Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Директивы размещения данных разных типов.Содержание книги
Поиск на нашем сайте Для численных данных определены типы ниже. Директива определения размещает и инициализирует задаваемое значение. имя BYTE значение; беззнаковый байт (1 байт), синоним DB. имя SBYTE значение; знаковый байт (1 байт). имя WORD значение; беззнаковое слово (2 байта), синоним DD. имя SWORD значение; знаковое слово (2 байта). имя DWORD значение; беззнаковое двойное слово (4 байта). имя SDWORD значение; знаковое двойное слово (4 байта). имя FWORD значение; беззнаковое слово (6 байт), синоним DF. имя QWORD значение; беззнаковое квадрослово (8 байт), синоним DQ. имя SQWORD значение; знаковое квадрослово (8 байт). имя OWORD значение; беззнаковое октослово (16 байт). имя REAL4 значение; переменная с ПТ с одинарной точностью (4 байта). имя REAL8 значение; переменная с ПТ с двойной точностью (8 байт). имя REAL10 значение; переменная с ПТ с повышенной точностью (10 байт). имя TBYTE значение; переменная с ПТ с повышенной точностью (10 байт), синоним DT. Строки. Директивы работы со строками.
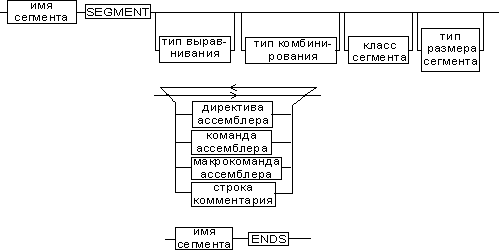
Структуры и записи. В MASM определены сложные объекты: · Записи. Это наборы полей переменной длины. · Структуры. Это наборы иерархически организованных областей. · Объединения. Это объекты, состоящие из разнородных объектов. Директива RECORD. Объявление записи с именем ИмяЗаписи, состоящей из поименованных полей с шириной, определяемой выражением. Синтакис: ИмяЗаписи RECORD; Объявление записи с именем ИмяЗаписи ИмяПоля:Ширина = выражение; Объявление поля записи ИмяПоля:Ширина = выражение; Объявление поля записи Директива STRUCT. Синтакис: ИмяСтруктуры STRUCT; Объявление структуры с именем ИмяСтруктуры ДекларацияПоля; Объявление поля структуры ДекларацияПоля; Объявление поля структуры ИмяСтруктуры ENDS; Конец структуры Директива UNION. Синтакис: ИмяОбъединения UNION; Объявление объединения с именем ИмяОбъединения ДекларацияПоля; Объявление поля объединения … ИмяОбъединения ENDS; Конец объединения Директива TYPEDEF. Объявление нового типа, который эквивалентен заданному типу. Синтакис: ИмяТипа TYPEDEF тип; Объявление типа с именем ИмяТипа, который эквивалентен заданному типу. · Стандартные директивы сегментации Для архитектуры Фон-Неймана используется одно общее ОЗУ. В нем нужно размещать коды программ, константы, переменные и стек. Сегментация используеттся для выделения сегментов под эти клмпоненты. Предусмотрены две группы директив – общие и упрощенные. Физически сегмент представляет собой область памяти, занятую командами и (или) данными, адреса которых вычисляются относительно значения в соответствующем сегментном регистре. Директива SEGMENT. Синтаксическое описание сегмента на ассемблере представляет собой конструкцию:
Первое предложение – это определение сегмента и его атрибутов. Последнее предложение – конец сегмента. Внутри размещаются содержательные предложения – директивы, команды, макрокоманды, комментарии. Имя сегмента. Назначает сегменту символическое имя, определяемое содержанием сегмента (код, данные и др.) Атрибут выравнивания сегмента (тип выравнивания) сообщает компоновщику о том, что нужно обеспечить размещение начала сегмента на заданной границе. Это важно, поскольку при правильном выравнивании доступ к данным в процессорах выполняется быстрее. Допустимые значения этого атрибута следующие: BYTE — выравнивание не выполняется. Сегмент может начинаться с любого адреса памяти; WORD — сегмент начинается по адресу, кратному 2, то есть последний (младший) значащий бит физического адреса равен 0 (выравнивание на границу слова); DWORD — сегмент начинается по адресу, кратному 4, то есть два последних (младших) значащих бита равны 0 (выравнивание на границу двойного слова); PARA — сегмент начинается по адресу, кратному 16, то есть последняя шестнадцатеричная цифра адреса должна быть 0h (выравнивание на границу параграфа); PAGE — сегмент начинается по адресу, кратному 256, то есть две последние шестнадцатеричные цифры должны быть 00h (выравнивание на границу 256-байтной страницы); MEMPAGE — сегмент начинается по адресу, кратному 4 Кбайт, то есть три последние шестнадцатеричные цифры должны быть 000h (адрес следующей 4-Кбайтной страницы памяти). По умолчанию тип выравнивания имеет значение PARA. Атрибут комбинирования сегментов (комбинаторный тип) сообщает компоновщику, как нужно комбинировать сегменты различных модулей, имеющие одно и то же имя. Значениями атрибута комбинирования сегмента могут быть: PRIVATE — сегмент не будет объединяться с другими сегментами