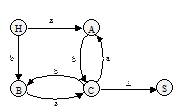Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Автоматные грамматики и конечные автоматыСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте Соглашение: в дальнейшем, если особо не оговорено, под регулярной грамматикой будем понимать леволинейную грамматику. Напомним, что грамматика G = (VT, VN, P, S) называется леволинейной, если каждое правило из Р имеет вид A ® Bt либо A ® t, где A, B Î VN, t Î VT. Алгоритм приведения грамматики к автоматному виду Соглашение: предположим, что анализируемая цепочка заканчивается специальным символом ^ - признаком конца цепочки. Для леволинейных грамматик существует алгоритм определения того, принадлежит ли анализируемая цепочка языку, порождаемому этой грамматикой (алгоритм разбора): (1) первый символ исходной цепочки a1a2...an^ заменяем нетерминалом A, для которого в грамматике есть правило вывода A ® a1 (другими словами, производим "свертку" терминала a1 к нетерминалу A) (2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: полученный на предыдущем шаге нетерминал A и расположенный непосредственно справа от него очередной терминал ai исходной цепочки заменяем нетерминалом B, для которого в грамматике есть правило вывода B ® Aai (i = 2, 3,.., n); Это эквивалентно построению дерева разбора методом "снизу-вверх": на каждом шаге алгоритма строим один из уровней в дереве разбора, "поднимаясь" от листьев к корню. При работе этого алгоритма возможны следующие ситуации: (1) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу S. Это означает, что исходная цепочка a1a2...an^ Î L (G). (2) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу, отличному от S. Это означает, что исходная цепочка a1a2...an^ Ï L (G). (3) на некотором шаге не нашлось нужной свертки, т.е. для полученного на предыдущем шаге нетерминала A и расположенного непосредственно справа от него очередного терминала ai исходной цепочки не нашлось нетерминала B, для которого в грамматике было бы правило вывода B ® Aai. Это означает, что исходная цепочка a1a2...an^ Ï L (G). (4) на некотором шаге работы алгоритма оказалось, что есть более одной подходящей свертки, т.е. в грамматике разные нетерминалы имеют правила вывода с одинаковыми правыми частями, и поэтому непонятно, к какому из них производить свертку. Это говорит о недетерминированности разбора. Анализ этой ситуации будет дан ниже. Допустим, что разбор на каждом шаге детерминированный. Для того, чтобы быстрее находить правило с подходящей правой частью, зафиксируем все возможные свертки (это определяется только грамматикой и не зависит от вида анализируемой цепочки). Это можно сделать в виде таблицы, строки которой помечены нетерминальными символами грамматики, столбцы - терминальными. Значение каждого элемента таблицы - это нетерминальный символ, к которому можно свернуть пару "нетерминал-терминал", которыми помечены соответствующие строка и столбец. Например, для грамматики G = ({a, b, ^}, {S, A, B, C}, P, S), такая таблица будет выглядеть следующим образом:
Знак "-" ставится в том случае, если для пары "терминал-нетерминал" свертки нет. Но чаще информацию о возможных свертках представляют в виде диаграммы состояний (ДС) - неупорядоченного ориентированного помеченного графа, который строится следующим образом: (1) строят вершины графа, помеченные нетерминалами грамматики (для каждого нетерминала - одну вершину), и еще одну вершину, помеченную символом, отличным от нетерминальных (например, H). Эти вершины будем называть состояниями. H - начальное состояние. (2) соединяем эти состояния дугами по следующим правилам: a) для каждого правила грамматики вида W ® t соединяем дугой состояния H и W (от H к W) и помечаем дугу символом t; б) для каждого правила W ® Vt соединяем дугой состояния V и W (от V к W) и помечаем дугу символом t; Диаграмма состояний для грамматики G (см. пример выше):
