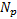Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Размещение данных в памяти ЭВМСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Одномерный линейный список
Недостатки: · Необходимы большие объемы свободной памяти · При необходимости вставить новую строчку или удалить существующую строку, необходимо сдвигать множество других строк, то есть совершать сдвиги больших объемов памяти ЭВМ
Связное распределение памяти
Память организована в виде связного списка. Недостаток в том, что необходимо хранить в памяти адрес следующей строки
Организация данных в памяти ЭВМ с использованием методов вычисления адреса по значениям ключей записей
1. Исходные записи обязательно упорядочены по ключу 2. Все записи фиксированной длины Пример: Ширина таблицы 20 байт
Для вычисления
На экзамене есть эти штуки
Метод хеширования (рандомизации)
Основная идея – каждый экземпляр хранимой записи размешается в памяти по адресу, вычисляемому с помощью некоторой адресной функции (хеш-функция) по значению первичного ключа. Пусть в предыдущем примере номер рейса изменяется от 0001 до 9999, но система ставиться в аэропорту, в котором обслуживается лишь 50 рейсов. И они находятся не подряд, а случайно. Нас интересует третий рейс 4-го января, а второй рейс не обслуживается вообще.
Для того, что бы использовать предыдущую формулу необходимо, что бы все строки были заполнены, иначе нельзя вычислить относительное положение. Информация о тех рейсах, которые не обслуживаются данным аэропортом, все равно должна присутствовать в памяти ЭВМ, если мы хотим использовать предыдущую формулу (пункт 3). То есть громадные объемы памяти будут использоваться впустую. Что бы исключить этот недостаток, адреса функций будут вычисляться с помощью некоторой хеш-функции, которую выбирают согласно здравому смыслу и которая должна тщательно быть проверена на контрольных примерах.
Ключ будет использоваться в пределах 0001 001 до 9999 365. А функция должна распределить эти числа в пределах от 0 до 18250 (50*365)
Использование метода квадратов
После этого выделяем некоторое количество разрядов из ключа Достоинства: · Выигрыш больших объемов памяти Недостатки: · Нарушена сортировка записи в памяти ЭВМ · Образуются пустоты и сгустки информации · Коллизия – двум записям присваивается один и тот же машинный адрес
Язык запросов SQL
Сначала язык назывался SEQUEL (structured English query language) SQL-92 – американский и европейский стандарт. Язык придуман для работы с реляционными базами данных. Основой этого языка является оператор SELECT [distinct] элементы FROM таблица (ы) [WHERE предикат] [GROUP BY поле [HAVING предикат]] [ORDER BY поле];
В квадратных скобках необязательные поля. Элементы – список столбцов, которые выводятся в результат. distinct - означает что в результате не будет дублирования строк FROM – имя таблицы, откуда извлекается информация WHERE – задается условие выбора информации GROUP BY – из исходной таблицы создаются группы, в которых указанное поле имеет одно и тоже значение HAVING – позволяет выводить информацию только о некоторых группах. ORDER BY – результат будет отсортирован по заданному полю.
Пример 1: Выдать название и капитал поставщиков из Казани SELECT название, капитал FROM поставщики WHERE город = Казань Пример 2: выбор номера всех поставок SELECT номер изделия FROM поставки Пример 3: второй пример, но без повторений SELECT DISTINCT номер изделия FROM поставки Пример 4: выдать номера и расход материалов SELECT номер изделия, «расход материала =; Расход» FROM изделия; в скобках можно указать, как будут названы столбцы в результате Пример 5: выдать всю информацию обо всех изделиях SELECT * FROM изделия Пример 6: выдать номера и наименования поставщиков, которые находятся в Москве и имеют некоторый капитал. SELECT номер_поставщика, название FROM поставщики WHERE город= «Москва» and капитал > 0 Можно использовать операторы or, and и not
Пример 7: Вывести номера и капитал поставщиков из Казани и упорядочить по возрастанию SELECT Nn, капитал FROM поставщики WHERE город=”Казань” ORDER BY капитал замечание 1: при сортировке, вместо имени поля можно указывать его порядковый номер SELECT N_из, расход FROM I ORDER BY 2 DESC В данном случае упорядочить по двойке означает упорядочить по расходу, в случае единицы упорядочивалось бы по номеру изделия Замечание 2: упорядочение может производиться по нескольким полям, в этом случае они перечисляются через запятую по старшинству.
Пример 8: выдать сведения об изделиях, расход материалов для которых от 400 до 500 квадратных дециметров SELECT N_из, название, расход FROM изделия WHERE расход BETWEEN 400 AND 500 В данном случае границы включаются так же можно использовать NOT BETWEEN, но в этом случае границы уже не входят
Пример 9: выдать сведения об изделиях расход материалов на которые 200, 400 или 500 дециметров SELECT N_из, название, расход FROM изделия WHERE расход IN (200, 400, 500); Замечание: можно пользоваться NOT IN. В таком случае выдаются все результаты, не попадающие под значения.
