розробка контекстних діаграм вирішує проблему чіткого визначення функціональної структури ІС на початковій стадії її проектування, що особливо важливо для складних багатофункціональних систем, в розробці яких беруть участь різні організації і колективи розробників. Після побудови контекстних діаграм отриману модель слід перевірити на повноту початкових даних про об'єкти системи і ізольованість об'єктів (відсутність інформаційних зв'язків з іншими об'єктами). Для кожної підсистеми, присутньої на контекстних діаграмах, виконується її деталізація за допомогою ДПД. Кожен процес на ДПД, у свою чергу, може бути деталізований за допомогою ДПД або мініспецифікацій. При деталізації повинні виконуватися наступні правила:
Мініспецифікація (опис логіки процесу) повинна формулювати його основні функції так, щоб надалі фахівець, що виконує реалізацію проекту, зміг виконати їх або розробити відповідну програму.
Мініспецифікація є кінцевою вершиною ієрархії ДПД. Рішення про завершення деталізації процесу і використання мініспецифікації ухвалюється аналітиком виходячи з таких критеріїв: · наявність у процесу щодо невеликої кількості вхідних і вихідних потоків даних (2-3 потоки); · можливості опису перетворення даних процесом у вигляді послідовного алгоритму; · виконання процесом єдиної логічної функції перетворення вхідної інформації у вихідну; · можливості опису логіки процесу за допомогою мініспецифікації невеликого об'єму (не більше 20-30 рядків). При побудові ієрархії ДПД переходити до деталізації процесів слід тільки після визначення змісту всіх потоків і накопичувачів даних, який описується за допомогою структур даних. Структури даних конструюються з елементів даних і можуть містити альтернативи, умовні входження та ітерації. Умовне входження означає, що даний компонент може бути відсутнім в структурі. Альтернатива означає, що в структуру може входити один з перерахованих елементів. Ітерація означає входження будь-якого числа елементів у вказаному діапазоні. Для кожного елементу даних може вказуватися його тип (безперервні або дискретні дані). Для безперервних даних може вказуватися одиниця вимірювання (кг, см і т.п.), діапазон значень, точність уявлення і форма фізичного кодування. Для дискретних даних може вказуватися таблиця допустимих значень. Після побудови завершеної моделі системи її необхідно верифікувати (перевірити на повноту і узгодженість). У повній моделі всі її об'єкти (підсистеми, процеси, потоки даних) повинні бути детально описані і деталізовані. Виявлені недеталізовані об'єкти слід деталізувати, повернувшись на попередні кроки розробки. У узгодженій моделі для всіх потоків даних і накопичувачів даних повинно виконуватися правило збереження інформації: всі дані, що поступають куди-небудь повинні бути пораховані, а всі дані, що читаються, повинні бути записані.
Моделювання даних Case-метод Баркера Мета моделювання даних полягає в забезпеченні розробника ІС концептуальною схемою бази даних у формі однієї моделі або декількох локальних моделей, які відносно легко можуть бути відображені в будь-яку систему баз даних. Найпоширенішим засобом моделювання даних є діаграми "сутність-зв'язок" (ERD). З їхньою допомогою визначаються важливі для предметної області об'єкти (сутності), їх властивості (атрибути) і відносини один з одним (зв'язки). ERD безпосередньо використовуються для проектування реляційних баз даних. Нотація ERD була вперше введена П. Ченом (Chen) і одержала подальший розвиток у роботах Баркера [8]. Метод Баркера буде викладатися на прикладі моделювання діяльності компанії з торгівлі автомобілями. Нижче наведені уривки з інтерв'ю, проведеного з персоналом компанії. Головний менеджер: один з основних обов'язків – утримання автомобільного майна. Він повинен знати, скільки сплачено за машини і які накладні витрати. Маючи цю інформацію, він може встановити нижню ціну, за яку міг би продати даний екземпляр. Крім того, він відповідає за продавців і йому потрібно знати, хто що продає і скільки машин продав кожний з них. Продавець: йому потрібно знати, яку ціну встановлювати і яка нижня ціна, за якої можна здійснити операцію. Крім того, йому потрібна основна інформація про машини: рік випуску, марка, модель і т.п. Адміністратор: його завдання зводиться до складання контрактів, для чого потрібна інформація про покупця, автомашину й продавця, оскільки саме контракти приносять продавцям винагороди за продажі. Перший крок моделювання - вибірка інформації з інтерв'ю й виділення сутностей. Сутність (Entity) - реальний або уявний об'єкт, що має істотне значення для розглянутої предметної області, інформація про який підлягає збереженню (рисунок 2.18).
