Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Зв'язок процесу із об'єктами VFSСодержание книги
Поиск на нашем сайте
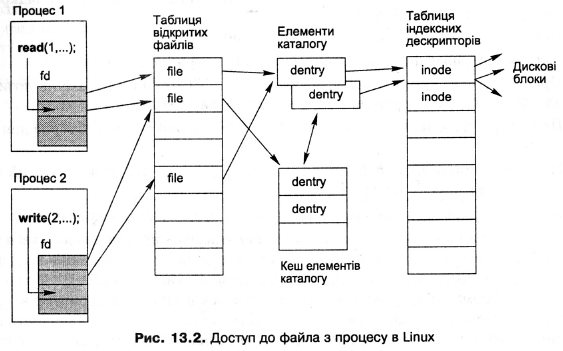
Тепер розглянемо, яким чином процес отримує доступ до об'єктів відкритих файлів. У керуючому блоці кожного процесу є два поля, що задають зв'язок цього процесу із файловою системою. Перше з них — поле fs, що задає покажчик на структуру типу fs_struct. Вона містить поля, що відповідають елементам файлової системи, які задають середовище процесу. Серед них об'єкти dentry, що відповідають кореневому каталогу процесу (поле root) і його поточному каталогу (поле pwd), a також права на доступ до файла за замовчуванням (поле umask). Другим полем є files, що задає покажчик на структуру типу files_struct. Ця структура описує відкриті файли, із якими в цей час працює процес. Таблиця файлових дескрипторів Найважливішим полем структури files_struct є поле fd, що містить масив покажчиків на об'єкти f 11 е. Кожен елемент цього масиву відповідає файлу, відкритому процесом. Довжину масиву fd зберігають у полі maxfds. Системні виклики UNIX використовують як параметр, що визначає відкритий файл, тобто індекс у масиві fd. Такі індекси називають файловими дескрипторами (file descriptors), а масив fd - масивом або таблицею файлових дескрипторів. Під час відкриття файла системний виклик ореп() виконує такі дії: створює новий об'єкт f 11 е; зберігає адресу цього об'єкта у першому вільному елементі масиву файлових дескрипторів fd; повертає індекс цього елемента (файловий дескриптор), який можна використати для роботи з цим файлом. За замовчуванням під час створення процесу виділяють пам'ять під масив fd з 32 елементів. Якщо процес відкриє більше файлів, масив автоматично розширюється. Максимальна кількість відкритих файлів для процесу є одним із лімітів на ресурси для процесу, у Linux за замовчуванням вона дорівнює 1024, але може бути збільшена. Перші три елементи масиву fd задаються автоматично під час запуску процесу, їм відповідають визначені файлові дескриптори. Кілька елементів масиву fd можуть вказувати на один і той самий об'єкт fі 1е. Доступ через кожний із них призводить до роботи з одним і тим самим відкритим файлом. Є два основні способи домогтися такого дублювання дескрипторів. По-перше, можна використати системні виклики dup() і dup2() для дублювання дескриптора в рамках одного процесу (dup2). По-друге, якщо створити процес-нащадок за допомогою fork(), елементи таблиці дескрипторів нащадка вказуватимуть на ті самі об'єкти f i 1 е, що й відповідні елементи таблиці дескрипторів предка. Розглянемо цю ситуацію докладніше. Насамперед з'ясуємо, чому необхідно вводити окремі об'єкти для відкритих файлів і список si i st замість того, щоб помістити інформацію про відкриті файли безпосередньо в таблицю дескрипторів файлів fd. Причина полягає в тому, що, якби інформація була поміщена безпосередньо в таблицю, предок і нащадок не могли б спільно використовувати відкриті файли так, як це потрібно для fork(). Прикладом може бути така послідовність подій: 1. Предок відкриває файл за допомогою open() i отримує дескриптор 4. 2. Предок записує три байти так: write(4. "AAA",3). Поточний покажчик позиції для дескриптора 4 переміщають у позицію 3, рахуючи від нуля. 3. Предок створює нащадка за допомогою fork() i очікує його завершення за waitpidO. 4. Нащадок записує п'ять байтів: write(4, "BBBBB".5), переміщаючи поточний покажчик у позицію 8, після чого завершується. 