Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Распределение адресного прострастваСодержание книги
Поиск на нашем сайте
Не следует думать, что термины "адресное пространство" и "оперативная память" эквивалентны. Адресное пространство - это просто набор адресов, которые умеет формировать процессор; совсем не обязательно все эти адреса отвечают реально существующим ячейкам памяти. В зависимости от модификации компьютера и состава его периферийного оборудования, распределение адресного пространства может несколько различаться. Тем не менее, размещение основных компонентов системы довольно строго унифицировано. Сегментная структура программ. Обращение к памяти осуществляется исключительно посредством сегментов - логических образований, накладываемых на любые участки физического адресного пространства. Начальный адрес сегмента, деленный на 16, т.е. без младшей шестнадцатеричной цифры, заносится в один из сегментных регистров; после этого мы получаем доступ к участку памяти, начинающегося с заданного сегментного адреса. Каким образом понятие сегментов памяти отражается на структуре программы? Следует заметить, что структура программы определяется, с одной стороны, архитектурой процессора (если обращение к памяти возможно только с помощью сегментов, то и программа, видимо, должна состоять из сегментов), а с другой - особенностями той операционной системы, под управлением которой эта программа будет выполняться. Наконец, на структуру программы влияют также и правила работы выбранного транслятора - разные трансляторы предъявляют несколько различающиеся требования к исходному тексту программы. Имеются 3 сегмента: · сегмент команд с именем code, · сегмент данных с именем data, · сегмент стека с именем stk. Описание каждого сегмента начинается с ключевого слова segment, предваряемого некоторым именем, и заканчивается ключевым словом end, перед которым указывается то же имя, чтобы транслятор знал, какой именно сегмент мы хотим закончить. Имена сегментов выбираются вполне произвольно. Порядок описания сегментов в программе, как правило, не имеет значения. Важно понимать, что в оперативную память компьютера сегменты попадут в том же порядке, в каком они описаны в программе (если специальными средствами ассемблера не задать иной порядок загрузки сегментов в память). Сегменты вводятся в программу с помощью директив ассемблера segment и ends. К директивам ассемблера относятся обозначения начала и конца сегментов segment и ends; ключевые слова, описывающие тип используемых данных (db, dup); специальные описатели сегментов вроде stack и т. д. Директивы служат для передачи транслятору служебной информации, которой он пользуется в процессе трансляции программы. Однако в состав выполнимой программы, состоящей из машинных кодов, эти строки не попадут, так как процессору, выполняющему программу, они не нужны. Другими словами, операторы типа segment и ends не транслируются в машинные коды, а используются лишь самим ассемблером на этапе трансляции программы. При загрузке программы сегменты размещаются в памяти, как показано на рисунке.
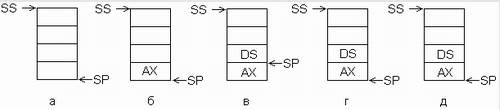
Образ программы в памяти. Образ программы в памяти начинается с сегмента префикса программы (Program Segment Prefics, PSP), образуемого и заполняемого системой. PSP всегда имеет размер 256 байт; он содержит таблицы и поля данных, используемые системой в процессе выполнения программы. Вслед за PSP располагаются сегменты программы в том порядке, как они объявлены в программе. Сегментные регистры автоматически инициализируются следующим образом: · ES и DS указывают на начало PSP (что дает возможность, сохранив их содержимое, обращаться затем в программе к PSP), · CS - на начало сегмента команд, · SS - на начало сегмента стека. В указатель команд IP загружается относительный адрес точки входа в программу (из операнда директивы end), а в указатель стека SP - величина, равная объявленному размеру стека, в результате чего указатель стека указывает на конец стека (точнее, на первое слово за его пределами). Таким образом, после загрузки программы в память адресуемыми оказываются все сегменты, кроме сегмента данных. Инициализация регистра DS в первых строках программы позволяет сделать адресуемым и этот сегмент. Важнейшая особенность архитектуры процессоров Intel - адрес любой ячейки памяти состоит из двух слов, одно из которых определяет расположение в памяти соответствующего сегмента, а другое - смещение в пределах этого сегмента. Сегмент всегда начинается с адреса, кратного 16, т.