
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Пользователи информационных системСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Информационные системы
Информационные системы – это системы, которые служат для сбора и накопления информации с целью эффективного её использования различными пользователями. По выполняемым функциям ИС делятся на: 1. Информационно-поисковые системы – ИПС. Характеризуются частыми запросами и редким обновлением. 2. Системы обработки данных – СОД. Характеризуются частым обновлением и редкими запросами (банковские системы). 3. Управляющие информационные системы – УИС (технологические процессы). 4. Информационные системы для поддержания решений – ИСПР. По характеру содержащейся информации ИС делятся на: 1. Фактографические системы (сведения о некотором объекте) 2. Документальные ИС. 3. Документально-фактографическая ИС.
По области применения ИС делятся на: 1. Используемые в производстве 2. Используемые в здравоохранении 3. Науке 4. Образование 5. Искусство 6. И так далее Предметная область – это часть реального мира, подлежащая изучению с целью автоматизации накопления, хранения и обработки информации и, в конечном счете, автоматизации управления (например: ВУЗ, предприятие, министерство). Каждая предметная область характеризуется фрагментами. Разновидностью ИС являются банки данных. Состав банка данных: 1. База данных или несколько баз. 2. Система управления базами данных – СУБД 3. Словарь данных 4. Администратор БД 5. Вычислительная система 6. Обслуживающий персонал База данных – поименованная совокупность взаимосвязанных данных, находящаяся под управлением СУБД. В БД включаются данные о предметной области, а так же описание самой базы данных, которая называется схемой. СУБД – совокупность программных и языковых средств, общего или специализированного назначения, необходимые для создания базы данных, поддержании информации в них в актуальном состоянии, и организации доступа к ним различным пользователям. Примеры СУБД – access, forPro, Oracle, MySQL, SQLlite. Программные средства СУБД включают в себя: 1. Ядро – набор программных средств, для создания и поддержания базы данных 2. Сервисные средства – программы, предоставляющие пользователям дополнительные возможности и услуги. Языковые средства СУБД делятся на 1. Языки описания данных
2. Языки манипулирования данными – языки манипуляторы 3. Языки запросов - SQL На SQL: SELECT ФИО, ДА FROM студ WHERE Nгр = ‘4209’ На QbE какие-то колоночки, галочки и прочая графическая ерунда. Словарь данных – подсистема банка данных, для централизованного хранения ба____, о взаимосвязях хранения данных друг с другом, типа данных и формата их представления. Если словарь данных является частью БД, он называется интегрированным, в противном случае автономным. Администратор БД – лицо или группа лиц, отвечающих за выработку требований к БД, проектирование, создание, эффективное использование БД и её сопровождение. Вычислительная система и обслуживающий персонал писать не надо будет!!
Пользователи информационных систем Пользователи ИС делятся на внутренних и конечных. Внутренние – пользователь, который разрабатывает ИС и поддерживает её функционирование. К ним относятся: 1. Администратор БД. На этапе создания это идеологи и конструктор системы. Руководит всеми работами по созданию БД и программного окружения. На этапе функционирования отвечает за функционирование системы, обеспечивает защиту данных от различных разрушений, отвечает за достоверность информации, её актуальности и т.д. 2. Администраторы функциональных подсистем. Вместе с администраторами БД пишут фильтры для пользователей. 3. Системные программисты. Генерация СУБД. Следит за функционированием СУБД в процессе работы. Разрабатывает программы, расширяющие возможности СУБД. 4. Прикладные программисты. Пишут программы, которые нужны для работы конкретного заказчика. Конечные – для кого создается ИС. Она делятся на: 1. Косвенные – те, кто непосредственно за компьютером не сидит, но пользуется информацией из БД. 2. Прямые – непосредственно сидит за компьютером и работают с БД.
