
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Превращение информации в ресурсСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Превращение информации в ресурс Развитие человеческого общества проходило неразрывно с формированием и накоплением знаний. Первые знания передавались устно из поколения в поколение, т.е. человеческая речь явилась первым носителем информации, отражающей накапливаемы знания. 3. Накопление данных. Начальным источником любой информации является объект реального мира. За счет процесса отражения наблюдатель выявляет характеристики этого объекта, которые и составляют основу информации. Процесс отражения может протекать естественным образом путем наблюдения либо с использованием современной методологии, основанной на широком применении методов математического моделирования и вычислительного эксперимента. При математическом моделировании исходный объект заменяется математической моделью и процесс отражения реализуется как изучение математической модели с помощью вычислительно-логических алгоритмов на компьютере. Математическая модель может быть проиграна в любых реальных и нереальных условиях. Независимо от характера эксперимента непосредственно либо опосредованно наблюдатель пытается оценить характеристики объекта, как проявление его свойств во времени. Эти характеристики находят свое отражение в информации, которая далее накапливается и затем подвергается преобразованию. В ЭВМ информация хранится и перерабатывается в некоторой символьной форме – форме данных. Под данными понимаются факты и идеи, представленные в формализованном виде, который позволяет передавать и обрабатывать эти факты и идеи с помощью соответствующих технических и программных средств. Т.е. при вводе информации в компьютер реализуется процесс преобразования информации в данные. Если данные нужно преобразовать в информацию, их необходимо актуализировать и придать им смысловое содержание. Данные имеют определенный жизненный цикл актуального существования, который в обобщенном виде можно представить следующей схемой. Цикл начинается с процесса формирования данных, т.е. преобразования информации в формализованный вид, затем осуществляется запись данных на носитель и после этого хранение данных. Следующие этапы – поиск требуемых данных, оценка данных с точки зрения их старения и содержательности. Большое значение имеют экономические аспекты хранения данных: стоимость хранения должна быть соизмерима с их ценностью. Поэтому необходимо регулярно выполнять следующие этапы: сортировку данных, обработку в соответствии с реальными вычислительными задачами, синтез данных – получение новых данных на основе объединения отдельных элементов и анализа, воспроизведение данных в удобной для использования форме, т.е преобразования их в информацию, необходимую для принятия решений. При потере актуальности данные удаляются.
Все этапы в автоматизированной информационной системе (АИС) реализуются с использованием разных методов и подходов. Например, формирование данных на базе ССОД (систем сбора и обработки данных) или непосредственного ввода документов.
Формирование знаний Для ЛПР данные должны предоставляться в виде информации, на основе которой могут быть приняты решения и определенные действия. Информационное обеспечение ППР выполняет АИС, которая использует имеющийся информационный ресурс. В настоящее время сформировалось новое научное направление, в котором рассматриваются различные методы и способы формирования знаний на основе данных, получения новых знаний на основе имеющихся информационных ресурсов в АИС. Различные виды знаний (конструктивные, процедурные или алгоритмические, понятийные или системные, фактографические (Фактографическая информация - результаты измерений, описаний и иного способа фиксирования в чистом виде, поддающиеся метрологическому анализу, аналогично результатам экспериментов.) хранятся в БД и БЗ АИС. Для их создания используется также математическое моделирование и вычислительный эксперимент. В этом случае исключается трудоемкий натурный эксперимент и реализуется подход “ модель-алгоритм-программа ”. Концептуальная модель АИС, включающая в себя фактографические, понятийные и конструктивные знания, является основой для формирования алгоритмической модели, которая базируется на процедурные знания. Реализация алгоритмической модели – это создание программного обеспечения. Цепь “ модель-алгоритм-программа ” – это путь получения новой информации: вместо объекта используется модель, на основе модели создается алгоритм получения характеристик объекта и программно реализуется этот процесс.