Вопрос 10 Регулярные выражения. Свойства регулярных выражений Регулярные множества можно обозначать с помощью регулярных выражений. Эти обозначения вводятся следующим образом: 1. 0 — регулярное выражение, обозначающее Æ. 2. l — регулярное выражение, обозначающее {l}. 3. а — регулярное выражение, обозначающее {a} "aÎV. 4. Если р и q — регулярные выражения, обозначающие регулярные множества Р и Q, то p+q, pq, р* — регулярные выражения, обозначающие регулярные множества P È Q, PQ и Р * соответственно. Два регулярных выражения a и b равны, a = b, если они обозначают одно и то же множество. Каждое регулярное выражение обозначает одно и только одно регулярное множество, но для одного регулярного множества может существовать сколь угодно много регулярных выражений, обозначающих это множество. При записи регулярных выражений будут использоваться круглые скобки, как и для обычных арифметических выражений. При отсутствии скобок операции выполняются слева на право с учетом приоритета. Приоритет для операций принят следующий: первой выполняется итерация (высший приоритет), затем конкатенация, потом — объединение множеств (низший приоритет). Если a, b и g — регулярные выражения, то свойства регулярных выражений можно записать в виде следующих формул: 1. g+aa* = g+a*a = a* 2. a+b = b+a. 3. a+(b+g) = (a+b)+g 4. a(b+g) = ab+ag 5. (b+g)a = ba+ga 6. a(bg) = (ab)g 7. a+a = a 8. a+a* = a* 9. l+a* = a*+l = a* 10. 0* = l 11. 0a = a0 = 0 12. 0+a = a+0 = a 13. la = al = a 14. (a*)* = a* Все эти свойства можно легко доказать, основываясь на теории множеств, так как регулярные выражения — это только обозначения для соответствующих множеств. Следует также обратить внимание на то, что среди прочих свойств отсутствует равенство ab = ba, то есть операция конкатенации не обладает свойством коммутативности. Это и не удивительно, поскольку для этой операции важен порядок следования символов.
Вопрос 11 Принципы построения лексических анализаторов Лексический анализатор имеет дело с такими объектами, как различного рода константы и идентификаторы (к последним относятся и ключевые слова). Язык констант и идентификаторов в большинстве случаев является регулярным — то есть может быть описан с помощью регулярных грамматик (см. главу «Регулярные языки»). Распознавателями для регулярных языков являются конечные автоматы. Существуют правила, с помощью которых для любой регулярной грамматики может быть построен недетерминированный конечный автомат, распознающий цепочки языка, заданного этой грамматикой (см. раздел «Конечные автоматы»). Конечный автомат для каждой входной цепочки языка дает ответ на вопрос о том, принадлежит или нет цепочка языку, заданному автоматом. Однако в общем случае задача сканера несколько шире, чем просто проверка цепочки символов лексемы на соответствие ее входному языку. Кроме этого, сканер должен выполнить следующие действия: · четко определить границы лексемы, которые в исходном тексте явно не заданы; · выполнить действия для сохранения информации об обнаруженной лексеме (или выдать сообщение об ошибке, если лексема неверна). Определение границ лексем Выделение границ лексем представляет определенную проблему. Ведь во входном тексте программы лексемы не ограничены никакими специальными символами. Если говорить в терминах программы-сканера, то определение границ лексем — это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание. В общем случае эта задача может быть сложной, и тогда требуется параллельная работа сканера (лексического анализатора), синтаксического разбора и, возможно, семантического анализа. Для большинства входных языков границы лексем распознаются по заданным терминальным символам. Эти символы — пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки с запятой и т. п.). Набор таких терминальных символов может варьироваться в зависимости от синтаксиса входного языка. Важно отметить, что знаки операций сами также являются лексемами и необходимо не пропустить их при распознавании текста. Как правило, сканеры действуют по следующему принципу: очередной символ из входного потока данных добавляется в лексему всегда, когда он может быть туда добавлен. Как только символ не может быть добавлен в лексему, то считается, что он является границей лексемы и началом следующей лексемы (если символ не является пустым разделителем — пробелом, символом табуляции или перевода строки, знаком комментария). Такой принцип не всегда позволяет правильно определить границы лексем в том случае, когда они не разделены пустыми символами. Например, приведенная выше строка языка С k=1+++++j; будет разбита на лексемы следующим образом: k = 1++ ++ + j; — и это разбиение неверное, компилятор должен будет выдать пользователю сообщение об ошибке, хотя правильный вариант распознавания строки