Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
I.Формальные языки и грамматикиСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте Курс лекций по дисциплине «Архитектура ЭВМ, СПО»
Содержание Введение……………………………………………………………………...........4I.Формальные языки и грамматики ……………………………………………..5 I.1. Цепочки символов………………………………………………………..…...5 I.2. Операции над цепочками символов………………………………………....5 I.3. Понятие языка…………………………………………………....………..….6 I.4. Способы задания языка………………………………………………..……..6 I.5. Синтаксис и семантика языка…………………………………………….….6 I.6. Определение грамматики…………………………………………….………7 I.7. Пример грамматики……………………………………………………….….8 I.8. Принцип рекурсии в правилах грамматики…………………………..…….9 I.9. Способы задания грамматик……………………………………………..…..9 I.9.1. Использование метасимволов……………………………………………10 I.9.2. Запись правил грамматики в графическом виде………………………..10 I.10. Распознаватель…………………………………………………….…...…..11 I.10.1. Схема распознавателя………………………………………..…….….…11 I.10.2. Задача разбора……………………………………………..……….…….12 I.11. Классификация грамматик…………………………………..……….……13 I.12. Классификация языков……………………………………………….…....14 I.13. Примеры классификаций языков и грамматик………………….….…....14 I.14. Цепочки вывода……………………………………………………….…...16 I.14.1. Понятие о выводе……………………………………………..…….……16 I.14.2. Сентенциальная форма грамматики……………………………….…....17 I.14.3. Левосторонние и правосторонние выводы………………………...…...18 I.14.4. Дерево вывода и методы его построения ………………………….…..19 I.15. Однозначности и эквивалентности грамматик…………………….…….19 I.15.1. Однозначные и неоднозначные грамматики………………………..….19 I.15.2. Проверка однозначной и эквивалентной грамматик…………….….…20 I.15.3. Правила, задающие неоднозначность в грамматиках……………...….21 II. Принципы построения трансляторов………………………………….…....22 II.1. Определения транслятора……………………………………………..…..22 II.2. Определение компилятора…………………………………………….…..22 II.3. Определения интерпретатора……………………………………........…..23 II.4. Этапы трансляции…………………………………………….………..…..23 II.5. Фазы компиляции………………………………………………….…..…..24 II.6. ТИ (таблицы идентификаторов)…………………………..…………..….25 II.6.1. Назначение и особенности построения…………………………….......25 II.6.2. Простейшие методы ……………………………………………….....…25 II.6.3. Построение ТИ по методу бинарного дерева…………….…….……...26 II.6.4. ХЭШ-функции, ХЭШ-адресации……………………………………......27 II.6.5. Выбор Хэш-функции при построении ТИ……………………………....28 II.6.6. Хэш-адресация с рехэшированием…………………………………......28 II.6.7. Построение ТИ по методу цепочек…………………………..……..…..30 II.7. Лексические анализаторы…………………………………….………..….31 II.7.1. Назначение ЛА…………………………………………………….…….31 II.7.2. Определение границ лексем……………………………………...……..32 II.7.3. Выполнение действий, связанных с лексемами……………………..…32 II.7.4. Применение конечных автоматов (КА) для построения ЛА…….……33 II.7.5. Алгоритм построения КА……………………………………………..…33 II.7.6. Пример применения КА для построения ЛА…………………….….…34 II.8. Принципы построения синтаксических анализаторов (СА)………..…..36 II.8.1. Значение СА…………………………………………………………..….36 II.8.2. Автоматы с магазинной памятью…………………………………..…..37 II.9. Принципы построения семантического анализатора (С-А)……………38 II.9.1. Назначение С-А………………………………………………………….38 II.9.2. Проверка соблюдения во входной программе семантических соглашений………………………………………………………….……38 II.9.3. Дополнение внутреннего представления программы……………..…39 II.9.4. Проверка смысловых норм языка программирования……………….40 II.10. Принципы генерации кода……………………………………………...40 II.11. Оптимизация кода…………………………………………………….…41 Список литературы …………………………………………………………....43
Введение Базовые принципы построения средств разработки СПО – это трансляторы, компиляторы и интерпретаторы. Разработчики СПО не создают его на уровне машинных команд понятных ЭВМ, т.к. большая трудоемкость этих работ и очень большое количество ошибок. СПО разрабатывается с применением языков высокого уровня, затем оно переводится на машинный язык с помощью трансляторов(переводчиков) и компиляторов. Последний имеет почти тоже значение, что и транслятор. Транслятор – это более широкое понятие, компилятор – более узкое. Все языки программирования построены на одном базисе(теория формальных языков и грамматик). Этот же базис используется в автоматизированных системах программирования.