Организация работы пользователя с базами данных
Автономные базы данных – ПК + БД + СМД (средство манипулирования данными) Файл-серверные - (Сервер + БД) + (СМД + ПК1) + (СМД + ПК2) +… + (СМД + ПКN) – недостатки 1. Для каждого пользователя при обращении к БД создается локальная копия на его компьютере. При этом непродуктивно используется сеть, по которой передаются большие объемы информации. 2. База данных достаточно большая, поэтому необходимо создание фильтров для каждого пользователя.
3. Необходимость грамотной организации параллельного доступа пользователей Платформа клиент-сервер (Сервер + БД + СМД) + ПК1 + ПК2 + … + ПКN В отличие от предыдущей формы, ликвидированы недостатки, в качестве данных передается только запрошенная информация Многоярусные БД ( Удаленный сервер + БД) + (сервер + БД + СМД) + (сервер + БД + СМД) + Т1 + Т2 + Т3 + … + ТN
Преимущество и проблемы интеграции информации
Интеграция информации – сбор информации в одну кучу. Достоинства: 1. Синхронное поддержание данных для всех приложений. 2. Устраняется избыточность информации. 3. Благодаря исключению дублирования повышается достоверность информации 4. Унификация средств организации данных – пользователя не интересует, как и где хранится информация, он делает запросы и получает то, что ему надо (вот эгоист!). 5. Высокий уровень независимости приложения от организации данных. Проблемы: 1. Поскольку пользователь уже не является единоличным владельцем своей информации возникает целая служба администратора базы данных, которая должна обеспечить нормальную работу: 1.1. Защита данных от разрушения при сбое оборудования (физическая целостность). Обеспечивается созданием резервных копий БД и ведения журнала изменений. 1.2. Защита от некорректных обновлений (логическая целостность). Создаются фильтры для каждого пользователя – то есть программ, допускающих пользователя только к своей информации. АБД для каждого пользователя определяет степень доступа (чтение; чтение/запись) 1.3. Большинство СУБД позволяет устанавливать область допустимых значений на данные. 1.4. Защита данных от несанкционированного доступа (использование ключей, паролей и так далее). Не делай легкий пароль блеять. 1.5. Обеспечение коллективного-параллельного доступа к данным. При параллельном чтении нет проблем. А вот при параллельном изменении данных БИДА. Если один пользователь начинает изменять данные, то работа остальных пользователей блокируется, до момента завершения изменений. Если в процессе внесений изменений произошла ошибка, то вся работа начинается с исходной точки.
Проектирование баз данных
1. Системный анализ 2. Инфологическое проектирование 3. Выбор СУБД 4. Даталогическое проектирование 5. Физическая реализация Проектирование базы данных – это переход от одного уровня абстракции информации к другому, то есть последовательный переход от словестного описания информационного описания предметной области к формализованному описанию объектов предметной области в терминах некоторой модели.
Системный анализ
1. Системный анализ – подробное описание объектов предметной области и взаимосвязи между ними, то есть подробное описание информационной системы На этом этапе определяется: · Какие задачи решает система · Какие ограничения существуют в системе · Какие документы используются в системе · Какие запросы удовлетворяются Пример описания информационной системы «библиотека». · Описание деятельности библиотеки · Выделить основные объекты 1. Книга 1.1. ISBN 1.2. Автор 1.3. Область знаний 1.4. Количество страниц 1.5. Издательство 1.6. Издание 1.7. Год издания 1.8. Количество в библиотеке 2. Читатель 2.1. Номер читательского билета