существует. Однако разработчики компиляторов сознательно идут на то, что отсекают некоторые правильные, но не вполне читаемые варианты исходных программ. Попытки усложнить лексический распознаватель неизбежно приведут к необходимости его взаимосвязи с синтаксическим разбором. Это потребует организации их параллельной работы и неизбежно снизит эффективность работы всего компилятора. Возникшие накладные расходы никак не оправдываются достигаемым эффектом — чтобы распознавать строки с сомнительными лексемами, достаточно лишь обязать пользователя явно указать с помощью пробелов (или других незначащих символов) границы лексем, что значительно проще. Выполнение действий, связанных с лексемами Выполнение действий в процессе распознавания лексем представляет для сканера гораздо меньшую проблему. Фактически КА, который лежит в основе распознавателя лексем, должен иметь не только входной язык, но и выходной. Он должен не только уметь распознать правильную лексему на входе, но и породить связанную с ней последовательность символов на выходе. В такой конфигурации КА преобразуется в конечный преобразователь. Для сканера действия по обнаружению лексемы могут трактоваться несколько шире, чем только порождение цепочки символов выходного языка. Сканер должен уметь выполнять такие действия, как запись найденной лексемы в таблицу лексем, поиск ее в таблице символов и запись новой лексемы в таблицу символов. Набор действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же по обнаружению конца распознаваемой лексемы. В КА сканера эти действия можно отобразить сравнительно просто — достаточно. иметь возможность с каждым переходом на графе автомата (или в функции переходов автомата) связать выполнение некоторой произвольной функции f(q,a), где q — текущее состояние автомата, а — текущий входной символ Функция может выполнять произвольные действия, доступные сканеру, в том числе работать с хранилищами данных, имеющимися в компиляторе (функция может быть и пустой — не выполнять никаких действий). Такую функцию, если она есть, обычно записывают на графе переходов КА под дугами, соединяющими состояния КА.
Вопрос 12.1. Грамматикой простого предшествования называют такую приведенную (без циклов, бесплодных и недостижимых символов и l-правил)КС-грамматику G(VN, VT, P,S), V = VT È VN, в которой: 1. Для каждой упорядоченной пары терминальных и нетерминальных символов выполняется не более чем одно из трех отношений предшествования: · Вi =• Вj (" Bi, Bj Î V), если и только если $ правило A®xBiBjyÎ P, где AÎ VN, x,yÎ V *; · Вi <• Вj (" Bi, Bj Î V), если и только если $ правило A®xBiDy Î P и вывод DÞ*Sjz, где A,DÎ VN, x,y,zÎ V *; · Вi •> Bj (" Bi, Bj Î V), если и только если $ правило А®хСВjуÎ P и вывод CÞ*zBi или $ правило A®xCDyÎ P и выводы CÞ*zBi и DÞ*Bjw, где A,C,DÎ VN, x,y,z,wÎ V *. 2. Различные правила в грамматике имеют разные правые части (то есть в грамматике не должно быть двух различных правил с одной и той же правой частью). Отношения =•, <• и •> называют отношениями предшествования для символов. Отношение предшествования единственно для каждой упорядоченной пары символов. При этом между какими-либо двумя символами может и не быть отношения предшествования — это значит, что они не могут находиться рядом ни в одном элементе разбора синтаксически правильной цепочки. Отношения предшествования зависят от порядка, в котором стоят символы, и в этом смысле их нельзя путать со знаками математических операций — они не обладают ни свойством коммутативности, ни свойством ассоциативности. Например, если известно, что Вi •> Bj, то не обязательно выполняется Bj <• Вi (поэтому знаки предшествования иногда помечают специальной точкой: =•, <•, •>). Для грамматик простого предшествования известны следующие полезные свойства: · всякая грамматика простого предшествования является однозначной; · легко проверить, является или нет произвольная КС-грамматика грамматикой простого предшествования (для этого достаточно проверить рассмотренные выше свойства грамматик простого предшествования или воспользоваться алгоритмом построения матрицы предшествования, который рассмотрен далее). Как и для многих других классов грамматик, для грамматик простого предшествования не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику в грамматику простого предшествования (или доказать, что