Современные ИТ позволяют по новому организовать информационный процесс как на стадии получения новой информации, так и на стадии использования информационного ресурса для управления объектом. Непрерывно происходит преобразование информации в данные, данных – в информацию и новые знания. Информационные ресурсы концентрируются в БД, БЗ, ХД (Хранилище Данных). Эффективность формирования и использования информационного ресурса зависит от решения проблемы представления информации в этих базах, составляющих основу АИС. Существуют следующие методы интеллектуального анализа данных для получения новых знаний и построения ХД, содержащих обобщенные показатели. Поиск ассоциаций. Ассоциации как привязка значений к какому-либо одному событию или выявление взаимосвязей в данных. Поиск последовательностей. Поиск последовательных во времени событий. Поиск скрытых закономерностей. Определяются причинно-следственные связи между значениями определенных косвенных параметров исследуемого объекта (ситуации, процесса) и распознаваемым свойством. Оценка важности (влияния) параметров на события и ситуации. Известно, что на наступление некоторого события или ситуации влияет некоторый набор параметров. Необходимо оценить степень этого влияния для перечисленных параметров. Классификация. Рассматривается конечное число классов объектов, которыми могут быть, в том числе, события, ситуации или процессы. Объекты должны быть описаны количественными значениями свойств. Классы описаны с помощью набора объектов, принадлежность которых данному классу априорно известна. Требуется найти критерии, по которым можно было бы отнести объект к тому или иному классу. Кластеризация. Кластеризация напоминает классификацию, за тем исключением, что критерии классификации не заданы. Прогнозирование. Оценка состояния объектов на основе ретроспективного анализа их свойств. По истории развития объекта управления определяются обобщенные показатели на некоторое время вперед.
Свойства и назначение ХД Концепция ХД получила развитие вследствие желания конечных пользователей (ЛПР) иметь непосредственный единообразный доступ к необходимым им данным, источники происхождения которых организационно и территориально распределены, а анализ может повысить эффективность генерации ППР. В этом контексте наиболее актуальной проблемой является обеспечение интегрированного представления о сложном ОУ в целом, комплексного анализа собранных о нем сведений и извлечения из огромного объема детализированных данных некоторой полезной информации – знаний о закономерностях его развития. Поддержка принятия управленческих решений на основе накопленной информации может осуществляться в трех основных областях: 1. Область детализированных данных. Это сфера действия большинства оперативных, или транзакционных систем (OLTP – On Line Transaction Procession), нацеленных на поиск детальной информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами. 2. Область агрегированных показателей. Комплексный взгляд на собранную в ХД информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP- On Line Analytical Procession). Здесь можно или ориентироваться на специальные многомерные СУБД, или (как правило, предпочтительнее) оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в специальной БД, либо агрегация информации может производиться в процессе обработки детализированных таблиц реляционной БД в интерактивном режиме.
3. Область закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (Data Mining), главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или (с определенной вероятностью) прогнозируют развитие рассматриваемых процессов. Предметом концепции ХД служат непосредственно данные. После того, как традиционная система обработки данных (СОД) реализована и начинает функционировать, она становится неотъемлемой частью производственного процесса. Данные, которые являются одним из конечных продуктов деятельности СОД, обладают такими же характеристиками, что и любой промышленный продукт: сроком годности, местом складирования (хранения), совместимостью с данными из других производств (СОД), рыночной стоимостью, транспортабельностью, комплектностью, ремонтопригодностью. Для обеспечения выполнения большой частоты аналитических запросов и эффективной обработки огромных массивов информации могут быть использованы различные технологии представления данных, отличные от классического реляционного представления. В отличие от БД в традиционных OLTP-системах, где данные подобраны в соответствии с конкретными приложениями, информация в ХД ориентирована на задачи принятия решений и представляется в виде обобщенных или агрегированных данных – знаний о поведении объекта управления. Для пользователя OLAP-системы требуются метаданные, по крайней мере, следующих типов: - описание структур данных, их взаимосвязей; - информация о хранимых в ХД и поддерживаемых им агрегатах данных; - информация об источниках данных и о степени их достоверности. Одна и та же информация могла попасть в ХД из разных источников. Пользователь должен иметь возможность узнать, какой источник был выбран основным, каким образом производились согласование и очистка данных; - информация о периодичности обновлений данных. Желательно знать не только то, какому моменту времени соответствуют интересующие его данные, но и когда они в следующий раз будут обновлены;
- информация о владельцах данных. Пользователю OLAP-системы может оказаться полезной информация о наличии в системе данных, к которым он не имеет доступа, о владельцах этих данных и о действиях, которые он должен предпринять, чтобы получить доступ к данным; - статистические оценки времени выполнения запросов. До выполнения запроса полезно иметь хотя бы приблизительную оценку времени, которое потребуется для получения ответа, и объема этого ответа. Уже сейчас известны примеры ХД, содержащих терабайты информации. Проблемой таких больших хранилищ является то, что накладные расходы на внешнюю память возрастают нелинейно при возрастании объема ХД. Исследования показали, что для ХД объемом в 100 гегабайт потребуется внешняя память объемом в 4,87 раза большая, чем нужно собственно для полезных данных. При дальнейшем росте ХД этот коэффициент увеличивается.