I.Формальные языки и грамматики I.1. Цепочки символов Понятие символа или буквы является базовым в теории формальных языков. Цепочкой символов или строкой называют произвольную упорядочную конечную последовательность символов, записанных один за одним. a d b c
Обозначение цепочек α,β,γ. Для цепочки символов имеет значение три фактора: 1.состав символов 2. их количество 3. порядок символов <<a>> и <<aa>>,<<аб>> и <<ва>> - различные цепочки символов. Цепочки α,β – равны, совпадают (α=β), если они имеют один и тот же состав символов, одно и тоже количество и одинаковый порядок следования символов в цепочке. Количество символов в цепочке называется длиной цепочки.
│α│ - длина цепочки символов отображающая таким образом │α│ Если α=β,то │α│=│ β │
I.3. Понятие языка В общем случае язык – это заданный набор символов и правил, устанавливающий способы комбинаций этих символов между собой для записи осмысленных текстов. Основой любого естественного или искусственного языка является алфавит, определяющий набор (множество) допустимых символов языка. Это множество символов обозначается V. Цепочка символов α является цепочкой над алфавитом α V: α(V),если в нее входят только символы,принадлежащие V. Для любого алфавита V пустая цепочка λ может являться или не являться цепочкой λ(V).Это условие оговаривается дополнительно. Если V некоторый алфавит, то V+ – это множество всех цепочек над алфавитом V V* – это множество всех цепочек над алфавитом λ(V) V* = V+ ∪ { λ } Языком L над алфавитом V: L(V) называется некоторое счетное подмножество цепочек конечной длины из множества всех цепочек над алфавитом V. Цепочку символов принадлежащей заданному языку часто называют предложениями языка, множество символов некоторого языка L(V) множеством предложений этого языка.
I.4. Способы задания языка Кроме алфавита язык предусматривает правила построения допустимых цепочек, т.к. не все цепочки над заданным алфавитом принадлежат языку. Символы могут объединяться в слова (лексемы) это элементарные конструкции языка, на их основе строятся предложения (более сложные конструкции). И те и другие в общем случае являются цепочками символов, но предусматривают некоторые правила построения(задающий язык). В общем случае язык можно задать тремя способами: 1) перечисление всех допустимых цепочек языка 2)указание способа порождения цепочек языка, т.е. задание грамматики языка 3)определение метода распознавания цепочек языка 1ый метод формальный и на практике не применяется (бесконечное число цепочек) 2ой способ предусматривает некоторые описания правил с помощью которых строятся цепочки языка. Когда такая цепочка, построенная с помощью этих правил из символов алфавита языка будет принадлежать заданному языку. Например: с правилами построения цепочек символов русского языка, знакомого в средней школе. 3ий способ предусматривает построение устройства (распознавателя),т.е. автомата, который на входе получает цепочку символов, а на выходе выдает ответ, принадлежит ли или нет эта цепочка заданному языку.
I.5. Синтаксис и семантика языка
В любом языке можно выделить синтаксис и семантику. Кроме того, трансляторы умеют делать с лексическими конструкциями (лексемами),которые задаются лексикой языка. Синтаксис языка – это любой набор правил, определяющий допустимые конструкции языка. Он определяет «форму» языка, т.е. задает набор цепочек символов, которые принадлежат языку. Чаще всего он задается в виде строго набора правил, но полностью это утверждение справедливо для чисто формальных языков. Для большинства языков программирования набор заданной синтаксической конструкции нуждается в дополнительных пояснениях. Например строка 3+2 является арифметическим выражением,а тройка 32+ не является. Семантика языка – это раздел языка, определяющий значения предложений языка. Она определяет содержание языка, т.е. задает смысл для всех допустимых цепочек языка. Для большинства языков она определяет неформальными методами отношение между знаками и тем, что они обозначают изучается семантикой. Чисто формальные языки лишены какого-либо смысла. Для записанного примера, используя семантику алгебры можно сказать, что строка 3+2 есть сумма чисел 3 и 2, а так же то, что 3+2=5 –это истинное выражение. Изложить синтаксис алгебры проще, чем ее семантику(хотя в случае алгебры семантику можно определить формально). Лексика – совокупность слов, словарный запас языка. Слово или лексическая единица(лексема языка) это конструкция, которая состоит из элементов алфавита языка и не содержит в себе других конструкций. Она может содержать только элементарные символы и не может содержать в себе других лексических единиц. Лексическими единицами (лексемами) для русского языка являются слова русского языка, а знаки препинания и пробелы – это разделители необразованных лексем. Лексическими единицами алгебры являются числа, знаки математических операций, обозначение функций неизвестных величин. В языках программные лексические единицы – это ключевые слова, идентификаторы, константы, метки, знаки препинания, разделители (скобки, точка запятой и др.)
I.6. Определение грамматики Грамматика языка – это описание способа построения предложений некоторого языка, т.е. математическая система, определяющая язык. Она указывает правила порождения цепочек символов языка, т.е. является генератором символов цепочек языка. Она относится ко 2ому способу определения языков (т.е. порождению цепочек символов). Она описывается различными способами. Например: грамматика русского языка описывается набором правил, изученных в школе. Для синтаксических конструкций языков программирования используют формальные описания грамматик, построенных на основе системы правил (или продукций). Правила или продукция – это упорядочная пара цепочек символов α, β. В правилах связан порядок следования цепочек, поэтому их записывают α → β или α: = β. Такая запись читается: «α порождает β»,- или так: «β по определению есть α» << α … β>>, << β … α>> Грамматика языка программирования содержит правила двух типов. Первые, определяющие синтаксические конструкции языка, они поддаются формальному описанию. Вторые, определяющие семантические ограничения языка. Они излагаются в неформальной форме. Поэтому любое описание или стандартный язык программирования состоит их 2ух частей. В первой части формально излагаются правила построения синтаксических конструкций, а потом на естественном языке дается описание семантических правил. G L(G) 2 грамматики G и G’ называются эквивалентными, если они определяют один и тот же язык. L(G)=L(G’) Две грамматики называются почти эквивалентными, если заданные ими языки различаются не более, чем на пустую цепочку символов. L(G)∪{ λ }=L(G’) ∪{ λ } Формально G определяется G(VT,VN,P,S), где VT – это множество терминальных символов или алфавит терминальных символов VN – это множество не терминальных символов или алфавит нетерминальных символов P – множество правил (продукций грамматик) Правило вида α → β, где α ∈ (VN ∪VT)+, β ∈ (VN ∪VT)* S – целевой, начальный символ грамматики S∈VT VN ⋂ VT = Алфавиты терминальных и нетерминальных символов не пересекаются. Это значит, что символ грамматики может быть терминальным, либо нетерминальным, но не может быть одновременно тем или другим. Целевой символ грамматики всегда терминальный (S). Множество V=VN∪VT называют полным алфавитом грамматики G. Множество терминальных символов VT содержит символы, которые входят в алфавит языка порождаемой грамматикой. Как правило символы из этого множества встречаются только в цепочках в правых частях правил. Множество нетерминальных символов VN содержит символы, которые определяют слова,понятия, конструкции языка. Каждый символ этого множества может встречаться в цепочках как левой, так и правой частей правил грамматики, но он обязан хотя бы 1 раз быть в левой части хотя бы одного правила. Во множестве правил могут быть несколько правил, имеющие одинаковые левые части вот такого вида: α → β1, α → β2, …, α → βn. Когда эти правила объединяют вместе, записывают в таком виде: α → β1 | β2 |…| βn. Одной строке в такой записи соответствует n-правил. Такую запись правил грамматики называют правилом Бэкуса – Наура. Эта форма предусматривает, что нетерминальные символы берутся в угловые скобки.
I.7. Пример грамматики Это грамматика G, которая определяет язык целых десятичных цифр со знаком G=({0,l,2,3,…,9,-,+},{<число>,<чс>,<цифра>},Р,<число>) Р: <<число> → <чс> | +<чс> | —<чс> <<чс> → <цифра> | <чс>|<цифра> <<цифра> → 0 | 1 | 2 | …| 9 Составляющие элементы этой грамматики: 1) множество терминальных символов VT содержит двенадцать элементов: это десять десятичных цифр и два знака; 2) множество нетерминальных символов VN содержит три символа: символы <число> и <цифра>; 3) множество правил содержит 10 правил, которые записаны в три строки Целевым символом является число. Символ <чс> бессмыслен. В названии нетерминальных символов не обязательно быть осмысленным. Они применяются для удобства понимания символов грамматики. Их набор произволен. Набор терминальных символов всегда строго соответствует алфавиту языка, определяемого грамматикой. В языках целых десятичных чисел со знаком, в котором нетерминальные символы обозначаются большими латинскими буквами. G' =({ 0, 1, 2, 3, …, 9, -, +}, {S, T, F }, Р, S) Р: S → Т | +Т | —Т Т → F | TF F → 0 | l | 2 …| 9 Здесь изменилось лишь множество нетерминальных символов VN={STF}, а язык заданный грамматикой не изменился, поэтому грамматики G и G’ считаются эквивалентными.
I.10. Распознаватель I.10.2. Задача разбора Для каждого языка программирования важно уметь не только построить текст программы, но и определить принадлежность текста к данному языку. Эту задачу решают компиляторы в числе прочих задач. Компилятор должен построить эквивалентную ей результирующую программу. В отношении исходной программы компилятор выступает в роле распознавателя. Грамматики и распознаватель – два независимых метода, которые могут быть использованы для определения какого-либо языка. При создании компилятора для некоторого языка программирования возникает задача связи между собой этих методов создания языка. Разработчикам известны языки программирования и грамматика (и стандартный язык). Задача разработчика построить распознаватель для заданного языка, который будет основой в компиляторе. Таким образом, задача разбора заключается в следующем: на основе грамматики некоторого языка построить распознаватель для этого языка. Заданная грамматика и распознаватель должны быть эквивалентны, т.е. определять один и тот же язык. Задача разбора в общем виде может быть решена не для всех языков. Языки программирования не являются чисто формальными языками и несут в себе некоторый смысл – семантику, то задача разбора для создания реальных компиляторов понимается несколько шире, чем она формируется для чисто формальных языков, т.е.компилятор должен определить, принадлежность одной цепочки символов заданному языку, но и определить ее смысловую нагрузку. Необходимо выявить те правила грамматики, на основании которых цепочка была рассмотрена. Задача разбора расширяется тем, что распознаватель в составе компилятора должен установить не только факт ошибки в входной программе, но и по возможности определить тип ошибки, но и то место в входной цепочке символов, где она встречается.
I.12. Классификация языков Языки классифицируются в соответствии с типами грамматик, которыми они заданы. Один и тот же язык может быть задан большим количеством грамматик, которые могут относиться к различным классификационным типам. Для классификации самого языка среди всех его грамматик выбирается грамматика с максимальным классификационным типом. L может быть задан G1 и G2, относящиеся типу 1, G3(тип 2),G4(тип 3), то сам язык должен относиться к типу 3 и являться регулярным. Тип 0 - язык с фразовой структурой. Это самые сложные языки, которые могут быть заданы только грамматикой типом 0. Тип 1 – КС язык. Время на распознавания языка этого типа зависит от цепочки символов. Применяется в анализе и переводе текстов в естественных языках. В компиляторах этот язык не используется. Тип 2 – КС (контекстно-свободные языки). Это основа синтаксических конструкций я.п. На их основе так же функционируют сложные командные процессы. Среди многочисленных классов существуют языки, которые распознавание предложений используют линейные зависимости, что упрощает структуру компилятора. Тип 3 – регулярные языки – самые простые и широко используются в области систем.Они лежат в основе конструкции я.п. Кроме того, на их основе строятся мнемокоды машинных команд, командные процессоры и другие структуры. Для работы с ними используются регулярные множества и выражения, а так же конечные автоматы.
I.13. Примеры классификаций языков и грамматик Классификация языков идет от простого к сложному, если имеет дело с регулярным, то так же можно считать, что является КСя., КЗ я. и языком с фразовой структурой. Существуют КС языки, которые не являются регулярными. Существуют КЗ я., которые не являются ни КС,ни регулярными языками. Пример 1 G1({0,1,2,3,…,9,-,+},{S,T,F},P1,S) правила P1: S→T|+T|-T T→F | TF F→0|…8|9 По структуре своих правил относится к КС гр. (тип2). Ее можно отнести и к типу 0, и к типу, но максимальным возможным является тип 2. К типу 3 нельзя отнести T→F | TF T→ TF (нельзя допустить для типа 3) Для того же самого языка можно построить и др. грамматику. G1’({0,1,2,3,…,9,-,+}, {S,T,F},Р1’, S) P1’ S→T|+T|-T T→ 0|1|…9| от |1T|…|8T|9T По структуре своих правил является праволинейной и может быть отнесена к регулярным грамматикам (тип 3). Можно построить эквивалентную леволинейную грамматику (тип 3) G1’’({0,1,2,3,…,9,-,+}, {S,T,F},Р1’’, S) Р1’’ T→+ | - | λ S→T0|T1|…T9|S0|S1|…S8|S9 Следовательно язык L1, заданный грамматиками G1,G1’,G1’’, относится к регулярным языкам (тип 3) Пример 2 G2({0,1},{A,S},P2,S) P2: S→0A1 0A→00A A→ λ Относится к типу 0, определяет язык множества предложения, которое может быть записано L(G2)={0n1n| n Для этого языка можно построить так же КЗ гр. G2 ’({0,1},{A,S},P2’,S) P2’: S→0A1|01 0A→00A1|001 G2’’ ({0,1},{ S},P2’’,S) P2’’ S→0S1|01 L2={0n1n| n>0} КС (тип 2) Пример 3 G3({a,b,c},{B,C,D,S},P3,S) P3 S → BD B → aBbC | ab Cb → bC CD → Dc bDc → bcc abD → abc L(G3) = {anbncn| n>0} Эта грамматика относится к типу 1 и является неукорачивающей. Она определяет язык множества предложений, который может быть записан L(G3) = {anbncn| n>0}. Этот язык не является КС языком, поэтому для него нельзя построить грамматику типа 2 и 3. Но для того же самого языка можно построить КЗ гр.
G’3({a,b,c,},{B,C,D,E,F,S},P3’,S) P3’ S→abc |AE A→aABC|aBC CBC→CDC CDC→BDC BDC→BCC CCE→CFE CFE→CFc CFc→CEc aB→ab bB→bb BCE→bCc bCc→be L3={anbncn| n>0} Этот язык является КЗ языком (тип 1)
I.14. Цепочки вывода I.14.1. Понятие о выводе Выводом называется процесс порождения предложения языка на основе правил, определяющих язык грамматики. Используются такие понятия β = δ1 γ δ2 – называется непосредственно выводимой из цепочки α = δ1 ω δ2 из грамматики G(VT,VN,P,S), V=VT ∪ VN, δ1,υ, δ2 ∈ V* > ω ∈ V+ в ней существует правило ω → υ ∈ P Непосредственная выводимость цепочки β из цепочки α обозначается α ⇒β При выводе выполняется подстановка по цепочке γ вместо подцепочки ω, β –выводима из цепочки α в том случае, если можно взять несколько символов в цепочке α, заменить их на другие символы, согласно некоторому правилу грамматики и получить цепочку β. При непосредственной выводимости любая из цепочек δ1, δ2 может быть пустой или обе могут быть пустыми. В предельном случае цепочка α может быть заменена на цепочку β, тогда в грамматике G должно существовать правило α ⇒β ∈ P Цепочка β называется выводимой из цепочки α (α ⇒*β) в том случае, если выполняется одно из двух условий: 1. β – непосредственно выводимая из α (α ⇒β) 2. γ - непосредственно выводимая из β (γ ⇒β) ∃ γ такая, что γ, выводимая из α и β, - непосредственно выводимая γ ⇒α β ⇒*γ Суть в том, что β выводимая из цепочки α (α ⇒β) или если можно построить последующие непосредственные цепочки из α ⇒β В этой последовательности каждая последующая цепочка υi непосредственно выводима из предыдущей цепочки υi-1 . Такая последовательность непосредственно выводимых цепочек называется выводом или цепочкой вывода. Каждый переход от одной непосредственно выводимой цепочки к следующей цепочке вывода называется шагом вывода. Если цепочка β выводится непосредственно из цепочки α, имеется один шаг вывода. Если цепочка от α к β имеет несколько промежуточных цепочек, она имеет специальное обозначение α ⇒ +β Если число шагов вывода известно, то его можно непосредственно указать в знаках выводимости цепочек α ⇒4 β (цепочка β выводится из цепочки α за 4 шага вывода) Пример G({0,1,…,9,-,+},{S,T,F},P,S) P: S→ |+T|-T T→F | TF F→0|…|9 Построим несколько произвольных цепочек вывода 1) S⇒-T⇒-TF⇒-TFF⇒-FFF⇒-4FF⇒-47F⇒-479 2) S⇒T⇒TF⇒T8⇒F8 ⇒18 3) T⇒TF⇒T0⇒TF0⇒T50⇒F50⇒350 4) TFT⇒TFFT⇒TFFF⇒FFFF⇒1FFF⇒1FF4⇒-10F4 ⇒1004 5) F ⇒5 Результат 1) S ⇒* 479 или S ⇒ + - 479 или S ⇒7 -479 2) S ⇒* 18 или S ⇒+18 или S ⇒518 3) T ⇒* 350 или T ⇒ -250 или T ⇒6 350 4) T ⇒* 1004 или TFT ⇒+1004 или TFT ⇒7 1004 5) F ⇒* 5 или F 15 Выводы построены на основе грамматики G. Можно построить сколько угодно цепочек вывода. Пример 2 G3(a,b,c),{B,C,D,S},P3} P3 B→ aBbC|ab Cb→bC CD→Dc bDc→bcc abD→abc L(G3)={anbncn| n>0} aaaabbbbcccc
S ⇒BD ⇒ aBbCD ⇒aaBbCbCD ⇒ aaaBbCbCbCD ⇒aaaabbCbCbCD⇒ aaaabbbCCbCD ⇒ ⇒aaaabbbCbCCD ⇒ aaaabbbbCCCD ⇒aaaabbbbCCDc ⇒ aaaabbbbCDcc ⇒ aaaabbbbDccc ⇒ ⇒ aaaabbbbcccc Тогда для грамматики G3 получили вывод S⇒* aaaabbbbcccc
II.1. Определения транслятора Всё, что до сих пор читалось, является теорией трансляторов. Транслятор – это программа, которая переводит программу на исходном входном языке в эквивалентную ей программу на результирующем выходном языке. В определении слово «программа» встречается 3 раза, что говорит о том, что в работе транслятора участвуют 3 программы. 1)Сам транслятор является программой. Это часть ПО. Он представляет собой набор машинных команд и выполняется компилятором, как и все прочие программы в ОС. Все составные части транслятора представляют собой динамичную загружаемые библиотеки и модули этой программы со своими входными и выходными данными. 2) Выходными данными транслятора является программа на результирующем языке, называемая результирующей программой. Она строится по синтаксическим правилам выходного языка транслятора. А ее смысл определяется семантикой выходного языка. Важным является эквивалентность исходной и результирующей программ, что означает совпадение их смысла с точки зрения исходного языка. Без выполнения этих требований, транслятор теряет фактический смысл. Чтобы создать транслятор, необходимо выбрать входной и выходной языки. С точки зрения преобразования предложений входного языка в эквивалентные им предложения выходного языка транслятор выступает как переводчик. Результатом работы транслятора будет результирующая программа, но только в том случае, если текст исходной программы является правильным, т.е. не содержит ошибок с точки зрения синтаксиса и семантики входного языка. Если исходная программа содержит хотя бы одну ошибку, то результатом работы транслятора будет сообщение об ошибке, как правило, с дополнительным сообщением о месте возникновения ошибки в исходной программе.
II.3. Определения интерпретатора Интерпретатор - это программа, которая воспринимает входную программу на исходном языке и выполняет ее. Он, так же как и транслятор, анализирует текст исходной программы,но он не порождает результирующую программу,а сразу же выполняет исходную программу в соответствии с ее смыслом, заданным семантикой входного языка. Результат его работы определен смыслом исходной программы. Результатом может быть сообщение об ошибке. Чтобы исполнить исходную программу,он должен преобразовать ее в язык машинных кодов. Эти коды не доступны для пользователей. Они используются и уничтожаются по мере надобности, так как того требует конкретная реализация тотализатора. Пользователь видит результат выполнения этих кодов, т.е. результат выполнения исходной программы.
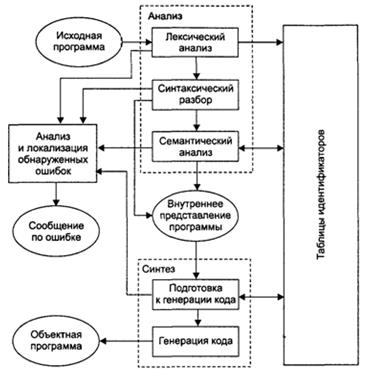
II.4. Этапы трансляции Они представлены на следующем рисунке
Процесс компиляции состоит из 2ух основных этапов: анализа и синтеза. На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов(ТИ). Результатом работы этапа служит некое внутреннее представление программы, понятное компилятору. На этапе синтеза на основании этого представления и информации, содержащейся вТИ, порождается текст результирующей программы. Конечный результат - объектный код. В составе компилятора входит часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки. Эти этапы состоят из более мелких этапов, называемых фазами компиляции. Их конкретная реализация и процесс взаимодействия различаются в зависимости от версии компилятора. Компилятор, с точки зрения формальных языков, выполняет две основные функции: 1)является распознавателем для языка исходной программы, т.е. он должен получить на вход цепочку символов входного языка, проверить ее принадлежность языку и правила, по которым она была построена (генератором цепочки входного языка выступает пользователь — автор исходного языка); 2) компилятор является генератором для языка результирующей программы. Он должен построить на выходе цепочку выходного языка по определенным правилам, предполагаемым языком машинных команд или языком ассемблера. В случае м.к. распознавателем этой цепочки будет выступать целевая ВС, под которую создается результирующая программа.
II.5. Фазы компиляции 1.Лексический анализ — это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического разбора. 2.Синтаксический разбор — это основная часть компилятора. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы. Синтаксический разбор выполняет роль распознавателя текста входного языка программирования. 3.Семантический анализ — это часть компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме этой проверки, он должен выполнять преобразования текста, требуемые семантикой входного языка. 4.Подготовка к генерации кода. Здесь выполняются предварительные действия, непосредственно связанные с синтезом текста результирующей программы, но еще не ведущие к порождению текста на выходном языке. В эту фазу входят например действия, связанные с идентификацией элементов языка, распределением памяти и др. 5.Генерация кода — это фаза, непосредственно связанная с порождением команд, составляющих предложения выходного языка и в целом текст результирующей программы. Это основная фаза синтеза на результирующем этапе. Кроме непосредственного порождения текста результирующей программы, генерация обычно включает в себя также оптимизацию, т.е. процесс, связанный с обработкой уже порожденного текста. 6.Таблицы идентификаторов (ТИ) — это специальным образом организованные наборы данных, служащие для хранения информации об элементах исходной программы, которые затем используются для порождения текста результирующей программы (переменные, константы, функции и др.). Конкретный состав набора элементов зависит от конкретного используемого языка программирования.
II.6. ТИ (таблицы идентификаторов) II.6.2. Простейшие методы Самый простой способ – это добавлять элементы в порядке их поступления. Тогда ТИ – это неупорядоченный массив информации, каждая ячейка которого содержит данные о соответствующем элементе таблицы.Поиск нужного элемента – это последовательное сравнение искомого элемента с каждым элементом таблицы, пока не будет найден нужный. Если за единицу времени принять время, затраченное компилятором на сравнение 2ух элементов, то для таблицы, содержащей N элементов в среднем будет выполняться N/2 сравнений. Заполнение ее – это добавление элемента в ее КС и время, требуемое для добавления элемента ТЭ, не будет зависеть от числа элементов в таблице N. Но если N велико, то поиск потребует значительных затрат времени. Поиск элементов такой таблицы Tn=O(N), поскольку поиск элементов Ti является часто выполняемой компилятором операцией, а количество различных идентификаторов в реальной исходной программе велико (от нескольких сотен до нескольких тысяч элементов), то такой поиск является неэффективным. Он будет более эффективным, если элементы таблицы упорядочены согласно некоторому порядку. Т.к. поиск осуществляется по имени идентификаторов, наиболее естественным решением будет расположить элементы таблицы в прямом или обратном алфавитном порядке. Эффективным способом поиска в упорядоченном списке из N элементов является бинарный или логарифмический поиск. Искомый элемент сравнивается с элементом (N+1)/2 в середине таблицы. Если этот элемент не является искомым, то нужно рассмотреть только блок элементов, пронумерованных от 1 до (N+1)/2-1, или блок элементов от (N+1)/2+1 до N, в зависимости от того, меньше или больше искомый элемент того, с которым его сравнили. Затем процесс повторяется над нужным блоком в два раза меньшего размера. Так продолжается до тех пор, пока искомый элемент не будет найден, либо алгоритм не дойдет до очередного блока, содержащего один или два элемента, с которыми можно выполнить прямое сравнение искомого элемента. Максимальное число сравнений равно 1+log2(N) - время поиска Тn = O(log2N). Пример: для N=127 бинарный поиск потребует максимум 8 сравнений, а поиск в неупорядоченной таблице — 64 сравнения. Недостаток логарифмического сравнения – это требование упорядочивания таблицы идентификаторов. Время его заполнения будет зависеть от числа элементов в массиве. ТИ просматривается еще до того, как она заполнена полностью, поэтому условие упорядоченности должны выполняться на всех этапах обращения к ней. Поэтому, для построения такой таблицы можно пользоваться упорядоченным элементом прямого подключения. При добавлении каждого нового элемента в таблицу сначала надо определить место, куда его поместить, а потом выполняют перенос части информации в таблице, если элемент добавляется не в ее конец. Среднее время, необходимое для помещения всех элементов в таблицу ТЗ = (N * log2N)+ K*O(N 2) K – коэф., отраж. соотношение между временем, затраченным на выполнение операции сравнения и операции переноса. При логарифмическом поиске добиваются существенного сокращения времени поиска нужного элемента за счет увеличения времени на помещение нового элемента в таблицу. Т.к. добавление новых элементов происходит значительно реже, чем обращение к ним, то этот метод более эффективен, чем метод организации неупорядоченной таблицы.
II.7.1. Назначение ЛА Лексема (лексическая единица языка) — это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и др. Состав возможных лексем для каждого конкретного языка является синтаксисом этого языка. Лексический анализатор (или сканер) — это часть компилятора, которая читает исходную программу и выделяет в ее тексте лексемы входного языка. Выходная информация передается для дальнейшей обработки компилятора. Есть причины, по которым в состав всех компиляторов включают ЛА. 1)Упрощается работа с текстом исходной программы на этапе синтаксического разбора. Сокращается объем обработанной информации, т.к. ЛА структурирует на поступ. на вход исходного текста программы и отбрасывает всю незначащую информацию. 2)Для выделения в тексте и разбора лексем можно применять простую эффективную и теоретически хорошо проработанную технику анализа, в то время, как на этапе СА конструкция исходного языка использует сложные алгоритмы разбора. 3)ЛА отделяет сложный по конструкции СА от работы с текстом исходной программы, структура которого может изменяться от версии входного языка. При такой конструкции компилятора для перехода одной версии к другой нужно только перестроить простой ЛА. ЛА исключает из текста исходной программы комментарии, незначащие пробелы, символы табуляции и перевода строки
|
||
|
|
Последнее изменение этой страницы: 2016-08-15; просмотров: 1163; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.108 (0.018 с.) |


 0}
0}