5. Предок записує ще три байти: write(4. "CCC",3), після чого закриває файл. У цьому разі коректна реалізація fork() вимагає, щоб предок продовжував записування у файл із того місця, на якому завершив своє виведення нащадок (тут — з позиції 8), тобто щоб у результаті було виведено "АААВВВВВССС". У той же час, якби інформація про відкриті файли містилася в таблиці дескрипторів, предок після завершення нащадка не зміг би довідатися, що нащадок зробив поточну позицію рівною 8 (інформація про це була б вилучена із пам'яті разом із керуючим блоком нащадка після його завершення). У результаті предок продовжив би виведення з того місця, де він його завершив на кроці 2 (із позиції 3), поверх запису нащадка. Результат був би "АААСССВВ", що відповідно до POSIX невірно. Взаємозв'язок компонентів VFS y разі отримання доступу до файла Тепер є вся інформація для того, щоб описати і показати на рис. 4.2 взаємозв'язок між різними компонентами VFS, необхідними для отримання доступу До файла. 1. Керуючий блок процесу містить покажчик на масив файлових дескрипторів fd, системні виклики UNIX приймають як параметри індекси в цьому масиві. Кожен процес має окрему його копію. 2. Кожний елемент масиву файлових дескрипторів вказує на об'єкт відкритого файла (структуру fі1е), ці об'єкти об'єднані у список. Кілька елементів таблиці fd (одного й того ж процесу або різних процесів) можуть вказувати на один і той самий об'єкт f 11 е. 3. Кожному об'єкту відкритого файла відповідає елемент каталогу, відображений об'єктом елемента каталогу (dentry). Кілька об'єктів file можуть посилатися на один об'єкт dentry; це означає, що файл був відкритий кілька разів із використанням одного й того самого імені (жорсткого зв'язку). 4. Кожному файлу файлової системи відповідає об'єкт індексного дескриптора (inode), ці об'єкти об'єднані у хеш-таблицю і декілька списків. Кілька об'єктів dentry можуть посилатися на один об'єкт inode, якщо вони відповідають жорстким зв'язкам. 5. Файловій системі в цілому відповідає об'єкт файлової системи. Інформація з об'єктів inode i об'єктів файлової системи дає змогу доступу до функцій підтримки конкретної файлової системи, що дає доступ до реального файла (на диску, мережного файла тощо).
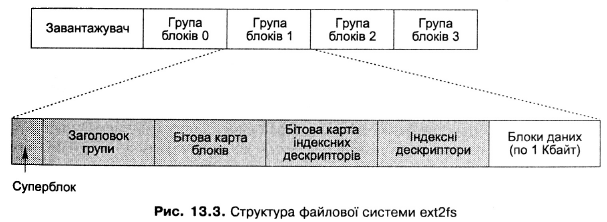
Файлова система ext2fs Стандартною дисковою файловою системою для Linux є друга розширена файлова система (ext2fs). Файлова система багато в чому схожа на файлову систему FFS. Наприклад, спільними рисами є структура індексного дескриптора і розміщення каталогів на файловій системі як звичайних файлів (хоч їхній вміст інтерпретують трохи інакше). Спільною є також ідея групування індексних дескрипторів і блоків для зв'язаних даних, хоча для реалізації цієї ідеї використовують інший підхід. Однією із базових відмінностей ext2fs від FFS є інша політика розподілу дискового простору. Як зазначалося, у FFS було дозволено розподіляти дисковий простір на блоки по 4 і 8 Кбайт, при цьому малі частини таких блоків, що залишилися після розподілу, своєю чергою розділяли на фрагменти по 1 Кбайт. В ext2fs ситуація змінилася — дисковий простір розподіляють на блоки тільки одного розміру. За замовчуванням він становить 1 Кбайт, хоча можна під час форматування файлової системи задати й більший розмір — 2 або 4 Кбайт. Основою обробки запитів введення-виведення в ext2fs є кластеризація суміжних запитів для досягнення максимальної продуктивності, для чого, як і в FFS, прагнуть