
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Доверительных областей для параметровСодержание книги
Поиск на нашем сайте 3.1. Доверительные интервалы и доверительные вероятности Выборочные параметры могут служить приближенными оценками соответствующих генеральных параметров. Погрешность такой оценки, как об этом говорилось ранее, тем меньше, чем больше объем выборки. Как можно оценить эту погрешность более строго? Все выборочные параметры ( Известно:
Но, к сожалению, обычно и F (x), и j(х) неизвестны. Задачу решают по другому. Находят с заданной вероятностью границы возможных значений изучаемого параметра. Эту заданную вероятность называют доверительной вероятностью. В зависимости от конкретных обстоятельств в качестве доверительной вероятности берут р = 0,95; 0,98; 0,99; реже р = 0,90 или р = 0,999. Иногда вместо доверительной вероятности рассматривают связанную с ней величину – так называемый уровень значимости a=1 Соответствующие доверительной вероятности границы значений параметра называют доверительными границами, а образуемый ими интервал – доверительным интервалом. Представляет интерес оценка генерального среднего и генеральной дисперсии с точки зрения определения их доверительных границ. 3.2. Оценка генерального среднего Предполагается, что наблюдаемая случайная величина имеет нормальное распределение. Для оценки генерального среднего желательно знать генеральную дисперсию s2. Но ее нельзя найти из наблюдений и вместо нее обычно берут выборочную дисперсию S 2. Вводят величину
где Таким образом, величина t – это не что иное, как нормированное отклонение Функция распределения величины t называется t –распределением, или распределением Стьюдента. Она зависит только от числа f степеней свободы, по которым подсчитана дисперсия S 2. Если дисперсия S 2 и среднее
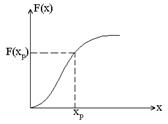
По форме графики напоминают плотность нормального распределения, но при t ® ±¥ они значительно медленнее сближаются с осью абсцисс. Представляет интерес рассмотрение одной из числовых характеристик случайной величины, которую называют квантиль. Квантилем хр случайной величины Х с функцией распределения F (x) называют решение уравнения
где вероятность Р – заданная величина (см. кривую распределения).
Величины квантилей представлены в специальных таблицах для соответствующих значений вероятности Р. Возвращаясь к распределению Стьюдента, обозначим tp – квантиль t –распределения. Если
Преобразуем поэтапно двустороннее неравенство. Для этого: 1) Берем левую границу:
2) Рассматриваем правую границу:
Окончательно получаем:
что можно представить в виде:
Таким образом, с вероятностью р – генеральное значение математического ожидания заключается в границах между Распределение Стьюдента позволяет оценивать генеральное среднее (математическое ожидание), когда генеральная дисперсия неизвестна. При этом число наблюдений может быть очень малым, даже равным двум. Конечно, скудость информации сказывается на результатах – доверительные границы получаются довольно широкими. Поэтому везде, где это только возможно, нужно стараться увеличивать число степеней свободы у выборочной дисперсии. Пример. Выборочное среднее Тогда учитывая, что
После вычислений получаем окончательные значения доверительной оценки генерального среднего
В некоторых задачах требуется найти одностороннюю доверительную оценку генерального среднего, т.е. оценку только сверху или только снизу. При этом задача решается аналогично.
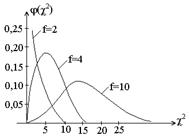
3.3. Оценка генеральной дисперсии Для оценки генеральной дисперсии s2 используется выборочная дисперсия S 2. Эта дисперсия в силу случайности выборки сама является случайной величиной. Но математическим ожиданием для S 2 служит генеральная дисперсия s2. Отсюда следует, что s2 можно оценить по S 2, если известно распределение величины S 2. Распределение величины S 2 можно получить с помощью так называемого распределения Пирсона (или c2 – распределения). Для выборки с элементами х 1, х 2,…, х n через c2 обозначается сумма
В этой сумме есть связь
Нетрудно установить связь между величинами c2 и S 2:
Теоретически доказано и подтверждено практикой, что для уровня значимости a = 1 - р доверительная оценка величины c2 имеет вид
где Отсюда
или после преобразований
Таким образом получили двустороннюю доверительную оценку для генеральной дисперсии s2.
