
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Разработка форм для сбора информации
Инструментом реализации методов сбора информации являются предварительно разработанные документы, в качестве которых могут выступать формы для регистрации наблюдений, анкета (вопросник) и т.п. Традиционная схема документа включает три блока: - введение (преамбула); - реквизитная часть (паспортичка); - основная часть. Во введении в краткой форме указывается, кто и с какой целью проводит исследование, дата, время и место его проведения, краткая информация о фирме. При составлении анкеты желательно заверить в анонимности опроса и поблагодарить респондента. В реквизитной части приводится информация о респондентах: для частных лиц – возраст, пол, принадлежность к определенному классу, род занятий, семейное положение, имя и адрес; для организаций – размер, месторасположение, направление производственно-хозяйственной деятельности, положение респондента в организации, его имя. При наблюдении реквизитов используется меньше. В основной части представлен перечень вопросов, позволяющих получить информацию для проведения МИ. Количество вопросов должно быть оптимальным, т.е. обеспечивающим полноту информации, но не чрезмерным (отталкивает респондентов). Ключевые слова при составлении вопросника:
Разработка выборочного плана При проведении МИ важно определиться с группой, среди членов которой оно проводится. Такая группа в статистике называется генеральной совокупностью (или просто совокупностью). Существует два метода сбора информации: - сплошной – обследование всех единиц генеральной совокупности (например, перепись населения, инвентаризация на предприятии, динамика объемов продаж своей продукции в магазинах и т.д.). Характеристики метода: дорого, в большинстве случаев его использование необоснованно, часто дает существенные ошибки (парадокс, но чем больше регистраторов, тем меньше за ними контроль и ниже уровень их подготовленности); - выборочный – сведения получаются от части единиц генеральной совокупности (невозможно изучить мнение всех детей 3-5 лет относительно какой-либо игрушки). Характеристики метода: экономичен по сравнению со сплошным методом, позволяет получить достаточно достоверные сведения, предполагает привлечение специалистов.
При определении выборки важно обеспечить ее количественную и качественную представительность (репрезентативность). Под количественной репрезентативностью понимается обеспечение в выборке такого числа единиц, которое может дать объективную картину изучаемого явления. Под качественной репрезентативностью понимают обеспечение в выборке максимально возможного числа групп в генеральной совокупности (наилучший вариант, когда в выборке представлены все изучаемые группы пропорционально их доле в генеральной совокупности) (рис. 2.1).
Рис. 2.1. Определение выборки
Полученные от выборки данные могут несколько не соответствовать данным, которые можно было бы получить при изучении всех членов совокупности. Различие между данными, полученными от выборки, и истинными данными называется ошибкой выборки. Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки. Формирование выборки основывается на знании контура выборки, под которым понимается список всех единиц совокупности, из которого выбираются единицы выборки. (Например, совокупность – все автомастерские города. Однако в данном случае невозможно определить точно всю совокупность, так как существуют нелегальные и полулегальные автомастерские. В связи с этим в контур выборки включаются только те мастерские, из которых формируется выборка) Методы формирования выборки: 1. Вероятностные (случайные) – все единицы совокупности имеют шанс быть включенными в выборку (предполагает знание всех единиц совокупности): - простой случайный отбор (выборка может формироваться вслепую (тянутся карточки из коробки) или с помощью таблицы случайных чисел); - систематический отбор (начальная точка случайная, а потом устанавливается интервал, например каждый 200-й телефонный номер); - кластерный отбор (основан на делении совокупности на подгруппы (кластеры), каждая из которых представляет совокупность в целом. Например, рынок делится на области, исследуется совокупность отдельной области и результаты переносятся на весь рынок);
- стратифицированный отбор (основан на делении совокупности на подгруппы (страты), которые индивидуальны и не отражают общую картину совокупности (по сути, это сегменты рынка). Из каждой подгруппы формируется выборка. Например, деление потребителей по уровню дохода). 2. Невероятностные (неслучайные) – когда невозможно рассчитать вероятность включения в выборку единицы совокупности: - метод отбора на основе принципа удобства (например, с точки зрения минимальных затрат времени и усилий, доступности респондентов, близости); - на основе суждения (на основе мнения квалифицированных специалистов относительно состава выборки); - в процессе опроса (исходя из предложений респондентов, уже подвергнувшихся опросу. Сначала формируется небольшая выборка, которая по мере опроса увеличивается); - на основе квот (исходя из установленной квоты на количество респондентов, например должно быть опрошено 50 покупателей, подошедших к прилавку). На практике исследователи нередко используют комбинацию перечисленных методов. Размер выборки определяется числом изучаемых единиц и редко зависит от размера совокупности (но необходимо обеспечить репрезентативность выборки. Например, изучать спрос на специализированные издания перед входом в метро неразумно). Существуют различные подходы к определению объема выборки: - бездоказательно принимается, что выборка должна охватывать 5% совокупности; - согласовывается количество исследуемых человек исходя из оговоренных с заказчиком условий; - объем выборки ограничивается предусмотренными затратами на проведение МИ; - на основе статистического анализа, когда предполагается определение минимального объема выборки с учетом требований к надежности и достоверности получаемых результатов. Сбор данных Способы сбора данных: - обеспечение сбора данных собственными силами (отвлекает сотрудников от выполнения основных функций); - создание для этого специальной группы (обычно комплектуется специалистами не очень высокой квалификации, например студентами, с которыми было проведено несколько тренировочных занятий); - привлечение специализированной коммерческой компании (положительными моментами в этом случае являются наличие у компании опыта проведения МИ, привлечение высококвалифицированного персонала, быстрота и качественность исследования). При сборе данных могут возникнуть вневыборочные ошибки (не путать с ошибками выборки!). Например: - выбор неверных элементов выборки для взятия интервью; - неучет мнения тех элементов выборки, которые по каким-либо причинам не были опрошены (отказался отвечать на вопросы интервьюера, не было дома и т.д.); - ложные оценки, даваемые респондентами преднамеренно; - фальсификация полученных данных со стороны недобросовестных интервьюеров; - технические ошибки добросовестных интервьюеров (например, при переписывании) и др. В отличие от ошибок выборки вневыборочные ошибки не могут быть измерены, поэтому важно предотвратить их.