2.2. ФИО 2.3. Год рождения 2.4. Адрес 2.5. Место работы 2.6. Телефон 3. Экземпляр 3.1. инвентарный номер 3.2. Место расположения 3.3. Вкладыш (кому, когда, дата возврата) Ограничения: 1. Книга может иметь ни одного автора 2. Читатели старше 17 лет (или не старше, если для мелких) 3. Книга 1980 года и выше. 4. Каждый читатель должен иметь на руках не более 5 книг 5. Каждый читатель должен иметь домашний телефон 6. Каждая область знания может содержать много книг, каждая книга может относиться ко многим областям знаний. Пользователи информационной системы 1. Библиотекарь. Его задачи: · Прием и регистрация новых книг · Относит книгу к одной или нескольким областям знаний · Определяет инвентарный номер и размещение · Списывает старые и утерянные книги · Записывает нового читателя в библиотеку · Уничтожает данные о выбывших читателях · Учет выдачи книг 2. Читатель. Задачи читателя: · Просмотр системного каталога по областям знаний, получение полного списка книг · Получение инвентарного номера выбранных книг и дату возврата, если книга на руках · Список книг по авторам · … 3. Администратор. Его задачи: · Должен иметь способ получать сведения о задолжниках · Получить сведения о непопулярных книгах · Получить сведения о наиболее популярных книгах
Инфологическое проектирование (без относительно конкретной СУБД)
Так как проектирование база дранных - это процесс длительный, итерационный, то для получения максимально положительного результата необходимо иметь такое представление модели базы дранных, что бы оно было всеобъемлющим и понятным, особенно заказчику. Для представления инфологической базы данных используются ER модели. КУРСОВАЯ – у меня отличная тема, я молодец
ER-модели В базе модели 3 понятия 1. Сущность – это собирательное понятие некоторого объекта, процесса или явления. Сущность имеет уникальное имя. Множество экземпляров, характеризуются атрибутами. 2. Атрибут – поименованная характеристика сущности, причем набор атрибутов должен быть таким, что бы один экземпляр отличался от другого. Набор атрибутов, однозначно идентифицирующих экземпляр сущности, называется ключевым. 3. Между сущностями могут быть установлены связи – бинарные ассоциации показывающие, каким образом сущности взаимодействуют друг с другом. Всякие графики с has_many belongs_to и прочие.
Выбор СУБД При выборе СУБД большое значение имеет логическая модель, свойственная для данной СУБД. При этом выделяют 3 логические модели:
1. Иерархическая модель данных 2. Сетевая МД 3. Реляционная МД
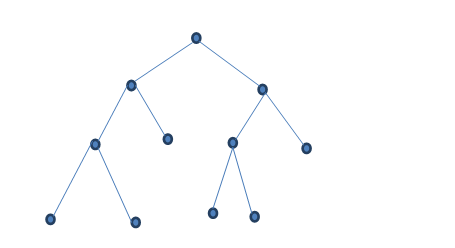
Иерархическая модель данных
Рисунок дерева. Особенности: 1. Могут присутствовать связи has_many, has_one 2. Структура древовидная. 3. Иерархия всегда начинается с корня (i = 1) 4. Корень только 1 5. На нижних уровнях, где i = 2,…,n – порожденные узлы и их может быть сколько угодно. 6. Доступ к каждому порожденному узлу выполняется только через его исходный. 7. Существует единственный иерархический путь доступа к любому узлу, начиная с корня. Достоинства: · На неё хорошо ложатся организационные системы Недостатки: · Сложный длительный поиск
Сетевая модель
Особенности: 1. Любой элемент может быть как исходным, так и порожденным 2. Любой элемент может иметь сколько угодно исходных. 3. Исходный элемент в сетевой модели называется владельцем набора, а порожденный – членом набора. 4. Любой элемент может быть одновременно и в роли владельца и в роли члена набора. 5. Связи могут быть: has_one, has_many, M:1, M:M На сетевую систему хорошо ложатся ИС типа «план графиков» Недостаток: Запутанные пути, и поэтому возникает задача поиска оптимального пути.
Реляционная модель данных (РМД)
РМД - это множество взаимосвязанных таблиц, то есть информация в них представляется множеством таблиц.
