Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Архитектура вычислительных систем со сверхдлинными командами
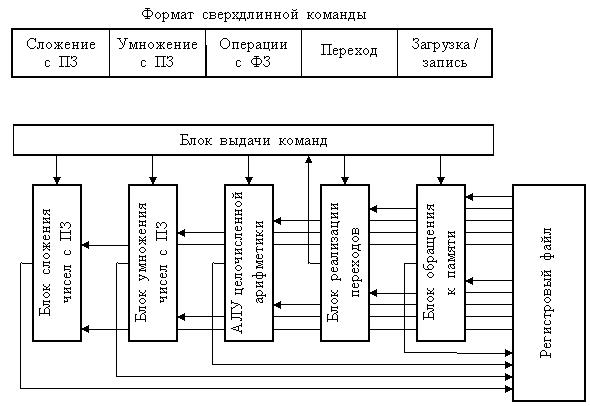
Архитектура с командными словами сверхбольшой длины или со сверхдлинными командами (VLIW - Very Long Instruction Word) известна с начала 80-х годов. VLIW – это набор команд, организованных наподобие горизонтальной микрокоманды в микропрограммном устройстве управления. Идея VLIW базируется на том, что задача эффективного планирования параллельного выполнения нескольких команд возлагается на «разумный» компилятор. Такой компилятор вначале исследует исходную программу с целью обнаружить все команды, которые могут быть выполнены одновременно без возникновения конфликтов. В процессе анализа компилятор может даже частично имитировать выполнение рассматриваемой программы. На следующем этапе компилятор пытается объединить такие команды в пакеты, каждый из которых рассматривается как одна сверхдлинная команда. Объединение нес-кольких простых команд в одну сверхдлинную производится по следующим правилам: · количество простых команд, объединяемых в одну команду сверхбольшой длины, равно числу имеющихся в процессоре функциональных (исполнительных) блоков (ФБ); · в сверхдлинную команду входят только такие простые команды, которые исполняются разными ФБ, т.е. обеспечивается одновременное исполнение всех составляющих сверхдлинной команды. Длина сверхдлинной команды обычно составляет от 256 до 1024 бит. Такая метакоманда содержит несколько полей (по числу образующих ее простых команд), каждое из которых описывает операцию для конкретного функционального блока. На рисунке показан возможный формат сверхдлинной команды и взаимосвязь между ее полями и ФБ, реализующими отдельные операции.
Каждое поле сверхдлинной команды отображается на свой функциональный блок, что позволяет получить максимальную отдачу от аппаратуры блока исполнения команд. VLIW-архитектуру можно рассматривать как статическую суперскалярную архитектуру. Распараллеливание кода производится на этапе компиляции, а не динамически во время исполнения. То, что в выполняемой сверхдлинной команде исключена возможность конфликтов, позволяет предельно упростить аппаратуру VLIW-процессора и добиться более высокого быстродействия. В качестве простых команд, образующих сверхдлинную, обычно используются команды RISC-типа, поэтому архитектуру VLIW иногда называют пост-RISC-архитектурой. Максимальное число полей в сверхдлинной команде равно числу вычислительных устройств и обычно колеблется в диапазоне от 3 до 20. Все вычислительные устройства имеют доступ к данным, хранящимся в едином многопортовом регистровом файле. Отсутствие сложных аппаратных механизмов, характерных для суперскалярных процессоров (предсказание переходов, внеочередное исполнение и т.д.) дает значительный выигрыш в быстродействии и возможность более эффективно использовать площадь кристалла. Подавляющее большинство цифровых сигнальных процессоров и мульти-медийных процессоров с производительностью более 1 млрд операций/с ба-зируется на VLIW-архитектуре. Серьезная проблема VLIW – усложнение регистрового файла и связей этого файла с вычислительными устройствами.
