
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Кафедра электронных вычислительных машинСодержание книги
Поиск на нашем сайте
Кафедра электронных вычислительных машин Кафедра социологии и социальных технологий Технологии работы в сети Интернет Конспект лекций для студентов Факультета управления и социальных коммуникаций всех форм обучения направления подготовки профиль – Управление персоналом организации
© Тверской государственный технический университет, 2020 © Абу-Абед Ф.Н., 2020 Раздел 1. Основные понятия глобальной сети Интернет, основные сервисы.
Адресация в IP-сетях Типы адресов: физический (MAC-адрес), сетевой (IP-адрес) и символьный (DNS-имя) Каждый компьютер в сети TCP/IP имеет адреса трех уровней:
В таблице приведены диапазоны номеров сетей, соответствующих каждому классу сетей.
Соглашения о специальных адресах: broadcast, multicast, loopback Регистрация доменных имен Для того, чтобы получить зону надо отправить заявку в РосНИИРОС, который отвечает за делегирование поддоменов в пределах домена ru. В заявке указывается адрес компьютера-сервера доменных имен, почтовый адрес администратора сервера, адрес организации и ряд другой информации. При размещении сервера домена следует позаботиться о том, чтобы существовал вторичный (secondary) сервер имен вашего домена. Согласно большинству рекомендаций, следует иметь от 2-х до 4-х серверов на случай отказа основного сервера доменных имен. Вообще говоря, можно вести переговоры о создании вторичного сервера доменных имен и с самим РосНИИРОС и с любым провайдером. Но за услуги последнего придется заплатить. Можно запустить вторичный сервер и на одном из своих компьютеров, но в этом случае вы просто выполните требования РосНИИРОС формально, так как надежности процедуре разрешения имен вашего домена такое решение не принесет.
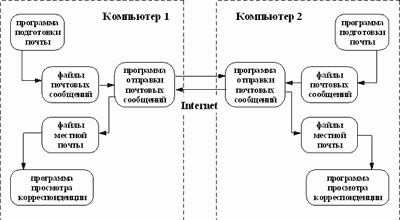
Рис.4. Схема подключения локальной сети к провайдеру Действительно, если ваша сеть подключена к провайдеру через один единственный шлюз (рисунок 3.4), то все ваши компьютеры, оказываются за шлюзом. При отказе шлюза все они для внешнего пользователя сети исчезают, а это значит, что если сервер доменных имен расположен на шлюзе или одном из компьютеров вашей сети, то для внешнего пользователя и их имена исчезнут также, в отличии от IP-адресов, которые прописаны в маршрутизаторе провайдера. На первый взгляд кажется, что если нет доступа, то и трансляция доменных имен в IP-адресе не нужна. Однако, это не совсем так. Если система не может разрешить доменное имя, то она сообщает - "unknown host", т.е. система такого компьютера не знает. Если же доменное имя успешно транслируется в IP-адрес, то, в случае потери связи, система сообщает - "host un-reachable", т.е. система знает о такой машине, но в данный момент достичь эту машину нет никакой возможности. Принципы организации Электронная почта во многом похожа на обычную почтовую службу. Корреспонденция, подготавливается пользователем на своем рабочем месте либо программой подготовки почты, либо просто обычным текстовым редактором. Обычно, программа подготовки почты вызывает текстовый редактор, который пользователь предпочитает всем остальным программам этого типа. Затем пользователь должен вызвать программу отправки почты (программа подготовки почты вызывает программу отправки автоматически). Стандартной программой отправки является программа sendmail. Sendmail работает как почтовый курьер, который доставляет обычную почту в отделение связи для дальнейшей рассылки. В Unix-системах sendmail сама является отделением связи. Она сортирует почту и рассылает ее адресатам. Для пользователей персональных компьютеров, имеющих почтовые ящики на своих машинах и работающих с почтовыми серверами через коммутируемые телефонные линии, могут потребоваться дополнительные действия. Так, например, пользователи почтовой службы Relcom должны запускать программу UUPC, которая осуществляет доставку почты на почтовый сервер. Для работы электронной почты в Internet разработан специальный протокол Simple Mail Transfer Protocol (SMTP), который является протоколом прикладного