преобразование невозможно). Метод предшествования основан на том факте, что отношения предшествования между двумя соседними символами распознаваемой строки соответствуют трем следующим вариантам: · Bi <• Bi+1, если символ Bi+1 — крайний левый символ некоторой основы (это отношение между символами можно назвать «предшествует основе» или просто «предшествует»); · Вi •> Bi+1, если символ Вi — крайний правый символ некоторой основы (это отношение между символами можно назвать «следует за основой» или просто «следует»); · Вi =• Bi+1, если символы Вi и Bi+1 принадлежат одной основе (это отношение между символами можно назвать «составляют основу»), Исходя из этих соотношений, выполняется разбор строки для грамматики предшествования. Суть принципа такого разбора можно пояснить на рис. 12.5. На нем изображена входная цепочка символов abgd в тот момент, когда выполняется свертка цепочки g. Символ a является последним символом подцепочки a, а символ b — первым символом подцепочки b. Тогда, если в грамматике удастся установить непротиворечивые отношения предшествования, то в процессе выполнения разбора по алгоритму «сдвиг-свертка» можно всегда выполнять сдвиг до тех пор, пока между символом на верхушке стека и текущим символом входной цепочки существует отношение <• или =•. А как только между этими символами будет обнаружено отношение •>, так сразу надо выполнять свертку. Причем для выполнения свертки из стека надо выбирать все символы, связанные отношением =•. То, что все различные правила в грамматике предшествования имеют различные правые части, гарантирует непротиворечивость выбора правила при выполнении свертки. Таким образом, установление непротиворечивых отношений предшествования между символами грамматики в комплексе с несовпадающими правыми частями различных правил дает ответы на все вопросы, которые надо решить для организации работы алгоритма «сдвиг-свертка» без возвратов.
Рис. 12.5. Отношения между символами входной цепочки в грамматике предшествования На основании отношений предшествования строят матрицу предшествования грамматики. Строки матрицы предшествования помечаются первыми (левыми) символами, столбцы — вторыми (правыми) символами отношений предшествования. В клетки матрицы на пересечении соответствующих столбца и строки помещаются знаки отношений. При этом пустые клетки матрицы говорят о том, что между данными символами нет ни одного отношения предшествования.
Вопрос 12.2 Грамматики операторного предшествования Операторной грамматикой называется КС-грамматика без l-правил, в которой правые части всех правил не содержат смежных нетерминальных символов. Для операторной грамматики отношения предшествования можно задать на множестве терминальных символов (включая символы ^H и ^K). Грамматикой операторного предшествования называется операторная КС-грамматика G(VN, VT, P,S), V = VT È VN, для которой выполняются следующие условия: 1. Для каждой упорядоченной пары терминальных символов выполняется не более чем одно из трех отношений предшествования: ·а =• Ь, если и только если существует правило A®xaby Î Р или правило А®хаСbу, где a,bÎ VT, A,CÎ VN, x,yÎ V *; ·а <• b, если и только если существует правило А®хаСу Î Р и вывод CÞ*bz или вывод CÞ*Dbz, где a,bÎ VT, A,C,DÎ VN, x,y,zÎ V *; ·а •> b, если и только если существует правило А®хСЬу Î P и вывод CÞ*za или вывод CÞ*zaD, где a,bÎ VT, A,C,DÎ VN, x,y,zÎ V *. 2. Различные порождающие правила имеют разные правые части, l-правила отсутствуют. Отношения предшествования для грамматик операторного предшествования определены таким образом, что для них выполняется еще одна особенность — правила грамматики операторного предшествования не могут содержать двух смежных нетерминальных символов в правой части. То есть в грамматике операторного предшествования G(VN, VT, P,S), V = VT È VN не может быть ни одного правила вида: А®хВСу, где A,B,CÎ VN, x.yÎ V * (здесь х и у — это произвольные цепочки символов, могут быть и пустыми). Для грамматик операторного предшествования также известны следующие свойства: -- всякая грамматика операторного предшествования задает детерминированный КС-язык (но не всякая грамматика операторного предшествования при этом является однозначной!); -- легко проверить, является или нет произвольная КС-грамматика грамматикой операторного предшествования (точно так