Направления развития АИС Высокие темпы развития информационных технологий в настоящее время обеспечивают постоянное совершенствование систем сбора и обработки данных, способы представления данных в БД и БЗ, создание новых методологий формирования ХД с целью повышения эффективности вырабатываемых управленческих решений. Новые средства и возможности информационных технологий порождают новые запросы пользователей и диалектический процесс автоматизации всех аспектов организационного управления формирует информационный бизнес в этой области. Несмотря на высокий существующий уровень автоматизации организационного управления на всех уровнях темпы развития информационного бизнеса все больше увеличиваются. Анализ этапов развития информационного бизнеса в области организационного управления показывает, что формируются циклы с непрерывным переходом на более высокий уровень автоматизации процессов принятия решений, а в пределах одного цикла включаются новые аспекты информационных технологий. Процесс развития информационного бизнеса тесно связан с информационными технологиями. Развитие информационных технологий по циклам приводит к необходимости реинжиниринга существующих АИС. Но, как правило, сложно определить на каком этапе проводить реинжиниринг, чтобы получить наибольший положительный эффект. Неопределенность возникает по следующим двум факторам. Во-первых, до определенного уровня эффективнее использовать хорошо настроенные АИС и решать вопросы интеграции с новыми информационными технологиями путем надстройки дополнительных функциональных модулей. В этом случае возникает опасность "бесконечного" подстраивания системы к новым условиям, что в конечном итоге сделает ее неэффективной и, возможно, неработоспособной. Кроме этого, стоимость самой АИС будет увеличиваться за счет новых компонентов и сильной привязки к предметной области, а эффективность будет снижаться за счет использования громоздких информационных технологий. К тому же, это противоречие увеличивается с течением времени функционирования АИС.
Во-вторых, можно произвести реинжиниринг на новой базовой основе. Возникает неопределенность во времени и масштабе реинжиниринга, так как использование новых информационных технологий приведет к необходимости заменить многие компоненты функциональной системы. Значительные материальные затраты потребуются на приобретение новых информационных технологий, но еще большая часть затрат возникает в процессе перехода от существующих технологий к новым информационным технологиям. В процессе функционирования эволюционной модели интеллектуальных информационных технологий в организационном управлении производственными процессами создается значительный объем взаимосвязанных данных, жизненный цикл которых еще не завершился. Из-за разнородности моделей данных и способов их физического представления возникает необходимость переноса накопленных в предметной области знаний и данных в новую программную среду. Также необходимо перенести накопленный опыт функционирования самой информационной системы на новую платформу. Реализация интерфейса АИС, обучение пользователей не вызывает особых затруднений. Но даже автоматизированное транспортирование больших объемов информации приводит на практике к появлению ошибок и потере данных из-за изменения модели данных и формы их представления. К тому же, в функционирующих автоматизированных системах специалисты должны вести параллельную обработку текущей информации. Если входные потоки данных имеют большой объем и переменный жизненный цикл по группам потока, то перед ЛПР возникает сложная многомерная задача по управлению потоками данных. К указанным факторам необходимо добавить также следующее. Современные информационные технологии усложняются по мере их совершенствования с точки зрения функционального богатства и интеграции. В связи с этим для их эффективного использования требуется все более высокая квалификация непосредственных пользователей-специалистов помимо квалификации их в своей специальной области. АИС – это человеко-компьютерные системы для поддержки принятия решений и производства информационных продуктов, использующие определенные информационные технологии. Они обеспечивают сбор, хранение, обработку, поиск, выдачу информации, необходимой в процессе принятия решений, помогает анализировать проблемы и создавать новые информационные продукты. Первые АИС появились в 50-х годах. Развитие АИС и их назначение тесно связано с развитием информационных технологий (но это разные понятия: ИТ могут существовать и вне АИС, а реализация функций АИС без использования ИТ невозможна). Можно выделить следующие этапы развития АИС в управлении экономикой, которые приведены в таблице 1.1.