с тем же именем вне данного модуля; PUBLIC — заставляет компоновщик соединить все сегменты с одинаковыми именами. Новый объединенный сегмент будет целым и непрерывным. Все адреса (смещения) объектов, а это могут быть, в зависимости от типа сегмента, команды и данные, будут вычисляться относительно начала этого нового сегмента; COMMON — располагает все сегменты с одним и тем же именем по одному адресу. Все сегменты с данным именем будут перекрываться и совместно использовать память. Размер полученного в результате сегмента будет равен размеру самого большого сегмента; AT xxxx — располагает сегмент по абсолютному адресу параграфа (параграф — объем памяти, кратный 16; поэтому последняя шестнадцатеричная цифра адреса параграфа равна 0). Абсолютный адрес параграфа задается выражением xxx. Компоновщик располагает сегмент по заданному адресу памяти (это можно использовать, например, для доступа к видеопамяти или области ПЗУ), учитывая атрибут комбинирования. Физически это означает, что сегмент при загрузке в память будет расположен, начиная с этого абсолютного адреса параграфа, но для доступа к нему в соответствующий сегментный регистр должно быть загружено заданное в атрибуте значение. Все метки и адреса в определенном таким образом сегменте отсчитываются относительно заданного абсолютного адреса; STACK — определение сегмента стека. Заставляет компоновщик соединить все одноименные сегменты и вычислять адреса в этих сегментах относительно регистра ss. Комбинированный тип STACK (стек) аналогичен комбинированному типу PUBLIC, за исключением того, что регистр ss является стандартным сегментным регистром для сегментов стека. Регистр sp устанавливается на конец объединенного сегмента стека. Если не указано ни одного сегмента стека, компоновщик выдаст предупреждение, что стековый сегмент не найден. Если сегмент стека создан, а комбинированный тип STACK не используется, программист должен явно загрузить в регистр ss адрес сегмента (подобно тому, как это делается для регистра ds). По умолчанию атрибут комбинирования принимает значение PRIVATE. Атрибут класса сегмента (тип класса) — это заключенная в кавычки строка, помогающая компоновщику определить соответствующий порядок следования сегментов при собирании программы из сегментов нескольких модулей. Компоновщик объединяет вместе в памяти все сегменты с одним и тем же именем класса (имя класса, в общем случае, может быть любым, но лучше, если оно будет отражать функциональное назначение сегмента). Типичным примером использования имени класса является объединение в группу всех сегментов кода программы (обычно для этого используется класс “code”). С помощью механизма типизации класса можно группировать также сегменты инициализированных и неинициализированных данных; Атрибут размера сегмента. Для процессоров i80386 и выше сегменты могут быть 16 или 32-разрядными. Это влияет, прежде всего, на размер сегмента и порядок формирования физического адреса внутри него. Атрибут может принимать следующие значения: USE16 — это означает, что сегмент допускает 16-разрядную адресацию. При формировании физического адреса может использоваться только 16-разрядное смещение. Соответственно, такой сегмент может содержать до 64 Кбайт кода или данных; USE32 — сегмент будет 32-разрядным. При формирования физического адреса может использоваться 32-разрядное смещение. Поэтому такой сегмент может содержать до 4 Гбайт кода или данных. Директива ASSUME. Все сегменты сами по себе равноправны, так как директивы SEGMENT и ENDS не содержат информации о функциональном назначении сегментов. Для того чтобы использовать их как сегменты кода, данных или стека, необходимо предварительно сообщить транслятору об этом, для чего используют специальную директиву ASSUME, имеющую формат, показанный на рисунке. Эта директива сообщает транслятору о том, какой сегмент к какому сегментному регистру привязан. В свою очередь, это позволит транслятору корректно связывать символические имена, определенные в сегментах. Привязка сегментов к сегментным регистрам осуществляется с помощью операндов этой директивы, в которых имя_сегмента должно быть именем сегмента, определенным в исходном тексте программы директивой SEGMENT или ключевым словом nothing. Если в качестве операнда используется только ключевое слово nothing, то предшествующие назначения сегментных регистров аннулируются, причем сразу для всех шести сегментных регистров. Но ключевое слово nothing можно использовать вместо аргумента имя сегмента; в этом случае будет выборочно разрываться связь между сегментом с именем имя сегмента и соответствующим сегментным регистром.