же, как и для простого предшествования). Как и для многих других классов грамматик, для грамматик операторного предшествования не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику в грамматику операторного предшествования (или доказать, что преобразование невозможно). Принцип работы распознавателя для грамматики операторного предшествования аналогичен грамматике простого предшествования, но отношения предшествования проверяются в процессе разбора только между терминальными символами. Для грамматики данного вида на основе установленных отношений предшествования также строится матрица предшествования, но она содержит только терминальные символы грамматики. Для построения этой матрицы удобно ввести множества крайних левых и крайних правых терминальных символов относительно нетерминального символа А - L t(A) или R t(A): -- Lt(А) = {t | $ AÞ*tz или $ AÞ*Ctz }, где tÎVT, A,CÎVN, zÎV*; -- R t (A) = {t | $ AÞ*zt или $ AÞ*ztC }, где tÎVT, A,CÎVN, zÎV*. Тогда определения отношений операторного предшествования будут выглядеть так: -- a =• Ь, если $ правило A®xaby Î Р или правило U®xaCby, где a,bÎ VT, A,CÎ VN, x,yÎ V *; -- a <• Ь, если $ правило А->хаСу Î Р и bÎ L t(C), где a,bÎ VT, A,CÎ VN, x,yÎ V *; -- a •> Ь, если $ правило A->xCby Î Р и aÎ R t(C), где a.bÎ VT, A.CÎ VN, x,yÎ V *. В данных определениях цепочки символов x,y,z могут быть и пустыми цепочками. Для нахождения множеств L t(A) и R t(A) предварительно необходимо выполнить построение множеств L (A) и R (A), как это было рассмотрено ранее. Далее для построения L t(A) и R t(A) используется следующий алгоритм: Шаг 1. " AÎVN: Rt0(A) = {t | A®ytB или A®yt, tÎVT, BÎVN, yÎV*}, Lt0(A) = {t | A®Bty или A®ty, tÎVT, BÎVN, yÎV*}. Для каждого нетерминального символа А ищем все правила, содержащие А в левой части. Во множество L (А) включаем самый левый терминальный символ из правой части правил, игнорируя нетерминальные символы, а во множество R (A) — самый крайний правый терминальный символ из правой части правил. Переходим к шагу 2. Шаг 2. " AÎ VN: Rti(A) = Rti-1(A) È Rti-1(B), " В Î (R(A) Ç VN), Lti(A) = Lti-1(A) È Lti-1(B), " В Î (L(A) Ç VN). Для каждого нетерминального символа А: если множество L (A) содержит нетерминальные символы грамматики А', А", …, то его надо дополнить символами, входящими в соответствующие множества L t(A’), L t(A’’),... и не входящими в L t(A). Ту же операцию надо выполнить для множеств R (A) и R t(A). Шаг 3. Если $ AÎ VN: R ti(A) ¹ R ti-1(A) или L ti(A) ¹ L ti-1(A), то i:=i+1 и вернуться к шагу 2, иначе построение закончено: R (A) = R ti(A) и L (A) = L ti(A). Если на предыдущем шаге хотя бы одно множество L t(A) или R t(A) для некоторого символа грамматики изменилось, то надо вернуться к шагу 2, иначе построение закончено. Для практического использования матрицу предшествования дополняют символами ^H и ^K (начало и конец цепочки). Для них определены следующие отношения предшествования: ^H <• а, " aÎ VT, если $ SÞ*ax или $ SÞ*Cax, где S,CÎ VN, xÎ V * или если aÎ L t(S); ^K •> a, " aÎVT, если $ SÞ*xa или $ SÞ*xaC, где S,CÎVN, xÎV* или если aÎRt(S). Здесь S — целевой символ грамматики. Матрица предшествования служит основой для работы распознавателя языка, заданного грамматикой операторного предшествования. Поскольку она содержит только терминальные символы, то, следовательно, будет иметь меньший размер, чем аналогичная матрица для грамматики простого предшествования. Следует отметить, что напрямую сравнивать матрицы двух грамматик нельзя — не всякая грамматика простого предшествования является грамматикой операторного предшествования, и наоборот. Например, рассмотренная далее в примере грамматика операторного предшествования не является грамматикой простого предшествования (читатели могут это проверить самостоятельно). Однако если две грамматики эквивалентны и задают один и тот же язык, то их множества терминальных символов должны совпадать. Тогда можно утверждать, что размер матрицы для грамматики операторного предшествования всегда будет меньше, чем размер матрицы эквивалентной ей грамматики простого предшествования. Все, что было сказано выше о способах хранения матриц для грамматик простого предшествования, в равной степени относится также и к грамматикам операторного предшествования, с той только разницей, что объем хранимой матрицы будет меньше.