Таблица 1.1
Производственная система Объектами автоматизированного управления являются: производство, научный эксперимент, комплексные испытания, объекты социальной сферы и др. Наибольшее значение имеет производство как источник экономического эффекта. Под производством понимается организационно-экономическая деятельность на основе единства целей функционирования, технологий, входных и выходных продуктов труда (производственные продукты, услуги). Любое производство представляет собой систему, которая функционирует в условиях воздействия окружающей среды. С внешней средой производство связано через ресурсные отношения и информационные связи. Производство направлено на достижение цели управления, например, получение прибыли для предприятия или организации. Управление производством осуществляется через производственные процессы. Производственный процесс – это определенное воздействие на определенный ресурс в соответствии с поставленной целью управления. Организационное управление направлено на эффективную организацию производственных процессов путем управления всеми видами ресурсов – материальными, финансовыми, энергетическими, информационными, трудовыми. Управляющими параметрами при этом являются объемы и темпы выпуска товарной продукции необходимой номенклатуры. Под воздействием возмущений, возникающих по вероятностным законам, появляются отклонения от заданных параметров. Устранение возникающих отклонений происходит своевременным принятием управленческих решений или выработкой управляющих воздействий, в совокупности представляющих собою организационное управление. Оно заключается в выделении ресурсов путем их размещения, изменения мощностей, последовательности применения, сочетания, анализа различных вариантов решений на количественной основе, выбора наилучшего варианта решений. На рис. 4.1. показана общая структура производственной системы, в которой взаимодействуют следующие наиболее динамические потоки: - материальный поток W, представленный в системе предметами труда (сырья, материалы, полуфабрикаты, запасные части); - поток орудий труда М (инструментов, технологических машин, транспортных средств, учитываемых в трудовом коллективе); - поток труда рабочих R – непосредственная работа над предметами труда и совместная деятельность с использованием орудий труда; - энергетический поток Э, образующийся в результате потребления электрической, механической, других видов энергии; - информационный поток H, адекватно отражающий состояние всех других потоков. Производственный процесс как определенное воздействие на определенный вид ресурса образует поток готовой продукции Y. Являясь целью интеллектуальной деятельности специалистов или ЛПР, он изначально задается по темпу и объему выпуска.
Рис.4.1. Система управления производственными процессами
В реальных условиях в производственной системе возникают различные нарушения в установившемся балансе динамичных потоков, что проявляется в различных формах. В материальном потоке W это может быть неполная номенклатура материалов, запасных частей, узлов, агрегатов, срывы графика движения транспортных средств, наличие брака или некомплектность поставки. В потоке орудий труда М – отказы или снижение производительности технологических машин, ухудшение качества или брак инструмента, внезапные выходы из строя оборудования. В потоке труда рабочих R – нехватка квалифицированных кадров, неправильное использование имеющихся рабочих, увольнения, болезни. В энергетическом потоке Э – выход из строя источников энергии, изменение их параметров, обрывы линии питания, отсутствие необходимого сервисного оборудования, нарушение правил техники безопасности. В информационном потоке Н – неточное определение расчетных показателей, отражающих ход производственных процессов, конструктивные переделки в чертежах, запаздывания в доставке технологической и сопроводительной документации. Указанные нарушения приводят к изменению объемов и темпов выпуска товарной продукции. Они относятся к первой отрицательной группе возмущающих воздействий Одновременно возникают достаточно сложные нежелательные ситуации, способы устранения которых неочевидны, неоднозначны и содержат неопределенности в выборе управляющих воздействий. Причины их возникновения носят объективный характер. Неопределенность связана с тем, что ход производственных процессов в пространстве и во времени подвержен действию значительного числа возмущающих воздействий, возникающих по вероятностным законам. Неоднозначность определена множеством способов устранения нежелательных ситуаций, последствия от которых в условиях многофакторности системы "человек-машина" трудно прогнозировать. Фактически даже при наличии ресурсов в сложных системах "человек-машина" интеллектуальная деятельность ЛПР протекает в условиях дефицита в них из-за трудно учитываемого множества нежелательных ситуаций. Дефицит в ресурсах может быть также искусственно создан в результате негативных последствий от ошибочных решений ЛПР, либо из-за несвоевременно полученной или отсутствия информации о наличии и движении ресурсов.