Терминология в БД
R:Студент
Номер зачетки – атрибут и первичный ключ. 5 доменов Отношения характеризуются следующими свойствами: 1. Каждое отношения представляет 1 объект (сущность) и состоит из картежей и атрибутов. Совокупность всех возможных значений атрибутов – домен. 2. Всем столбцам таблицы присвоены уникальные имена. 3. В отношении не может быть 2-ух одинаковых строк. 4. Столбцы и строки могут просматриваться в любом порядке. 5. Строки могут быть не упорядочены сверху вниз, а столбцы слева-направо. 6. Каждое отношение должно иметь первичный ключ – это один или несколько атрибутов, который единственным образом идентифицирует каждую строку таблицы. Удаление какого-либо атрибута из сложного ключа нарушает идентификацию. Возможны случаи, когда отношение имеет несколько комбинаций атрибутов, каждый из которых однозначно определяет все кортежи отношений. Эти комбинации называются возможными ключами, и любой из них может быть выбран первичным. Ключи используются для: 1. Исключения дублирования кортежей. 2. Для упорядочения кортежей и как следствие, ускорения обработки информации.
3. Для организации связей между таблицами.
Связывание таблиц
R2: Студент – ФИО| группа | специальность R3: Предметы – название | количество часов R1: Успеваемость – ФИО | дисциплина | оценка Пусть в отношении R1 имеется не ключевой атрибут А, значение которого является значениями ключевого предмета отношения R2, тогда говорят, что атрибут А отношения R1 есть внешний ключ (foreign key). В РБД должна обеспечиваться ссылочная целостность, то есть каждому значению внешнего ключа должна соответствовать строка в связываемых таблицах. При связывании двух таблиц выделяют основную и подчиненную таблицу. Логическое связывание производится при помощи ключа связи – один или несколько атрибутов связи (могут быть ключевыми или обычными). Между двумя таблицами могут быть установлены связи: 1:1 1:M M:1 M:M
Контроль целостности Одной строке таблицы соответствует несколько в другой: 1:M 1. Контроль целостности - каждой записи основной таблицы соответствует 0 или более записей подчиненной таблицы. 2. В подчиненной таблице нет записей, которые не имеют записей в основной таблице. 3. Каждая запись дополнительной таблицы имеет только одну запись родительской таблицы. Правило перехода от инфологической модели к РБД 1. Каждой сущности ставится в соответствие отношение реляционной модели. 2. Каждый атрибут сущности становится атрибутом отношения, возможно с другим именем. Для каждого атрибута отношений при этом определяется тип данных допустимых для этой СУБД. 3. Первичный ключ сущности становится первичным ключом отношения 4. В каждом отношении подчиненной сущности добавляется набор атрибутов основной сущности, являющихся первичными ключом основной сущности (внешний ключ)
Операции над РБК
1. Все данные рассматриваются как таблица, в которой каждая строка имеет один и тот же форма. 2. Схемой отношения R называется конечное множество атрибутов 3. Каждому атрибуту Операции: Включение Для выполнения операции необходимо знать имя отношения, значение нового кортежа, у нового кортежа должен быть уникальный ключ.
Обновление Для выполнения операции необходимо знать имя кортежа, идентификатор одного или нескольких кортежей, подлежащих изменению.
Удаление Для выполнения надо знать имя отношения и идентификатор (ы) отношения (ий) подлежащих отношений.
Обработка отношений На входе одно или несколько отношений, а на выходе новое отношение.
R1, R2 и R3 – односхемные отношения 1. Объединение
2. Пересечение
3. Вычитание
4. Симметричная разность
5. Декартово произведение R1 и R2 могут иметь разные схемы, а R3 включает в себя все атрибуты R1 и R2. Пусть R1 секция волейбол, а R2 отношения экзамены ()
Результатом декартова произведения будет таблица:
6. Выборка (горизонтальная подмножество). На входе одно отношение, например R3 из пункта 5. На выходе новое отношение, построенное по той же схеме, но содержит лишь те кортежи, которые удовлетворяют заданному условию. 7. Проекция (вертикальное подмножество). На входе одно отношение, на выходе новое отношение, построенное, может быть, по другой схеме. 8. Соединение – декартово произведение, но с выбором по некоторому условию, например по совпадению полей. 9. Деление. Пусть Тогда результата R3 определен на атрибутах R1, которых нет среди атрибутов R2.