Выборка с использованием предиката LIKE. Пример 10: SELECT N_из, название, материал FROM изделия WHERE название LIKE “П*” Этот запрос ищет изделия, название которых начинаются на букву П с любым количеством символом в конце. Предикат LIKE имеет следующий вид: название_столбца LIKE литерная строковая константа столбец обязательно должен типа char “ “ или “?” – один произвольный символ “%” или “*” – любое количество любых символов
Пример 11: выдать все комбинации о таких поставщиках и изделиях, которые размещены в одном и том же городе. SELECT P.*, I.* FROM поставщики, изделия WHERE поставщики.город = изделие.город Замечание: поля в предикате соединения должны быть обязательно одного типа, но не обязательно с одинаковым названием. Таким образом можно соединить 3,4 и более таблиц Пример 12: выдать всю информацию о поставщиках и изделиях, расположенных в одном и том же городе, при этом капитал должен быть более 50 миллионов. SELECT * FROM поставщики, изделия WHEN поставищики.город = изделия.город AND поставищики.капитал > 50 Пример 13: использование подзапросов подзапрос – конструкция (select…from…where) вложенная в другую такую конструкцию Назовите поставщиков поставляющих изделие N7 SELECT поставищики.название FROM поставщики WHERE поставщики.N_п IN (SELECT поставки.N_п FROM поставки WHERE поставки.название = «N7») Если есть подзапрос, то сначала работает он, далее – основной запрос. Аналогично можно написать сложный запрос: SELECT поставищки.название FROM поставщики, поставки WHERE поставки.название = «N7»
Выдать название поставщиков, поставляющих шубы. SELECT поставщики.название FROM поставщики WHERE поставщики.N_п IN (SELECT поставки.N_п FROM поставки WHERE поставки.название IN (SELECT изделия.название FROM изделия WHERE изделия.название= «шуба»))
Сложный запрос: SELECT поставщики.название FROM поставщики, изделия, поставки WHERE изделие.название= «шуба» AND изделие.N_из=поставки.N_из AND поставки.N_п=поставщики=N_п
Пример 15: коррелированный подзапрос (рассмотрим на примере 13). SELECT поставщики.название FROM поставщики WHERE “N7” IN (SELECT поставки.N_из FROM поставки WHERE поставки.N_п=поставщики.N_п) поставщик.N_п это не конкретное значение, а название столбца. Такой подзапрос называется коррелированным. И столбец поставщик.N_п будет рассматриваться строка за строкой.
Пример 16: использование одной и той же таблицы в подзапросе и внешнем запросе. Выдать номера поставщиков, которые поставляют хотя бы одно изделие, поставляемое поставщиком П3.
Пример 17: использование одной и той же таблицы в коррелированном подзапросе и внешнем запросе. Выдать номер всех изделий, поставляемых более чем одним поставщиком. SELECT DISTICT IPX.название FROM IP IPX WHERE IPX.N_п IN (SELECT IPY.N_п FROM IP IPY WHERE IPY.N_п<>IPX.N_п)
Пример 18: запрос использующий квантор существования EXISTS (SELECT…FROM…WHERE) Выдать название всех поставщиков поставляющих изделие N3 SELECT поставщики.название FROM поставщики WHERE EXISTS (SELECT * FROM поставки WHERE поставки.название= «N3» AND поставки.N_п=поставщики.N_п) Помимо EXISTS может быть использован так же NOT EXISTS
Использование стандартных функций
Они следующие: 1. COUNT – количество значений в столбце 2. SUM – сумма значений в столбце 3. AVG – среднее значение в столбце 4. MAX 5. MIN 2 и 3 только для числовых полей. Примеры: 1. SELECT COUNT(*) FROM поставщики выдать количество строк в таблице поставщики 2. SELECT COUNT(DISTINCT N_п) FROM поставки 3.
Пример 19. Функция в подзапросе: выдать капитал, чей капитал ниже среднего SELECT Nn FROM P WHERE капитал < (SELECT AVG(капитал) FROM P);
Функции из коррелированного запроса: выдать номер, капитал и город поставщиков чей уставной капитал больше или равен среднему по своему городу: SELECT Nn, капитал, город FROM P PX WHERE капитал >= (SELECT AVG(капитал) FROM P PY WHERE PY.город=PX.город); PX.город – название столбца, поэтому запрос коррелированный
Пример 21: использования фразы GROUP BY. Перекомпонует указанную таблицу, образуя группы, в которых указанные поля имеют одно и то же значение. Вычислить общий объем и среднюю цену поставок по каждому изделию: SELECT Nиз, SUM(кол), AVG(цена) FROM IP GROUP BY Nиз
SELECT Nиз, SUM(кол), AVG(цена) FROM IP WHERE Nn <> “П2” GROUP BY Nиз В данном случае сначала работает оператор WHERE, а только потом группировка.