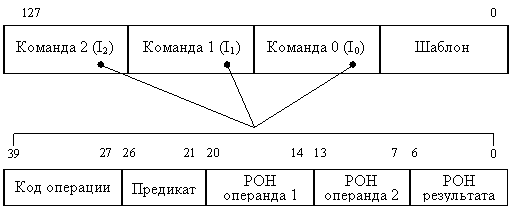
Архитектура IA-64 Дальнейшим развитием идеи VLIW стала новая архитектура IA-64 – совместная разработка фирм Intel и Hewlett-Packard (IA – это аббревиатура от Intel Architecture). В IA-64 реализован новый подход, известный как вычисления с явным параллелизмом команд (EPIC, Explicitly Parallel Instruction Computing) и являющийся усовершенствованным вариантом технологии VLIW. Первым представителем данной стратегии стал микропроцессор Itanium компании Intel. Корпорация Hewlett-Packard также реализует данный подход в своих разработках. В архитектуре IA-64 предполагается наличие в процессоре 128 64-разрядных регистров общего назначения (POH) и 128 80-разрядных регистров с плавающей запятой. Кроме того, процессор IA-64 содержит 64 однобитовых регистра предикатов. Формат команд в архитектуре IA-64:
Рис. 10.2. Формат сверхдлинной команды в архитектуре IA-64 Команды упаковываются (группируются) компилятором в сверхдлинную команду – связку (bundle) длиною в 128 разрядов. Связка содержит три команды и шаблон, в котором указываются зависимости между командами (можно ли с командой I0 запустить параллельно I1, или же I1 должна выполняться только после I0), а также между другими связками (можно ли с командой I2 из связки S0 запустить параллельно команду I3 из связки S1). Перечислим все варианты составления связки из трех команд:
· I0 ║ I1 ║ I2 – все команды исполняются параллельно; · I0 & I1 ║ I2 – сначала I0, затем исполняются параллельно I1 и I2; · I0 ║ I1 & I2 – параллельно обрабатываются I0 и I1, после них – I2; · I0 & I1 & I2 – команды исполняются в последовательности I0, I1, I2. Одна связка, состоящая из трех команд, соответствует набору из трех функциональных блоков процессора. Процессоры IA-64 могут содержать разное количество таких блоков, оставаясь при этом совместимыми по коду. Благодаря тому что в шаблоне указана зависимость и между связками, процессору с N одинаковыми блоками из трех ФБ будет соответствовать сверхдлинная команда из N × 3 команд (N связок). Тем самым обеспечивается масштабируемость IA-64. Поле каждой из трех команд в связке состоит из пяти полей: · 13-разрядного поля кода операции; · 6-разрядного поля предикатов, хранящего номер одного из 64 регистров предиката; · 7-разрядного поля первого операнда (первого источника), где указывается номер регистра общего назначения или регистра с плавающей запятой, в котором содержится первый операнд; · 7-разрядного поля второго операнда (второго источника), где указывается номер регистра общего назначения или регистра с плавающей запятой, в котором содержится второй операнд; · 7-разрядного поля результата (приемника), где указывается номер регистра общего назначения или регистра с плавающей запятой, куда дол-жен быть занесен результат выполнения команды. Предикация – это способ обработки условных ветвлений. Если в исходной программе встречается условное ветвление (по статистике через каждые 6 команд), то команды из разных ветвей помечаются разными регистрами предиката (команды имеют для этого соответствующие поля), далее они выполняются совместно, но их результаты не записываются, пока значения регистров предиката (РП) не определены. Когда вычисляется условие ветвления, РП, соответствующий «правильной» ветви, устанавливается в 1, а другой – в 0. Перед записью результатов процессор проверяет поле предиката и записывает результаты только тех команд, поле предиката которых указывает на РП с единичным значением. Предикаты формируются как результат сравнения значений, хранящихся в двух регистрах. Результат сравнения («Истина» или «Ложь») заносится в один из РП, но одновременно с этим во второй РП записывается инверсное значение полученного результата. Такой механизм позволяет процессору более эффективно выполнять конструкции типа IF-THEN-ELSE. Логика выдачи команд на исполнение сложнее, чем в традиционных процессорах типа VLIW, но намного проще, чем у суперскалярных процессоров с неупорядоченной выдачей. Особенностями архитектуры EPIC являются: · большое количество регистров; · масштабируемость архитектуры до большого количества функциональных блоков, т.е. наследственно масштабируемая система команд (ISIS - Inherently Scaleable Instruction Set); · явный параллелизм в машинном коде. Поиск зависимостей между коман-дами осуществляет не процессор, а компилятор; · предикация – команды из разных ветвей условного предложения снабжаются полями предикатов (полями условий) и запускаются параллельно; · предварительная загрузка – данные из медленной основной памяти загру-жаются заранее. Преимущества технологии VLIW. Использование компилятора позволяет устранить зависимость между командами до того, как они будут реально выполняться, в отличие от суперскалярных процессоров, где такие зависимости приходится обнаруживать и устранять «на лету». Отсутствие зависимостей между командами в коде, сформированном компилятором, ведет к упрощению аппаратных средств процессора и за счет этого к существенному подъёму его быстродействия. Наличие множества функциональных блоков дает возмож-ность выполнять несколько команд параллельно.