Пусть делимое это R3 из пункта 5, а делитель.
Язык запросов SQL
Сначала язык назывался SEQUEL (structured English query language) SQL-92 – американский и европейский стандарт. Язык придуман для работы с реляционными базами данных. Основой этого языка является оператор SELECT [distinct] элементы FROM таблица (ы) [WHERE предикат] [GROUP BY поле [HAVING предикат]] [ORDER BY поле];
В квадратных скобках необязательные поля. Элементы – список столбцов, которые выводятся в результат. distinct - означает что в результате не будет дублирования строк FROM – имя таблицы, откуда извлекается информация WHERE – задается условие выбора информации GROUP BY – из исходной таблицы создаются группы, в которых указанное поле имеет одно и тоже значение HAVING – позволяет выводить информацию только о некоторых группах. ORDER BY – результат будет отсортирован по заданному полю.
Пример 1: Выдать название и капитал поставщиков из Казани SELECT название, капитал FROM поставщики WHERE город = Казань Пример 2: выбор номера всех поставок SELECT номер изделия FROM поставки Пример 3: второй пример, но без повторений SELECT DISTINCT номер изделия FROM поставки Пример 4: выдать номера и расход материалов SELECT номер изделия, «расход материала =; Расход» FROM изделия; в скобках можно указать, как будут названы столбцы в результате Пример 5: выдать всю информацию обо всех изделиях SELECT * FROM изделия Пример 6: выдать номера и наименования поставщиков, которые находятся в Москве и имеют некоторый капитал. SELECT номер_поставщика, название FROM поставщики WHERE город= «Москва» and капитал > 0 Можно использовать операторы or, and и not
Пример 7: Вывести номера и капитал поставщиков из Казани и упорядочить по возрастанию SELECT Nn, капитал FROM поставщики WHERE город=”Казань” ORDER BY капитал замечание 1: при сортировке, вместо имени поля можно указывать его порядковый номер SELECT N_из, расход FROM I ORDER BY 2 DESC В данном случае упорядочить по двойке означает упорядочить по расходу, в случае единицы упорядочивалось бы по номеру изделия Замечание 2: упорядочение может производиться по нескольким полям, в этом случае они перечисляются через запятую по старшинству.
Пример 8: выдать сведения об изделиях, расход материалов для которых от 400 до 500 квадратных дециметров SELECT N_из, название, расход FROM изделия WHERE расход BETWEEN 400 AND 500 В данном случае границы включаются так же можно использовать NOT BETWEEN, но в этом случае границы уже не входят
Пример 9: выдать сведения об изделиях расход материалов на которые 200, 400 или 500 дециметров SELECT N_из, название, расход FROM изделия WHERE расход IN (200, 400, 500); Замечание: можно пользоваться NOT IN. В таком случае выдаются все результаты, не попадающие под значения.