уровня и использует транспортный протокол TCP. Однако, совместно с этим протоколом используется и Unix-Unix-CoPy (UUCP) протокол. UUCP хорошо подходит для использования телефонных линий связи. Большинство пользователей электронной почты Relcom реально пользуются для доставки почты на узел именно этим протоколом. Разница между SMTP и UUCP заключается в том, что при использовании первого протокола sendmail пытается найти машину-получателя почты и установить с ней взаимодействие в режиме on-line для того, чтобы передать почту в ее почтовый ящик. В случае использования SMTP почта достигает почтового ящика получателя за считанные минуты и время получения сообщения зависит только от того, как часто получатель просматривает свой почтовый ящик. При использовании UUCP почта передается по принципу "stop-go", т.е. почтовое сообщение передается по цепочке почтовых серверов от одной машины к другой пока не достигнет машины-получателя или не будет отвергнуто по причине отсутствия абонента-получателя. С одной стороны, UUCP позволяет доставлять почту по плохим телефонным каналам, т.к. не требуется поддерживать линию в течении времени доставки от отправителя к получателю, а с другой стороны бывает обидно получить возврат сообщения через сутки после его отправки из-за того, что допущена ошибка в имени пользователя. В целом же общие рекомендации таковы: если имеется возможность надежно работать в режиме on-line и это является нормой, то следует настраивать почту для работы по протоколу SMTP, если линии связи плохие или on-line используется чрезвычайно редко, то лучше использовать UUCP.
Рис. 6. Структура взаимодействия участников почтового обмена Основой любой почтовой службы является система адресов. Без точного адреса невозможно доставить почту адресату. В Internet принята система адресов, которая базируется на доменном адресе машины, подключенной к сети. Например, для пользователя paul машины с адресом polyn.net.kiae.su почтовый адрес будет выглядеть как: Таким образом, адрес состоит из двух частей: идентификатора пользователя, который записывается перед знаком "коммерческого @", и доменного адреса машины, который записывается после знака "@". Адрес UUCP был бы записан как строка вида: net.kiae.su!polyn!paulПрограмма рассылки почты Sendmail сама преобразует адреса формата Internet в адреса формата UUCP, если доставка сообщения осуществляется по этому протоколу. Язык гипертекста HTML Разработчики HTML пытались решить две задачи:
Первая задача была решена за счет выбора теговой модели описания документа. Такая модель широко применяется в системах подготовки документов для печати. К моменту создания HTML существовал стандарт языка разметки печатных документов - StandardGeneralisedMarkupLanguage, который и был взят в качестве основы HTML. Такой подход предполагает наличие еще одной компоненты технологии - интерпретатора языка. В WWW функции интерпретатора разделены между сервером гипертекстовой базы данных и клиентом. Языки сценариев JavaScript Язык JavaScript разрабатывался компанией Netscape как язык сценариев просмотра HTML-страниц. JavaScript является объектно-ориентированным языком. В целом язык ориентирован на встроенные объекты NetscapeNavigator: окна, формы, поля форм, элементы рабочих областей Navigator. Это сильно облегчает обучение языку и позволяет сразу писать интересные и полезные программы. Используя JavaScript, можно организовать многооконный интерфейс с локальной справочной системой и встроенной графикой, возложив при этом многие вопросы проверки вводимых пользователем данных на JavaScript. По своим функциональным возможностям JavaScript довольно сильно уступает Java: можно организовать прокрутку текста, организовать открытие нового окна, запрограммировать калькулятор, но не более того. VisualBasicScript В настоящий момент во всем мире программисты широко используют для быстрой разработки своих приложений язык VisualBasic, который не требует применения разнообразных SDK и нескольких месяцев на его изучение, как это происходит с языком С++. Так же, как VisualBasic облегчает разработку приложений для