е. на границе 16-байтового блока памяти (параграфа). Сегментный адрес можно рассматривать, как номер параграфа, с которого начинается данный сегмент. Размер сегмента определяется объемом содержащихся в нем данных, но никогда не может превышать величину 64 Кбайт, что определяется максимально возможной величиной смещения. Сегментный адрес сегмента команд хранится в регистре CS, а смещение к адресуемому байту - в указателе команд IP. Как уже отмечалось, после загрузки программы в IP заносится смещение первой команды программы; процессор, считав ее из памяти, увеличивает содержимое IP точно на длину этой команды (команды процессоров Intel могут иметь длину от 1 до 6 байт), в результате чего IP указывает на вторую команду программы. Выполнив первую команду, процессор считывает из памяти вторую, опять увеличивая значение IP. В результате в IP всегда находится смещение очередной команды, т. е. команды, следующей за выполняемой. Описанный алгоритм нарушается только при выполнении команд переходов, вызовов подпрограмм и обслуживания прерываний. Сегментный адрес сегмента данных обычно хранится в регистре DS, a смещение может находится в одном из регистров общего назначения, например, в ВХ или SI. Стек Стеком называют область программы для временного хранения произвольных данных. Разумеется, данные можно сохранять и в сегменте данных, однако в этом случае для каждого сохраняемого на время данного надо заводить отдельную именованную ячейку памяти, что увеличивает размер программы и количество используемых имен. Удобство стека заключается в том, что его область используется многократно, причем сохранение в стеке данных и выборка их оттуда выполняется с помощью эффективных команд push и pop без указания каких-либо имен. Стек традиционно используется, например, для сохранения содержимого регистров, используемых программой, перед вызовом подпрограммы, которая, в свою очередь, будет использовать регистры процессора "в своих личных целях". Исходное содержимое регистров извлекается из стека после возврата из подпрограммы. Другой распространенный прием - передача подпрограмме требуемых ею параметров через стек. Подпрограмма, зная, в каком порядке помещены в стек параметры, может забрать их оттуда и использовать при своем выполнении. Отличительной особенностью стека является своеобразный порядок выборки содержащихся в нем данных: в любой момент времени в стеке доступен только верхний элемент, т.е. элемент, загруженный в стек последним. Выгрузка из стека верхнего элемента делает доступным следующий элемент. Элементы стека располагаются в области памяти, отведенной под стек, начиная со дна стека (т.е. с его максимального адреса) по последовательно уменьшающимся адресам. Адрес верхнего, доступного элемента хранится в регистре-указателе стека SP. Как и любая другая область памяти программы, стек должен входить в какой-то сегмент или образовывать отдельный сегмент. В любом случае сегментный адрес этого сегмента помещается в сегментный регистр стека SS. Таким образом, пара регистров SS:SP описывают адрес доступной ячейки стека: в SS хранится сегментный адрес стека, а в SP - смещение последнего сохраненного в стеке данного (рис. а). Обратите внимание на то, что в исходном состоянии указатель стека SP указывает на ячейку, лежащую под дном стека и не входящую в него.
Состояния стека: · а - исходное состояние, · б - после загрузки одного элемента (в данном примере - содержимого регистра АХ), · в - после загрузки второго элемента (содержимого регистра DS), · г - после выгрузки одного элемента, · д - после выгрузки двух элементов и возврата в исходное состояние. Загрузка в стек осуществляется специальной командой работы со стеком push (протолкнуть). Эта команда сначала уменьшает на 2 содержимое указателя стека, а затем помещает операнд по адресу в SP. Если, например, мы хотим временно сохранить в стеке содержимое регистра АХ, следует выполнить команду push АХ Стек переходит в состояние, показанное на рис. б. Видно, что указатель стека смещается на два байта вверх (в сторону меньших адресов) и по этому адресу записывается указанный в команде проталкивания операнд. Следующая команда загрузки в стек, например, push DS переведет стек в состояние, показанное на рис. в. В стеке будут теперь храниться два элемента, причем доступным будет только верхний, на который указывает указатель стека SP. Если спустя какое-то время нам понадобилось восстановить исходное содержимое сохраненных в стеке регистров, мы должны выполнить команды выгрузки из стека pop (вытолкнуть): pop DS pop AX Состояние стека после выполнения первой команды показано на рис. г, а после второй - на рис. д. Для правильного восстановления содержимого регистров выгрузка из стека должна выполняться в порядке, строго противоположном загрузке - сначала выгружается элемент, загруженный последним, затем предыдущий элемент и т.