3.4. Проверка статистических гипотез применяется для того, чтобы использовать полученную по выборке информацию для суждения о законе распределения генеральной совокупности. При этом имеется определенное представление о неизвестном вероятностном законе F (x) и его параметрах, которое формулируется в виде статистической гипотезы, обозначаемой символом Н о (нулевая, или основная гипотеза). Запись С помощью статистических методов или критериев для проверки гипотезы устанавливается, соответствуют ли взятые из выборки данные выдвинутой гипотезе или нет, т.е. нужно ли принять или отвергнуть гипотезу. Если вид функции распределения F (x) задан отдельными параметрами и если гипотеза строится именно по этим неизвестным параметрам, то говорят о параметрических гипотезах. Для проверки гипотезы вводят критерий – правило, позволяющее принять или отвергнуть гипотезу в соответствии с данными эксперимента. Особое положение занимает проверка адекватности модели регрессии. Адекватная модель регрессии, как правило, неизвестна. Подбирая, например, параболическую модель мы не знаем заранее, какого она должна быть порядка, на какой степени следует остановиться. Не знаем мы также, сколько факторов надо учитывать. Поэтому обычно начинают с моделей первого порядка – линейных моделей и затем повышают порядок модели (степень многочлена) до тех пор, пока при сравнительно небольшом числе параметров модель не станет адекватной, т.е. гипотеза об ее истинности не будет противоречить данным эксперимента (если это вообще возможно, если существует такая параболическая модель). Для проверки адекватности модели обычно используют критерий Фишера.
3.4.1. Гипотеза о равенстве дисперсий. Критерий Фишера Сравнение двух или нескольких выборочных дисперсий является одной из важнейших задач статистической обработки наблюдений. Основной выясняемый вопрос при этом – можно ли считать сравниваемые выборочные дисперсии оценками одной и той же генеральной дисперсии. Начнем со сравнения двух выборочных дисперсий Распределением Фишера (или F –распределением) называется распределение случайной величины:
Это распределение зависит только от f 1 и f 2 при этом
На рисунке приведены графики плотности F –распределения при сочетаниях (f 1, f 2) = (10,4) и (10,50). Как и в случае c2–распределения, плотность рассматривается лишь на положительной полуоси, т.е. при 0 £ F £ ¥. В литературе даются квантили F1–р для некоторых наиболее употребительных уровней значимости a =
Например: F 0,95(4,3) = 9,1; F 0,05(3,4) = Вернемся к рассмотрению нулевой гипотезы, согласно которой
При этом будем обозначать через
Нулевая гипотеза отвергается, если Пример. При изучении стабильности температуры в термостате получены данные 21,2; 21,8; 21,3; 21,0; 21,4; 21,3. К стабилизатору температуры применено некоторое усовершенствование, после чего (на другом режиме) получены данные: 37,7; 37,6; 37,6; 37,4. Можно ли при уровне значимости a = 0,05 считать усовершенствование эффективным? Эффективность стабилизаторов температуры, очевидно, зависит от даваемой ими дисперсии температур. Таким образом, задача состоит в том, чтобы сравнить генеральные дисперсии данных выборок температур. Вычисляем выборочные дисперсии, уменьшив для удобства вычислений все данные на 21 в первом случае и на 37,5 – во втором:
Отсюда Числа степеней свободы f 1 = 5, f 2 = 3. Усовершенствование может лишь уменьшить дисперсию, поэтому применяем односторонний критерий значимости. По таблице квантилей распределения Фишера находим F 0,95(5,3) = 9,0. Мы видим, что
3.5. Проверка адекватности уравнения регрессии (математической модели) После завершения вычислений, связанных с получением оценок коэффициентов регрессии, проверяется адекватность полученного уравнения. Для проверки значимости (адекватности) уравнения регрессии в целом с использованием F –критерия Фишера общую дисперсию Общая дисперсия У:
где n – объем выборки; у i (i = 1, 2,…, n) – выборочные значения у. Остаточная дисперсия (дисперсия неадекватности)
т.е. показатель ошибки предсказания уравнением регрессии результатов опытов, где ур i – расчетное значение величины у, вычисленное по полученному уравнению регрессии (двойка в знаменателе) – количество переменных в уравнении регрессии. Качество предсказания определяют, сравнивая Для заданной величины уровня значимости Для того, чтобы уравнение регрессии адекватно описывало результаты экспериментов с определенной доверительной вероятностью «р» требуется выполнение следующего условия: F < Fтаб.
Пример. Данные эксперимента
Расчеты по известной методике позволяют получить для уравнения регрессии a = 3,73; b = 0,53, т.е. линейное уравнение регрессии имеет вид:
Оценим значимость этого уравнения с использованием критерия Фишера. Для этого определяем общую дисперсию у:
(при этом Остаточная дисперсия
Откуда
Определяем
Для 5 % уровня значимости (a = 0,05) и для f 1 = 7, a f 2 = 6, F таб = 4,21 F < F таб, т.е. уравнение регрессии адекватно.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 303; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.169 (0.013 с.) |

 , S 2) являются случайными величинами и их отклонения от генеральных параметров (погрешности) также будут случайными. Поэтому вопрос об оценке этих отклонений носит вероятностный характер и можно лишь указать вероятность той или иной погрешности, т.е. найти вероятность того, что некоторая случайная величина Dn (отклонение выборочного параметра n от исследуемого генерального) не превосходит по абсолютной величине некоторого заданного числа e. Задача легко решается, если известны функции распределения F (x) или j(х) величины Dn.