Рис. 2.18. Графічне зображення сутності Кожна сутність повинна мати унікальний ідентифікатор. Кожен екземпляр сутності повинен однозначно ідентифікуватися й відрізнятися від всіх інших екземплярів даного типу сутності. Кожна сутність повинна мати деякі властивості: à кожна сутність повинна мати унікальне ім'я, і до одного і того самого імені повинна завжди застосовуватися одна і та ж сама інтерпретація. Та сама інтерпретація не може застосовуватися до різних імен, якщо тільки вони не є псевдонімами; à сутність володіє одним або декількома атрибутами, які або належать сутності, або успадковуються через зв'язок; à сутність володіє одним або декількома атрибутами, які однозначно ідентифікують кожен екземпляр сутності; à кожна сутність може мати будь-яку кількість зв'язків з іншими сутностями моделі. Звертаючись до наведених вище уривків з інтерв'ю, видно, що сутності, які можуть бути ідентифіковані з головним менеджером - це автомашини й продавці. Продавцю важливі автомашини й пов'язані з їхнім продажем дані. Для адміністратора важливі покупці, автомашини, продавці й контракти. Виходячи із цього, виділяються 4 сутності (автомашина, продавець, покупець, контракт), які зображуються на діаграмі в такий спосіб (рисунок 2.19).
Рис. 2.19. Наступним кроком моделювання є ідентифікація зв'язків. Зв'язок (Relationship) - пойменована асоціація між двома сутностями, що має значення для розглянутої предметної області. Зв'язок - це асоціація між сутностями, за якої, як правило, кожен екземпляр однієї сутності, названою батьківською сутністю, асоційований з довільною (у тому числі нульовою) кількістю екземплярів другої сутності, названою сутністю-нащадком, а кожен екземпляр сутності-нащадка асоційований у точності з одним екземпляром сутності-батька. Таким чином, екземпляр сутності-нащадка може існувати тільки при існуванні сутності батька. Зв'язку може даватися ім'я, що виражається граматичним зворотом дієслова, і поміщається біля лінії зв'язку. Ім'я кожного зв'язку між двома даними сутностями повинне бути унікальним, але імена зв'язків у моделі не обов’язково мають бути унікальними. Ім'я зв'язку завжди формується з точки зору батька, так що словосполучення може бути утворено поєднанням імені сутності-батька, імені зв'язку, вираження ступеня та імені сутності-нащадка. Наприклад, зв'язок продавця з контрактом може бути виражений в такий спосіб: à продавець може одержати винагороду за 1 або більше контрактів; à контракт повинен бути ініційований рівно одним продавцем. Ступінь зв'язку й обов'язковість графічно зображуються в такий спосіб (рисунок 2.20).
Рис. 2.20.
Таким чином, 2 пропозиції, що описують зв'язок продавця з контрактом, графічно будуть виражені в такий спосіб (рисунок 2.21).
Описавши також зв'язки інших сутностей, одержимо наступну схему (рисунок 2.22).
Останнім кроком моделювання є ідентифікація атрибутів. Атрибут - будь-яка характеристика сутності, що має значення для розглянутої предметної області й призначена для кваліфікації, ідентифікації, класифікації, кількісної характеристики або вираження стану сутності. Атрибут являє собою тип характеристик або властивостей, асоційованих з безліччю реальних або абстрактних об'єктів (людей, місць, подій, станів, ідей, пара предметів і т.д.). Екземпляр атрибута - це певна характеристика окремого елемента множини. Екземпляр атрибута визначається типом характеристики та її значенням, що називається значенням атрибута. В ER-моделі атрибути асоціюються з конкретними сутностями. Таким чином, екземпляр сутності повинен мати єдине конкретне значення для асоційованого атрибута.