д. Совсем не обязательно при восстановлении данных помещать их туда, где они были перед сохранением. Например, можно поместить в стек содержимое DS, а извлечь его оттуда в другой сегментный регистр - ES; push DS pop ES; Теперь ES=DS, а стек пуст Это распространенный прием для перенесения содержимого одного регистра в другой, особенно, если второй регистр - сегментный. Обратите внимание на то, что после выгрузки сохраненных в стеке данных они физически не стерлись, а остались в области стека на своих местах. Правда, при "стандартной" работе со стеком они оказываются недоступными. Действительно, поскольку указатель стека SP указывает под дно стека, стек считается пустым; очередная команда push поместит новое данное на место сохраненного ранее содержимого АХ, затерев его. Однако пока стек физически не затерт, сохраненными и уже выбранными из него данными можно пользоваться, если помнить, в каком порядке они расположены в стеке. Этот прием часто используется при работе с подпрограммами. Какого размера должен быть стек? Это зависит от того, насколько интенсивно он используется в программе. Если, например, планируется хранить в стеке массив объемом 10 000 байт, то стек должен быть не меньше этого размера. При этом надо иметь в виду, что в ряде случаев стек автоматически используется системой, в частности, при выполнении команды прерывания int 21h. По этой команде сначала процессор помещает в стек адрес возврата, а затем операционная система отправляет туда же содержимое регистров и другую информацию, относящуюся к прерванной программе. Поэтому, даже если программа совсем не использует стек, он все же должен присутствовать в программе и иметь размер не менее нескольких десятков слов, например, 128 слов. Математический сопроцессор Семейство процессоров IA-32 содержит так называемый модуль операций с ПТ {FPU - Floating-Point Unit), который используется исключительно для быстрого выполнения этого типа операций. В процессорах Intel386 этот блок был реализован в виде отдельной микросхемы математического сопроцессора, которая обозначалась как InteI387. Однако, начиная с процессоров Intel486, математический сопроцессор стал находиться на одном кристалле с основным процессором. В модуле FPU содержится 8 внутренних регистров для хранения данных с ПТ, которые называются ST(0), ST(1), ST(2), ST(3), ST(4), ST(5), ST(6) и ST(7). Они образуют стек сопроцессора Остальные регистры, выполняющие функции управления и хранящие указатели, показаны на рисунке.
Другие регистры. В этом разделе мы просто упомянем о двух других наборах регистров, которые используютсядля поддержки мультимедийных приложений. · Восемь 64-разрядных регистров, использующихся в так называемых ММХ-командах. · Восемь 128-разрядных ХММ-регистров, использующихся при выполнении потоковой обработки данных (SIMD-операций), т.е. когда с помощью одной машинной команды можно выполнить одну и ту же операцию над несколькими данными (Single-Instruction, Multiple-Data, или SIMD). MMX-технология MMX = Multi-Media eXtension – мульти-медиа расширение. Технология MMX - итог совместной работы создателей архитектуры микропроцессоров Intel и программистов. При ее разработке был исследован широкий круг программ аудиовизуальной обработки информации: обработка изображений, MPEG-видео, синтеза музыки, сжатия речи и ее распознавания, поддержка видеоконференций, компьютерные игровые программы и т. д. В результате этого анализа были выявлены основные особенности таких программ: · использование данных целого типа небольшой разрядности, например, 8-разрядные графические пиксели и 16-разрядная оцифровка звука; · короткие циклы с высокими коэффициентами повторяемости; · большое количество операций умножения и суммирования, в том числе из-за широкого использования быстрого преобразования Фурье; · применение алгоритмов, требующих интенсивных вычислений; · широкое использование операций с высоким уровнем параллелизма. Было отмечено, что в мультимедийных приложениях 80% времени выполнения программы приходится на 10-20% программного кода. Малая разрядность данных требует дополнительных действий при их обработке на 32-разрядном микропроцессоре, не позволяя в то же время использовать всю мощь 32-разрядной архитектуры. Простым и наглядным примером такого рода обработки может служить изменение значений всех пикселей видеопамяти на определенную величину. Пусть емкость видеопамяти составляет 1 Мбайт, а каждый пиксель