
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Статистическая обработка данных в Microsoft ExcelСодержание книги
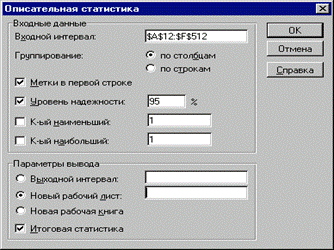
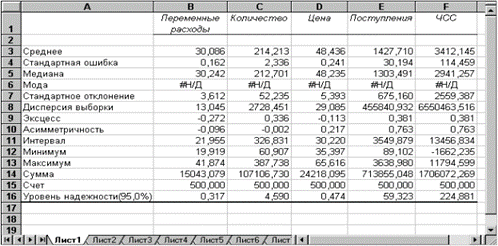
Поиск на нашем сайте Статистические функции НАКЛОН Возвращает наклон линии линейной регрессии Инструмент анализа данных "Описательная статистика" Чем больше характеристик распределения случайной величины нам известно, тем точнее мы можем судить об описываемых ею процессов. Инструмент "Описательная статистика" автоматически вычисляет наиболее широко используемые в практическом анализе характеристики распределений. При этом значения могут быть определены сразу для нескольких исследуемых переменных. Определим параметры описательной статистики. Для этого необходимо выполнить следующие шаги. Результатом выполнения указанных действий будет формирование отдельного листа, содержащего вычисленные характеристики описательной статистики для исследуемых переменных. Выполнив операции форматирования, можно привести полученную ЭТ к более наглядному виду (рис.5).
Вторая строка ЭТ содержит значения стандартных ошибок Медиана - это значение случайной величины, которое делит площадь, ограниченную кривой распределения, пополам (т.е. середина численного ряда или интервала). Как и математическое ожидание, медиана является одной из характеристик центра распределения случайной величины. В симметричных распределениях значение медианы должно быть равным или достаточно близким к математическому ожиданию. Мода - наиболее вероятное значение случайной величины (наиболее часто встречающееся значение в интервале данных). Для симметричных распределений мода равна математическому ожиданию. Иногда мода может отсутствовать. В данном случае ППП EXCEL вернул сообщение об ошибке. Таким образом, вычисление моды не представляется возможным. Эксцесс характеризует остроконечность (положительное значение) или пологость (отрицательное значение) распределения по сравнению с нормальной кривой. Теоретически, эксцесс нормального распределения должен быть равен 0. Однако на практике для генеральных совокупностей больших объемов его малыми значениями можно пренебречь. Асимметричность (коэффициент асимметрии или скоса - s) характеризует смещение распределения относительно математического ожидания. При положительном значении коэффициента распределение скошено вправо, т.е. его более длинная часть лежит правее центра (математического ожидания) и обратно. Для нормального распределения коэффициент асимметрии равен 0. На практике, его малыми значениями можно пренебречь. Для вычисления коэффициента асимметрии используется статистическая функция СКОС (). Формула для проверки значимости показателя эксцесса задается аналогичным образом. Числителем этой формулы будет функция ЭКСЦЕСС (), а знаменателем соотношение, реализованное средствами EXCEL. Оставшиеся показатели описательной статистики представляют меньший интерес. Величина "Интервал" определяется как разность между максимальным и минимальным значением случайной величины (численного ряда). Параметры "Счет" и "Сумма" представляют собой число значений в заданном интервале и их сумму соответственно. Последняя характеристика "Уровень надежности" показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. По умолчанию уровень надежности принят равным 95%. Дополнение "Анализ данных" содержит целый ряд других полезных инструментов, позволяющих быстро и эффективно осуществить требуемый вид обработки данных. Вместе с тем, большинство из них требует осмысленного применения и соответствующей подготовки пользователя в области математической статистики. Практическое задание 1: Выполнить самостоятельную работу по вычислению статистических показателей содержания некоторых микроэлементов в крови анализируемой группы животных. Этапы выполнения задания: 1. Вычислить не менее 10 показателей, характеризующих выборку, используя статистические функции. 2. Вычислить статистические показатели, характеризующие выборку, используя Пакет Анализа. Вопросы для контроля знаний. 1.Перечислите известные способы вычисления статистических показателей выборки.2.Какие статистические функции вы знаете? 3. Что такое описательная статистика и как она применяется? Цель – формирование практических умений и навыков применения относительной и абсолютной адресации данных в ячейках электронной таблицы. План
|
||
|
|
Последнее изменение этой страницы: 2021-01-08; просмотров: 325; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.01 с.) |

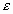 для средних величин распределений. Другими словами среднее или ожидаемое значение случайной величины М (Е) определено с погрешностью
для средних величин распределений. Другими словами среднее или ожидаемое значение случайной величины М (Е) определено с погрешностью 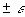 .
.