Атрибут може бути або обов'язковим, або необов'язковим (рисунок 2.23). Обов'язковість означає, що атрибут не може приймати невизначених значень (null values). Атрибут може бути або описовим (тобто звичайним дескриптором сутності), або входити до складу унікального ідентифікатора (первинного ключа). Унікальний ідентифікатор - це атрибут або сукупність атрибутів і/або зв'язків, призначений для унікальної ідентифікації кожного екземпляра даного типу сутності. У випадку повної ідентифікації кожен екземпляр даного типу сутності повністю ідентифікується своїми власними ключовими атрибутами, у протилежному випадку в його ідентифікації беруть участь також атрибути іншої сутності-батька (рисунок 2.24).
Рис. 2.23.
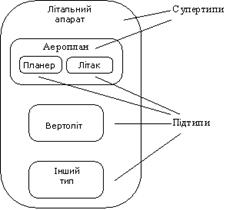
Рис. 2.24. Кожен атрибут ідентифікується унікальним ім'ям, що виражає граматичним зворотом іменника, яке описує характеристику, що представляється атрибутом. Атрибути зображуються у вигляді списку імен усередині блоку асоційованої сутності, причому кожен атрибут займає окремий рядок. Атрибути, що визначають первинний ключ, розміщаються нагорі списку й виділяються знаком "#". Кожна сутність повинна володіти хоча б одним можливим ключем. Можливий ключ сутності - це один або кілька атрибутів, чиї значення однозначно визначають кожен екземпляр сутності. При існуванні декількох можливих ключів один з них позначається як первинний ключ, а інші - як альтернативні ключі. З урахуванням наявної інформації доповнимо побудовану раніше діаграму (рисунок 2.25). Крім перерахованих основних конструкцій модель даних може містити ряд додаткових. Підтипи й супертипи: одна сутність є узагальнюючим поняттям для групи подібних сутностей (рисунок 2.26). Взаємовиключаючі зв'язки: кожен екземпляр сутності бере участь тільки в одному зв'язку із групи взаємовиключаючих зв'язків (рисунок 2.27)
Рис. 2.25.
Рис. 2.26. Підтипи й супертипи
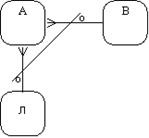
Рис. 2.27. Взаємовиключаючі зв'язки Рекурсивний зв'язок: сутність може бути зв'язана сама із собою (рисунок 2.28). Непереміщувані (non-transferrable) зв'язки: екземпляр сутності не може бути перенесений з одного екземпляра зв'язка в іншій (рисунок 2.29).
Рис. 2.28. Рекурсивний зв'язок
Рис. 2.29. Непереміщуваний зв'язок Методологія IDEF1 Метод IDEF1, розроблений Т.Ремей (T.Ramey), також заснований на підході П.Чена й дозволяє побудувати модель даних, еквівалентну реляційній моделі в третій нормальній формі. На даний час на основі вдосконалення методології IDEF1 створена її нова версія - методологія IDEF1X. IDEF1X розроблена з урахуванням таких вимог, як простота вивчення й можливість автоматизації. IDEF1X-діаграми використовуються поруч з розповсюдженими CASE-засобами (зокрема, ERwin, Design/IDEF). Сутність у методології IDEF1X є незалежною від ідентифікаторів або просто незалежною, якщо кожен екземпляр сутності може бути однозначно ідентифікований без визначення його зв’язків з іншими сутностями. Сутність називається залежною від ідентифікаторів або просто залежною, якщо однозначна ідентифікація екземпляра сутності залежить від його відношення до іншої сутності (рисунок 2.30).