кодируется 1 байтом. Тогда для выполнения указанного действия потребуется выполнить примерно 1 млн операций по прибавлению константы к однобайтовому операнду, который выбирается из памяти. Одновременное выполнение таких действий над 4 операндами, что сократило бы количество операций в 4 раза, невозможно в классической архитектуре IA-32 из-за отсутствия соответствующих команд в системе команд и форматов используемых данных. На устранение этих противоречий и были направлены основные усилия разработчиков технологии MMX. Процессор Pentium MMX, в котором впервые была реализована новая технология, был представлен фирмой INTel в январе 1997 года. Он позволил на 10-20 % повысить производительность на стандартных тестах, а для специализированных мультимедийных приложений - на 50 %. Главной особенностью MMX-технологии является новый принцип обработки информации - обработка по схеме SIMD (Single Instruction Multiple Data) - один поток команд, много потоков данных. Этот вид обработки подразумевает, что с помощью одной команды одна и та же операция выполняется сразу над несколькими операндами, например, производится суммирование нескольких пар слагаемых. Такой подход требует поддержки как со стороны системы команд и форматов данных, так и на аппаратном уровне. Расширение MMX ориентировано в основном на использование в мультимедийных приложениях. Основная идея MMX заключается в одновременной обработке нескольких элементов данных за одну инструкцию. Для этого используются 64-битные регистры MMX, в которых размешается несколько данных меньшего размера. Расширение MMX использует новые типы упакованных данных: Packed byte - упакованные байты (восемь байт).
Packed word - упакованные слова (четыре слова).
Packed doubleword - упакованные двойные слова (два двойных слова).
Packed quadword - учетверенное слово.
Расширение MMX включает 8 регистров общего пользования (MM0-MM7). Размер регистров составляет 64 бита. Физически эти регистры пользуются младшими битами рабочих регистров сопроцессора. Команды MMX "портят" регистр состояния и регистр тэгов. По этой причине совместное использование команд MMX и команд сопроцессора может вызвать определенные трудности. Другими словами, перед каждым использованием команд MMX Вам придется сохранять контекст сопроцессора, а это может весьма замедлить работу программы. Важно отметить также, что команды MMX работают непосредственно с регистрами сопроцессора, а не с указателями на элементы стека.
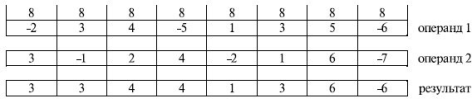
Важное правило, которое следует соблюдать при совместном использовании математического сопроцессора и MMX-расширения: последней выполняемой командой MMX-расширения должна быть команда EMMS. Дело в том, что все ММХ-команды выполняются в том же режиме, что и команды сопроцессора с плавающей точкой, что вызывает изменения содержимого регистра состояния (swr) сопроцессора. Команда EMMS обеспечивает корректный переход процессора от выполнения фрагмента программного кода с ММХ-командами к обработке обычных команд с плавающей точкой. При этом emms устанавливает значение 1 во всех разрядах регистра состояния. Если фрагмент программы, в,котором есть ММХ-команды, не заканчивается командой emms, то все последующие операции с плавающей точкой будут давать некорректные результаты, о чем сигнализирует исключение Stack overflow. В систему команд MMX были включены 57 новых инструкций. Их использование было призвано, во-первых, уменьшить время выполнения мультимедийных приложений, а во-вторых, минимизировать конфликты в конвейере, который становился все более многоступенчатым, что приводило к существенным потерям в производительности из-за конфликтов. Проиллюстрируем это на примере нескольких команд. Команда PADDSB "Сложение со знаком с насыщением" выполняет сложение одновременно 8 пар однобайтовых операндов. Кроме того, если при выполнении сложения произошло переполнение, то результатом операции будет максимально возможное в этом формате число. Это избавляет программиста от необходимости использования после выполнения каждого сложения команд условных переходов, анализирующих признак переполнения результата, что, в свою очередь, благотворно сказывается на работе конвейера.
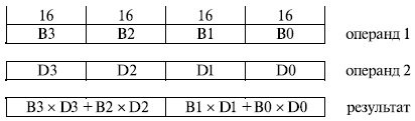
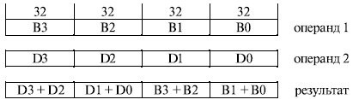
Команда PMADDWD "Умножение с накоплением" эффективна при выполнении вычислений, характерных для обработки звуковой и графической информации. Она одновременно перемножает четыре операнда формата "слово" (16 разрядов), попарно складывает результаты умножений двух младших и двух старших байт и получает два 32-разрядных результата.