Директива.ALPHA. Сегменты во внутренней таблице упорядочиваются по алфавиту. Директива.SEQ. Сегменты во внутренней таблице упорядочиваются поcледовательно. Директива по умолчанию.. Директива.GROUP. Добавляет в поименованную группу перечисленные сегменты. Синтакис: Имя GROUP сегмент [, сегмент [ … Упрощенные директивы сегментации. Для простых программ, содержащих по одному сегменту для кода, данных и стека, хотелось бы упростить ее описание. Для этого в трансляторы MASM ввели возможность использования упрощенных директив сегментации. Но здесь возникла проблема, связанная с тем, что необходимо было как-то компенсировать невозможность напрямую управлять размещением и комбинированием сегментов. Для этого совместно с упрощенными директивами сегментации стали использовать директиву указания модели памяти MODEL, которая частично стала управлять размещением сегментов и выполнять функции директивы ASSUME (поэтому при использовании упрощенных директив сегментации директиву ASSUME можно не использовать). Эта директива связывает сегменты, которые в случае использования упрощенных директив сегментации имеют предопределенные имена, с сегментными регистрами (хотя явно инициализировать ds все равно придется). Синтаксис той или иной директивы зависит от используемой версии ассемблера и никак не связан с системой команд процессоров Intel. Разные ассемблеры могут генерировать идентичный машинный коддля системы команд процессоров Intel, но они могут поддерживать совершенно разный набор директив. Директивы модели памяти. Синтаксис директивы MODEL.
Модель памяти. Обязательным параметром директивы MODEL является модель памяти. Этот параметр определяет модель сегментации памяти для программного модуля. В таблице приведены некоторые значения параметра модель памяти директивы MODEL.
Операнды директивы MODEL используют для задания модели памяти, которая определяет набор сегментов программы, размеры сегментов данных и кода, способ связывания сегментов и сегментных регистров. Предполагается, что программный модуль может иметь только определенные типы сегментов, которые определяются упрощенными директивами описания сегментов. Эти директивы приведены в таблице.
Операнд - имя кодового сегмента. Наличие в некоторых директивах параметра [имя] говорит о том, что возможно определение нескольких сегментов этого типа. С другой стороны, наличие нескольких видов сегментов данных обусловлено требованием обеспечить совместимость с некоторыми компиляторами языков высокого уровня, которые создают разные сегменты данных для инициализированных и неинициализированных данных, а также констант. При использовании директивы MODEL транслятор делает доступными несколько идентификаторов, к которым можно обращаться во время работы программы, с тем, чтобы получить информацию о тех или иных характеристиках данной модели памяти. Перечислим эти идентификаторы и их значения.
Операнд - язык. Применяктся в моделях с вызываемыми процедурами, когда вызывающая программа использует код, созданный в вызываемой программе. Операнд служит для того, чтобы компилятор мог правильно организовать интерфейс (связь) между процедурой на ассемблере и программой на языке высокого уровня. Необходимость такого указания возникает вследствие того, что способы передачи аргументов при вызове процедур различны для разных языков высокого уровня. При вызове подпрограммы аргумент загружаются в стек двумя способами: · Слева направо. · Справа налево После обработки стек очищает одна из двух программ: · Вызываемая. · Вызывающая. В таблице представлены данные о передаче аргументов в языках высокого уровня.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 318; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.220 (0.014 с.) |