Windows, а VisualBasicforApplication (VBA) делает то же для приложений, базирующихся на MicrosoftOffice, VisualBasicScript (VBScript), дает в руки тех, кто создает Internet-приложения, аналогичный по мощности инструмент. Предшественники HTML Начало истории HTML следует отнести к далекому 1986 году, когда Международная организация по стандартизации (ISO) приняла стандарт ISO-8879, озаглавленный "StandardGeneralizedMarkupLanguage" (SGML). Стандарт этот посвящен описанию SGML - обобщенного метаязыка, позволяющего строить системы логической, структурной разметки любых разновидностей текстов. Слово "структурная" означает, что управляющие коды, вносимые в текст при такой разметке, не несут никакой информации о внешнем виде документа, а лишь указывают границы и соподчинение его составных частей, т.е. задают его логическую структуру. Создатели SGML стремились максимально абстрагироваться от проблем представления электронного текста в разных программах, на разных компьютерных платформах и устройствах вывода. Так, если с помощью SGML размечается документ, содержащий заголовки, идеология языка запрещает указывать, что такой-то заголовок должен набираться, скажем, шрифтом Times полужирного начертания кегля 12 пунктов. SGML в таком случае требует ограничиться указанием на уровень заголовка и его место в иерархической структуре документа. Благодаря таким ограничениям размеченный текст сможет без труда интерпретировать любая программа, работающая с любым мыслимым устройством вывода. К примеру, при работе в графическом интерфейсе заголовок может действительно выводиться полужирным шрифтом повышенного кегля; программа, использующая текстовый интерфейс, выделит его пустой строкой сверху и снизу и, возможно, повышенной яркостью символов; синтезатор речи, читающий документ вслух, сможет отметить заголовок паузой и изменением интонации. Можно сказать, что SGML-разметка обнажает нематериальную "душу" текста, для которой впоследствии любая программа-интерпретатор сможет подобрать подходящее к случаю "тело". Однако абстрактность SGML этим не исчерпывается. SGML представляет собой не готовую систему разметки текста, а лишь удобный метаязык, позволяющий строить такие системы для конкретных обстоятельств. Жизнь многообразна и непредсказуема: сегодня вам требуется выделять в текстах заголовки, а завтра, возможно, понадобится размечать подписи в письмах, математические формулы или имена действующих лиц в пьесе. Стандарт SGML определяет лишь синтаксис записи элементов разметки - тегов - и их атрибутов, а также правила определения новых тегов и указания структурных отношений между ними. Для практической же разметки документов нужно приложение SGML - набор определенных в соответствии со стандартом тегов, представляющий собой, по сути, формальное описание структуры документа. Cам по себе SGML не получил сколько-нибудь заметного распространения - до тех пор, пока в 1991 г. сотрудники Европейского института физики частиц (CERN, http://www.cern.ch), занятые созданием системы передачи гипертекстовой информации через Internet, не выбрали SGML в качестве основы для нового языка разметки гипертекстовых документов. Этот язык - самое известное из приложений SGML - был назван HTML (HyperTextMarkupLanguage, "язык разметки гипертекста"). Группы тегов HTML Все теги HTML по их назначению и области действия можно разделить на следующие основные группы:
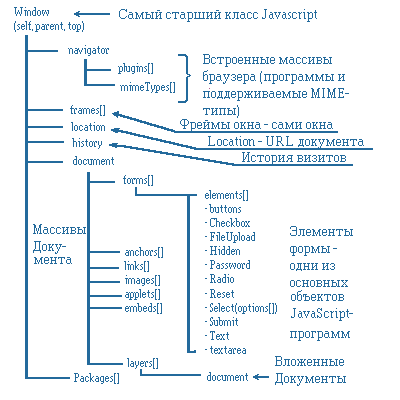
Структура HTML-документа HTML-документ представляет собой иерархию элементов документа, заключенных в "теговые скобки". В секцию головы всегда помещается заглавие документа (не путать с именем файла), которое при просмотре HTML-страницы появляется в заголовке окна броузера. Заглавие показывает общий смысл HTML-страницы. Для определения заглавия HTML-страницы применяется теговый контейнер <TITLE>, например: <TITLE>Моя любимая страница</TITLE> <HTML> <HEAD> Голова документа </HEAD> <BODY> Тело, Содержание документа </BODY></HTML>HTML-контейнеры как объекты программирования Основная идея JavaScript состоит в возможности изменения значений атрибутов HTML-контейнеров