Команда PMAXSB выполняет нахождение максимума одновременно для восьми 8-разрядных операндов. Она позволяет не только выполнить операцию пакетами по 8 байт, но и избежать ветвлений, а следовательно, и "штрафов" за их неправильное предсказание.
XMM технология Технология MMX получила свое развитие в микропроцессоре Pentium III с появлением специального аппаратного блока SSE (Streaming SIMD Extension - потоковое SIMD-расширение) обработки информации по схеме SIMD. Новая технология получила название XMM (eXtended Multi-Media). Блок SSE содержит отдельный регистровый файл из восьми 128-разрядных регистров XMM, что позволяет обрабатывать по схеме SIMD числа с плавающей запятой (четыре 32-разрядных числа).
Числа с плавающей запятой имеют следующий формат: · знак: 1 разряд; · порядок (смещенный): 8 разрядов; · мантисса: 23 разряда. Расширено и количество форматов чисел с фиксированной точкой, обрабатываемых в XMM по схеме SIMD: · 16 операндов х 8 разрядов; · 8 операндов х 16 разрядов; · 4 операнда х 32 разряда; · 2 операнда х 64 разряда. Для обработки чисел новых форматов в систему команд дополнительно введены 70 новых команд. Блок SSE2, включенный в микропроцессор Pentium 4, реализует 144 новые команды. Из этих 144 инструкций 68 расширяют возможности старых SIMD-инструкций по работе с целыми числами, а 76 являются совершенно новыми. Среди последних - инструкции, позволяющие оперировать со 128-разрядными числами (как целыми, так и вещественными с двойной точностью). Операции SSE2 позволили существенно повысить эффективность применения микропроцессора при реализации трехмерной графики и современных интернет-приложений, обеспечении сжатия и кодирования аудио- и видеоданных и ряда других применений. В результате производительность процессора Pentium 4 при выполнении таких операций стала вдвое выше, чем Pentium III. Отметим несколько новых по сравнению с MMX инструкций, вошедших в состав команд SSE/SSE2. Команда ADDSUBPS выполняет сложение второго и четвертого элементов с одинарной точностью с одновременным вычитанием первого и третьего элементов. Эта инструкция полезна при работе с комплексными числами в случае использования соответствующего типа переменных. Команда HADDPS осуществляет горизонтальное сложение элементов с одинарной точностью. Первый результат является суммой первого и второго элементов первого (исходного) операнда; второй результат - суммой третьего и четвертого элементов первого операнда; третий результат - суммой первого и второго элементов второго операнда (операнда назначения) и, наконец, четвертый результат - суммой третьего и четвертого элементов второго операнда.
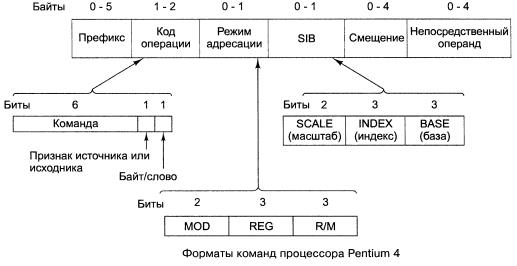
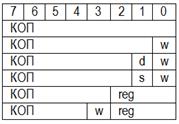
Новые возможности в этом направлении обработки информации были обеспечены в технологии SSE3, внедренной в ядре Prescott процессора Pentium 4 добавлением набора из 13 инструкций, и в технологии SSE4 в микропроцессорах семейства INTel Core 2 Duo. Система команд Формат команды Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Под каждую команду в системной памяти процессора прошиты подпрограммы их выполнения. Ассемблер, анализируя исходник проекта, в сегменте кода, заменяет предложения исходника на эти подпрограммы. Каждая команда содержит элементы, определяющие: · Код операции (КОП) описывает, что делать. Значение в поле КОП определяет в блоке микропрограммного управления подпрограмму, реализующую действия для данной команды. · Операнды описывают объекты, с которыми нужно что-то делать. Операнды в команде могут и не задаваться, а подразумеваться по умолчанию. · Типы операндов описывают, как делать, обычно задаются неявно. Правила кодирования команд называются форматом команд. Команды процессоров архитектуры IA-32 считаются сложными. Максимальная длина машинной команды IA-32 составляет 15 байт. Реальная команда может содержать гораздо меньшее количество полей, вплоть до одного — только КОП. Приведенный на рисунке формат машинной команды является самым общим.