Windows NT Стоимость Windows NT сравнительно невелика, но стоимость сервера и сети в целом (с учетом дополнительного необходимого программного обеспечения) является высокой. Обновление версий требует также значительных вложений в ПО и аппаратные средства. Использование встроенных протоколов ТСР/IР и NetBios как основных обеспечивает взаимосвязь с другими типами сетей и их приложениями. Возможность исполнения Windows - приложений на сервере в процессе функционирования сети позволяет делать его невыделенным. В качестве достоинств можно также отметить следующие: - простота установки и администрирования; - высокая степень надежности при сбоях; - защита класса С2; - встроенная технология статического и динамического обмена данными между Windows - приложениями (OLE (Object Linking and Embedding) - технология позволяющая редактировать данные, созданные в другой программе, не выходя из основного редактора. и DDE технологии Связь DDE (динамический обмен данными) между файлом-"источником" (сервером) (например, электронной таблицей Excel) и файлом данных системы STATISTICA (файлом-"клиентом") устанавливается таким образом, что при внесении изменений в файл-источник в таблице исходных данных системы STATISTICA (файле-клиенте) данные будут автоматически обновляться.); - развитый графический интерфейс. К недостаткам можно отнести следующие особенности: - алгоритмы распределения оперативной памяти между процессами не могут быть оптимизированы для выполнения большого количества активных фоновых задач; - в связи с тем, что система очень требовательна к аппаратным ресурсам, обладает малой производительностью; - невозможно конфигурировать для нестандартных аппаратных средств и неэффективно используется стандартное программное обеспечение для нетипичных конфигураций аппаратуры; - для реализации виртуальной памяти используется страничная подкачка образов процессов, а не общего пула памяти - что обеспечивает оптимизацию системы для применения на рабочих станциях, но делает невозможной ее оптимизацию для сервера. В связи с этим Windows NT обладает невысокой производительностью в качестве сервера; - соответствует стандарту POSIX (стандарт для реализации UNIX - совместимых систем), но отсутствует возможность генерации ядра, не поддерживается режим реального времени; - повышенное внимание к вопросам безопасности ограничивает совместимость Windows NT с различными программами, в том числе с коммуникационными программами, что также снижает производительность системы.
Заключение. Для организации серверов приложений (SQL серверов) целесообразно использование операционной системы UNIX, остальные ОС в качестве серверов приложений менее эффективны. Для реализации файл-серверов может быть использована любая современная система. Но при этом Windows NT требует наибольших аппаратных ресурсов. При невысокой пропускной способности каналов связи UNIX позволяет оптимизировать доступ за счет маршрутизации пакетов. Для реализации серверов удаленного доступа целесообразно использование UNIX, поскольку не требует установки каких-либо дополнительных пакетов. Windows NT требует больших аппаратных ресурсов с очень высокой стоимостью и не предназначен для организации серверов удаленного доступа с малым числом соединений. Наиболее эффективной ОС по стоимости, производительности, функциональным возможностям, защите данных и перспективе развития являются операционные системы семейства UNIX. Выбор СУБД Выбор СУБД зависит от организации локальной и сетевой базы данных (БД), стоимости, специфики решаемых задач, функциональных особенностей (поддержка целостности, уровень защиты данных, быстродействие, эффективно обрабатываемый объем данных в БД, сетевая поддержка, наличие среды разработки, взаимодействие с другими приложениями, в том числе Интернет-приложениями). Необходимо рассмотреть следующие методологии организации сетевой базы данных: 1. БД хранится централизованно на сервере, а доступ со стороны рабочих станций по сети; 2. БД распределена по компьютерам-рабочим станциям, но жестко зафиксирована. Выбор сетевого протокола (ODBC, Microsoft, Novell). Сетевой протокол используется для доступа к данным в удаленной БД. Он позволяет интегрировать разнородные БД. Выбор осуществляется в соответствии с международным стандартом ISO (семиуровневой модели) и определяется следующими критериями: 1. Производительностью и эффективностью для обеспечения необходимой скорости обработки запросов и ответов. 2. Возможностью его реализации существующим программным обеспечением с использованием доступных системных модулей. В сети могут быть установлены одинаковые SQL сервера, тогда можно использовать сетевой протокол SQL сервера, а не использовать дополнительное ПО для реализации стандартного протокола (ODBC). Сетевой протокол должен соответствовать международному стандарту ISO. К такому протоколу относится ODBC, который универсально подходит для взаимодействия с любыми СУБД. Выбор метода авторизации. 