Вопрос 13 Синтаксический анализ - это процесс, в котором исследуется цепочка лексем и устанавливается, удовлетворяет ли она структурным условиям, явно сформулированным в определении синтаксиса языка. Это – самая сложная часть компилятора. Синтаксический анализатор расчленяет исходную программу на составные части, формирует ее внутреннее представление, заносит информацию в таблицу символов и другие таблицы. При этом производится полный синтаксический и, по возможности, семантический контроль программы. Фактически, это - синтаксически управляемая программа. При этом обычно стремятся отделить синтаксис от семантики насколько это возможно - когда синтаксический анализатор распознает конструкцию исходного языка, он вызывает семантическую процедуру, которая контролирует эту конструкцию, заносит информацию куда надо, проверяет на дублирование описания переменных, проверяет соответствие типов и т.п. Предложения исходной программы обычно записываются в инфиксной форме. Однако эта привычная форма, в которой оператор записывается между операндами, является совершенно не пригодной для автоматического вычисления. Дело в том, что необходимо постоянно помнить о приоритетах операторов, "забегая" при анализе выражения "вперед". К тому же очень усложняют жизнь применяемые скобки, определяющие очередность вычислений. Альтернативой инфиксной форме является польская форма записи (в честь польского математика Лукасевича): постфиксная и префиксная. Обычно под польской формой понимают именно постфиксную форму записи. Кроме того, используются и такие внутренние формы представления исходной программы, как дерево (синтаксическое) и тетрады. Вопрос 14 Общие принципы работы табличных распознавателей Табличные распознаватели используют для построения цепочки вывода КС-грамматики другие принципы, нежели МП-автоматы. Как и МП-автоматы, они получают на вход цепочку входных символов a = a1a2…an, aÎ VT *, |a| = n, а построение вывода основывают на правилах заданной КС-грамматики G(VT, VN, P,S). Принцип их работы заключается в том, что искомая цепочка вывода строится не сразу — сначала на основе входной цепочки порождается некоторое промежуточное хранилище информации объема n*n (промежуточная таблица), а потом уже на его основе строится вывод. Табличные алгоритмы обладают полиномиальными характеристиками требуемых вычислительных ресурсов в зависимости от длины входной цепочки. Для произвольной КС-грамматики G(VT, VN, P, S) время выполнения алгоритма Тэ имеет кубическую зависимость от длины входной цепочки, а необходимый объем памяти Мэ — квадратичную зависимость от длины входной цепочки: Тэ = О(n3) и Мэ = O(n2). Квадратичная зависимость объема необходимой памяти от длины входной цепочки напрямую связана с использованием промежуточного хранилища данных. Табличные распознаватели универсальны — они могут быть использованы для распознавания цепочек, порожденных с помощью произвольной КС-грамматики (возможно, саму грамматику первоначально потребуется привести к заданному виду, но это не ограничивает универсальности алгоритмов). Кроме того, табличные распознаватели — это самые эффективные с точки зрения требуемых вычислительных ресурсов универсальные алгоритмы для распознавания цепочек КС-языков. Хотя табличные распознаватели и являются самыми эффективными среди универсальных распознавателей, тем не менее они не находят широкого применения. Дело в том, что полиномиальная зависимость требуемых вычислительных ресурсов от длины входной цепочки символов является неудовлетворительной для компиляторов (длины входных цепочек — тысячи и десятки тысяч символов). Поэтому практически всегда используются не универсальные, а более узкие, специализированные алгоритмы распознавателей, которые имеют обычно линейную зависимость требуемых вычислительных ресурсов от длины входной цепочки символов К универсальным алгоритмам прибегают только тогда, когда специализированный распознаватель построить не удается.