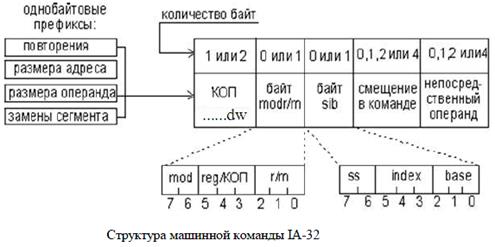
Опишем назначения полей машинной команды. Префиксы. Необязательные элементы машинной команды, каждый из которых состоит из одного байта или может отсутствовать. В памяти префиксы предшествуют команде. Назначение префиксов — модифицировать операцию, выполняемую командой. Прикладная программа может использовать следующие типы префиксов: · Префикс замены сегмента. В явной форме указывает, какой сегментный регистр используется в данной команде для адресации стека или данных. Префикс отменяет выбор сегментного регистра по умолчанию. Префиксы замены сегмента имеют следующие значения: · 2eh –замена сегмента CS. · 36h –замена сегмента SS. · 3eh –замена сегмента DS. · 26h –замена сегмента ES. · 64h –замена сегмента FS. · 65h –замена сегмента GS. · Префикс разрядности адреса уточняет разрядность адреса (32 или 16-разрядный). Каждой команде, в которой используется адресный операнд, ставится в соответствие разрядность адреса этого операнда. Этот адрес может иметь разрядность 16 или 32 бит. Это смещение называется эффективный адрес. Если разрядность адреса 32 бит, это означает, что команда содержит 32-разрядное смещение, оно соответствует 32-разрядному смещению адресного операнда относительно начала сегмента и по его значению формируется 32-битное смещение в сегменте. С помощью префикса разрядности адреса можно изменить действующее по умолчанию значение разрядности адреса. Это изменение будет касаться только той команды, которой предшествует префикс. · Префикс разрядности операнда аналогичен префиксу разрядности адреса, но указывает на разрядность операндов (32 или 16-разрядные), с которыми работает команда. В соответствии с какими правилами устанавливаются значения атрибутов разрядности адреса и операндов по умолчанию? · Префикс повторения используется с цепочечными командами (командами обработки строк). Этот префикс “зацикливает” команду для обработки всех элементов цепочки. Система команд поддерживает два типа таких префиксов: безусловные (rep — 0f3h), заставляющие повторяться цепочечную команду некоторое количество раз; условные (repe/repz — 0f3h, repne/repnz — 0f2h), которые при зацикливании проверяют некоторые флаги, и в результате проверки возможен досрочный выход из цикла Код операции. Обязательный элемент, описывающий операцию, выполняемую командой. Многим командам соответствует несколько кодов операций, каждый из которых определяет нюансы выполнения операции. Поле кода операции не имеет однозначной структуры. В зависимости от конкретных команд оно может иметь в своем составе от 1 до 3 элементов. Один из этих трех элементов является непосредственно кодом операции или ее частью, остальные уточняют детали операции. Дополнительные биты поля КОП: · Поле reg (3-бита) определяют регистр, используемый в команде. · Бит d задает направление передачи данных: при 0 из регистра reg, при 1 в регистр reg, · Бит s задает необходимость расширения 8-битового непосредственного операнда ло 16 или 32 бита · Бит w определяет размер данных, которыми оперирует команда: байт, слово, двойное слово: при 0 — 8 битов; при 1 — 16 битов для 16-разрядного размера операндов или 32 бита для 32-разрядного размера операндов. Однобайтовые КОП.