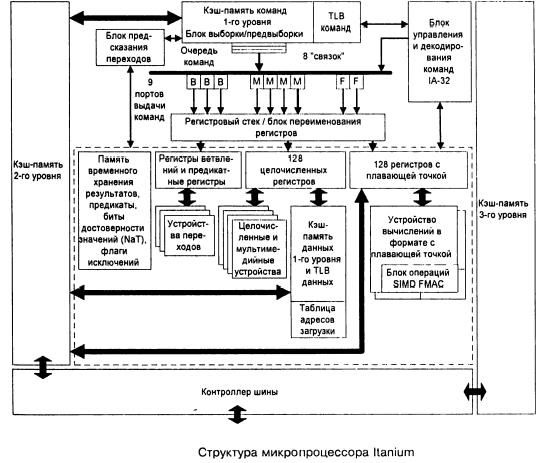
Недостатки технологии VLIW. Требуется новое поколение компиляторов, способных проанализировать программу, найти в ней независимые команды, связать такие команды в строки длиной от 256 до 1024 бит, обеспечить их параллельное выполнение. Компилятор должен учитывать конкретные детали аппаратных средств. При определенных ситуациях программа оказывается недостаточно гибкой. Основные сферы применения. VLIW-процессоры пока еще мало распространены. Основными сферами применения технологии VLIW являются цифровые сигнальные процессоры и вычислительные системы, ориентированные на архитектуру IA-64. Наиболее известной была VLIW-система фирмы Multiflow Computer, Inc. В России VLIW-концепция была реализована в суперкомпьютере Эльбрус 3-1 и получила дальнейшее развитие в его последователе – Эльбрус-2000 (E2k). К VLIW относится и семейство сигнальных процессоров TMS320C6x фирмы Texas Instruments. В начале 2000 года фирма Transmeta заявила процессор Crusoe, представляющий собой программно-аппаратный комплекс. В нем команды микропроцессоров серии х86 транслируются в слова VLIW длиной 64 или 128 бит. Оттранслированные команды хранятся в кэш-памяти, а трансляция при многократном их использовании производится только один раз. Ядро процессора исполняет элементы кода в строгой последовательности. Itanium В чем заключается революционность Itanium? Сама Intel по праву называет Itanium «самой значительной новой разработкой Intel в области микропроцессорной архитектуры с момента выпуска процессора i386 в 1985 году». Революционность состоит в отказе от давно морально устаревшей системы команд x86 (она в ходу с 1978 года) и в радикальном переходе к новой архитектуре, свободной от «пережитков прошлого». Революционной в Itanium является не только 64-разрядность (у 32-разрядных процессоров теоретическое ограничение объема адресуемой оперативной памяти составляет 4 Гбайт, а у 64-битных — несколько терабайт), но и явный параллелизм EPIC (Explicity Parallel Instruction Computing).