Пример использования слова HAVING. Позволяет исключать из результата некоторые группы. HAVING работает только с группировкой и не работает как WHERE. SELECT Nиз, SUM(кол), AVG(цена) FROM IP GROUP BY Nиз HAVING COUNT(*) >=2 Отобрать группы, количество элементов в которых больше 2-ух.
Пример 22 с помощью слова UNION. При объединении двух таблиц обязательно выполнение следующих условий: 1. Таблицы должны иметь одинаковое количество столбцов. 2. Для каждого i (I – номер столбца) типы столбцов должны совпадать. Выдать номер изделий расход материалов на которые составляет более 410 кв дециметров, либо цена более 5000 рублей.
SELECT Nиз FROM I WHERE расход > 410 UNION SELECT Nиз FROM IP WHERE цена > 5000 Первая таблица выдается без изменений, а второй запрос добавляет только то, чего нет. С помощью UNION можно объединять любое количество запросов.
Запросы по нескольким таблицам, объединяемым с помощью оператора JOIN. Объединение таблиц по условию (внутреннее объединение).
FROM T1 INNER JOIN T2 ON (T1.П1 <оператор> T2.П1) [AND/OR (T1.П2 <опер> T2.П2)] [AND/OR (T1.П3 <опер> T2.П3)]
SELECT P.Nn, P.назв, P.Тип FROM P INNER JOIN IP ON (P.Nn=IP.Nn) from p, ip where p.Nn=IP.Nn
Левое внешнее объединение Включаются все записи из первой левой таблицы, даже если нет совпадающих из второй таблицы.
Правое внешнее объединение Включаются все записи из второй правой таблицы, даже если нет совпадающих в левой.
Операторы языка SQL для работы с таблицами 1. Создание таблицы – CREATE TABLE <name> (имя_столбца тип_данных [not null],…, имя_столбца тип_данных [not null]) NOT NULL – для полей, которые не могут быть пустыми, допустим для первичного ключа. 2. Удаление таблицы - DROP TABLE <name> 3. Изменение таблицы – ALTER TABLE <name> (ADD/MODIFY/DROP <имя_столбца>[<тип_данных>][not null],…, ADD/MODIFY/DROP <имя_столбца>[<тип_данных>][not null]) 4. Создание индекса – CREATE INDEX <имя_индексного_файла> ON <имя_таблицы> (<имя_столбца>[ASC/DESC],…, <имя_столбца>[ASC/DESC]); 5. Удаление индекса – DROP INDEX <имя_индексного_файла> 6. Представления – CREATE VIEW <имя_представления> [(<имя_столбца>[,<имя_столбца>]..)] AS <оператор SELECT>
Обновление записи в таблице: UPDATE <имя_таблицы> SET поле = выражение [, поле = выражение …] [where предикат] Пример: UPDATE SET Адрес = “Волкова 15”, город = “Щелково” WHERE название = «Биржа»
Удаление записей – DELETE На след неделе контрольная – первый пункт оператор SELECT второй - одна из последних тем.
СУБД Microsoft Access Он позволяет 1. Хранить данные в виде таблиц. 2. Легко связывать данные, находящиеся в разных таблицах. 3. Дает возможность работать с данными других источников. 4. Позволяет устанавливать связь с другими приложениями MS Office (word, excel). 5. Возможность создавать свои приложения с помощью языка VBA (Visual Basic Application). Одним словом MA это функционально-полная реляционная СУБД, в которой предусмотрены все необходимые средства для определения и обработки данных, а также для управления ими при работе с большими объемами информации. МА спроектирован так, что может использоваться как самостоятельная СУБД на отдельном персональном компьютере и так же работать в сети в режиме «клиент-сервер» (это значит, что он имеет надежные средства защиты информации).
Основные объекты МА Таблица – используется для хранения информации, которая вводится в базу данных. Для каждой таблицы может быть определен первичный ключ, и может быть проведено индексирование. Запросы – позволяют создавать условия для отбора данных, а так же вносить изменения в данные.
Составление сложных запросов 1. Создание таблицы по результатам запроса. a) Открыть окно запросов и сформировать запрос. b) Запрос -> создать таблицу -> (система попросит ввести имя) ввести имя.