1. Стандарт ISO подразумевает хранение списка пользователей с прописанными правами вместе с основной БД. Авторизация реализуется средствами СУБД. 2. Второй вариант подразумевает хранение списка пользователей не непосредственно в БД, а в операционной системе. В этом случае авторизация пользователей сетевая и реализуется на уровне ОС. Резервирование БД. Для обеспечения надежности хранения данных обязательно создается копия БД. Централизованные БД, как правило, копируются на сервере. Для распределенных БД существуют разные стратегии: 1) создание резервной копии БД на самой рабочей станции, либо на любой рабочей станции в сети; 2) создание резервной копии на Backup сервере. С помощью специальной программы Backup автоматически создается зеркальная копия БД на любом сетевом компьютере достаточной мощности, который и является Backup-сервером. Архитектура клиент-сервер Архитектура клиент-сервер предназначена для разрешения проблем файл-серверных приложений путем разделения компонентов приложения и размещения их там, где они будут функционировать наиболее эффективно. Особенностью архитектуры клиент-сервер является наличие выделенных серверов баз данных, понимающих запросы на языке структурированных запросов (Structured Query Language, SQL) и выполняющих поиск, сортировку и агрегирование информации. Отличительная черта серверов БД — наличие справочника данных, в котором записаны структура БД, ограничения целостности данных, форматы и даже серверные процедуры обработки данных по вызову или по событиям в программе. Объектами разработки в таких приложениях, помимо диалога и логики обработки, являются, прежде всего, реляционная модель данных и связанный с ней набор SQL-операторов для типовых запросов к базе данных. Большинство конфигураций клиент-сервер использует двухуровневую модель, в которой клиент обращается к услугам сервера. Предполагается, что диалоговые компоненты PS и PL размещаются на клиенте, что позволяет реализовать графический интерфейс. Компоненты управления данными DS и FS размещаются на сервере, а диалог (PS, PL) и логика (BL, DL) — на клиенте. В двухуровневом определении архитектуры клиент-сервер используется именно этот вариант: приложение работает на клиенте, СУБД — на сервере (рис. 8.4).
Рис. 8.4. Классический вариант клиент серверной системы
Поскольку эта схема предъявляет наименьшие требования к серверу, она обладает наилучшей масштабируемостью. Однако сложные приложения, активно взаимодействующие с БД, могут жестко загрузить как клиент, так и сеть. Результаты SQL-запроса должны вернуться клиенту для обработки, потому что там реализована логика принятия решения. Такая схема приводит к дополнительному усложнению администрирования приложений, разбросанных по различным клиентским узлам. Для сокращения нагрузки на сеть и упрощения администрирования приложений компонент BL можно разместить на сервере. При этом вся логика принятия решений оформляется в виде хранимых процедур и выполняется на сервере БД. Хранимая процедура — процедура с SQL-операторами для доступа к БД, вызываемая по имени с передачей требуемых параметров и выполняемая на сервере БД. Хранимые процедуры могут компилироваться, что повышает скорость их выполнения и сокращает нагрузку на сервер. Хранимые процедуры улучшают целостность приложений и БД, гарантируют актуальность коллективных операций и вычислений. Улучшается сопровождение таких процедур, а также безопасность (нет прямого доступа к данным). Следует помнить, что перегрузка хранимых процедур прикладной логикой может перегрузить сервер, что приведет к потере производительности. Эта проблема особенно актуальна при разработке крупных информационных систем, в которых к серверу может одновременно обращаться большое количество клиентов. Поэтому в большинстве случаев следует принимать компромиссные решения: часть логики приложения размещать на стороне сервера, часть — на стороне клиента. Такие клиент-серверные системы называются системами с разделенной логикой. Данная схема при удачном разделении логики позволяет получить более сбалансированную загрузку клиентов и сервера, но при этом затрудняется сопровождение приложений. Создание архитектуры клиент-сервер возможно и на основе многотерминальной системы. В этом случае в многозадачной среде сервера приложений выполняются программы пользователей, а клиентские узлы вырождены и представлены терминалами. Подобная схема информационной системы характерна для Unix. В настоящее время архитектура клиент-сервер получила признание и широкое распространение как способ организации приложений для рабочих групп и информационных систем корпоративного уровня. Подобная организация работы повышает эффективность выполнения приложений за счет использования возможностей сервера БД, разгрузки сети и обеспечения контроля целостности данных. Двухуровневые схемы архитектуры клиент-сервер могут привести к некоторым проблемам в сложных информационных приложениях с множеством пользователей и запутанной логикой. Решением этих проблем может стать применение многоуровневой архитектуры.