Выборка с использованием предиката LIKE. Пример 10: SELECT N_из, название, материал FROM изделия WHERE название LIKE “П*” Этот запрос ищет изделия, название которых начинаются на букву П с любым количеством символом в конце. Предикат LIKE имеет следующий вид: название_столбца LIKE литерная строковая константа столбец обязательно должен типа char “ “ или “?” – один произвольный символ “%” или “*” – любое количество любых символов
Пример 11: выдать все комбинации о таких поставщиках и изделиях, которые размещены в одном и том же городе. SELECT P.*, I.* FROM поставщики, изделия WHERE поставщики.город = изделие.город Замечание: поля в предикате соединения должны быть обязательно одного типа, но не обязательно с одинаковым названием. Таким образом можно соединить 3,4 и более таблиц Пример 12: выдать всю информацию о поставщиках и изделиях, расположенных в одном и том же городе, при этом капитал должен быть более 50 миллионов. SELECT * FROM поставщики, изделия WHEN поставищики.город = изделия.город AND поставищики.капитал > 50 Пример 13: использование подзапросов подзапрос – конструкция (select…from…where) вложенная в другую такую конструкцию Назовите поставщиков поставляющих изделие N7 SELECT поставищики.название FROM поставщики WHERE поставщики.N_п IN (SELECT поставки.N_п FROM поставки WHERE поставки.название = «N7») Если есть подзапрос, то сначала работает он, далее – основной запрос. Аналогично можно написать сложный запрос: SELECT поставищки.название FROM поставщики, поставки WHERE поставки.название = «N7»
Выдать название поставщиков, поставляющих шубы. SELECT поставщики.название FROM поставщики WHERE поставщики.N_п IN (SELECT поставки.N_п FROM поставки WHERE поставки.название IN (SELECT изделия.название FROM изделия WHERE изделия.название= «шуба»))
Сложный запрос: SELECT поставщики.название FROM поставщики, изделия, поставки WHERE изделие.название= «шуба» AND изделие.N_из=поставки.N_из AND поставки.N_п=поставщики=N_п
Пример 15: коррелированный подзапрос (рассмотрим на примере 13). SELECT поставщики.название FROM поставщики WHERE “N7” IN (SELECT поставки.N_из FROM поставки WHERE поставки.N_п=поставщики.N_п) поставщик.N_п это не конкретное значение, а название столбца. Такой подзапрос называется коррелированным. И столбец поставщик.N_п будет рассматриваться строка за строкой.
Пример 16: использование одной и той же таблицы в подзапросе и внешнем запросе. Выдать номера поставщиков, которые поставляют хотя бы одно изделие, поставляемое поставщиком П3.
Пример 17: использование одной и той же таблицы в коррелированном подзапросе и внешнем запросе. Выдать номер всех изделий, поставляемых более чем одним поставщиком. SELECT DISTICT IPX.название FROM IP IPX WHERE IPX.N_п IN (SELECT IPY.N_п FROM IP IPY WHERE IPY.N_п<>IPX.N_п)
Пример 18: запрос использующий квантор существования EXISTS (SELECT…FROM…WHERE) Выдать название всех поставщиков поставляющих изделие N3 SELECT поставщики.название FROM поставщики WHERE EXISTS (SELECT * FROM поставки WHERE поставки.название= «N3» AND поставки.N_п=поставщики.N_п) Помимо EXISTS может быть использован так же NOT EXISTS
Использование стандартных функций
Они следующие: 1. COUNT – количество значений в столбце 2. SUM – сумма значений в столбце 3. AVG – среднее значение в столбце 4. MAX 5. MIN 2 и 3 только для числовых полей. Примеры: 1. SELECT COUNT(*) FROM поставщики выдать количество строк в таблице поставщики 2. SELECT COUNT(DISTINCT N_п) FROM поставки 3.
Пример 19. Функция в подзапросе: выдать капитал, чей капитал ниже среднего SELECT Nn FROM P WHERE капитал < (SELECT AVG(капитал) FROM P);
Функции из коррелированного запроса: выдать номер, капитал и город поставщиков чей уставной капитал больше или равен среднему по своему городу: SELECT Nn, капитал, город FROM P PX WHERE капитал >= (SELECT AVG(капитал) FROM P PY WHERE PY.город=PX.город); PX.город – название столбца, поэтому запрос коррелированный
Пример 21: использования фразы GROUP BY. Перекомпонует указанную таблицу, образуя группы, в которых указанные поля имеют одно и то же значение. Вычислить общий объем и среднюю цену поставок по каждому изделию: SELECT Nиз, SUM(кол), AVG(цена) FROM IP GROUP BY Nиз
SELECT Nиз, SUM(кол), AVG(цена) FROM IP WHERE Nn <> “П2” GROUP BY Nиз В данном случае сначала работает оператор WHERE, а только потом группировка.
