
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Классификаторы на основе нейросетей
Нейронные сети могут применяться при решении многих задач обработки информации, в частности в задачах распознавания образов. Как известно, искусственный нейрон выполняет следующие преобразования входного вектора X=(xi): y = I(S); S = ∑ wixi, где wi– весовой вектор нейрона (веса синаптических связей), S – результат взвешенного суммирования, I – нелинейная функция активации нейрона. В терминах модели (1.1) X – соответствует внутренним описаниям множества F, а функции S и I – компоненты процедуры классификации f. Функциональность нейрона проста, поэтому для решения конкретных задач нейроны объединяются в сети. Обучение классификатора, при условии, что выбрана топология сети и выбрана функция активации I, сводится к подбору весовых коэффициентов каждого нейрона. В данной работе рассматривается применение трех топологий: сети Гроссберга, Хопфилда и Кохонена. Первые две топологии — сети с обратными связями, следовательно, обладающие «памятью», что очень ценно, поскольку такие сети могут быть ориентированы на анализ текстов в условиях меняющейся реальности.
Нейронная сеть Хопфилда — полносвязная нейронная сеть с симметричной матрицей связей. Сеть Хопфилда является однослойной рекурсивной сетью, потому что обладает обратными связями. Она функционирует циклически. В процессе работы динамика таких сетей сходится (конвергирует) к одному из положений равновесия. Эти положения равновесия являются локальными минимумами функционала, называемого энергией сети (в простейшем случае — локальными минимумами отрицательно определённой квадратичной формы на n-мерном кубе). Такая сеть может быть использована как автоассоциативная память, как фильтр, а также для решения некоторых задач оптимизации. В отличие от многих нейронных сетей, работающих до получения ответа через определённое количество тактов, сети Хопфилда работают до достижения равновесия, когда следующее состояние сети в точности равно предыдущему: начальное состояние является входным образом, а при равновесии получают выходной образ. Образ, который сеть запоминает или распознаёт (любой входной образ) может быть представлен в виде вектора X размерностью N, где N – число нейронов в сети. Выходной образ представляется вектором Y с такой же размерностью. Каждый нейрон сети Хопфилда может принимать одно из двух состояний (что аналогично выходу нейрона с пороговой функцией активации), из-за их биполярной природы нейроны сети Хопфилда иногда называют спинами:
Обучение любой нейронной сети состоит в вычислении весовых коэффициентов. Для этого строится матрица весов W (для сети Хопфилда она имеет размер NxN), отражающая связь между нейронами. При обучении сети некому образу X весовые коэффициенты устанавливаются так:
где М — число запоминаемых образов, k — номер запоминаемого вектора, Xij— i-я компонента запоминаемого j-го вектора. Это выражение может стать более ясным, если заметить, что весовая матрица W может быть найдена вычислением внешнего произведения каждого запоминаемого вектора с самим собой и суммированием матриц, полученных таким образом. Это может быть записано в виде
Алгоритм обучения сети Хопфилда существенно отличается от таких классических алгоритмов обучения перцептронов, как метод коррекции ошибки или метод обратного распространения ошибки. Отличие заключается в том, что вместо последовательного приближения к нужному состоянию с вычислением ошибок, все коэффициенты матрицы рассчитываются по одной формуле, за один цикл, после чего сеть сразу готова к работе. Вычисление коэффициентов основано на следующем правиле: для всех запомненных образов матрица весов должна удовлетворять уравнению
поскольку именно при этом условии состояния сети Xiбудут устойчивы — попав в такое состояние, сеть в нём и останется. В сети Хопфилда матрица весов является симметричной, а диагональные элементы матрицы полагаются равными нулю, что исключает эффект воздействия нейрона на самого себя и является необходимым для сети Хопфилда, но не достаточным условием, устойчивости в процессе работы сети. Как только веса заданы, сеть может быть использована для получения запомненного выходного вектора по данному входному вектору, который может быть частично неправильным или неполным. Возможны несколько исходов:
в идеале сеть распознает образ и выдаст на выход эталонный вектор, соответствующий искажённому. если в памяти сети есть похожие образы, и входящий искажённый похож на их обоих, то сеть может впасть в бесконечный цикл. В первом случае признаком нахождения решения сетью Хопфилда является момент, когда достигается статический аттрактор, т.е. на каждом следующем шаге повторяется устойчивое состояние. Во втором — динамический, когда до бесконечности чередуются два разных состояния {X(t),X(t+1)}, соответствующих похожим образам. Распознавание проводится по следующей схеме. Пусть t — текущая итерация. При t =1 случайным образом выбирается нейрон r для обновления. Для него локальное поле ar(t) действующим на нейрон yiсо стороны всех остальных нейронов сети:
где wij— весовой коэффициент между нейронами i и j, yj(t-1) — значения выходов нейрона j в предыдущий момент времени.