и свойств среды отображения в процессе просмотра HTML-страницы пользователем. При этом не происходит перезагрузки страницы. На практике это выражается в том, что можно, например, изменить цвет фона страницы, или интегрированную в документ картинку, открыть новое окно или выдать предупреждение. Объекты Для реализации этой идеи была предложена объектная модель документа. Суть модели в том, что каждый HTML-контейнер - это объект, который характеризуется тройкой: свойства методы события Объекты с одинаковым набором свойств, методов и событий объединяются в классы однотипных объектов. Классы - это описания возможных объектов. Сами объекты появляются только после загрузки документа браузером, или как результат работы программы. Об этом нужно всегда помнить, чтобы не обратиться к объекту, которого нет. Свойства Многие HTML-контейнеры имеют атрибуты. Например, контейнер <a> имеет атрибут href, который превращает его в гипертекстовую ссылку: <a href=kuku.htm>kuku</a> если рассматривать контейнер <A...>...</A> как объект, то атрибут href будет задавать свойство объекта. Программист может изменить значение атрибута и, следовательно, свойство объекта: document.links[0].href="kuku1.htm"; Значения не всех атрибутов можно изменять. Например, высота и ширина графической картинки определяются по первой загруженной в момент загрузки страницы картинки. Все последующие картинки, которые заменяют начальную, масштабируются до нее. Для общности картины свойствами в JavaScript наделены объекты, которые не имеют аналогов в HTML-разметке. Например, среда исполнения, которая называется объектом navigator или окно браузера, которое является вообще самым старшим объектом JavaScript Методы В терминологии JavaScript методы объекта определяют функции изменения его свойств. Например, с объектом документ связаны методы open(), write(), close(). Эти методы позволяют сгенерировать или изменить содержание документа: События Кроме методов и свойств объекты характеризуются событиями, которые с ними могут происходить. Собственно, суть программирования на JavaScript заключена в написании обработчиков этих событий. Например, с объектом типа button(контейнер INPUT типа button - "кнопка") может происходить событие "Click", т.е. на кнопку могут нажать. Для этого атрибуты контейнера INPUT расширены атрибутом обработки события Click - onClick. В качестве значения этого атрибута указывается программа обработки события, которую должен написать автор HTML-документа на JavaScript: <input type=button value="Don't click here" onClick="window.alert('We repeate again: DON\'T CLICK HERE');"> Обработчики событий указываются в тех контейнерах, с которыми эти события связаны. Например, контейнер BODY определяет свойства всего документа, поэтому обработчик события завершения загрузки всего документа указывается в этом контейнере как значение атрибута onLoad Иерархия классов Объектно ориентированный язык программирования предполагает наличие иерархии классов объектов. В JavaScript такая иерархия начинается с класса объектов window, т.е. window.document.location
Вообще говоря, JavaScript не является классическим объектным языком. В нем нет наследования и полиморфизма. Программист может определить свой собственный класс объектов через оператор function, но чаще пользуется стандартными объектами, их конструкторами и вообще не использует деструкторов классов. Это объясняется тем, что область действия JavaScript- программы не распространяется обычно за пределы текущего окна. В ряде случаев у разных объектов JavaScript определены свойства с одинаковыми именами. В этом случае нужно четко указывать, свойство какого объекта программист хочет использовать. Например, window и document имеют свойство location. Только для window это объект класса location, а для document - строковый литерал, который принимает в качестве значения URL загруженного документа. Следует также учитывать, что для многих объектов существуют стандартные методы преобразования значений свойств объектов в обычные переменные. Например, для всех объектов по умолчанию определен метод преобразования