Пример использования слова HAVING. Позволяет исключать из результата некоторые группы. HAVING работает только с группировкой и не работает как WHERE. SELECT Nиз, SUM(кол), AVG(цена) FROM IP GROUP BY Nиз HAVING COUNT(*) >=2 Отобрать группы, количество элементов в которых больше 2-ух.
Пример 22 с помощью слова UNION. При объединении двух таблиц обязательно выполнение следующих условий: 1. Таблицы должны иметь одинаковое количество столбцов. 2. Для каждого i (I – номер столбца) типы столбцов должны совпадать. Выдать номер изделий расход материалов на которые составляет более 410 кв дециметров, либо цена более 5000 рублей. SELECT Nиз FROM I WHERE расход > 410 UNION SELECT Nиз FROM IP WHERE цена > 5000 Первая таблица выдается без изменений, а второй запрос добавляет только то, чего нет. С помощью UNION можно объединять любое количество запросов.
Запросы по нескольким таблицам, объединяемым с помощью оператора JOIN. Объединение таблиц по условию (внутреннее объединение).
FROM T1 INNER JOIN T2 ON (T1.П1 <оператор> T2.П1) [AND/OR (T1.П2 <опер> T2.П2)] [AND/OR (T1.П3 <опер> T2.П3)]
SELECT P.Nn, P.назв, P.Тип FROM P INNER JOIN IP ON (P.Nn=IP.Nn) from p, ip where p.Nn=IP.Nn
Левое внешнее объединение Включаются все записи из первой левой таблицы, даже если нет совпадающих из второй таблицы.
Правое внешнее объединение Включаются все записи из второй правой таблицы, даже если нет совпадающих в левой.
Операторы языка SQL для работы с таблицами 1. Создание таблицы – CREATE TABLE <name> (имя_столбца тип_данных [not null],…, имя_столбца тип_данных [not null]) NOT NULL – для полей, которые не могут быть пустыми, допустим для первичного ключа. 2. Удаление таблицы - DROP TABLE <name> 3. Изменение таблицы – ALTER TABLE <name> (ADD/MODIFY/DROP <имя_столбца>[<тип_данных>][not null],…, ADD/MODIFY/DROP <имя_столбца>[<тип_данных>][not null]) 4. Создание индекса – CREATE INDEX <имя_индексного_файла> ON <имя_таблицы> (<имя_столбца>[ASC/DESC],…, <имя_столбца>[ASC/DESC]); 5. Удаление индекса – DROP INDEX <имя_индексного_файла> 6. Представления – CREATE VIEW <имя_представления> [(<имя_столбца>[,<имя_столбца>]..)] AS <оператор SELECT>
Обновление записи в таблице: UPDATE <имя_таблицы> SET поле = выражение [, поле = выражение …] [where предикат] Пример: UPDATE SET Адрес = “Волкова 15”, город = “Щелково” WHERE название = «Биржа»
Удаление записей – DELETE На след неделе контрольная – первый пункт оператор SELECT второй - одна из последних тем.
СУБД Microsoft Access Он позволяет 1. Хранить данные в виде таблиц. 2. Легко связывать данные, находящиеся в разных таблицах. 3. Дает возможность работать с данными других источников. 4. Позволяет устанавливать связь с другими приложениями MS Office (word, excel). 5. Возможность создавать свои приложения с помощью языка VBA (Visual Basic Application). Одним словом MA это функционально-полная реляционная СУБД, в которой предусмотрены все необходимые средства для определения и обработки данных, а также для управления ими при работе с большими объемами информации. МА спроектирован так, что может использоваться как самостоятельная СУБД на отдельном персональном компьютере и так же работать в сети в режиме «клиент-сервер» (это значит, что он имеет надежные средства защиты информации).
Основные объекты МА Таблица – используется для хранения информации, которая вводится в базу данных. Для каждой таблицы может быть определен первичный ключ, и может быть проведено индексирование. Запросы – позволяют создавать условия для отбора данных, а так же вносить изменения в данные.
