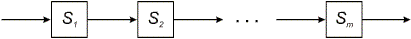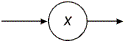Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение программы грамматического разбора для заданного синтаксиса.Содержание книги
Поиск на нашем сайте
Программу, которая распознает какой-либо язык, легко построить на основе его детерминированного синтаксического графа (если таковой существует). Этот граф фактически представляет собой блок-схему программы, при ее разработке рекомендуется строго следовать правилам преобразования, подобным тем, с помощью которых можно предварительно получить из БНФ графическое представление синтаксиса. Применение данных правил предполагает наличие основной программы, содержащей процедуры, которые соответствуют различным подцелям, а также процедуру перехода к очередному символу. Для простоты мы будем считать, что предложение, которое нужно анализировать, представлено входным файлом input и что терминальные символы – отдельные значения типа char. Пусть символьная переменная char ch всегда содержит очередной читаемый символ. Тогда переход к следующему символу выражается оператором: ch = fgetc(input); Следует отметить, что функция char fgetc(FILE *fp) является стандартной функцией языка Си для чтения символа из файла и для ее использования необходимо в начале программы подключить соответствующий заголовочный файл директивой #include <stdio.h> Основная программа будет состоять из оператора чтения первого символа, за которым следует оператор активации основной цели грамматического разбора. Отдельные процедуры, соответствующие целям грамматического разбора или графам, получаются по следующим правилам. Пусть оператор, полученный с помощью преобразования графа S, обозначается через T (S). Правила преобразования графа в программу. В1. Свести систему графов к как можно меньшему числу отдельных графов с помощью соответствующих подстановок. В2. Преобразовать каждый граф в описание процедуры в соответствии с приведенными ниже правилами В3-В7. В3. Последовательность элементов
переводится в составной оператор { T(S1); T(S2); ...; T(Sn) } В4. Выбор элементов
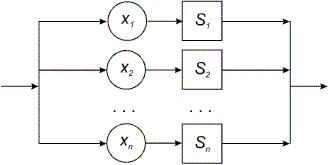
переводится в условный оператор if(belongsTo(ch, L1)) T(S1); else if(belongsTo(ch, L2)) T(S2); else... if(belongsTo(ch, Ln)) T(Sn); else error(); где L i означает множество начальных символов конструкции S i (L i = first (S i)), а функция belongsTo(ch, Li) возвращает истинное значение, если символ ch принадлежит соответствующему множеству начальных символов L i и ложное значение в противном случае.
В5. Цикл вида
переводится в оператор while(belongsTo(ch, L)) T(S); где T(S) есть отображение S в соответствии с правилами В3-В7, а L есть множество L = first(S). В6. Элемент графа, обозначающий другой граф A
переводится в оператор обращения к функции A(). В7. Элемент графа, обозначающий терминальный символ
переводится в оператор if(ch == ’x’) ch = fgetc(input); else error(); где error() – функция, к которой обращаются при появлении неправильной конструкции. Теперь покажем применение этих правил на примере преобразования редуцированного графа (см. рис.9.2) в программу грамматического разбора. char ch; void A() { if(ch == 'x') ch = fgetc(input); else if(ch == '(') { ch = fgetc(input); A(); while(ch == '+') { ch = fgetc(input); A(); } if(ch == ')') ch = fgetc(input); else error(); } else error(); } void main(int argc, char **argv) { ch =fgetc(input); A(); } При этом преобразовании свободно применялись некоторые очевидные правила программирования, позволяющие упростить программу. Например, при буквальном переводе четвертая строка имела бы вид: if(ch == 'x') if(ch == 'x') ch = fgetc(input); else error(); else... Ясно, что ее можно сократить, как это сделано в программе. Операторы чтения в восьмой и двенадцатой строках тоже получены с помощью такого же упрощения. По-видимому, полезно определить, когда вообще возможны подобные упрощения, и показать это непосредственно в виде графов. Два основных случая покрываются следующими дополнительными правилами: В4а.
if(ch == 'x1') { ch = fgetc(input); T(S1); } else if(ch == 'x2') { ch = fgetc(input); T(S2); } else ... if(ch = 'xn') { ch = fgetc(input); T(Sn); } else error(); В5а.
while(ch == 'x') { ch = fgetc(input); T(S); } Кроме того, часто встречающуюся конструкцию ch = fgetc(input); T(S); while(W) { ch = fgetc(input); T(S); } можно, разумеется, выразить короче: do { ch = fgetc(input); T(S); } while(W); Мы намеренно не описываем пока функцию error ("ошибка"). Поскольку сейчас нас интересует лишь, как определить, правильно ли входное предложение, мы можем считать, что эта процедура заканчивает работу программы. На практике в случае появления неправильных конструкций нужно организовать корректную их диагностику, что будет рассмотрено далее.
|
|||||
|
|
Последнее изменение этой страницы: 2016-08-14; просмотров: 372; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.195.236 (0.01 с.) |