розташовувати зв'язані дані разом. Для вирішення цієї задачі використовують групування даних, схоже за своїми принципами на використання груп циліндрів у FFS. Відмінності тут переважно зумовлені тим, що сьогодні у дисках використовують циліндри з різною геометрією залежно від відстані до центра пластини, тому об'єднання таких циліндрів у групи фіксованого розміру часто не відповідає фізичній структурі диска. Виходячи з цього, в ext2fs дисковий простір ділять не на групи циліндрів, а просто на групи блоків (block groups), не прив'язані до геометрії диска. Такі групи за структурою схожі на групи циліндрів: кожна група блоків теж є зменшеною копією файлової системи із суперблоком, таблицею індексних дескрипторів тощо (рис. 4.3).
Під час розміщення файла для нього спочатку вибирають групу блоків і в ній розміщують індексний дескриптор. При цьому перевагу отримує група блоків каталогу, де перебуває цей файл. Після цього, під час розподілу дискових блоків для файла, пробують вибрати ту саму групу, у якій перебуває індексний дескриптор. Файли каталогів не збирають разом, їх розподіляють рівномірно у доступних групах блоків для зменшення загальної фрагментації та більш рівномірного використання диска (навколо кожного файла каталогу групуватимуться індексні дескриптори його файлів, а навколо цих індексних дескрипторів — блоки їхніх файлів). Облік вільних блоків та індексних дескрипторів ведуть за допомогою пари бітових карт — по одній на кожну групу блоків. Розмір кожної такої карти дорівнює одному блоку (1 Кбайт), тому максимально можлива кількість блоків та індексних Дескрипторів у групі дорівнює 8 Кбайт. Під час розміщення перших блоків нового файла файлова система починає пошук вільних блоків від початку групи блоків, У разі розширення наявного файла пошук триває від блоку, виділеного найпізніше. Цей пошук відбувається у два етапи: на першому в бітовій карті відшукують вільний байт (8 біт), що відповідає 8 неперервно розташованим дисковим блокам (аналогам блоку в 8 Кбайт). Якщо байт знайти не вдалося, виконують ще один пошук, але при цьому відшукують будь-який вільний біт. Якщо байтовий пошук завершився успішно, система шукає вільні біти від початку цього байта назад до першого зайнятого біта. Метою цього пошуку є зменшення фрагментації (так не залишатиметься «дірок» між виділеним інтервалом блоків і попередніми зайнятими блоками). Після того, як вільний блок було знайдено одним із двох способів, його виділяють для використання файлом. Додатково випереджувально виділяють до 8 блоків, що розташовуються за ним (якщо зайнятий блок під час цього виділення виявляють раніше, то виділяють менше ніж 8 блоків). Метою такого випереджувального виділення є зменшення фрагментації та витрат часу на виділення дискових блоків. У разі закриття файла всі виділені таким чином блоки, що реально не використані, повертаються у бітову карту як вільні. Розмір кожного індексного дескриптора становить 128 байт. Використовують 12 прямих блоків і по одному непрямому блоку першого, другого та третього рівнів. Довжина адреси блоку становить 4 байти, що більше, ніж стандартна довжина для багатьох UNIX-систем, тому можна адресувати більше дискового простору. Місце для розміщення списків керування доступом зарезервоване, але може бути використане тільки в ядрі версії 2.6.
|
||||||||||
|
|
Последнее изменение этой страницы: 2016-07-11; просмотров: 295; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.143.17.175 (0.006 с.) |