Алгоритм Кока—Янгера—Касами Алгоритм Кока—Янгера—Касами для заданной грамматики G(VT, VN, P,S) и цепочки входных символов a, a = a1a2…an, aÎ VT *, |a| = n строит таблицу Tn*n, такую, что "AÎ VN: AÎT[i,j], тогда и только тогда, если АÞ+аi...ai+j-1. Таким образом, элементами таблицы Tn*n являются множества нетерминальных символов в алфавита VN. Тогда существованию вывода SÞ*a соответствует условие SÎT[1,n]. При условии существования вывода по таблице Tn*n можно найти всю полную цепочку вывода SÞ*a. Для построения вывода по алгоритму Кока—Янгера—Касами грамматика G(VT, VN, P,S) должна быть в нормальной форме Хомского. Поскольку, как было показано выше, любую произвольную КС-грамматику можно преобразовать в нормальную форму Хомского, это не накладывает дополнительных ограничений на применимость данного алгоритма. Алгоритм Кока—Янгера—Касами фактически состоит из трех вложенных циклов. Поэтому ясно, что время выполнения алгоритма имеет кубическую зависимость от длины входной цепочки символов. Таблица Tn*n, используемая для хранения промежуточных данных в процессе работы алгоритма, является таблицей множеств. Очевидно, что требуемый для ее хранения объем памяти имеет квадратичную зависимость от длины входной цепочки символов. Сам алгоритм Кока—Янгера—Касами можно описать следующим образом: Шаг1. Цикл для j от 1 до n Т[1,j]:= {А | $ А®aj Î Р } - в T[1,j] включаются все нетерминальные символы для которых в грамматике G существует правило A®aj Конец цикла для j Шаг 2. Цикл для i от 2 до n Цикл для j от 1 до n-i+1 T[1,j] = Æ. Цикл для k от 1 до i-1 T[1,j]:= Т[1,j] È {А | $ А®ВС Î Р, BÎT[k.j], CÎT[i-k, j+k]} Конец цикла для k Конец цикла для j Конец цикла для i
Результатом работы алгоритма будет искомая таблица Tn*n. Для проверки существования вывода исходной цепочки в заданной грамматике остается только проверить условие SÎT[1,n]. Если вывод существует, то необходимо получить цепочку вывода. Для этого существует специальная рекурсивная процедура R. Она выдает последовательность номеров правил, которые нужно применить, чтобы получить цепочку вывода. Ее можно описать следующим образом: R(i,j,A), где AÎ VN. 1. Если j=1 и существует правило А®аi, то выдать номер этого правила. 2. Иначе (если j > 1) возьмем k как наименьшее из чисел, для которых $ А®ВХ Î Р, BÎT[k,j], CÎT[i-k,j+k] (таких правил может быть несколько, для определенности берем наименьшее k). Пусть правило А®ВС имеет номер m. Тогда нужно выдать этот номер m, потом вызвать сначала R(i,k,B), а затем — R(i-k,j+k,C). Для получения всей последовательности номеров правил нужно вызвать R(1,n,S). Рекурсивная процедура R не требует дополнительной памяти для своего выполнения, кроме стека, необходимого для организации рекурсии. Время ее выполнения имеет квадратичную зависимость от длины входной цепочки. На основании последовательности номеров правил, полученной с помощью алгоритма Кока—Янгера—Касами и рекурсивной процедуры R, можно построить левосторонний вывод для заданной грамматики G(VT, VN, P,S) и цепочки входных символов a. Таким образом, с помощью данного алгоритма решается задача разбора.