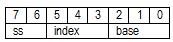
Последующие поля машинной команды определяют местоположение операндов, участвующих в операции, и особенности их использования. Рассмотрение этих полей связано со способами задания операндов в машинной команде и потому будет выполнено позже. Байт режима адресации modr/m. Иногда называется постбайтом, Значения этого байта определяет используемую форму адреса операндов. Операнды могут находиться в памяти в одном или двух регистрах. Если операнд находится в памяти, то байт modr/m определяет компоненты (смещение, базовый и индексный регистры), используемые для вычисления его эффективного адреса. Байт modr/m состоит из трех полей: · Поле mod определяет количество байт, занимаемых в команде адресом операнда, поле смещение в команде).Поле mod используется совместно с полем r/m, которое указывает способ модификации адреса операнда смещение в команде. · Поле reg/КОП определяет либо регистр, находящийся в команде на месте первого операнда, либо возможное расширение кода операции; · Поле r/m используется совместно с полем mod и определяет либо регистр, находящийся в команде на месте первого операнда (если mod = 11), либо используемые для вычисления эффективного адреса (совместно с полем смещение в команде) базовые и индексные регистры. Байт масштаб-индекс-база sib (Scale-Index-Base ) используется для расширения возможностей адресации операндов. На наличие байта sib в машинной команде указывает сочетание одного из значений 01 или 10 поля mod и значения поля r/m= 100. Байт sib состоит из трех полей: · Поле масштаба ss. В этом поле размещается масштабный множитель для индексного компонента index, занимающего следующие три бита байта sib. В поле ss может содержаться одно из следующих значений: 1, 2, 4, 8. При вычислении эффективного адреса на это значение будет умножаться содержимое индексного регистра. · Поле index — используется для хранения номера индексного регистра, который применяется для вычисления эффективного адреса операнда; · Поле base — используется для хранения номера базового регистра, который также применяется для вычисления эффективного адреса операнда. Напомню, что в качестве базового и индексного регистров могут использоваться практически все регистры общего назначения.
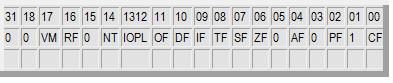
Поле смещения в команде. 8, 16 или 32-разрядное целое число со знаком, представляющее собой, полностью или частично (с учетом вышеприведенных рассуждений), значение эффективного адреса операнда. Поле непосредственного операнда. Необязательное поле, представляющее собой 8, 16 или 32-разрядный непосредственный операнд. Наличие этого поля, конечно, отражается на значении байта modr/m. Для описания команд приняты обозначения: · Структура регистра флагов eflags:
В нижней строке этой таблицы приводятся значения флагов после выполнения команды: · 1 — после выполнения команды флаг устанавливается (равен 1); · 0 — после выполнения команды флаг сбрасывается (равен 0); · r — значение флага зависит от результата работы команды; ·? — после выполнения команды флаг не определен; · пробел — после выполнения команды флаг не изменяется; Для представления операндов в синтаксических диаграммах используются следующие обозначения: · r8, r16, r32 — операнд в одном из регистров размером байт, слово или двойное слово; · m8, m16, m32, m48 — операнд в памяти размером байт, слово, двойное слово или 48 бит; · i8, i16, i32 — непосредственный операнд размером байт, слово или двойное слово; · a8, a16, a32 — относительный адрес (смещение) в сегменте кода. · На многих диаграммах в целях компактности возможные сочетания операндов показаны в виде следующей конструкции:
Конструируя команду на основе подобной синтаксической диаграммы, вы должны помнить о соответствии типов. В подобной диаграмме допустимы только следующие сочетания: "r8, m8", "r16, m16", "r32, m32". Например, сочетание "r8, m16" недопустимо. Однако есть единичные случаи, когда подобные сочетания возможны; тогда они специально оговариваются. Описанная в данном приложении система команд в полном объеме поддерживается микропроцессором Pentium. Предыдущие модели микропроцессора могут не поддерживать отдельные команды. Чтобы прояснить этот момент, мы будем указывать в примерах для каждой команды директиву типа.286. Это будет означать, что описываемая команда поддерживается всеми моделями микропроцессора, начиная с i286. Если ничего не указывается, то это означает, что данная команда работает на всех моделях микропроцессоров Intel, начиная с i8086/8088. Классификация команд Имеются наборы команд для разных узлов процессора: · Целочисленный процессор. · Арифметический сопроцессор с плавающей точкой. · Целочисленное MMX расширение. · XMM расширение с плавающей точкой, 70 команд.. Целочисленный процессор Команды общего назначения.
Команды ввода-вывода.
|
||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 321; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.219.221 (0.018 с.) |