Составление сложных запросов 1. Создание таблицы по результатам запроса. a) Открыть окно запросов и сформировать запрос. b) Запрос -> создать таблицу -> (система попросит ввести имя) ввести имя. 2. Запрос с добавлением полей одной таблицы в конец другой таблицы. a) Сформировать запрос в режиме конструктора b) Запрос -> добавить -> имя таблицы, в конец которой будут добавляться новые поля c) В бланке запросов в строке добавить указываются названия столбцов, в которые идет добавление 3. Обновление записей с помощью запросов. a) Открывается окно запросов в режиме конструктора b) перенести то, что меняем c) Запрос->обновить 4. Удаление записей по заданному условию. a) Открыть окно запросов в режиме конструктора. b) Запрос-> удалить. 5. Создание вычисляемых полей a) Открывается окно в режиме конструктора. b) В бланк запросов переносятся поля ФИО и оклад. c) Формируются остальные 3 столбца. Налог: [Оклад]*0,13; К выдаче: [Оклад]-[Налог]; Роспись: ‘ ‘ d) Сохранить результаты в новой таблице e) Создать по этой таблице отчет.
Формы
Позволяет создать удобный пользовательский интерфейс для работы с данными. Формы это объект, который в основном предназначен для ввода данных, отображение их на экране или управление работой приложения. Формы можно распечатать. С помощью форм, в ответ на некоторые события (например, нажатие кнопки) можно запустить макрос или процедуру.
Отчет
Отчет – объект, предназначенный для создания документа, который в последствие может быть распечатан или включен в документ другого приложения. Макрос – объект, предназначенный для структурированного описания одного или нескольких действий. Модуль – объект, содержащий программы на VBA, позволяющие разбить на более мелкие действии те действия, которые определяются макросом или обнаруживать ошибки и обрабатывать их.
СУБД FoXPro Архитектура
имяфайла.dbf – файл базы данных имя.prg – программы, которые работают с таблицами имя.idx – индексные файлы
Выражение Константы, переменные функции, которые соединяются арифметическими знаками, скобками. Знаки отношений (<,>,#,=,=>,=<) могут быть применены к датам, числам и символам. «Петров А» = «Петров А» - дает истину «Петров А» = «Пет» - дает истину, потому что сравнение идет по правому операнду, посимвольно «Пет» = «Петров А» - дает ложь «==» - сравнение на полное тождество (в этом случае сравнивается и длина слова и содержание).
Все функции разделены на 14 групп. 1. Математические: синусы, косинусы и прочее. 2. Строковые 3. Работа с датами 3.1. Date() – выдает текущая дату (системную) 3.2. day(<выражение типа date>) – выделение для из даты, т.е. число месяца 3.3. month () – 04 3.4. year 4. Функции преобразования данных 4.1. Str(<числовое выражение>, [длина], [<количество десятичных знаков>]) – перевод числа в строку. Если не указывать параметры в квадратных скобках, то число остается в том же виде, т.е. не сокращается.
Подпрограммы пользователя
процедуры могут быть 1.1. внешние 1.2. внутренние
Внешние процедуры Хранятся в виде отдельного командного файла. do <имя_файла.prg> [with <параметры>] Если в процедуре есть параметры, то они должны быть заданы в ее первой строке. parametrs <список параметров> Преимущества внешних процедур: 1. Программа состоит только из вызовов внешних процедур, т.е. все очень компактно и читабельно Недостаток: При вызове каждой процедуры идет обращение к внешнему устройству, что является самой длиной операцией, тратится много времени.
Внутренние процедуры Чтобы сократить количество обращений к внешнему устройству и сэкономить время используются внутренние процедуры, которые записываются в теле основной программы и загружаются в оперативную память вместе с ней. Если процедуры друг за другом, то они записываются так: procedure <имя процедуры> [parameters <список параметров&g |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 3738; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.119.117.128 (0.018 с.) |



 ставится в соответствии множество значений
ставится в соответствии множество значений  – домен.
– домен.




 – делимое, а
– делимое, а 