Все выборочные ошибки можно разделить на: - ошибки лиц, определяющих сбор данных; - ошибки респондентов; - преднамеренные; - непреднамеренные.
Анализ данных Анализ данных начинается с преобразования исходных данных, т.е. их кодирования и приведения к более сжатому виду, удобному для анализа (обычно в матричной форме). Этот процесс называется процессом табуляции. Далее проводится статистический анализ с целью выявления сущности, закономерностей, тенденций развития исследуемых явлений. Анализ служит исходной точкой прогнозирования, планирования и управления этими явлениями. Виды статистического анализа, используемые при МИ: 1. Дескриптивный анализ. Использует две группы мер: 1) меры центральной тенденции – описывают типичного респондента или типичный ответ): - мода – наиболее часто встречаемая величина в наборе данных, наиболее типичное значение среди данных (не значит, что большинство!). Например:
Ответ: мода = 100;
- медиана (центральная величина) – значение признака, занимающее срединное место в ряду значений данного признака, расположенных в ранжированном порядке) (в нашем примере медиана = 99); - средняя – рассчитывается как средняя арифметическая величина (взвешенная и невзвешенная) или средняя геометрическая величина. При этом учитывается каждое значение признака: средняя арифметическая невзвешенная: средняя арифметическая взвешенная: средняя геометрическая: например:
Тогда т.е. средний темп составляет + 3,64%;
2) меры вариации (рассеивания) – описывают степень схожести или несхожести респондентов или ответов с типичными респондентами или ответами. При высокой схожести ответов говорят о малой вариации (узкая кривая распределения), при низкой схожести ответов – о высокой вариации (широкая кривая распределения): - размах вариации – разница между наибольшим и наименьшим значениями признака (учет только экстремальных значений); - среднее отклонение – учитывает отдельное отклонение каждого значения признака от среднего значения измеренного признака.
Различают простое и взвешенное среднее отклонение: п ростое среднее отклонение: взвешенное среднее отклонение:
- среднее квадратическое отклонение (стандартное отклонение) – обобщающая статистическая характеристика вариации значений признака. Расчет похож на расчет среднего отклонения. Различают простое и взвешенное среднее квадратическое отклонение: простое среднее квадратическое отклонение: взвешенное среднее квадратическое отклонение: - дисперсия (s²) – возведение в квадрат среднего квадратического отклонения. 2. Статистический вывод. Основан на статистическом анализе результатов выборочных исследований для получения выводов обо всей совокупности в целом. 3. Анализ различий. Позволяет сравнивать результаты исследования двух или более групп респондентов либо вариантов ответов в одной группе респондентов. 4. А нализ связей. Позволяет выявить систематические связи переменных, направления и степень их воздействия друг на друга. 5. Предсказательный анализ. Используется для прогнозирования развития событий в будущем. Последние четыре вида статистического анализа базируются на использовании методов дескриптивного анализа.
Оформление заключительного отчета
|
||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2022-09-03; просмотров: 49; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.224.39.74 (0.034 с.) |
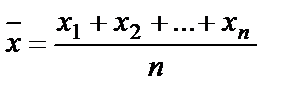 ,
,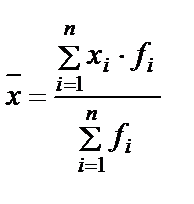 ,
,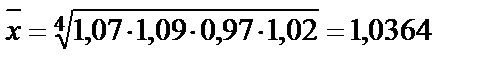 ,
, 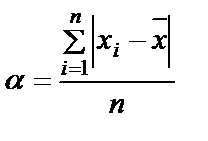 ,
, ;
;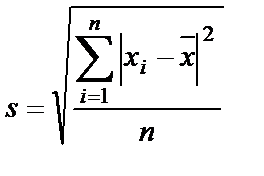 ,
,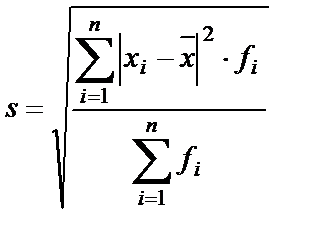 ;
;