Многоуровневая архитектура Многоуровневая архитектура стала развитием архитектуры клиент-сервер и в своей классической форме состоит из трех уровней: □ нижний уровень представляет собой приложения клиентов, выделенные для выполнения функций и логики представлений PS и PL и имеющие программный интерфейс для вызова приложения на среднем уровне; □ средний уровень представляет собой сервер приложений, на котором выполняется прикладная логика BL и с которого логика обработки данных DL выполняет операции с базой данных DS; □ верхний уровень представляет собой удаленный специализированный сервер базы данных, выделенный для услуг обработки данных DS и файловых операций FS (без использования хранимых процедур). Подобную концепцию обработки данных пропагандируют, в частности, фирмы Oracle, Sun, Borland и др. Трехуровневая архитектура позволяет еще больше сбалансировать нагрузку на разные узлы и сеть, а также способствует специализации инструментов для разработки приложений и устраняет недостатки двухуровневой модели клиент-сервер. Централизация логики приложения упрощает администрирование и сопровождение. Четко разделяются платформы и инструменты для реализации интерфейса и прикладной логики, что позволяет с наибольшей отдачей реализовывать их специалистам узкого профиля. Наконец, изменения прикладной логики не затрагивают интерфейса, и наоборот. Но поскольку границы между компонентами PL, BL и DL размыты, прикладная логика может реализовываться на всех трех уровнях. Сервер приложений с помощью монитора транзакций обеспечивает интерфейс с клиентами и другими серверами, может управлять транзакциями и гарантировать целостность распределенной базы данных. Средства удаленного вызова процедур наиболее соответствуют идее распределенных вычислений: они обеспечивают из любого узла сети вызов прикладной процедуры, расположенной на другом узле, передачу параметров, удаленную обработку и возврат результатов. С ростом систем клиент-сервер необходимость трех уровней становится все более очевидной. Продукты для трехуровневой архитектуры, так называемые мониторы транзакций, являются относительно новыми. Эти инструменты в основном ориентированы на среду Unix, однако прикладные серверы можно строить на базе Microsoft Windows NT с вызово
|
|||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 814; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.146.176.191 (0.02 с.) |


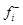 . Вторая положительная группа возмущающих воздействий
. Вторая положительная группа возмущающих воздействий  образуется за счет появления новых возможностей: увеличения скорости потоков путем использования высокопроизводительного оборудования, повышения квалификации кадров, более прогрессивной оплаты труда и др. Возникающие отклонения в ресурсах приводят к различным производственным ситуациям. Нежелательные ситуации устраняются за счет создания запасов и резервов, а также простым устранением возмущающих воздействий.
образуется за счет появления новых возможностей: увеличения скорости потоков путем использования высокопроизводительного оборудования, повышения квалификации кадров, более прогрессивной оплаты труда и др. Возникающие отклонения в ресурсах приводят к различным производственным ситуациям. Нежелательные ситуации устраняются за счет создания запасов и резервов, а также простым устранением возмущающих воздействий.