Рис. 2.30. Сутності
Кожній сутності присвоюється унікальне ім'я й номер, розділені косою рискою "/" і розміщують над блоком. Зв'язок може додатково визначатися за допомогою вказування степеня або потужності (кількості екземплярів сутності-нащадка, які можуть існувати для кожного екземпляра сутності-батька). В IDEF1X можуть бути виражені наступні потужності зв'язків: à кожен екземпляр сутності-батька може мати нуль, один або більше пов'язаних з ним екземплярів сутності-нащадка; à кожен екземпляр сутності-батька повинен мати не менше одного пов'язаного з ним екземпляра сутності-нащадка; à кожен екземпляр сутності-батька повинен мати не більше одного пов'язаного з ним екземпляра сутності-нащадка; à кожен екземпляр сутності-батька пов'язаний з деяким фіксованим числом екземплярів сутності-нащадка. Якщо екземпляр сутності-нащадка однозначно визначається своїм зв'язком із сутністю-батьком, то зв'язок називається ідентифікуючим, у противному випадку - неідентифікуючим. Зв'язок зображується лінією, проведеною між сутністю-батьком і сутністю-нащадком із крапкою на кінці лінії в сутності-нащадка. Потужність зв'язку позначається як показано на рис. 2.31 (потужність за замовчуванням - N).
Рис. 2.31. Потужність зв'язку
Ідентифікуючий зв'язок між сутністю-батьком і сутністю-нащадком зображується суцільною лінією (рисунок 2.32). Сутність-нащадок в ідентифікуючому зв'язку є залежною від ідентифікатора сутністю. Сутність-батько в ідентифікуючому зв'язку може бути як незалежною, так і залежною від ідентифікатора сутністю (це визначається її зв'язками з іншими сутностями).
Рис. 2.32. Ідентифікуючий зв'язок
Пунктирна лінія зображує неідентифікуючий зв'язок (рисунок 2.33). Сутність-нащадок у неідентифікуючому зв'язку буде незалежною від ідентифікатора, якщо вона не є також сутністю-нащадком у якому-небудь ідентифікуючому зв'язку.
Рис. 2.33. Неідентифікуючий зв'язок
Атрибути зображуються у вигляді списку імен усередині блоку сутності. Атрибути, що визначають первинний ключ, розміщаються нагорі списку й відокремлюються від інших атрибутів горизонтальною рискою (рисунок 2.34).
Рис. 2.34. Атрибути й первинні ключі
Сутності можуть мати також зовнішні ключі (Foreign Key), які можуть використовуватися як частина або цілого первинного ключа, або неключового атрибута. Зовнішній ключ зображується за допомогою внесення усередину блоку сутності імен атрибутів, після яких йдуть букви FK у дужках (рисунок 2.35).
Рис. 2.35. Приклади зовнішніх ключів Критерії оцінки і вибору Критерії формують базис для процесів оцінки та вибору і можуть приймати різні форми, включаючи: • числові заходи в широкому діапазоні значень; • числові заходи в обмеженому діапазоні значень; • двійкові заходи (істина/брехня, так/ні); • заходи, які можуть приймати одне або більше з безлічі кінцевих значень. Кожен критерій повинен бути вибраний і адаптований експертом з урахуванням особливостей конкретного процесу. В більшості випадків тільки деякі з безлічі описаних нижче критеріїв виявляються прийнятними для використання, при цьому також додаються додаткові критерії. Вибір і уточнення набору використовуваних критеріїв є критичним кроком в процесі оцінки і/або вибору. Функціональні характеристики Критерії першого класу призначені для визначення функціональних характеристик CASE-засобу. Вони діляться на ряд груп і підгруп. 1. Середовище функціонування: а. Проектне середовище: • підтримка процесів життєвого циклу. Визначає набір процесів ЖЦ, які підтримує CASE-засіб. Прикладами таких процесів є аналіз вимог, проектування, реалізація, тестування і оцінка, супровід, забезпечення якості, управління конфігурацією і управління проектом, причому вони залежать від прийнятої користувачем моделі ЖЦ. • область застосування. Прикладами є системи обробки трансакцій, системи реального часу, інформаційні системи і т.