По сути, архитектура IA-64 (именно так называется технология, по которой проектируются процессоры Itanium, MсKinley и последующие) впитала в себя все лучшие идеи: VLIW (Very Long Instruction Word, архитектура с длинными командами), устранение ветвлений, улучшенный механизм предварительной подачи данных и пр. Среди характеристик первого процессора архитектуры IA-64 можно также отметить увеличенное адресное пространство, обнаружение и исправление ошибок. В принципе, о силиконовой составляющей процессора Itanium давно уже известно многое. Думаю, что к моменту выхода эта информация будет разниться только в деталях: станет известна точная частота (Intel может, к примеру, выдать не обещанные 800, а все 1000 МГц) и будет определена ценовая политика. Картридж Itanium предназначен для установки в Slot M — комбинированный процессорный разъем, сочетающий достоинства как Socket, так и Slot. Сигнальная матрично-штырьковая часть разведена с силовой частью, по которой подается питание, с тем чтобы исключить помехи. На обратной стороне процессорного картриджа расположена массивная теплоотводная пластина, позволяющая равномерно распределять по всей поверхности процессора ватты, излучаемые в воздух. К тому же сильно нагревающиеся блоки процессора тоже размещены равномерно. Согласно предварительным данным Itanium поддерживает частоту шины памяти 266 МГц. Архитектура Itanium подразумевает использование 2 или 4 Мбайт кэш-памяти третьего уровня. Статическая кэш-память новой конструкции размещена на одной плате с ядром процессора и работает с ним на одинаковой тактовой частоте.
Процессор Itanium, предназначенный для корпоративных серверов и рабочих станций самого высокого класса, не похож ни на одно из изделий, ранее выпущенных фирмой Intel. Разработчики этой модели отказались, наконец, от 32-разрядного набора команд x86, который неизменно реализовывали микросхемы Intel с тех пор, как в 1985 г. дебютировал процессор 386. Itanium построен на базе абсолютно нового 64-разрядного набора команд, известного под названием IA-64. В двух словах, набор команд IA-64 обеспечивает возможность работать с 64-разрядными регистрами и 64-разрядными каналами передачи данных. Главное преимущество такой архитектуры состоит в том, что, поскольку она позволяет использовать 64-разрядные (а не 32-разрядные) адреса для обращения к каждой ячейке памяти, совокупное адресуемое пространство памяти составляет 264 бит (т. е. 18 млрд. Гбайт, или 18 Эбайт). Правда, пока что Itanium не выходит на столь высокие показатели, хотя уже сегодня он обеспечивает возможность обращения к 16 Тбайт памяти (для сравнения: 32-разрядные микросхемы ограничены объемом 4 Гбайт). Ну, а если процессор может работать с такими гигантскими объемами памяти, то он способен лучше справляться с обработкой крупных массивов данных при выполнении таких задач, как добыча информации. Itanium обеспечивает функционирование современных 32-разрядных программ, но в полной мере реализовать заложенные в новой архитектуре преимущества смогут только приложения, специально разработанные для этой платформы. "Приложения большого объема нужно будет перекомпилировать для Itanium, - считает Кевин Круэлл, старший эксперт специализирующейся на рынке ЦП исследовательской фирмы MicroDesign Resources (Саннивейл, шт. Калифорния). - Этот процессор обрабатывает 32-разрядный код просто с черепашьей скоростью".
Многоядерные архитектуры Существуют одно- и многоядерные процессоры с параллельным выполнением некоторых операций, встречаются также системы, в которых несколько процессоров работают над одной задачей параллельно. Рассмотрим сначала одноядерный процессор. «Процессорное ядро» (как правило, для краткости его называют просто «ядро») — это конкретное воплощение (микро)архитектуры (т.е. архитектуры в «аппаратном» смысле), являющееся стандартом для целой серии процессоров. Например, K10 — это микроархитектура, которая лежит в основе многих сегодняшних процессоров AMD: Athlon II, Phenom, Phenom II, Opteron. Микроархитектура задаёт общие принципы: «средний» по длине конвейер, исполнение до трёх команд за такт, предсказание переходов и внеочередное исполнение, и прочие «глобальные» особенности. Ядро — более конкретное воплощение. Например, процессоры микроархитектуры К10 с двумя ядрами, без поддержки многопроцессорности и кэша L3, с шиной HyperTransport частотой в 2 ГГц — это более-менее полное описание ядра Regor для Athlon II. Можно сказать что «ядро» — это конкретное воплощение определённой