2. Запрос с добавлением полей одной таблицы в конец другой таблицы. a) Сформировать запрос в режиме конструктора b) Запрос -> добавить -> имя таблицы, в конец которой будут добавляться новые поля c) В бланке запросов в строке добавить указываются названия столбцов, в которые идет добавление 3. Обновление записей с помощью запросов. a) Открывается окно запросов в режиме конструктора b) перенести то, что меняем c) Запрос->обновить 4. Удаление записей по заданному условию. a) Открыть окно запросов в режиме конструктора. b) Запрос-> удалить. 5. Создание вычисляемых полей a) Открывается окно в режиме конструктора. b) В бланк запросов переносятся поля ФИО и оклад. c) Формируются остальные 3 столбца. Налог: [Оклад]*0,13; К выдаче: [Оклад]-[Налог]; Роспись: ‘ ‘ d) Сохранить результаты в новой таблице e) Создать по этой таблице отчет.
Формы
Позволяет создать удобный пользовательский интерфейс для работы с данными. Формы это объект, который в основном предназначен для ввода данных, отображение их на экране или управление работой приложения. Формы можно распечатать. С помощью форм, в ответ на некоторые события (например, нажатие кнопки) можно запустить макрос или процедуру.
Отчет
Отчет – объект, предназначенный для создания документа, который в последствие может быть распечатан или включен в документ другого приложения. Макрос – объект, предназначенный для структурированного описания одного или нескольких действий. Модуль – объект, содержащий программы на VBA, позволяющие разбить на более мелкие действии те действия, которые определяются макросом или обнаруживать ошибки и обрабатывать их.
СУБД FoXPro Архитектура
имяфайла.dbf – файл базы данных имя.prg – программы, которые работают с таблицами имя.idx – индексные файлы
Выражение Константы, переменные функции, которые соединяются арифметическими знаками, скобками. Знаки отношений (<,>,#,=,=>,=<) могут быть применены к датам, числам и символам. «Петров А» = «Петров А» - дает истину «Петров А» = «Пет» - дает истину, потому что сравнение идет по правому операнду, посимвольно «Пет» = «Петров А» - дает ложь «==» - сравнение на полное тождество (в этом случае сравнивается и длина слова и содержание).
Все функции разделены на 14 групп. 1. Математические: синусы, косинусы и прочее. 2. Строковые 3. Работа с датами 3.1. Date() – выдает текущая дату (системную) 3.2. day(<выражение типа date>) – выделение для из даты, т.е. число месяца 3.3. month () – 04 3.4. year 4. Функции преобразования данных 4.1. Str(<числовое выражение>, [длина], [<количество десятичных знаков>]) – перевод числа в строку. Если не указывать параметры в квадратных скобках, то число остается в том же виде, т.е. не сокращается.
Подпрограммы пользователя
процедуры могут быть 1.1. внешние 1.2. внутренние
Внешние процедуры Хранятся в виде отдельного командного файла. do <имя_файла.prg> [with <параметры>] Если в процедуре есть параметры, то они должны быть заданы в ее первой строке. parametrs <список параметров> Преимущества внешних процедур: 1. Программа состоит только из вызовов внешних процедур, т.е. все очень компактно и читабельно Недостаток: При вызове каждой процедуры идет обращение к внешнему устройству, что является самой длиной операцией, тратится много времени.
Внутренние процедуры Чтобы сократить количество обращений к внешнему устройству и сэкономить время используются внутренние процедуры, которые записываются в теле основной программы и загружаются в оперативную память вместе с ней. Если процедуры друг за другом, то они записываются так: procedure <имя процедуры> [parameters <список параметров>] : команды Return Вызывается она точно так же, как и внешняя процедура. Преимущества: не тратится время на вызов процедуры (большая экономия во времени) Недостаток: основная программа становится громоздкой и нечитабельной, т.к. все процедуры тут.
Процедурный файл
Несколько внешних процедур могут храниться в одном процедурном файле типа.prg. Таким образом, основная программа не захламлена процедурами, но они быстро загружаются из отдельного файла. Примечание: необходимо включить в начало основной программы имя подключаемого процедурного файла: set procedure to <имя> В каждый момент времени может быть загружен только 1 процедурный файл, поэтому отработавший процедурный файл надо сначала выгрузить командой: Set procedure to После чего можно загружать другие проц. файлы. Пример: Имеется файл сотрудников с такими полями: ФИО, должность, зарплата и отдел. Нужно сформировать ведомость по зарплате в таком виде: (в верхней строчке указывается положение посимвольно)
Вычисление налога и вычисление заработной платы будут оформлены в отдельных процедурах, и объединены в один процедурный файл. Поэтому сначала мы создадим этот процедурный файл. modi comm PFILE – откроется новое окно, в котором будет создан новый файл PFILE.prg Procedure nachnal Parameter z nalog = z*0.13 Return Procedure nachzarp Parameter z itog=z-nalog Return Теперь создаем основную программу
modi comm zarplata
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 581; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.107.181 (0.012 с.) |

 и множество к каким-то образом преобразуется во множество адресов M.
и множество к каким-то образом преобразуется во множество адресов M.