д. • розмір підтримуваних додатків. Визначає обмеження на такі величини, як кількість рядків коду, розмір бази даних, кількість елементів даних, кількість об'єктів конфігураційного управління. b. ПО/ТЕХНІЧНІ засоби: • необхідні технічні засоби. Устаткування, необхідне для функціонування CASE-засобу, включаючи тип процесора, об'єм оперативної і дискової пам'яті. • підтримувані технічні засоби. Елементи устаткування, які можуть використовуватися CASE-засобом, наприклад, пристрою введення/виведення. • потрібне ПО. ПО, необхідне для функціонування CASE-засобу, включаючи операційні системи і графічні оболонки. • підтримуване ПО. Програмні продукти, які можуть використовуватися CASE-засобом. c. Технологічне середовище: • відповідність стандартам технологічного середовища. Такі стандарти стосуються мови, бази даних, комунікацій, графічного інтерфейсу користувача, документації, розробки, управління конфігурацією, безпеки, стандартів обміну інформацією і інтеграції по даних, по управлінню і по призначеному для користувача інтерфейсу. • сумісність з іншими засобами. Здібність до взаємодії з іншими засобами, включаючи безпосередній обмін даними (прикладами таких засобів є текстові процесори, бази даних і інші CASE-засоби). • підтримувана методологія. Набір методів і методик, підтримуваних CASE-засобом. Прикладами є структурний або об'єктно-орієнтований аналіз і проектування. • підтримувані мови. Всі мови, використовувані CASE-засобом. Прикладами таких мов є мови програмування (Кобол, Ада, З), мови баз даних і мови запитів (DDL, SQL), графічні мови (Postscript, HPGL), мови специфікації проектних вимог і інтерфейси операційних систем (мови управління завданнями). 2. Функції, орієнтовані на фази життєвого циклу: а.Моделювання: • побудова діаграм. Можливість створення і редагування діаграм різних типів, що представляють інтерес для користувача. • графічний аналіз. Можливість аналізу графічних об'єктів, а також зберігання і представлення проектної інформації в графічному уявленні. • введення і редагування специфікацій вимог і проектних специфікацій. До специфікацій такого роду відносяться описи функцій, даних, інтерфейсів, структури, якості, продуктивності, технічних засобів, середовища, витрат і графіків. • мова специфікації вимог і проектних специфікацій. Можливість імпорту, експорту і редагування специфікацій з використанням формальної мови. • моделювання даних. Можливість введення і редагування інформації, що описує елементи даних системи і їх відношення. • моделювання процесів. Можливість введення і редагування інформації, що описує процеси системи і їх відношення. • проектування архітектури ПО. Проектування логічної структури ПО - структури модулів, інтерфейсів і ін. • імітаційне моделювання. Можливість динамічного моделювання різних аспектів функціонування системи на основі специфікацій вимог і/або проектних специфікацій, включаючи зовнішній інтерфейс і продуктивність. • прототипування. Можливість проектування і генерації попереднього варіанту всієї системи або її окремих компонент на основі специфікацій вимог і/або проектних специфікацій. Прототипування в основному стосується зовнішнього, призначеного для користувача інтерфейсу і здійснюється при безпосередній участі користувачів. • генерація екранних форм. Можливість генерації екранних форм на основі специфікацій вимог і/або проектних специфікацій. • можливість трасування. Можливість аналізу функціонування системи від специфікації вимог до кінцевих результатів (встановлення і відстежування відповідностей і зв'язків між функціональними і іншими зовнішніми вимогами до ІС, технічними рішеннями і результатами проектування). Пряме трасування (перевірка обліку всіх вимог) і зворотне трасування (пошук проектних рішень, не пов'язаних ні з якими зовнішніми вимогами). • синтаксичний і семантичний контроль проектних специфікацій. Контроль синтаксису діаграм і типів їх елементів, контроль декомпозиції функцій, перевірка специфікацій на повноту і несуперечність. • інші види аналізу. Конкретні додаткові види аналізу можуть включати алгоритми, потоки даних, нормалізацію даних, використання даних, призначений для користувача інтерфейс. • автоматизоване проектування звітів. b.