микроархитектуры «в кремнии», обладающее (в отличие от самой микроархитектуры) набором строго обусловленных характеристик. Микроархитектура — аморфна, она описывает общие принципы построения процессора. Ядро — микроархитектура, «обросшая» всевозможными параметрами и характеристиками. Чрезвычайно редки случаи, когда процессоры сменяли микроархитектуру, сохраняя название. И, наоборот, практически любое наименование процессора хотя бы несколько раз за время своего существования «меняло» ядро. Например, общее название серии процессоров AMD — «Athlon 64» — это одна микроархитектура (K8), но целых 13 ядер — от Sledgehammer (2003) до Huron (2009). Разные ядра, построенные на одной микроархитектуре, могут иметь в том числе разное быстродействие. За последнее десятилетие удельная производительность процессоров в пересчете на число транзисторов упала на один-два порядка. Дальнейшее развитие полупроводниковых технологий не может компенсировать неэффективность современных процессоров. Показатели быстродействия процессоров (в частности, тактовые частоты) достигли практически граничных показателей, плотность энергии увеличивается пропорционально уменьшению размеров транзисторов, и, соответственно, увеличиваются проблемы с теплоотводом. Если нельзя использовать все возможности на одном ядре из-за исключительной сложности такого ядра, то следует пойти по пути увеличения числа ядер. Именно так поступили в Sun Microsystems, выпустив 8-ядерный процессор. Niagara. Сторонники EPIC-подхода также склонились к многоядерному решению. На форуме IDF осенью 2004 года Пол Отеллини, генеральный директор Intel, заявил: Мы связываем наше будущее с многоядерными продуктами; мы верим, что это ключевая точка перегиба для всей индустрии. Можно говорить о двух заметно разнящихся между собой тенденциях в процессе увеличения числа ядер. · Мультиядерность (multi-core). В этом случае предполагается, что ядра являются высокопроизводительными и их относительно немного; сейчас их число — два-четыре. Основных недостатков этого подхода два: первый — высокое энергопотребление, второй — высокая сложность чипа и, как следствие, низкий процент выхода готовой продукции. При производстве 8-ядерного процессора IBM Сell только 20% производимых кристаллов являются годными. · Другой путь — многоядерность (many-core). В таком случае на кристалле собирается на порядок большее число ядер, но имеющих более простую структуру и потребляющих миливатты мощности. Сейчас количество ядер варьируется от 40 до 200, можно ожидать появления процессоров с тысячами и десятками тысяч ядер. Многоядерные процессоры, если все сводится к размещению большего числа простых ядер на одной подложке, нельзя воспринимать как решение всех проблем. Многоядерные процессоры чрезвычайно сложно программировать, они могут быть эффективны только на приложениях, обладающих естественной многопоточностью. IBM предлагает архитектуру Power7, которая приходит на смену Power6, предназначавшейся для Unix-серверов корпорации. Архитектура Power7 является для IBM заметным шагом вперед. От 2 ядерных моделей корпорация переходит к 4, 6 и 8 ядрам, и каждое из них способно выполнять четыре потока команд одновременно. Процессоры Power7 должны выйти в 2010. Они будут изготавливаться по 45-нанометровому технологическому процессу и, как утверждают в IBM, их можно будет устанавливать в нынешних серверах моделей Power 570 и Power 595. Fujitsu представляет 8 ядерный процессор SPARC64 — новую версию 4-ядерного процессора SPARC64 VII. Процессоры SPARC64 используются в серверах Fujitsu и Sun Microsystems. AMD применяет в блейд-серверах процессоры Magny-Cours. Это 12-ядерные процессоры, которые объединяют на одной микросхеме два 6 ядерных процессора, соединенных шиной AMD Hyper Transport. Название им взяли у известной гоночной трассы во Франции. Выход Magny-Cours запланирован на 2010. Intel работает над 8 ядерными двухпоточными процессорами Nehalem-EX, выход которых назначен на 2010. Ожидается появление Tukwila — 4-ядерной версии процессора Itanium. Но вопрос в том, в какой степени современное программное обеспечение — и, следовательно, конечные пользователи — способно использовать возможности многоядерных процессоров. Приложения должны быть написаны так, чтобы решаемые ими задачи можно было разбивать на подзадачи, выполняемые на нескольких ядрах параллельно.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 355; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.221.101.89 (0.037 с.) |