в строку символов: toString(). Поле location Поле location отображает URL загруженного документа Вообще говоря, location - это объект. Из-за изменений в версиях JavaScript класс location входит как подкласс и в класс window и в класс document. Мы будем рассматривать location только как window.location. Кроме того, location - это еще и подкласс класса URL, к которому относятся также объекты классов Area и Link. Location наследует все свойства URL, что позволяет легко получить доступ к любой части схемы URL. Рассмотрим характеристики и способы использования объекта location: Свойства Методы Событий, характеризующих location, нет Как видим список характеристик объекта location неполный. Свойства Предположим, что браузер отображает страницу, расположенную по адресу: http://kuku.ru:80/r/dir/page?search#mark window.location.host – kuku.ru window.location.port - 80 Методы Методы location предназначены для управления загрузкой и перезагрузкой страницы. Это управление заключается в том, что можно либо перегрузить документ(reload), либо загрузить(replace) новый документ. При этом в трассу просмотра страниц(history) при выполнении этих методов информация не заносится: window.location.reload(true); Метод reload() полностью моделирует поведение браузера при нажатии на кнопку Reload в панели инструментов. Если вызывать метод без аргумента или указать его равным true, то браузер проверит время последней модификации документа и загрузит его либо из кеша(если не был модифицирован), либо с сервера. Такое поведение соответствует простому нажатию на кнопку Reload. Если в качестве аргумента указать false, то браузер перезагрузит текущий документ с сервера, не взирая ни на что. Такое поведение соответствует одновременному нажатию на Reload и кнопку клавиатуры shift(Reload+shift). Метод replace позволяет заместить текущую страницу на другую страницу таким образом, что это замещение не будет отражено в трассе просмотра html-страниц(history) и при нажатии на кнопку Back из панели инструментов пользователь всегда будет попадать на первую загруженную нормальным способом (по гипертекстовой ссылке) страницу. Напомним, что при изменении свойств location также происходит перезагрузка страниц, но в этом случае записи об их посещении в history попадают Конструкции языка Содержимое XML- документа представляет собой набор элементов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных. Рассмотрим каждый из них подробней. Элементы данных Элемент - это структурная единица XML- документа. Заключая слово rose в в тэги <flower> </flower>, мы определяем непустой элемент, называемый <flower>, содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, - т.е. практически любые части XML- документа. Любой непустой элемент должен состоять из начального, конечного тэгов и данных, между ними заключенных. Например, следующие фрагменты будут являться элементами: <flower>rose</flower><city>Novosibirsk</city>,а эти - нет: <rose><flower>roseНабором всех элементов, содержащихся в документе, задается его структура и определяются все иерархическое соотношения. Плоская модель данных превращается с использованием элементов в сложную иерархическую систему со множеством возможных связей между элементами. Например, в следующем примере мы описываем месторасположение Новосибирских университетов (указываем, что Новосибирский Университет расположен в городе Новосибирске, который, в свою очередь, находится в России), используя для этого вложенность элементов XML: <country id="Russia"> <cities-list><city><title>Новосибирск</title><state>Siberia</state><universities-list><university id="2"><title>Новосибирский Государственный Технический Университет</title><noprivate/><address URL="www.nstu.ru"/><description>очень хороший институт</description> </university> <university id="2"><title>Новосибирский Государственный Университет</title><noprivate/><address URL="www.nsu.ru"/><description>тоже не плохой</description> </university> </universities-list></city></cities-list></country>Производя в последствии поиск в этом документе, программа клиента будет опираться на информацию, заложенную в его структуру - используя элементы документа. Т.