Вопрос 15 Грамматика обладает свойством LL(k), k > 0, если на каждом шаге вывода для однозначного выбора очередной альтернативы МП-автомату достаточно знать символ на верхушке стека и рассмотреть первые k символов от текущего положения считывающей головки во входной цепочке символов. Грамматика называется LL (k)-грамматикой, если она обладает свойством LL(k) для некоторого k > 0. Название «LL(k)» несет определенный смысл. Первая литера «L» происходит от слова «left» и означает, что входная цепочка символов читается в направлении слева направо. Вторая литера «L» также происходит от слова «left» и означает, что при работе распознавателя используется левосторонний вывод. Вместо «k» в названии класса грамматики стоит некоторое число, которое показывает, сколько символов надо рассмотреть, чтобы однозначно выбрать одну из множества альтернатив. Так, существуют LL(1)-грамматики, LL(2)-грамматики и другие классы. Очевидно, что LL(0)-грамматика бессмысленна, т.к. этом случае разбор вообще не зависит от входной цепочки. В совокупности все LL(k)-грамматики для всех k>0 образуют класс LL-грамматик. Алгоритм разбора входных цепочек для LL(k)-грамматики носит название «k-предсказывающего алгоритма». Принципы его выполнения во многом соответствуют функционированию МП-автомата с той разницей, что на каждом шаге работы этот алгоритм может просматривать k символов вперед от текущего положения считывающей головки автомата. Для LL(k)-грамматик известны следующие полезные свойства: · всякая LL(k)-грамматика для любого k>0 является однозначной; · существует алгоритм, позволяющий проверить, является ли заданная грамматика LL(k)-грамматикой для строго определенного числа k. Кроме того, известно, что все грамматики, допускающие разбор по методу рекурсивного спуска, являются подклассом LL(1)-грамматик. То есть любая грамматика, допускающая разбор по методу рекурсивного спуска, является LL(1)-грамматикой (но не наоборот!). Есть, однако, неразрешимые проблемы для произвольных КС-грамматик: · не существует алгоритма, который бы мог проверить, является ли заданная КС-грамматика LL(k)-грамматикой для некоторого произвольного числа k; · не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику к виду LL(k)-грамматики для некоторого k (или доказать, что преобразование невозможно). Это несколько ограничивает применимость LL(k)-грамматик, поскольку не всегда для произвольной КС-грамматики можно очевидно найти число k, для которого она является LL(k)-грамматикой, или узнать, существует ли вообще для нее такое число k. Для LL(k)-грамматики при k>1 совсем не обязательно, чтобы все правые части правил грамматики для каждого нетерминального символа начинались с k различных терминальных символов. Для LL(1)-грамматики, очевидно, для каждого нетерминального символа не может быть двух правил, начинающихся с одного и того же терминального символа. Однако это менее жесткое условие, чем то, которое накладывает распознаватель по методу рекурсивного спуска, поскольку в принципе LL(1)-грамматика допускает в правой части правил цепочки, начинающиеся с нетерминальных символов, а также l-правила. Поскольку все LL(k)-грамматики используют левосторонний нисходящий распознаватель, основанный на алгоритме с подбором альтернатив, очевидно, что они не могут допускать левую рекурсию. Поэтому никакая леворекурсивная грамматика не может быть LL-грамматикой. Следовательно, первым делом при попытке преобразовать грамматику к виду LL-грамматики необходимо устранить в ней левую рекурсию (соответствующий алгоритм был рассмотрен выше). Класс LL-грамматик широк, но все же он недостаточен для того, чтобы покрыть все возможные синтаксические конструкции в языках программирования (к
|
|||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-10-24; просмотров: 512; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.014 с.) |