, S 2) являются случайными величинами и их отклонения от генеральных параметров (погрешности) также будут случайными. Поэтому вопрос об оценке этих отклонений носит вероятностный характер и можно лишь указать вероятность той или иной погрешности, т.е. найти вероятность того, что некоторая случайная величина Dn (отклонение выборочного параметра n от исследуемого генерального) не превосходит по абсолютной величине некоторого заданного числа e. Задача легко решается, если известны функции распределения F (x) или j(х) величины Dn. .
. .
. ,
,
 ,
,
 или
или  .
. ;
;  ;
; ; откуда
; откуда  .
. ;
;  ;
; ; или, в итоге
; или, в итоге 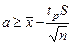 .
. ,
, .
. и
и  , где величина tр определяется по таблицам распределения Стьюдента для заданной доверительной вероятности р и определяемого числа степеней свободы f = n
, где величина tр определяется по таблицам распределения Стьюдента для заданной доверительной вероятности р и определяемого числа степеней свободы f = n  .
. найдено по трем наблюдениям, а выборочная дисперсия определена как S 2 = 0,25, при этом f = 3 - 1 = 2. В качестве доверительной вероятности возьмем р = 0,95, Величину tp найдем из таблицы Стьюдента, где для f = 2 и р = 0,95 находим tp = 4,30.
найдено по трем наблюдениям, а выборочная дисперсия определена как S 2 = 0,25, при этом f = 3 - 1 = 2. В качестве доверительной вероятности возьмем р = 0,95, Величину tp найдем из таблицы Стьюдента, где для f = 2 и р = 0,95 находим tp = 4,30. , доверительная оценка определится как:
, доверительная оценка определится как: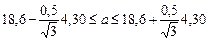 .
. .
. .
.
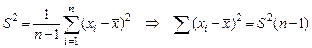
 или
или  .
. ,
, и
и 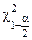 – соответствующие квантили распределения Пирсона.
– соответствующие квантили распределения Пирсона.
 .
.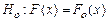 означает допущение («гипотезу») о том, что F o(x) есть функция распределения генеральной совокупности.
означает допущение («гипотезу») о том, что F o(x) есть функция распределения генеральной совокупности. и
и 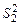 , имеющих соответственно f 1 и f 2 степеней свободы. Будем считать, что первая выборка сделана из генеральной совокупности с дисперсией
, имеющих соответственно f 1 и f 2 степеней свободы. Будем считать, что первая выборка сделана из генеральной совокупности с дисперсией  , вторая – из генеральной совокупности с дисперсией
, вторая – из генеральной совокупности с дисперсией  . Выдвигается нулевая гипотеза – гипотеза о равенстве генеральных дисперсий
. Выдвигается нулевая гипотеза – гипотеза о равенстве генеральных дисперсий 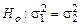 . Для того, чтобы отвергнуть эту гипотезу, нужно доказать значимость расхождения между
. Для того, чтобы отвергнуть эту гипотезу, нужно доказать значимость расхождения между  . В качестве критерия значимости обычно используется так называемое распределение Фишера.
. В качестве критерия значимости обычно используется так называемое распределение Фишера.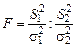 .
. .
.

 .
. . В этом случае
. В этом случае 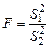 и, следовательно, F –распределение может быть использовано непосредственно для оценки отношения
и, следовательно, F –распределение может быть использовано непосредственно для оценки отношения  . При этом должно выполняться двустороннее неравенство
. При этом должно выполняться двустороннее неравенство . (*)
. (*) заведомо невозможно, то нужно применять односторонний критерий, сравнивая отношение
заведомо невозможно, то нужно применять односторонний критерий, сравнивая отношение 
 ,
,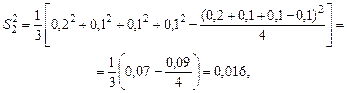
 .
. сравнивают с остаточной дисперсией
сравнивают с остаточной дисперсией  .
. ,
, ,
,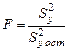 (делят всегда большую величину на меньшую).
(делят всегда большую величину на меньшую).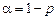 по таблице критерия Фишера (и для соответствующих значений степеней свободы f 1 и f 2) определяют табличное значение критерия F таб.
по таблице критерия Фишера (и для соответствующих значений степеней свободы f 1 и f 2) определяют табличное значение критерия F таб. .
.
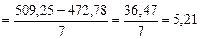
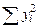 и
и  взяты из таблицы, по которой определяют коэффициенты регрессии).
взяты из таблицы, по которой определяют коэффициенты регрессии). и находится с помощью таблицы
и находится с помощью таблицы







 .
. .
.