е. если, например, требуется найти нужный университет в нужном городе, используя приведенный фрагмент документа, то необходимо будет просмотреть содержимое конкретного элемента <university>, находящегося внутри конкретного элемента <city>. Поиск при этом, естественно, будет гораздо более эффективен, чем нахождение нужной последовательности по всему документу. В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является <country> В некоторых случаях тэги могут изменять и уточнять семантику тех или иных фрагментов документа, по разному определяя одну и ту же информацию и тем самым предоставляя приложению-анализатору этого документа сведения о контексте использования описываемых данных. Например, прочитав фрагмент <city> Holliwood </city> мы можем догадаться, что речь в этой части документа идет о городе, а вот во фрагменте <restaurant> Holliwood </restaurant> - о забегаловке. В случае, если элемент не имеет содержимого, т.е. нет данных, которые он должен определять, он называется пустым. Примером пустых элементов в HTML могут служить такие тэги HTML, как <br>, <hr>, <img>;. Необходимо только помнить, что начальный и конечные тэги пустого элемента как бы объединяется в один, и надо обязательно ставить косую черту перед закрывающей угловой скобкой (например, <empty/>;) Комментарии Комментариями является любая область данных, заключенная между последовательностями символов <!-- и --> Комментарии пропускаются анализатором и поэтому при разборе структуры документа в качестве значащей информации не рассматриваются. Атрибуты Если при определении элементов необходимо задать какие-либо параметры, уточняющие его характеристики, то имеется возможность использовать атрибуты эдлемента. Атрибут - это пара "название" = "значение", которую надо задавать при определении элемента в начальном тэге. Пример: <color RGB ="true">#ff08ff</color><color RGB ="false">white</color>или <author id=0>Ivan Petrov</author>Примером использования атрибутов в HTML является описание элемента <font>: <font color=”white” name=”Arial”>Black</font>Cпециальные символы Для того, чтобы включить в документ символ, используемый для определения каких-либо конструкций языка (например, символ угловой скобки) и не вызвать при этом ошибок в процессе разбора такого документа, нужно использовать его специальный символьный либо числовой идентификатор. Например, <, > " или $(десятичная форма записи),  (шестнадцатеричная) и т.д. Строковые обозначения спецсиволов могут определяться в XML документе при помощи компонентов (entity), о чем мы еще поговорим немного позже. Структура XSL- таблиц Рассмотрим основные структурные элементы XSL, используемые, в частности, в конверторе msxsl, для создания оформления XML-документов. Правила XSL XSL- документ представляет собой совокупность правил построения, каждое из которых выделено в отдельный блок, ограниченный тэгами <rule> и </rule>;. Правила определяют шаблоны, по которым каждому элементу XML ставится в соответствие последовательность HTML- тэгов, т.е. внутри них содержатся инструкции, определяющие элементы XML- документа и тэги форматирования, применяемые к ним. Элементы XML, к которым будет применяться форматирование, обозначаются в XSL дескриптором <target-element/>;. Для указания элемента с конкретным названием (название элемента определяется тэгами, его обозначающими), т.е. определения класса элемента, можно использовать атрибут type ="<имя_элемента>" Вот пример простейшего XSL-документа, определяющего форматирование для фрагмента <flower>rose</flower>: <xsl><rule><target-element type="flower"/><p color="red" font-size="12"><children/></p></rule></xsl>Уже на этом примере можно проследить особенность использования стилевых таблиц: в любых правилах при помощи соответствующих элементов декларативно задается область, которая определяет фрагмент XML-документа, как мы чуть позже увидим, программа-анализатор заново проходит все элементы, начиная с текущего, всякий раз, когда в структуре XML- документа обнаруживаются новые вложенные элементы. Инструкция <target-element> указывает на то, что данное правило определяет элемент. Параметром type="flower" задается название XML-элемента, для которого будет использоваться это правило. Программа-конвертор будет использовать HTML-тэги, помещенные внутри блока <rule></rule> для форматирования XML-элемента, которому "предназначался" текущий блок. В том случае, если для какого-то элемента XML шаблон не определяется, в выходной документ будут добавлены тэги форматирования по умолчанию (например, <DIV></DIV>) Процесс разбора XSL-правил является рекурсивным, т.