Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Иерархическая кластеризация на основе дендрограммы⇐ ПредыдущаяСтр 15 из 15
Функция Z = linkage(Y, ’method’) возвращает иерархическое дерево кластеров. Ее аргументами является вектор Y, возвращаемый функцией pdist. Строка ‘method’ задает метод кластеризации:
На первом шаге ближайшие объекты объединяются парами и каждая найденная пара рассматривается как новый объект. Каждый следующий объект присоединяется или к одному из исходных, или к одной из ранее образованных групп, группы могут объединяться. Матрица Z имеет (m -1) строку и 3 столбца. Первые 2 столбца – номера объединяемых объектов, третий – расстояние между ними. Функция dendrogram(Z) создает графическое отображение полученного дерева кластеров. Функция cophenet(Z,Y) возвращает аналог коэффициента корреляции, характеризующий качество разбиения: чем ближе к 1, тем лучше. Функция inconsistent(Z) возвращает коэффициенты несовместимости для каждого уровня дерева и тоже характеризует качество разбиения. Функция T = cluster(Z, cutoff) или T = cluster(Z, cutoff, depth) объединяет все перечисленные функции. Здесь
Функция T = clusterdata(X, cutoff) объединяет все перечисленные функции. В Документе 8.3 сформирована 2-мерная выборка из ранее рассмотренного примера и приведены варианты обращения к нескольким стандартным функциям ИМС MatLab, на рис.8.3, 8.4 – экранный вывод.
Рис.8.3. Экранный вывод в Документе 8.3
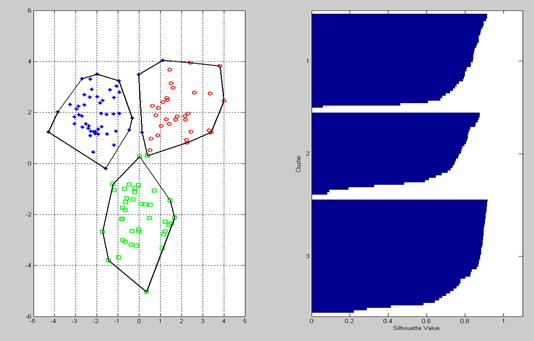
Рис.8.4. Дендрограмма - графический вывод в Документе 8.3 Оценка качества разделения Качество разбиения обычно характеризуют отношением среднего расстояния между центрами классов к среднему расстоянию элементов внутри каждого класса от его центра. В версиях ИМС MatLab, начиная с 7x, этой цели служит специальная функция silhouette(X0,T,’distance’,’sqEuclidean’). Результат вычислений в Документе 8.2 с использованием этой функции приведен на рис.8.5.
Рис.8.5. Результат вычислений в Документе 8.2 с использованием функции silhouette
Задания на лабораторную работу 5. Смоделировать две 3-мерные выборки (n =100) из нормального закона с различными средними и ковариационными матрицами. 6. Произвести кластеризацию полученных данных 3 различными способами. 7. Проанализировать зависимость результатов кластеризации от расстояния Махаланобиса между исходными классами. 8. Перейти к плоскости главных компонент и изобразить на ней зоны притяжения каждого из классов. Контрольные вопросы Знать основные определения теории кластеризации в линейном и нелинейном вариантах, технологии методов k средних и динамических сгущений, подход на основе дендрограмм. ЗАКЛЮЧЕНИЕ Электронное учебное пособие по дисциплине «Интеллектуальный анализ данных» разработано в соответствии с федеральным государственным образовательным стандартом (ФГОС ВО 3++) по уровню магистратуры. В электронном учебном пособии содержится систематическое изложение основ современных методов анализа многомерных данных. Содержание данного электронного учебного пособия соответствует рабочей программе дисциплины и основано на материалах отечественных и зарубежных исследований, включая современные публикации. БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Большаков А.А., Каримов Р.Н. М. Методы обработки многомерных данных и временных рядов. Учебное пособие для ВУЗов. - Горячая линия-Телеком, 2015. – 522 с. 2. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики.- М.: Наука, 1965.- 464с.
3. Дьяконов В., Круглов В. Математические пакеты расширения MATLAB. Специальный справочник. - СПб: Питер, 2001 4. Мхитарян В.С. Анализ данных. Учебник для академического бакалавриата. - М.: Юрайт, 2016. 5. Советов Б.Я., Цехановский В.В. Информационные технологии. Учебник для прикладного бакалавриата. - М.: Юрайт, 2016. 6. Чубукова И. Data Mining. - М.: Юрайт, 2016
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-03-09; просмотров: 136; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.58.121.131 (0.008 с.) |