После расчёта локального поля нейрона ar(t) это значение используется для расчёта значения выхода нейрона r: yr(t)=sign(ar(t)) Выходной вектор рекурсивно подаётся на вход сети снова, после чего выполняется следующая итерация (t=t+1). Устойчивость сети достигается, когда выполняется общая энергия сети уменьшается от итерации к итерации, т.е.:
E(t+1)≤E(t), где
В ситуации, когда происходят бесконечные циклические переходы, энергия двух разных состояний соответственно равна E(t) и E(t+1). При этом состояния t+1 и t-1, а также t и t+2 — совпадают. Если образуется такое состояние, то его называется динамическим аттрактором. Если же совпадают состояния t и t+1, аттрактор называют статическим. Как было сказано выше, в идеальном случае, ответом сети является такое устойчивое состояние, которое совпадает с одним из запомненных при обучении векторов, однако при некоторых условиях (в частности, при слишком большом количестве запомненных образов) результатом работы может стать так называемый ложный аттрактор («химера»), состоящий из нескольких частей разных запомненных образов, а также в синхронном режиме сеть может прийти к динамическому аттрактору. Обе эти ситуации в общем случае являются нежелательными, поскольку не соответствуют ни одному запомненному вектору, а следовательно, не определяют класс, к которому сеть отнесла входной образ. Если моделировать работу сети как последовательный алгоритм, то в асинхронном режиме работы состояния нейронов в следующий момент времени меняются последовательно: вычисляется локальное поле для первого нейрона в момент t, определяется его реакция, и нейрон устанавливается в новое состояние (которое соответствует его выходу в момент t+1), потом вычисляется локальное поле для второго нейрона с учётом нового состояния первого, меняется состояние второго нейрона, и так далее — состояние каждого следующего нейрона вычисляется с учетом всех изменений состояний рассмотренных ранее нейронов. В этом случае невозможен динамический аттрактор: вне зависимости от количества запомненных образов и начального состояния сеть непременно придёт к устойчивому состоянию (статическому аттрактору). Сеть с обратной связью формирует ассоциативную память. Сеть Хопфилда можно отнести к автоассоциативной памяти, то есть такой, которая может завершить или исправить образ, но не может ассоциировать полученный образ с другим образом. Чтобы организовать устойчивую автоассоциативную память с помощью сети с обратными связями, веса нужно выбирать так, чтобы образовывать энергетические минимумы в нужных вершинах единичного гиперкуба.
У нейронной сети Хопфилда есть ряд недостатков. 1. Относительно небольшой объём памяти, величину которого можно оценить выражением:
Попытка записи большего числа образов приводит к тому, что нейронная сеть перестаёт их распознавать. Сеть, содержащая N нейронов может запомнить не более ~0.15*N образов. Так что реальная сеть должна содержать достаточно внушительное количество нейронов. 2. Достижение устойчивого состояния не гарантирует правильный ответ сети. Это происходит из-за того, что сеть может сойтись к так называемым ложным аттрактором, иногда называемым «химерой» (как правило, химеры склеены из фрагментов различных образов).
Сеть Гроссберга (ART) Топология сети ART (Adaptive Resonance Theory), разработанная Гроссбергом и Карпентером, хорошо зарекомендовала себя для решения задач кластеризации. Основная идея сетей Гроссберга - опознание образа за счет сравнения характерных признаков сигнала с запомненным ранее эталоном (классом). Сеть состоит из двух слоев нейронов. Первый (входной) слой – сравнивающий, содержит столько нейронов, сколько терминов в словаре обучающей выборки документов; второй слой – распознающий. В общем случае между слоями существуют прямые связи с весами wijот i–ого нейрона входного слоя к j–ому нейрону распознающего слоя, обратные связи с весами vij– от i-ого нейрона распознающего слоя к j–ому нейрону входного слоя. Так же существуют латеральные тормозящие связи между нейронами распознающего слоя. Каждый нейрон распознающего слоя отвечает за один класс объектов. Веса wij используются на первом шаге классификации для выявления наиболее подходящего нейрона – класса, веса обратных связей vijхранят типичные образы (прототипы) соответствующих классов и используются для непосредственного сопоставления с входным вектором. Сеть ART имеет достаточно много выходных нейронов, однако используется только часть из них. В сети хранится набор образцов для сравнения с входным сигналом. Если входной сигнал достаточно похож на один из эталонных образцов (находится с ним в резонансе), усиливается вес для синапса нейрона, отвечающего за данную категорию. Если же в сети нет схожих с входным вектором образцов, ему в соответствие ставится один из незадействованных выходных нейронов [Ф. Уссермен Нейрокомпьютерная техника. - М.: Мир, 1992. ].
Согласно назначению приведенных компонентов такой сети процедура классификации представляет собой следующую последовательность операций: 1. Вектор X подается на вход сети, для каждого нейрона распознающего слоя определяется взвешенная сумма его входов. 2. За счет латеральных тормозящих связей распознающего слоя на его выходах устанавливается единственный сигнал с наибольшим значением, остальные выходы становятся близкими к 0: yi=max(Y) 3. Определяется мера близости Siмежду входным вектором X и прототипом класса Vi, соответствующего i-ому нейрону, победившему на предыдущем шаге. Если результат сравнения превышает порог p, делается вывод о том, что входной вектор принадлежит классу ci, в противном случае выход данного нейрона обнуляется (принудительная блокировка) и повторяется процедура на шаге 2, в которой за счет обнуления самого активного нейрона происходит выбор нового.
4. Шаги 2-3 повторяются до тех пор, пока не будет получен класс cout, либо пока не будут принудительно заблокированы все нейроны распознающего слоя. В реализации классификатора некоторые компоненты сети могут быть опущены. Например, можно убрать связи латерального торможения, вместо двух матриц Wijи Vijиспользуется одна – Wij, которая отвечает и за выбор предпочтительного нейрона-класса, и за хранение прототипов классов. В этом случае вычисление функции сопоставления S совмещает в себе шаги 2 и 3 и рассчитывается непосредственно для X и весовых векторов Wi, побеждает тот нейрон i, для которого max(Si). Для обучения сети используются такие меры близости:
где β - положительная константа, n - размерность вектора признаков. Алгоритм обучения [Alberto Muñoz. Compound Key Word Generation from Document Databases Using A Hierarchical Clustering ART Model, 1997 ] состоит из следующих шагов. 1. На входы подать обучающий вектор X. Активизировать все нейроны выходного слоя. 2. Найти активный нейрон с прототипом Wi, наиболее близким к X, используя меру близости Si’. 3. Если для найденного нейрона 4. Если для найденного нейрона Si <ρ, ρ ∈ [0,1], 3. то деактивировать найденный нейрон. Если все нейроны неактивны, то создать новый класс Wi = X, идти на шаг 1. Иначе идти на шаг 2 и попробовать другой еще активный нейрон. 5. Если для найденного нейрона Si' и Siпревышают пороги, указанные на шаге 4 и 5, то модифицировать его веса Wi= λ X Wi+ (1 − λ) Wi, передвинув ближе к входному вектору. На количество образующихся классов оказывают влияние константы β и ρ. С ростом ρ и уменьшением β их количество увеличивается. Коэффициент обучения 0 < λ < 1 определяет скорость обучения. В начале обучения его значения должно быть большим и монотонно уменьшаться со временем. Cнижение ρ и увеличение β снижает избирательность сети, что приводит к снижению точности и повышению полноты классификации.
Классификация документов сводится к предъявлению обученной нейронной сети вектора авизируемого текста X и поиска из всех нейронов распознающего слоя того, для которого Si наибольшая. При использовании в качестве входных векторов представление текста в виде лексических векторов модели терм-документ, входной слой содержит столько нейронов, сколько терминов в словаре обучающей выборки документов (Nw), весовые вектора Wi нейронов распознающего слоя содержат значимость wjij-ого термина для i-ого класса. При использовании триграммной модели представления текста число входных нейронов соответствует M3, при этом весовые вектора Wiопределяют значимость wjij-ой триграммы для i-ого класса.
Сеть Кохонена (SOM) Назначение сети Кохонена (SOM, Self-Organizing Map, – самоорганизующиеся карты Кохонена) [Круглов В.В., Борисов В.В. Искусственные нейронные сети. Теория и практика. – М.: Горячая линия – Телеком, 2001. ] – разделение векторов входных сигналов на группы, поэтому возможность представления текстов в виде векторов действительных чисел позволят применять данную сеть для кластеризации. Cеть состоит из одного слоя, имеющего форму прямоугольной решетки для 4-х связных нейронов и форму соты для 6-ти связных. Анализируемые вектора X подаются на входы всех нейронов. По результатам обучения геометрически близкие нейроны оказываются чувствительными к похожим входным сигналам, что может быть использовано в задаче классификации следующим образом. Для каждого класса определяется центральный нейрон и доверительная область вокруг него. Критерием границы доверительной области является расстояние между векторами соседних нейронов и расстояние до центрального нейрона области. При подаче на вход обученной сети вектора текста активизируются некоторые нейроны (возможно из разных областей), текст относится к тому классу, в доверительной области которого активизировалось наибольшее число нейронов и как можно ближе к ее центру. Алгоритм обучения сети заключается в следующем. Все вектора должны лежать на гиперсфере единичного радиуса. Задается мера соседства нейронов, позволяющая определять зоны топологического соседства в различные моменты времени. Кроме того, задается размер решетки и размерность входного вектора, а так же определяется мера подобия векторов S (наиболее подходящей является косинус угла). Далее выполняются следующие шаги для каждого вектора обучающей выборки. 1. Начальная инициализация плоскости может быть произведена, например произвольным распределением весовых векторов на гиперсфере единичного радиуса. 2. Сети предъявляется входной вектор текста X и вычисляется мера подобия S(X,Wj) для каждого j – ого нейрона сети. Нейрон, для которого Sjмаксимальна, считается текущим центром и для него определяется зона соседства Dj(t). 3. Для всех нейронов, попадающих в зону Dj(t) производится коррекция весов по правилу wij(t + 1) = wij(t) + λ (xi(t) − wij(t)), где λ - шаг обучения, уменьшающийся с течением времени. Величина Dj(t) уменьшается со временем, так что изначально она охватывает всю сеть, а в конце обучения зона сужается до одного-двух нейронов, когда λ также достаточно мало. По аналогии с классификатором Гроссберга возможно использование как представление терм-документ, так и триграммное представление. На обучение сети оказывает влияние: 1. Количество нейронов и их размещение. Количество нейронов следует выбирать не меньше количества групп, которые требуется получить. Расположение нейронов на двумерной плоскости зависит от решаемой задачи. Как правило, выбирается либо квадратная матрица нейронов, либо прямоугольная с отношением сторон, близким к единице. 2. Начальное состояние. Может быть применена инициализация случайными значениями, но это не всегда приводит к желаемым результатам. Один из возможных вариантов улучшения этого – вычисление характеристических векторов репрезентативной выборки текстов, определяющих границу двумерной плоскости проекции. После этого, весовые вектора нейронов равномерно распределяются в полученном диапазоне. 3. Значение коэффициента обучения. Вне зависимости от начального распределения весовых векторов нейронов при значении коэффициента скорости обучения в районе 0.5-1 образуется множество отдельных классов, хотя в целом тенденция нейронов объединяться в однотипную группу сохраняется. В данном случае можно говорить о повышенной чувствительности сети к различным входным воздействиям. При уменьшении этого коэффициента чувствительность сети падает. Так что такие показатели как полнота и точность классификации определяются величиной λ и скоростью ее уменьшения в процессе обучения, чем быстрее убывает λ, тем больше точность и меньше полнота классификации. 4. Характер изменения топологической зоны соседства Dj(t). Определяет область нейронов, которые подлежат обучению. Чем быстрее будет сокращаться эта область, тем больше классов будет образовано, тем больше точность и меньше полнота. 5. Тип подаваемых на вход данных. Для лексических векторов фактически проводится обработка по имеющимся в документе термам, что дает достаточно хорошие результаты. В этом случае можно выделять документы по специфике словарного набора. Однако без применения морфологического анализа, данный метод не применим, так как резко увеличивается вычислительная сложность. Для триграммного представления текстов результаты классификации хуже, что связано с низкой адекватностью модели. 6. Последовательность подачи на вход векторов документов из разных групп. Поскольку со временем изменяется коэффициент скорости обучения λ, результаты подачи на вход различных векторов текстов оказываются различными. При большом начальном значении λ, происходит интенсивная модификация всех нейронов вокруг победителя. При этом со временем λ уменьшается и, если успеет уменьшиться значительно по сравнению с начальным значением до момента поступления на вход документов из следующей группы, получится довольно распределенная область, в которой встречаются документы из первой группы и сконцентрированные документы из второй группы. При случайной подаче документов из разных групп, области близости образуются равномерно. Однако возможно склеивание документов из разных групп. Причина в том, что вектор второго документа может оказаться где-нибудь поблизости от первого. В данном случае после приближения первым документов весовых векторов соседних от него нейронов, второй документ может скорректировать нейроны под себя. Еще одним распространенным методом классификации в рамках детерминистского подхода является метод опорных векторов, который, в зависимости от своих параметров, может реализовать нейросетевое распознавание и обладает более высокой скоростью работы, чем нейросети.
Метод опорных векторов
Метод опорных векторов (Support Vector Mashine, SVM), предложенный В.Н. Вапником [Vapnik V.N. Statistical Learning Theory. – New York: Wiley; 1998. – 732 p. Vapnik V.N. The nature of statistical learning theory. – New York: Springer-Verlag, 2000. – 332 p. ], относится к группе граничных методов классификации. Он определяет принадлежность объектов к классам с помощью границ областей. При изложении метода будем рассматривать только бинарную классификацию, т.е. классификацию только по двум категориям, т.е. С={С1, С2}, принимая во внимание то, что этот подход может быть расширен на любое конечное количество категорий. Предположим, что каждый объект классификации является вектором в n-мерном пространстве. Формализуем эту классификацию в рамках модели (1.1). D — множество документов, С={1, -1} — множество классов F - множество представлений документов
Метод SVM на множестве Х строит линейный пороговый классификатор f: F→C:
где вектор x=(x1,...,xn) — признаковое описание объекта, вектор w=(w1,...,wn) и скалярный порог w0— параметры алгоритма. Уравнение
Метод SVM базируется на таком постулате: наилучшая разделяющая прямая – это та, которая максимально далеко отстоит от ближайших до нее точек обоих классов. То есть задача метода SVM состоит в том, чтобы найти такие вектор w и число w0, чтобы ширина разделяющей полосы была максимальна. Поскольку чем шире полоса, тем увереннее можно классифицировать документы, соответственно, в методе SVM считается, что самая широкая полоса является наилучшей. Границами полосы являются две параллельные гиперплоскости с направляющим вектором w. Точки, ближайшие к разделяющей гиперплоскости, расположены точно на границах полосы, при этом сама разделяющая гиперплоскость проходит ровно по середине полосы. Нетрудно доказать, что ширина разделяющей полосы обратно пропорциональна норме вектора w. В этом случае построение оптимальной разделяющей гиперплоскости сводится к минимизации квадратичной формы при l ограничениях-неравенствах вида относительно n+1 переменных w, w0:
Эта задача эквивалентна двойственной задаче поиска седловой точки функции Лагранжа
Из условия равенство нулю производных Лагранжиана немедленно вытекают два соотношения:
Из (3.3) следует, что искомый вектор весов w является линейной комбинацией векторов обучающей выборки, причём только тех, для которых λi = 0. На этих векторах xi ограничения-неравенства обращаются в равенства, следовательно, эти векторы находятся на границе разделяющей полосы. Все остальные векторы отстоят дальше от границы, для них λi = 0, и они не участвуют в сумме (3.3). Алгоритм Значение классификатора f(x) не изменилось бы, если бы этих векторов вообще не было в обучающей выборке. Опорным вектором (support vector) называется объект обучающей выборки xi, находящийся на границе разделяющей полосы, если λi> 0 Подставляя (3.3) и (3.4) обратно в Лагранжиан, получим эквивалентную задачу квадратичного программирования, содержащую только вектор λ.
В этой задаче минимизируется квадратичный функционал, имеющий неотрицательно определённую квадратичную форму, следовательно, выпуклый. Область, определяемая ограничениями неравенствами и одним равенством, также выпуклая. Следовательно, данная задача имеет единственное решение. Допустим, мы решили эту задачу. Тогда вектор w вычисляется по формуле (3.3). Для определения порога w0достаточно взять произвольный опорный вектор xi и выразить w0из равенства (3.1). На практике для повышения численной устойчивости рекомендуется брать в качестве w0среднее по всем опорным векторам, а ещё лучше медиану:
w0=med{<w,xi>-yi: λi> 0, i=1,...,l}
В итоге алгоритм классификации может быть записан в следующем виде:
Чтобы обобщить SVM на случай линейной неразделимости за отправную точку берется задача (3.2) со следующими модификациями: · допускается появление ошибок на объектах обучающей выборки, но при этом вводится набор дополнительных переменных ξi, характеризующих величину ошибки на объектах xi; · в (3.2) смягчаются ограничения-неравенства (3.1); · в минимизируемый функционал вводится штраф за суммарную ошибку. Вектор w и скалярный порог w0могут быть получены при минимизации функционала:
Положительная константа C является управляющим параметром метода и позволяет находить компромисс между максимизацией разделяющей полосы и минимизацией суммарной ошибки. Как и в случае линейной разделимости классов, задача минимизации функционала сводится к поиску седловой точки функции Лагранжа и параметры разделяющей поверхности w и w0также выражаются только через двойственные переменные λi. Таким образом, задача снова сводится к квадратичному программированию относительно двойственных переменных λi. Единственное отличие от линейно разделимого случая состоит в появлении ограничения сверху λi≥C:
Поскольку гарантировать линейную разделимость выборки в общем случае не представляется возможным, то на практике для построения SVM решают именно эту задачу. Этот вариант алгоритма называют SVM с мягким зазором (soft-margin SVM), тогда как в линейно разделимом случае говорят об SVM с жёстким зазором (hard-margin SVM). При этом существенно, что целевая функция зависит не от конкретных значений, а от скалярных произведений между ними. Следует заметить, что целевая функция является выпуклой, поэтому любой ее локальный минимум является глобальным. Для алгоритма классификации сохраняется формула (3.5), с той лишь разницей, что теперь ненулевыми λi обладают не только опорные объекты, но и объекты-нарушители (объекты, лежащие внутри разделяющей полосы, но классифицирующиеся правильно, либо попадающие на границу классов, либо вообще относящиеся к чужому классу. В определённом смысле это недостаток SVM, поскольку нарушителями часто оказываются шумовые выбросы, и построенное на них решающее правило, по сути дела, опирается на шум. Константу C обычно выбирают по критерию скользящего контроля. Это трудоёмкий способ, так как задачу приходится решать заново при каждом значении C. Если есть основания полагать, что выборка почти линейно разделима, и лишь объекты-выбросы классифицируются неверно, то можно применить фильтрацию выбросов. Сначала задача решается при некотором C, и из выборки удаляется небольшая доля объектов, имеющих наибольшую величину ошибки ξi. После этого задача решается заново по усечённой выборке. Возможно, придётся проделать несколько таких итераций, пока оставшиеся объекты не окажутся линейно разделимыми. Метод классификации разделяющей полосой имеет два недостатка: - при поиске разделяющей полосы важное значение имеют только пограничные точки; - во многих случаях найти оптимальную разделяющую полосу невозможно. Для улучшения метода применяется идея расширенного пространства, которая заключается в переходе от исходного пространства признаковых описаний объектов X к новому пространству H с помощью некоторого преобразования ψ: X → H. Если пространство H имеет достаточно высокую размерность, то можно надеяться, что в нём выборка окажется линейно разделимой. Пространство H называют спрямляющим. Если предположить, что признаковыми описаниями объектов являются векторы ψ(xi), а не векторы xi, то построение SVM проводится точно так же, как и ранее. Единственное отличие состоит в том, что скалярное произведение <x, x′> в пространстве X всюду заменяется скалярным произведением <ψ(x), ψ(x′)> в пространстве H. Это возможно с помощью ядра. Функция K: X × X → R называется ядром (kernel function), если она представима в виде K(x, x′) = <ψ(x), ψ(x′)> при некотором отображении ψ: X → H, где H — пространство со скалярным произведением. Отсюда вытекает естественное требование: спрямляющее пространство должно быть наделено скалярным произведением, в частности, подойдёт любое евклидово, а в общем случае и гильбертово, пространство. В случае линейной неразделимости: 1.Выбирается отображение векторов в новое, расширенное пространство ψ: X → H. 2. Автоматически применяется новая функция скалярного произведения — ядро K(x,z) = <ψ(x), ψ(z)>. На практике обычно выбирают не отображение, а сразу функцию ядра - главный параметр настраивания машины опорных векторов. 3. Определяется разделяющая гиперплоскость в новом пространстве: с помощью функции K(x,z) устанавливается новая матрица коэффициентов для задачи оптимизации. При этом вместо скалярного произведения <x,z> берется значение K(x,z), и решается новая задача оптимизации. 4. Найдя w и w0, получаем разделяющую гиперплоскость в новом, расширенном, пространстве.
Ядром может быть не всякая функция, однако класс допустимых ядер достаточно широк. Например, в системе классификации новостного контента с применением известного пакета LibSVM (http://www.csie.ntu.edu.tw/~cjlin/libsvm) в качестве функции ядра рекомендуется использовать радиальную базисную функцию: Используя функцию ядра, нетрудно показать связь SVM с двухслойными нейронными сетями. Рассмотрим структуру алгоритма классификации f(x) после замены решающем правиле скалярного произведения <xi, x> ядром K(xi, x). При этом перенумеруем объекты так, чтобы первые h объектов оказались опорными. Поскольку λi= 0 для всех неопорных объектов, i = h+1,...,l:
Следовательно, классификатор f(х) можно рассматривать как двухслойную нейронную сеть, имеющую n входных нейронов и h нейронов в скрытом слое и обладающую следующими особенностями: · число нейронов скрытого слоя определяется автоматически. · векторы весов у нейронов скрытого слоя совпадают с признаковыми описаниями опорных объектов. · λi — это вес, выражающий степень важности ядра K(xi, x).
Метод SVM обладает определенными преимуществами: - на тестах с документальными массивами превосходит другие методы; - при выборах разных ядер позволяет реализовать другие подходы. Например, большой класс нейронных сетей можно представить с помощью SVM со специальными ядрами; - итоговое правило выбирается не с помощью экспертных эвристик, а путем оптимизации некоторой целевой функции.
К недостаткам метода можно отнести: - иногда слишком малое количество параметров для настройки: после того как фиксируется ядро, единственным изменяемым параметром остается коэффициент ошибки; - нет четких критериев выбора ядра; - медленное обучение системы классификации.
Как видно из проведенного обзора, на сегодняшний день существует очень большое количество классификаторов. Большинство из рассмотренных методов имеют существенный недостаток – обучение с учителем (supervised learning). В данном случае классификация определяет документы в одну или более предопределённых категорий. В классификации текста новый текстовый документ назначается в один из уже существующих наборов документов класса. Определить новые заранее не известные структуры коллекции документов при таком подходе не представляется возможным. Решением этой проблемы занимается текстовую кластеризация – обучение без учителя (unsupervised learning). Текстовая кластеризация автоматически выявляет группы семантически похожих документов среди заданного фиксированного множества документов. Следует отметить, что группы формируются только на основе попарной схожести описаний документов, и никакие характеристики этих групп не задаются заранее, в отличие от текстовой классификации, где категории задаются заранее.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 167; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.219.22.169 (0.104 с.) |
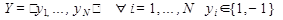

 , где Xi— i-й запоминаемый вектор-строка
, где Xi— i-й запоминаемый вектор-строка ,
, ,
,


 ,
, 
 или еще нет ни одного класса, то создать новый класс Wi=X и идти на шаг 1.
или еще нет ни одного класса, то создать новый класс Wi=X и идти на шаг 1. - множество описаний, построенное по обучающей выборке документов, каждый элемент множества — вектор
- множество описаний, построенное по обучающей выборке документов, каждый элемент множества — вектор 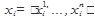 .
. - отношение на декартовом квадрате СxХ
- отношение на декартовом квадрате СxХ ,
, описывает гиперплоскость, разделяющую классы. Заметим, что параметры линейного порогового классификатора определены с точностью до нормировки: значение f(x) не изменится, если w и w0 одновременно умножить на одну и ту же положительную константу. Т.е. если классы линейно разделимы, разделяющая гиперплоскость не единственна. Удобно выбрать эту константу таким образом, чтобы для всех пограничных (т. е. ближайших к разделяющей гиперплоскости) объектов хi из X выполнялись условия:
описывает гиперплоскость, разделяющую классы. Заметим, что параметры линейного порогового классификатора определены с точностью до нормировки: значение f(x) не изменится, если w и w0 одновременно умножить на одну и ту же положительную константу. Т.е. если классы линейно разделимы, разделяющая гиперплоскость не единственна. Удобно выбрать эту константу таким образом, чтобы для всех пограничных (т. е. ближайших к разделяющей гиперплоскости) объектов хi из X выполнялись условия: (3.1)
(3.1)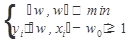 (3.2)
(3.2)
 (3.3)
(3.3) (3.4)
(3.4)
 (3.5)
(3.5)