е. если у элемента есть дочерние элементы, то программа будет искать определения этих элементов, расположенных "глубже" в дереве документа. Указанием на то, что необходимо повторить процесс разбора XML документа, теперь уже для дочерних элементов, является инструкция <children/>. Дойдя до нее, анализатор выберет из иерархического дерева XML- элементов нужную ветвь и найдет в XSL-шаблонах правила, определяющие форматирование этих нижележащих элементов. В том случае, если вместо <children> мы укажем инструкцию <empty/>;, программа закончит движение по данной ветви и возвратится назад, в родительское правило. При этом текущее правило никакой информации в выходном HTML-документе изменять не будет, т.к. <empty/> в данном случае означает, что содержимое элемента отсутствует. Если в одном правиле <target-element> используется несколько раз, то инструкции по форматированию будут распространены на все описываемые внутри него XML-элементы, т.е. можно задавать единый шаблон форматирования для нескольких элементов одновременно: <xsl><rule><target-element type="item1"/><target-element type="item2"/><target-element type="item3"/><hr><children/><hr></rule></xsl>Ниже приведен пример более сложного XSL- описания, некоторые фрагменты которого будут пояснены позже. XML-документ: <?XML Version="1.0"?><documents><books><book id="Book1"><title>Макроэномические показатели экономики Римской Империи в период ее расцвета</title><author>Иван Петров</author><date>21.08.98</date></book><book id="Book2"><title>Цветоводство и животноводство. Практические советы</title><author>Петр Сидоров</author><date>10.10.98</date></book></books><articles><article id="Article1"><author>Петр Иванов</author><title>Влияние повышения тарифов оплаты за телефон на продолжительность жизни населения</title><date>12.09.98</date></article></articles></documents>Содержимое XSL-документа: <xsl> <rule> <root/> <HTML> <BODY bgcolor="white"> <center><hr <table border="2"> <children/> </table></center> </BODY> </HTML> </rule> <rule> <element type="book"> <target-element type="author"/> </element> <td align="center"> <p color="red" font-size="14"> <b> <children/> </b></p></td> </rule> <rule> <element type="article"> <target-element type="author"/> </element> <td align="center"> <p color="red" font-size="14" font-style="italic"><children/></p></td> </rule> <rule> <target-element type="book"/> <tr><children/></tr> </rule> <rule> <target-element type="article"/> <tr><children/></tr> </rule> <rule> <target-element/> <td align="center"><p><children/></p></td> </rule> <rule> <target-element type="books"/> <tr><td colspan="3" bgcolor="silver" >Books</td></tr> <children/> </rule> <rule> <target-element type="articles"/> <tr><td colspan="3" bgcolor="silver" >Articles</td></tr> <children/> </rule></xsl>Корневое правило Разбор любого XSL- документа всегда начинается с правила для корневого элемента, в котором определяется область всего разбираемого XML документа и поэтому тэги форматирования, помещенные сюда, будут действовать на весь документ в целом. Для обозначения корневого правила необходимо включить в него элемент <root/>;. Например, для того, чтобы задать тэг <body> для формируемой нами выходной HTML- страницы, мы можем использовать следующий фрагмент: <xsl><rule><root/><html><head><title> Flowers</title></head><body bgcolor="white" link="blue" alink="darkblue" vlink="darckblue"><children/></body></html></rule></xsl>В этом примере при помощи инструкций <root/> и <children/> мы определили ряд начальных и конечных