Реалізація: синтаксично кероване редагування. Можливість введення і редагування початкових кодів на одному або декількох мовах з одночасним синтаксичним контролем. • генерація коду. Можливість генерації кодів на одному або декількох мовах на основі проектних специфікацій. Типи коду, що генерується, можуть включати звичайний програмний код, схему бази даних, запити, екрани/меню. • компіляція коду. • конвертація початкового коду. Можливість перетворення коду з однієї мови в іншій. • аналіз надійності. Можливість кількісно оцінювати параметри надійності ПО, такі, як кількість помилок і ін. • реверсний інжиніринг. Можливість аналізу існуючих початкових кодів і формування на їх основі проектних специфікацій. • реструктуризація початкового коду. Можливість модифікації формату і/або структури існуючого початкового коду. • аналіз початкового коду. Прикладами такого аналізу можуть бути визначення розміру коду, обчислення показників складності, генерація перехресних посилань і перевірка на відповідність стандартам. • відлагодження. Типові функції відлагодження - трасування програм, виділення вузьких місць і найбільш часто використовуваних фрагментів коду і т.д. 3.Тестування: • опис тестів. Типові можливості включають генерацію тестових даних, алгоритмів тестування, необхідних результатів і т.д. • фіксація і повторення дій оператора. Можливість фіксувати дані, що вводяться оператором за допомогою клавіатури, миші і т.д., редагувати їх і відтворювати в тестових прикладах. • автоматичний запуск тестових прикладів. • регресійне тестування. Можливість повторення і модифікації раніше виконаних тестів для визначення відмінностей в системі і/або середовищі. • автоматизований аналіз результатів тестування. Типові можливості включають порівняння очікуваних і реальних результатів, порівняння файлів, статистичний аналіз результатів і ін. • аналіз тестового покриття. Оснащеність засобами контролю початкового коду і аналіз тестового покриття. Перевіряються, зокрема, звернення до операторів, процедур і змінних. • аналіз продуктивності. Можливість аналізу продуктивності програм. Аналізовані параметри продуктивності можуть включати використання центрального процесора, пам'яті, звернення до певних елементів даних і/або сегментам коду, тимчасові характеристики і т.д. • аналіз виняткових ситуацій в процесі тестування. • динамічне моделювання середовища. Зокрема, можливість автоматично генерувати модельовані вхідні дані системи. 3.Загальні функції: а. Документування: • редагування текстів і графіки. Можливість вводити і редагувати дані в текстовому і графічному форматі. • редагування за допомогою форм. Можливість підтримувати форми, визначені користувачами, вводити і редагувати дані відповідно до форм. • можливості видавничих систем. • підтримка функцій і форматів гіпертексту. • відповідність стандартам документування. • автоматичне витягання даних з репозиторія і генерація документації по специфікаціях користувача. b. Управління конфігурацією: • контроль доступу і змін. Можливість контролю доступу на фізичному рівні до елементів даних і контролю змін. • відстежування модифікацій. Фіксація і ведення журналу всіх модифікацій, внесених до системи в процесі розробки або супроводу. • управління версіями. Ведення і контроль даних про версії системи і всіх її використовуваних компонентів. • облік стану об'єктів конфігураційного управління. Можливість отримання звітів про всі послідовні версії, вміст і стан різних об'єктів конфігураційного управління. • генерація версій і модифікацій. Підтримка призначеного для користувача опису послідовності дій, потрібних для формування версій і модифікацій, і автоматичне виконання цих дій. • архівація. Можливість автоматичної архівації елементів даних для подальшого використання. з. Управління проектом: • управління роботами і ресурсами. Контроль і управління процесом проектування ІС в термінах структури завдань і призначення виконавців, послідовності їх виконання, завершення окремих етапів проекту і проекту в цілому. Можливість підтримки планових даних, фактичних даних і їх аналізу. • оцінка. Можливість оцінювати витрати, графік і інші проектні параметри, що вводяться користувачами. • управління процедурою тестування. Підтримка управління процедурами і програмою тестування, наприклад, управління розкладом планованих процедур, фіксація і запис результатів тестування, генерація звітів і т.д. • управління якістю. Введення відповідних даних, їх аналіз і генерація звітів. • дії, що коректують. Підтримка управління діями, що коректують, включаючи обробку повідомлень про проблемні ситуації.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 777; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.188.223.91 (0.019 с.) |