
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Этапы классификации речевых сообщений. Формализация задачи классификации текстовСтр 1 из 7Следующая ⇒
Лекция № 14. Классификация Парадигматический подход
Парадигматический подход предполагает измерение семантических расстояний в лексиконе. Исходный тезис таков: семантическую близость следует определять, опираясь на данные о значении, хранящиеся «внутри» языкового знака, а не за его пределами. Определив лексикон языка как сложным образом упорядоченное множество классов слов, связанных парадигматическими отношениями (семантических полей или группировок иного толка, например, лексико-семантических групп, синонимических рядов), и описав значения единиц данных классов с помощью набора неких семантических признаков, можно применить к описанию языкового материала несложный математический аппарат. Класс лексических единиц при этом интерпретируется как n-мерное метрическое пространство, в котором каждое из значений лексем можно задать как точку или вектор. Для пары лексем расстояние определяется через число совпадающих или различающихся семантических признаков в их значениях. Наиболее известный лексикографический ресурс, оснащённый специализированным модулем для определения количественных оценок тесноты связей между значениями слов, – это компьютерный тезаурус WordNet. WordNet это семантический словарь английского языка, базовой словарной единицей которого является синонимический ряд, так называемый «синсет», объединяющий слова со схожим значением. Синсеты связаны между собой различными семантическими отношениями. WordNet содержит приблизительно 155 тысяч различных лексем и словосочетаний, организованных в 117 тысяч синсетов, разбитых по частям речи: существительные, глаголы, прилагательные и наречия. Чтобы воспользоваться информацией WordNet в классификаторе, необходимо решить задачу устранения лексической многозначности слов. Разрешение лексической многозначности (Word Sense Disambiguation, WSD) — это задача выбора значения (концепта) многозначного слова или фразы из множества их значений (концептов) в зависимости от контекста, в котором данное слово находится. Одним из эффективных методов устранения лексической многозначности на базе WordNet является метод, основанный на оценке семантической близости концептов WordNet с помощью контекстных векторов второго порядка [Patwardhan S., Pedersen T. Using WordNet-based context vectors to estimate the semantic relatedness of concepts//EACL 2006 Workshop Making Sense of Sense. — 2006. P.1–8.].
В определении значений слов существенную роль играет контекст. Одно и тоже значение слова, как правило, употребляется в одинаковом контексте. Контекстные векторы широко используются в информационном поиске и в задачах обработки естественного языка. Контекстный вектор Чтобы построить контекстные векторы второго порядка (векторы дефиниций) для синсетов WordNet, необходимо определить пространство слов W. Оно обычно представляется матрицей, строки которой являются контекстными векторами первого порядка. Значения на пересечениях строк и столбцов указывают на частоты совместной встречаемости двух слов в тексте. Определив пространство слов, контекст можно представить как сумму контекстных векторов первого порядка слов, определяющих этот контекст. Итак, пространство слов W определяется множеством контекстных векторов первого порядка. Чтобы построить контекстный вектор первого порядка для слова w, необходимо последовательно выполнить следующие действия: 1. Инициализировать контекстный вектор первого порядка 2. Найти каждое вхождение слова w в тексте. 3. Для каждого вхождения слова w увеличить значения вектора Таким образом, контекстный вектор первого порядка В качестве корпуса текстов для построения контекстных векторов первого порядка используются дефиниции синсетов WordNet. Такой корпус содержит приблизительно 1,4 миллиона слов, а размерность пространства слов составляет порядка 20 тысяч без учета редко встречающихся и так называемых стоп-слов (стоп-слова – это наиболее распространенные, встречающиеся в большинстве документов, и чаще всего высокоранговые слова, которые не несут высокой смысловой нагрузки и обычно используются для связи слов в предложении).
Определение значения терма tj осуществляется следующим образом: 1.Вычисляется контекст для терма tj. Контекст определяется суммой контекстных векторов первого порядка слов, находящихся на расстоянии в пять позиций слева и справа от терма tj в документе. 2.Производится оценка семантической близости всех возможных концептов tj. Для каждого концепта вычисляется косинус угла между вектором его дефиниции и контекстом. 3.Самый близкий концепт si выбирается в качестве значения терма tj.
Наряду с косинусной мерой можно использовать меру: · Хэмминга, значение которой в одинаковой степени определяется всеми признаками, рассматриваемыми как равноправные; · Евклида, учитывающая расхождения между сравниваемыми объектами по всевозможным признакам, но значение которой во многом определяется значением доминирующего признака; · Чебышева, пренебрегающая периферийными признакам сравниваемых объектов и учитывающая расхождение по основному признаку, особенно если у него много значений. У ресурсов типа WordNet есть свои преимущества (например, возможность дифференцировать различные значения одного и того же слова), однако они уступают корпусным ресурсам, отличающимся не только удобством в практическом использовании и гибкостью, но и известной беспристрастностью. Методы синтагматического подхода, при котором необходимо обращаться к представительному корпусу текстов, дают возможность работать с точными данными, на их основе реконструировать ментальный лексикон человека и готовить разнообразные семантические описания.
Модель n-грамм
В полиграммной модели со степенью n и основанием M текст представляется вектором {fi}, i=1..Mn, где fi – частота встречаемости i -ой n -граммы в тексте. n -грамма является последовательностью подряд идущих n – символов вида a1…an-1an, причем символы ai принадлежат алфавиту, размер которого совпадает с M. Непосредственно номер n -граммы определяется как
Mn r(an) + Mn-1 r(an-1) +...+r(a1),
где r(ai) ϵ [1,M] – порядковый номер символа ai в алфавите. Предполагается, что частота появления n -граммы в тексте несет важную информацию о свойствах документа, поэтому является информативным признаком при представлении текстов документов. Кроме того, максимальное количество n -грамм постоянной длины для данного языка фиксировано и не зависит от объема обучающего корпуса текстов. Так, например, для русского языка, как правило, используется модель со степенью n =3 (триграммная модель) и основанием M =33, при этом применяется русский алфавит с естественной нумерацией символов r("А") = 1, r("Б") = 2,..., r("Я") = 32. Все остальные символы считаются пробелами с нулевыми номерами. Несколько подряд идущих пробелов считаются одним. С учетом этого размерность вектора для произвольного текста жестко фиксирована и составляет 333= 35937 элемента. Однако, как показывает практика, в реальных текстах реализуется не более 25-30 процентов n-грамм от общего допустимого их числа, т.е. для русского языка их не более 7000. Кроме того, сведения о биграммах и триграммах символов наиболее частых слов русского языка существуют в электорнном виде и находятся в свободном доступе [Шаров С.А. Частотный словарь русского языка [Электронный ресурс]. – Режим доступа: http://www.artint.ru/projects/frqlist.asp, свободный ].
Достоинствами полиграммной модели являются: · отсутствие необходимости дополнительной лингвистической обработки; · фиксированная размерность векторов и простота получения векторного описания текста. К недостаткам отнесем следующее: · отражение векторами {fi} содержания текста не всегда адекватно (такой моделью плохо отражается содержание небольших текстов; модель больше подходит для определения языка текста, чем для классификации по тематике), · в соответствии с предыдущим пунктом возникает необходимость более тщательного подбора обучающей выборки текстов. Количественное описание семантических связей, наблюдаемых в языке и в тексте, построение классификаторов на их основе невозможно без обращения к методам теории вероятностей, математической статистики, теории множеств, теории информации, теории распознавания образов и предполагает разработку специализированных алгоритмов и программ.
Классический метод классификации текстов делает очень сильные предположения о независимости участвующих событий (появления слов в документах), но практика показывает, что наивный байесовский классификатор оказывается весьма эффективен. При описании вероятностной модели, как и ранее, используется множество рубрик C, каждая из которых представлена фиксированным набором ключевых слов, множество документов D, по которому составлен словарь коллекции Метод Байеса заключается в вычислении вероятностей сопоставления документа каждой из рубрик и выборе рубрики, вероятность для которой будет максимальной. Каждая рубрика ci характеризуется безусловной вероятностью ее выбора P(ci) в процессе классификации некоторого документа (совокупность таких событий для всех рубрик образуют систему гипотез, так что
Апостериорная вероятность принадлежности документа d рубрике ciпо теореме Байеса вычисляется так:
Делая предположение о независимости термов в документе, получаем:
Далее задача состоит в нахождении оценок априорных вероятностей P(ci) и P(w|ci). Оценить P(ci) можно с помощью отношения количества документов из обучающей выборки, которым приписана рубрика ci, к количеству документов в обучающей выборке
P(w|ci) можно оценить как отношение документов из рубрики ci, содержащих терм w, к общему числу документов в рубрике ci:
В числителе добавлена единица для избегания нулевых вероятностей. Запишем решающее правило для метода Байеса:
На практике существует два подхода к использованию метода Байеса для классификации: 1) для каждой рубрики в отдельности принимать решение относится документ к ней или нет – бинарная классификация. При этом множество рубрик С сокращается до двух – ciи 2) вычислять P(ci|d) для всех рубрик и выбирать те, для которых эта вероятность будет максимальной.
Другой подход у оценке условной вероятности P(ci|d) предложен в методеProbabilistic TF-IDF (PrTFIDF). Терм w встречается в документе d с вероятностью P(w|d). Применяя формулу полной вероятности и затем теорему Байеса, получаем:
Делая предположение о том, что терм w несет исчерпывающую информацию о документе d в целом, так что принадлежность документа к той или иной категории не вносит дополнительной информации о документе в целом, получим P(d|ci,w) ≈ P(d|w). Очевидно, что если в качестве термов выбраны леммы, то данное предположение не всегда верно, в частности, для слов, имеющих несколько смысловых значений. Тем не менее, в целях упрощения можно попробовать использовать это предположение, получаем:
Остается вычислить оценку этих двух вероятностей. P(w|d) вычисляется на основе представления документа d:
где TF(w,d) – частота вхождения слова w в документ d, |d| – общее количество слов в документе.
Применяя теорему Байеса, найдем вероятность того, что документ, в котором есть слово w, принадлежит рубрике ci. По аналогии с моделью наивного байесовского классификатора, логично предположить, что оценки вероятностей P(ci) следует вычислять оценки этих вероятностей на основе априорной информации как отношение количества документов в рубрике к общему числу документов, однако, как показывает практика, классификатор, использующий неравные вероятности для рубрик, давал существенно худшие результаты, поскольку он в основном выбирал рубрики с большим числом документов и игнорировал рубрики с небольшим числом документов. Поэтому следует сделать предположение о том, вероятности P(ci) одинаковы для всех рубрик, следовательно:
Оценка P (w|ci) может быть вычислена на основе обучающего набора данных как
На основе полученных оценок аппроксимируем вероятность P(ci|d):
Запишем решающее правило для алгоритма PrTFIDF. В случае, если значение P(ci|d) не требуется в качестве меры уверенности в выборе рубрики, то знаменатель первой дроби можно не рассчитывать. Тогда классификатор f имеет вид:
Задача обучения классификатора сводится к вычислению всех возможных P (w|ci) на основе обучающей выборки документов. Размерность пространства при построении вектора признаков, равна числу различных термов содержащихся в обучающей выборке текстов. Из-за того, что учитываются все слова, которые когда-либо встретились в текстах, вектора получаются с огромным количеством координат, большинство из которых нули. Многие алгоритмы классификации очень чувствительны к времени вычисления, которое часто является функцией от длины вектора, представляющего документ, поэтому необходимо стараться уменьшить размерность пространства признаков. Существуют различные расширения базового подхода, позволяющие сократить размерность признакового пространства. Например, можно по-другому выбирать термы. Бывает полезным брать в качестве термов не слова, а устойчивые группы слов, вводить дополнительные термы (например, характеризующие длину документа). Для сокращения размерности векторов можно не учитывать редкие слова, которые увеличивают размер правила, но, как правило, не несут полезной для классификатора информации. Для чего вводят коэффициент полезности каждого терма (насколько этот терм полезен для классификации). Эту характеристику можно определить, основываясь на корреляции между встречаемостью слова в документе и принадлежностью этого документа к одной (или нескольким) из категорий. Наиболее простой и популярный подход – удаление из вектора признаков стоп-слов. Кроме удаления лишних термов, можно ещё группировать несколько термов в один. Например, можно группировать вместе синонимы. Ещё один подход — совстречаемость (cooccurrence): объединять слова, часто встречающиеся в одном окружении. Например, в словосочетаниях «руководитель компании», «директор компании» слова «руководитель» и «директор» встречаются перед словом «компания». Поэтому их можно объединить в один искусственный терм. В общем случае для слов определяется некая метрика близости, и группы близких слов склеиваются в один терм. Вес такого терма в каждом конкретном документе рассчитывается из весов представителей группы, которые встречаются в этом документе. Одними из самых распространенных подходов, к уменьшению размерности пространства признаков, являются стемминг (процедура усечения окончаний) [D.A. Hull. Stemming Algorithms – A Case Study for Detailed Evaluation, JASIS, 47(1): 70-84, 1996 ], алгоритмы, основанные на правилах словообразования [M.F.Porter. An algorithm for suffix stripping, Program, 14(3):130-137, 1980 ], а также их комбинации. Они используют предположение, что приведение различных встречающихся форм слова к одному поисковому признаку (к одной форме) значительно уменьшит размерность признакового пространства, что может увеличить скорость и обработки и положительно сказаться на результате классификации. Эту процедуру выполняет модуль морфологического анализа. В литературе данный модуль также называют нормализатором слов, лемматизатором или стеммером. Операцию, или выполняемую данным модулем можно представить как отображение W→L, где W – множество всех терминов в коллекции документов; L – множество всех соответствующих лемм. При этом количество лемм меньше мощности множества всех терминов |W|>|L|. Реализуя данное преобразование, можно достичь улучшения точности поиска за счет использования вместо частот слов частоты лемм, что позволяет получить больший вес для релевантных документов. Кроме того, так как количество лемм меньше количества слов, то лемматизация приводит к уменьшению размерности пространства признаков и увеличению скорости классификации. Такая предварительная обработка - сокращение текста для более точной классификации, с помощью описанных выше подходов называется препроцессинг. Однако надо сказать, что развитие методов смыслового сжатия текстов [Леонтьева Н. Н. Неполнота и смысловое сжатие в текстовом корпусе // Международная конференция MegaLing'2005 «Прикладная лингвистика в поиске новых путей». Материалы конференции. Меганом, Крым, Украина. Симферополь: Изд-во «Осипов». СПб, 2005. C. 67-73.] и совершенствование алгоритмов классификации приводит к тому, что использование морфологической обработки для уменьшения размера индекса в настоящее время не является критически важным в большинстве случаев. Проблема классификаций произвольной области знаний, к сожалению, не всегда разрешима из-за синонимии и полисемии языка. В первом случае имеется в виду, что одно и то же понятие может быть выражено в документе и в запросе с использованием различных терминов - синонимов. Например, самолет и аэроплан. Во втором случае, один термин может иметь различные значения в различных контекстах. Например, рак - это беспозвоночное, болезнь и созвездие. В приведенных же классических моделях изначально предполагалось рассмотрение документов как множества отдельных слов вне контекста, не зависящих друг от друга, грамматика и порядок следования слов игнорируются. Такая упрощающая концепция имеет название «Bag of Words». Один из подходов к решению проблемы синонимии и полисемии языка, учитывающий контекстную близость и существенно сокращающий размерность вектора признаков, связан с использованием классификаторов, основанных на функциях подобия.
Сеть Гроссберга (ART) Топология сети ART (Adaptive Resonance Theory), разработанная Гроссбергом и Карпентером, хорошо зарекомендовала себя для решения задач кластеризации. Основная идея сетей Гроссберга - опознание образа за счет сравнения характерных признаков сигнала с запомненным ранее эталоном (классом). Сеть состоит из двух слоев нейронов. Первый (входной) слой – сравнивающий, содержит столько нейронов, сколько терминов в словаре обучающей выборки документов; второй слой – распознающий. В общем случае между слоями существуют прямые связи с весами wijот i–ого нейрона входного слоя к j–ому нейрону распознающего слоя, обратные связи с весами vij– от i-ого нейрона распознающего слоя к j–ому нейрону входного слоя. Так же существуют латеральные тормозящие связи между нейронами распознающего слоя. Каждый нейрон распознающего слоя отвечает за один класс объектов. Веса wij используются на первом шаге классификации для выявления наиболее подходящего нейрона – класса, веса обратных связей vijхранят типичные образы (прототипы) соответствующих классов и используются для непосредственного сопоставления с входным вектором. Сеть ART имеет достаточно много выходных нейронов, однако используется только часть из них. В сети хранится набор образцов для сравнения с входным сигналом. Если входной сигнал достаточно похож на один из эталонных образцов (находится с ним в резонансе), усиливается вес для синапса нейрона, отвечающего за данную категорию. Если же в сети нет схожих с входным вектором образцов, ему в соответствие ставится один из незадействованных выходных нейронов [Ф. Уссермен Нейрокомпьютерная техника. - М.: Мир, 1992. ]. Согласно назначению приведенных компонентов такой сети процедура классификации представляет собой следующую последовательность операций: 1. Вектор X подается на вход сети, для каждого нейрона распознающего слоя определяется взвешенная сумма его входов. 2. За счет латеральных тормозящих связей распознающего слоя на его выходах устанавливается единственный сигнал с наибольшим значением, остальные выходы становятся близкими к 0: yi=max(Y) 3. Определяется мера близости Siмежду входным вектором X и прототипом класса Vi, соответствующего i-ому нейрону, победившему на предыдущем шаге. Если результат сравнения превышает порог p, делается вывод о том, что входной вектор принадлежит классу ci, в противном случае выход данного нейрона обнуляется (принудительная блокировка) и повторяется процедура на шаге 2, в которой за счет обнуления самого активного нейрона происходит выбор нового.
4. Шаги 2-3 повторяются до тех пор, пока не будет получен класс cout, либо пока не будут принудительно заблокированы все нейроны распознающего слоя. В реализации классификатора некоторые компоненты сети могут быть опущены. Например, можно убрать связи латерального торможения, вместо двух матриц Wijи Vijиспользуется одна – Wij, которая отвечает и за выбор предпочтительного нейрона-класса, и за хранение прототипов классов. В этом случае вычисление функции сопоставления S совмещает в себе шаги 2 и 3 и рассчитывается непосредственно для X и весовых векторов Wi, побеждает тот нейрон i, для которого max(Si). Для обучения сети используются такие меры близости:
где β - положительная константа, n - размерность вектора признаков. Алгоритм обучения [Alberto Muñoz. Compound Key Word Generation from Document Databases Using A Hierarchical Clustering ART Model, 1997 ] состоит из следующих шагов. 1. На входы подать обучающий вектор X. Активизировать все нейроны выходного слоя. 2. Найти активный нейрон с прототипом Wi, наиболее близким к X, используя меру близости Si’. 3. Если для найденного нейрона 4. Если для найденного нейрона Si <ρ, ρ ∈ [0,1], 3. то деактивировать найденный нейрон. Если все нейроны неактивны, то создать новый класс Wi = X, идти на шаг 1. Иначе идти на шаг 2 и попробовать другой еще активный нейрон. 5. Если для найденного нейрона Si' и Siпревышают пороги, указанные на шаге 4 и 5, то модифицировать его веса Wi= λ X Wi+ (1 − λ) Wi, передвинув ближе к входному вектору. На количество образующихся классов оказывают влияние константы β и ρ. С ростом ρ и уменьшением β их количество увеличивается. Коэффициент обучения 0 < λ < 1 определяет скорость обучения. В начале обучения его значения должно быть большим и монотонно уменьшаться со временем. Cнижение ρ и увеличение β снижает избирательность сети, что приводит к снижению точности и повышению полноты классификации. Классификация документов сводится к предъявлению обученной нейронной сети вектора авизируемого текста X и поиска из всех нейронов распознающего слоя того, для которого Si наибольшая. При использовании в качестве входных векторов представление текста в виде лексических векторов модели терм-документ, входной слой содержит столько нейронов, сколько терминов в словаре обучающей выборки документов (Nw), весовые вектора Wi нейронов распознающего слоя содержат значимость wjij-ого термина для i-ого класса. При использовании триграммной модели представления текста число входных нейронов соответствует M3, при этом весовые вектора Wiопределяют значимость wjij-ой триграммы для i-ого класса.
Сеть Кохонена (SOM) Назначение сети Кохонена (SOM, Self-Organizing Map, – самоорганизующиеся карты Кохонена) [Круглов В.В., Борисов В.В. Искусственные нейронные сети. Теория и практика. – М.: Горячая линия – Телеком, 2001. ] – разделение векторов входных сигналов на группы, поэтому возможность представления текстов в виде векторов действительных чисел позволят применять данную сеть для кластеризации. Cеть состоит из одного слоя, имеющего форму прямоугольной решетки для 4-х связных нейронов и форму соты для 6-ти связных. Анализируемые вектора X подаются на входы всех нейронов. По результатам обучения геометрически близкие нейроны оказываются чувствительными к похожим входным сигналам, что может быть использовано в задаче классификации следующим образом. Для каждого класса определяется центральный нейрон и доверительная область вокруг него. Критерием границы доверительной области является расстояние между векторами соседних нейронов и расстояние до центрального нейрона области. При подаче на вход обученной сети вектора текста активизируются некоторые нейроны (возможно из разных областей), текст относится к тому классу, в доверительной области которого активизировалось наибольшее число нейронов и как можно ближе к ее центру. Алгоритм обучения сети заключается в следующем. Все вектора должны лежать на гиперсфере единичного радиуса. Задается мера соседства нейронов, позволяющая определять зоны топологического соседства в различные моменты времени. Кроме того, задается размер решетки и размерность входного вектора, а так же определяется мера подобия векторов S (наиболее подходящей является косинус угла). Далее выполняются следующие шаги для каждого вектора обучающей выборки. 1. Начальная инициализация плоскости может быть произведена, например произвольным распределением весовых векторов на гиперсфере единичного радиуса. 2. Сети предъявляется входной вектор текста X и вычисляется мера подобия S(X,Wj) для каждого j – ого нейрона сети. Нейрон, для которого Sjмаксимальна, считается текущим центром и для него определяется зона соседства Dj(t). 3. Для всех нейронов, попадающих в зону Dj(t) производится коррекция весов по правилу wij(t + 1) = wij(t) + λ (xi(t) − wij(t)), где λ - шаг обучения, уменьшающийся с течением времени. Величина Dj(t) уменьшается со временем, так что изначально она охватывает всю сеть, а в конце обучения зона сужается до одного-двух нейронов, когда λ также достаточно мало. По аналогии с классификатором Гроссберга возможно использование как представление терм-документ, так и триграммное представление. На обучение сети оказывает влияние: 1. Количество нейронов и их размещение. Количество нейронов следует выбирать не меньше количества групп, которые требуется получить. Расположение нейронов на двумерной плоскости зависит от решаемой задачи. Как правило, выбирается либо квадратная матрица нейронов, либо прямоугольная с отношением сторон, близким к единице. 2. Начальное состояние. Может быть применена инициализация случайными значениями, но это не всегда приводит к желаемым результатам. Один из возможных вариантов улучшения этого – вычисление характеристических векторов репрезентативной выборки текстов, определяющих границу двумерной плоскости проекции. После этого, весовые вектора нейронов равномерно распределяются в полученном диапазоне. 3. Значение коэффициента обучения. Вне зависимости от начального распределения весовых векторов нейронов при значении коэффициента скорости обучения в районе 0.5-1 образуется множество отдельных классов, хотя в целом тенденция нейронов объединяться в однотипную группу сохраняется. В данном случае можно говорить о повышенной чувствительности сети к различным входным воздействиям. При уменьшении этого коэффициента чувствительность сети падает. Так что такие показатели как полнота и точность классификации определяются величиной λ и скоростью ее уменьшения в процессе обучения, чем быстрее убывает λ, тем больше точность и меньше полнота классификации. 4. Характер изменения топологической зоны соседства Dj(t). Определяет область нейронов, которые подлежат обучению. Чем быстрее будет сокращаться эта область, тем больше классов будет образовано, тем больше точность и меньше полнота. 5. Тип подаваемых на вход данных. Для лексических векторов фактически проводится обработка по имеющимся в документе термам, что дает достаточно хорошие результаты. В этом случае можно выделять документы по специфике словарного набора. Однако без применения морфологического анализа, данный метод не применим, так как резко увеличивается вычислительная сложность. Для триграммного представления текстов результаты классификации хуже, что связано с низкой адекватностью модели. 6. Последовательность подачи на вход векторов документов из разных групп. Поскольку со временем изменяется коэффициент скорости обучения λ, результаты подачи на вход различных векторов текстов оказываются различными. При большом начальном значении λ, происходит интенсивная модификация всех нейронов вокруг победителя. При этом со временем λ уменьшается и, если успеет уменьшиться значительно по сравнению с начальным значением до момента поступления на вход документов из следующей группы, получится довольно распределенная область, в которой встречаются документы из первой группы и сконцентрированные документы из второй группы. При случайной подаче документов из разных групп, области близости образуются равномерно. Однако возможно склеивание документов из разных групп. Причина в том, что вектор второго документа может оказаться где-нибудь поблизости от первого. В данном случае после приближения первым документов весовых векторов соседних от него нейронов, второй документ может скорректировать нейроны под себя. Еще одним распространенным методом классификации в рамках детерминистского подхода является метод опорных векторов, который, в зависимости от своих параметров, может реализовать нейросетевое распознавание и обладает более высокой скоростью работы, чем нейросети.
Метод опорных векторов
Метод опорных векторов (Support Vector Mashine, SVM), предложенный В.Н. Вапником [Vapnik V.N. Statistical Learning Theory. – New York: Wiley; 1998. – 732 p. Vapnik V.N. The nature of statistical learning theory. – New York: Springer-Verlag, 2000. – 332 p. ], относится к группе граничных методов классификации. Он определяет принадлежность объектов к классам с помощью границ областей. При изложении метода будем рассматривать только бинарную классификацию, т.е. классификацию только по двум категориям, т.е. С={С1, С2}, принимая во внимание то, что этот подход может быть расширен на любое конечное количество категорий. Предположим, что каждый объект классификации является вектором в n-мерном пространстве. Формализуем эту классификацию в рамках модели (1.1). D — множество документов, С={1, -1} — множество классов F - множество представлений документов
Метод SVM на множестве Х строит линейный пороговый классификатор f: F→C:
где вектор x=(x1,...,xn) — признаковое описание объекта, вектор w=(w1,...,wn) и скалярный порог w0— параметры алгоритма. Уравнение
Метод SVM базируется на таком постулате: наилучшая разделяющая прямая – это та, которая максимально далеко отстоит от ближайших до нее точек обоих классов. То есть задача метода SVM состоит в том, чтобы найти такие вектор w и число w0, чтобы ширина разделяющей полосы была максимальна. Поскольку чем шире полоса, тем увереннее можно классифицировать документы, соответственно, в методе SVM считается, что самая широкая полоса является наилучшей. Границами полосы являются две параллельные гиперплоскости с направляющим вектором w. Точки, ближайшие к разделяющей гиперплоскости, расположены точно на границах полосы, при этом сама разделяющая гиперплоскость проходит ровно по середине полосы. Нетрудно доказать, что ширина разделяющей полосы обратно пропорциональна норме вектора w. В этом случае построение оптимальной разделяющей гиперплоскости сводится к минимизации квадратичной формы при l ограничениях-неравенствах вида относительно n+1 переменных w, w0:
Эта задача эквивалентна двойственной задаче поиска седловой точки функции Лагранжа
Из условия равенство нулю производных Лагранжиана немедленно вытекают два соотношения:
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 171; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.183.137 (0.154 с.) |
 указывает на все слова вместе с которыми слово w встречается в тексте. Векторы, сформированные из контекстных векторов (контекстные векторы второго порядка), можно использовать для представления значений слов [Schutze H. Automatic word sense discrimination // Computational Linguistics. — 1998. — V. 24. P.97–123.].
указывает на все слова вместе с которыми слово w встречается в тексте. Векторы, сформированные из контекстных векторов (контекстные векторы второго порядка), можно использовать для представления значений слов [Schutze H. Automatic word sense discrimination // Computational Linguistics. — 1998. — V. 24. P.97–123.].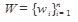 , включающий все термы, встречающиеся хотя бы в одном документе из информационного массива. Образом текста является вектор d=(d1,...,dn), компонента i которого равна 1, если терм w i входит в данный документ, и 0 в противном случае. Здесь, как и ранее, терм задается своим порядковым номером в словаре, а n - общее количество термов в словаре коллекции.
, включающий все термы, встречающиеся хотя бы в одном документе из информационного массива. Образом текста является вектор d=(d1,...,dn), компонента i которого равна 1, если терм w i входит в данный документ, и 0 в противном случае. Здесь, как и ранее, терм задается своим порядковым номером в словаре, а n - общее количество термов в словаре коллекции.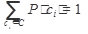 ), а так же условной вероятностью P(w|ci) встретить терм w в документе d при условии выбора рубрики ci. Эти величины используются при расчете вероятностей P(d|ci) того, что текст будет классифицирован при условии выбора рубрики ci. При расчете P(d|ci) учитывается представление d в виде последовательности термов wk. Подстановка этих величин в формулу Байеса дает вероятность того, что будет выбрана рубрика ci, при условии, что документ d пройдет успешную классификацию. Процедура классификации сводится к подсчету P(ci|d) для всех рубрик ci и выбора той, для которой эта величина максимальна. Обучение сводится к составлению словаря W и определению для каждой рубрики величин P(ci) и P(w|ci).
), а так же условной вероятностью P(w|ci) встретить терм w в документе d при условии выбора рубрики ci. Эти величины используются при расчете вероятностей P(d|ci) того, что текст будет классифицирован при условии выбора рубрики ci. При расчете P(d|ci) учитывается представление d в виде последовательности термов wk. Подстановка этих величин в формулу Байеса дает вероятность того, что будет выбрана рубрика ci, при условии, что документ d пройдет успешную классификацию. Процедура классификации сводится к подсчету P(ci|d) для всех рубрик ci и выбора той, для которой эта величина максимальна. Обучение сводится к составлению словаря W и определению для каждой рубрики величин P(ci) и P(w|ci).

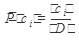

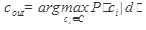
 , в которую входят все документы не вошедшие в ci;
, в которую входят все документы не вошедшие в ci;







 ,
, 
 или еще нет ни одного класса, то создать новый класс Wi=X и идти на шаг 1.
или еще нет ни одного класса, то создать новый класс Wi=X и идти на шаг 1.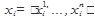 .
. - отношение на декартовом квадрате СxХ
- отношение на декартовом квадрате СxХ описывает гиперплоскость, разделяющую классы. Заметим, что параметры линейного порогового классификатора определены с точностью до нормировки: значение f(x) не изменится, если w и w0 одновременно умножить на одну и ту же положительную константу. Т.е. если классы линейно разделимы, разделяющая гиперплоскость не единственна. Удобно выбрать эту константу таким образом, чтобы для всех пограничных (т. е. ближайших к разделяющей гиперплоскости) объектов хi из X выполнялись условия:
описывает гиперплоскость, разделяющую классы. Заметим, что параметры линейного порогового классификатора определены с точностью до нормировки: значение f(x) не изменится, если w и w0 одновременно умножить на одну и ту же положительную константу. Т.е. если классы линейно разделимы, разделяющая гиперплоскость не единственна. Удобно выбрать эту константу таким образом, чтобы для всех пограничных (т. е. ближайших к разделяющей гиперплоскости) объектов хi из X выполнялись условия: (3.1)
(3.1)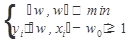 (3.2)
(3.2)
 (3.3)
(3.3) (3.4)
(3.4)