HTML-тэгов для нашей страницы, между которыми затем в процессе рекурсивного обхода XSL- анализатора будут помещены остальные элемента документа. В том случае, если мы не определяем правило для корневого элемента, разбор документа начнется с первого правила с инструкцией <target-element>(для оформления же заголовка документа будет использован образец форматирования, применяющийся по умолчанию). Documents Type Definitions (DTD) В XML- документах DTD определяет набор действительных элементов, идентифицирует элементы, которые могут находиться в других элементах, и определяет действительные атрибуты для каждого из них. Синтаксис DTD весьма своеобразен и от автора-разработчика требуются дополнительные усилия при создании таких документов(сложность DTD является одной из причин того, что использование SGML, требующего определение DTD для любого документа, не получило столь широкого распространения как, например, HTML). Как уже отмечалось, в XML использовать DTD не обязательно - документы, созданные без этих правил, будут правильно обрабатываться программой-анализатором, если они удовлетворяют основным требованиям синтаксиса XML. Однако контроль за типами элементов и корректностью отношений между ними в этом случае будет полностью возлагаться на автора документа. До тех пор, пока грамматика нашего нового языка не описана, его сможем использовать только мы, и для этого мы будем вынуждены применять специально разработанное программное обеспечение, а не универсальные программы-анализаторы.. В DTD для XML используются следующие типы правил: правила для элементов и их атрибутов, описания категорий(макроопределений), описание форматов бинарных данных. Все они описывают основные конструкции языка - элементы, атрибуты, символьные константы внешние файлы бинарных данных. Для того, чтобы использовать DTD в нашем документе, мы можем или описать его во внешнем файле и при описании DTD просто указать ссылку на этот файл или же непосредственно внутри самого документа выделить область, в которой определить нужные правила. В первом случае в документе указывается имя файла, содержащего DTD- описания: <?xml version="1.0" standalone="yes"?><! DOCTYPE journal SYSTEM "journal.dtd">...Внутри же документа DTD- декларации включаются следующим образом: ...<! DOCTYPE journal [<!ELEMENT journal (contacts, issues, authors)>...]>...В том случае, если используются одновременно внутренние и внешние описания, то программой-анализатором будут сначала рассматриваться внутренние, т.е. их приоритет выше. При проверке документа XML- процессор в первую очередь ищет DTD внутри документа. Если правила внутри документа не определены и не задан атрибут standalone ="yes", то программа загрузит указанный внешний файл и правила, находящиеся в нем, будут считаны оттуда. Если же атрибут standalone имеет значение "yes ", то использование внешних DTD описаний будет запрещено. Определение элемента Элемент в DTD определяется с помощью дескриптора! ELEMENT, в котором указывается название элемента и структура его содержимого. Например, для элемента <flower> можно определить следующее правило: <!ELEMENT flower PCDATA>Ключевое слово ELEMENT указывает, что данной инструкцией будет описываться элемент XML. Внутри этой инструкции задается название элемента(flower) и тип его содержимого. В определении элемента мы указываем сначала название элемента(flower), а затем его моде
|
||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-12-17; просмотров: 90; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.142.198.108 (0.015 с.) |

 Тверь 2020
Тверь 2020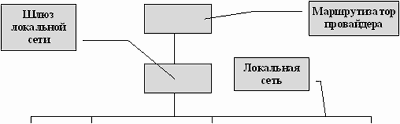
 каждый объект приписан к тому или иному окну. Для обращения к любому объекту или его свойству указывают полное или частичное имя этого объекта или свойства объекта, начиная с имени объекта старшего в иерархии, в который данный объект входит:
каждый объект приписан к тому или иному окну. Для обращения к любому объекту или его свойству указывают полное или частичное имя этого объекта или свойства объекта, начиная с имени объекта старшего в иерархии, в который данный объект входит:


